☆常用的Sql语句汇总(DDL/DML)
常用的sql语句汇总
1、获取所有表名、表信息
- 里面有表注释
| 数据库种类 | sql | 备注 |
|---|---|---|
| mysql | -- 获取所有表名、视图名 show tables -- 获取 dev_test_data数据库 所有表、视图信息 select * from information_schema.tables where table_schema='dev_test_data' -- 获取表名、视图名 select table_name from information_schema.tables where table_schema='dev_test_data' -- 只获取表信息 select * from information_schema.tables where table_schema='dev_test_data' and table_type = 'BASE TABLE' |
|
| 达梦8 (底层是oracle) |
-- 获取表、视图名称 select table_name from user_tab_comments -- 只获取表名称 select table_name from user_tab_comments where TABLE_TYPE = 'TABLE' -- 获取表信息、视图 select * from user_tab_comments |
基本和oracle一样的 |
| oracle | -- 获取表名 select table_name from user_tab_comments where TABLE_TYPE = 'TABLE' -- 获取表信息 select * from user_tab_comments where TABLE_TYPE = 'TABLE' -- 获取表、视图信息 select * from user_tab_comments |
2、获取当前表的 主表(外键关联的表)
| 数据库种类 | sql | 备注 |
|---|---|---|
| mysql | SELECT REFERENCED_TABLE_NAME FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE CONSTRAINT_SCHEMA='dev_test_data' AND TABLE_NAME = 't_c_my_dept' and REFERENCED_TABLE_NAME != 'null' |
获取字段:table_name |
| oracle、达梦8 | -- 根据表名获取 其主表 第一种 方法 select t1.table_name, t2.table_name as "TABLE_NAME(R)", t1.constraint_name, t1.r_constraint_name as "CONSTRAINT_NAME(R)", a1.column_name, a2.column_name as "COLUMN_NAME(R)" from user_constraints t1, user_constraints t2, user_cons_columns a1, user_cons_columns a2 where t1.owner = upper('CJY') and t1.r_constraint_name = t2.constraint_name and t1.constraint_name = a1.constraint_name and t1.r_constraint_name = a2.constraint_name and t1.table_name = 't_c_emp' -- 根据表名获取 其主表 第二种 方法 select cl.table_name from user_cons_columns cl left join user_constraints c on cl.constraint_name = c.r_constraint_name where c.constraint_type = 'R' and c.table_name = 't_c_dept' and c.owner = 'CJY' |
|
--(获取其主表) ———— 外键关联的表
- 就是这个表中的外键关联的表

2.1、获取从表

--mysql
select * from INFORMATION_SCHEMA.KEY_COLUMN_USAGE where TABLE_SCHEMA = "dev_test_data" and REFERENCED_TABLE_NAME in ('t_c_my_dept') AND REFERENCED_TABLE_NAME != ""
--oracle、达梦
获取其从表
-- 根据表名获取 其从属表的名字
select c.table_name from user_cons_columns cl
left join user_constraints c on cl.constraint_name = c.r_constraint_name
where c.constraint_type = 'R'
and cl.table_name = 't_c_dept' and c.owner = 'CJY'
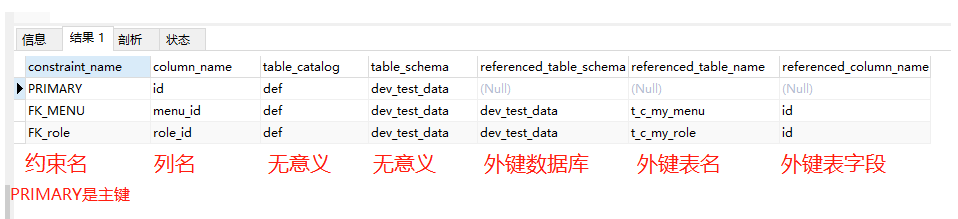
3、获取表的约束
- 根据表名、数据库名
| 数据库种类 | SQL | 备注 |
|---|---|---|
| mysql | SELECT constraint_name, column_name, table_catalog, table_schema, referenced_table_schema, referenced_table_name, referenced_column_name, table_name FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE table_schema = 'fd' -- 筛选表名,一起查询快些 -- AND table_name = 't_autotb561' AND ( referenced_table_name IS NOT NULL OR constraint_name = 'PRIMARY' ) |
23.2.3更新 |
| oracle/达梦8 | SELECT aa.CONSTRAINT_NAME, aa.COLUMN_NAME, aa.CONSTRAINT_TYPE, aa.SEARCH_CONDITION, aa.R_CONSTRAINT_NAME, bb.TABLE_NAME, bb.COLUMN_NAME, aa.TABLE_NAME FROM ( SELECT A.CONSTRAINT_NAME, A.TABLE_NAME, A.COLUMN_NAME, B.CONSTRAINT_TYPE, B.SEARCH_CONDITION, B.R_CONSTRAINT_NAME FROM USER_CONS_COLUMNS A, USER_CONSTRAINTS B WHERE A.CONSTRAINT_NAME = B.CONSTRAINT_NAME -- 模式名 AND A.owner = 'THEME_BY1' -- 表名(查所有比一个个查询快) -- AND A.TABLE_NAME = 'E_Z_CS_EMP' ) aa LEFT JOIN USER_CONS_COLUMNS bb ON bb.CONSTRAINT_NAME = aa.R_CONSTRAINT_NAME |
23.2.3更新 |
mysql
oracle

