hadoop伪分布式集群的安装(不是单机版)
三台虚拟机,关闭防火墙,关闭selinux
查看防火状态 systemctl status firewalld
暂时关闭防火墙 systemctl stop firewalld
永久关闭防火墙 systemctl disable firewalld
查看 selinux状态 getenforce
暂时关闭 selinux setenforce 0
hostnamectl set-hostname master hostnamectl set-hostname slave1 hostnamectl set-hostname slave2
使用bash命令刷新生效
在/etc/hosts文件中添加ip映射
IP+主机名称
根据自己需求修改,这里给出模板

配置ssh免密登录
ssh-keygten -t rsa #生成密钥 ssh-copy-id master #分发给其他节点,分发给自己主要是为了之后群集集群不需要输入密码 ssh-copy-id slave1 ssh-copy-id slave2
安装JAVA和HADOOP
解压JAVA

解压HADOOP

修改名称为jdk与hadoop

配置环境变量
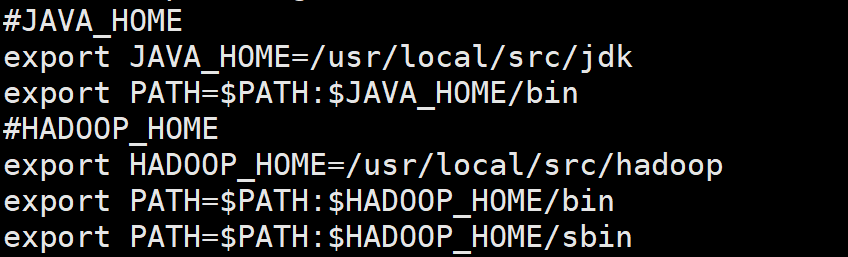
刷新环境变量,使生效
source /etc/profile
使用javac 与hadoop verison验证是否安装成功
配置hadoop文件
core-site.xml文件
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.7.2/data/tmp</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-2.6.0/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-2.6.0/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
yarn.site.xml
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
在hadoop-env.sh yarn-env.sh mapred-env.sh中配置java环境

这里给出hadoop-env.sh 其他相同
配置slave
写入三台主机的主机名

将配置好的hadoop分发给其他主机
[root@master ~]# scp -r /usr/local/src/hadoop/ root@slave1:/usr/local/src/ [root@master ~]# scp -r /usr/local/src/hadoop/ root@slave2:/usr/local/src/
格式化namenode
hdfs namenode -format
启动dfs
start-dfs.sh
启动yarn
start-yarn.sh
使用jps查看
master节点:ResourceManager,DataNode,SecondaryNameNode,NameNode,NodeManager
slave1节点与slave2节点:NodeManager,DataNode
集群全部启动则为启动成功
进入web页面验证
namenode web页面 = IP+50070
yarn web页面 =IP 8088