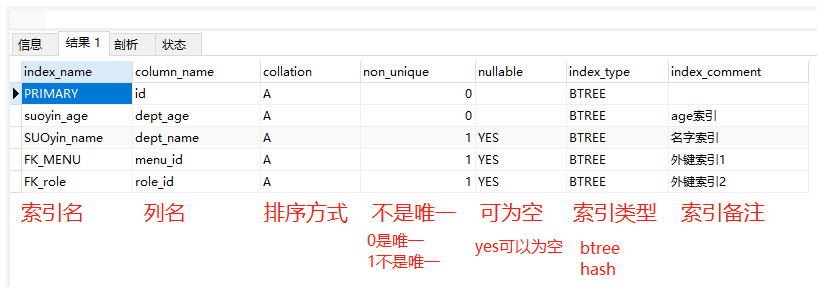
4、获取表的索引
- 根据表名、数据库名
| 数据库种类 | SQL | 备注 |
|---|---|---|
| mysql | SELECT index_name, column_name, COLLATION, non_unique, nullable, index_type, index_comment, table_name FROM information_schema.statistics WHERE table_schema = 'fd' -- 筛选表名,一起查询快些 -- AND table_name = 't_c_my_dept'; |
23.2.3更新 |
| oracle/达梦8 | SELECT t.index_name, t.column_name, t.descend, i.uniqueness, i.compression, i.INDEX_TYPE, i.table_type, t.TABLE_NAME FROM user_ind_columns t, user_indexes i WHERE t.index_name = i.index_name AND t.table_name = i.table_name -- 筛选表,全部查询快些 -- AND t.TABLE_NAME = 'abcdTYB_T_AUTOTB557' |
23.2.3更新 |
mysql
oracle

5、case when then else end
5.1、情况一
测试表:
CREATE TABLE test.cc (
id int PRIMARY key IDENTITY(1,1),
name varchar(255) NULL,
age int NULL,
country varchar(255) NULL
)
需求
需求:
用一句sql查询出一张表中年龄<10和年龄≥10的
【提示:用内联;group by后面括号里面可以写逻辑】
【提示:用case when】

下面是实现sql(两种方式)
-- 1 查询年龄小于10、大于10的人数
select
case
when age > 0 and age < 10 then 'age小于10'
when age >= 10 and age < 20 then 'age大于10'
else '其他'
end as '条件',
count(*) as '人数'
from test.t_user
group by
case
when age > 0 and age < 10 then 'age小于10'
when age >= 10 and age < 20 then 'age大于10'
else '其他'
end;
-- 2 查询中国人、美国人、其他国家人的年龄和(第一种写法)
select sum(age) as '年龄和',
case name
when 'cc' then '中国人'
when 'dd' then '中国人'
when 'ee' then '中国人'
when 'ff' then '美国人'
when 'gg' then '美国人'
when 'hh' then '美国人'
else '其他国家'
end as '国家'
from test.t_user
group by
case name
when 'cc' then '中国人'
when 'dd' then '中国人'
when 'ee' then '中国人'
when 'ff' then '美国人'
when 'gg' then '美国人'
when 'hh' then '美国人'
else '其他国家'
end;
-- 3 查询中国人、美国人、其他国家人的年龄和(第二种写法)
select sum(age) as '年龄和',
case country
when '中国' then '中国人'
when '美国' then '美国人'
else '其他国家'
end as '国家'
from test.t_user
group by
case country
when '中国' then '中国人'
when '美国' then '美国人'
else '其他国家'
end;
5.2、情况二
TD_DI_WORK_TABLE 表中有表名字段 TARGET_TABLE_NAME

TD_DI_WORK_TABLE 中有NODE_ID 与 TD_DI_NODE 关联
- TD_DI_NODE 中有WORK_TYPE类型,表名该表的构建类型
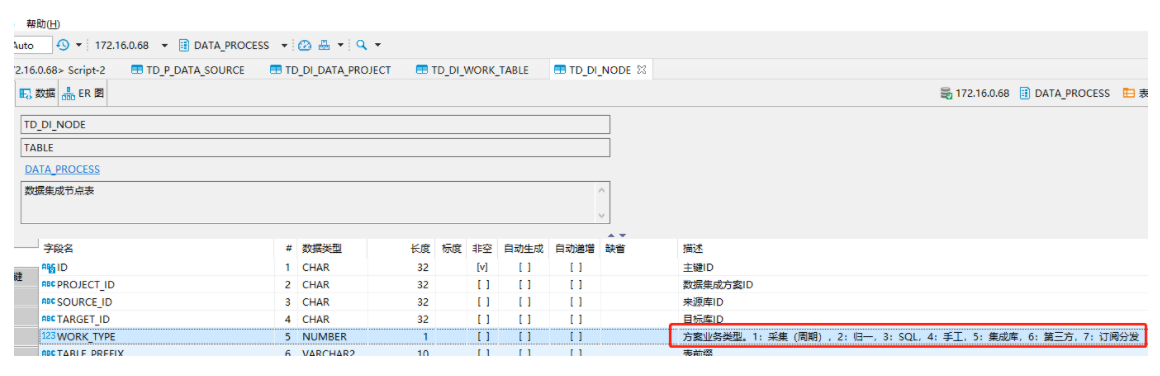
要求:查询出表名+类型,类型需要根据1-7转换为中文:如:a_tree_pid(采集)
- oracle连接字符串:|| 、concat
方式一:
SELECT
wt.TARGET_TABLE_NAME ||
(CASE
dn.WORK_TYPE
WHEN 1 THEN '(采集)'
WHEN 2 THEN '(归一)'
WHEN 7 THEN '(订阅)'
ELSE '(主题)'
END
) AS tableName
FROM
TD_DI_WORK_TABLE AS wt
LEFT JOIN TD_DI_NODE AS dn ON
dn.ID = wt.NODE_ID
方式二:
SELECT
CONCAT(
wt.TARGET_TABLE_NAME,
(CASE
dn.WORK_TYPE
WHEN 1 THEN '(采集)'
WHEN 2 THEN '(归一)'
WHEN 7 THEN '(订阅)'
ELSE '(主题)'
END
)
) AS tableName1
FROM
TD_DI_WORK_TABLE AS wt
LEFT JOIN TD_DI_NODE AS dn ON
dn.ID = wt.NODE_ID
结果:
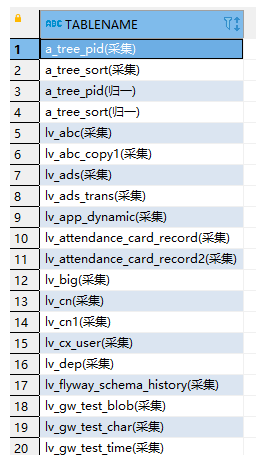
5.3、例子
SELECT
(
CASE
FILE_TYPE
WHEN 1 THEN 'PDF'
WHEN 2 THEN 'picture'
WHEN 3 THEN 'DOC'
WHEN 4 THEN 'EXCEL'
WHEN 5 THEN 'PPT'
WHEN 6 THEN 'audio'
WHEN 7 THEN 'video'
WHEN 8 THEN 'text'
WHEN 9 THEN 'other'
ELSE '其他'
END
) AS AA
FROM
TD_DR_DATA_RESOURCE_STATIC AS drs
6、建表、建注释、建索引
6.1、达梦
1、常用数据类型
| 名称 | 长度(精度) | 精度(标度) | 可做主键 | 可索引 | 默认值 | 备注 |
|---|---|---|---|---|---|---|
| CHAR | 1-8188 | - | true | true | 默认值长度 <= 长度 | |
| VARCHAR2 | 1-8188 | - | true | true | 默认值长度 <= 长度 | |
| NUMBER | 0-38 | 0<=精度<=长度 | true | true | 精度 + 默认值小数点前的长度(喊“-”符号位) <= 长度、必须是数字 | |
| NUMERIC | 0-38 | 0<=精度<=长度 | true | true | 精度 + 默认值小数点前的长度(喊“-”符号位) <= 长度、必须是数字 | |
| DECIMAL | 0-38 | 0<=精度<=长度 | true | true | 精度 + 默认值小数点前的长度(喊“-”符号位) <= 长度、必须是数字 | |
| SMALLINT | 5 | - | true | true | 必须是数字,-32768<=默认值<=32767(Short) | 长度、精度固定 |
| INTEGER | 10 | - | true | true | 必须是数字,-2147483648<=默认值<=2147483647(Integer) | 长度、精度固定 |
| BIGINT | 19 | - | true | true | 必须是数字, -9223372036854775808<=默认值<=9223372036854775807(Long) |
长度、精度固定 |
| DATE | 13 | - | true | true | 可以为:SYSDATE 或 yyyy-MM-dd 格式的时间 | 长度、精度固定 |
| TIME | 22 | 0<=精度<=6 | true | true | 可以为:SYSDATE 或 HH:mm:ss 格式的时间 | 长度固定 |
| TIMESTAMP | 36 | 0<=精度<=6 | true | true | 可以为:SYSDATE 或 yyyy-MM-dd HH:mm:ss 格式的时间 | 长度固定 |
| TEXT | 2147483647 | - | false | false | 文本 | 文本(可用java中的:String接收) |
| BLOB | 2147483647 | - | false | false | 不能设置默认值 | 二进制文件 |
| CLOB | 2147483647 | - | false | false | 不能设置默认值 | 文本(可用java中的:String接收) |
2、规则:表名、字段、注释长度
①、表名、字段名的最大长度 128 字节。
②、注释(表注释、字段注释)字符串最大长度为4000(中文2000)

3、建表sql—创建联合索引
- 联合主键名字:PK_UNION_e25f0721c3fe4a4aa47781606200475f 不能重复,且是随机生成的
CREATE TABLE SUBJECT2."t_name"(
"id" CHAR (10) NOT NULL,
"idd" CHAR (2) NOT NULL,
"VARCHAR21" VARCHAR2 (10) DEFAULT ('-33') ,
"NUMBER1" NUMBER (10,7) DEFAULT ('-45.56565665') ,
"DECIMAL1" DECIMAL (10,7) DEFAULT ('545.56565665') NOT NULL,
"DATE1" DATE DEFAULT (SYSDATE) ,
"time1" TIME (6) DEFAULT (SYSDATE) ,
"Timestamp1" TIMESTAMP (6) DEFAULT (SYSDATE) NOT NULL,
"SMALLINT1" SMALLINT DEFAULT ('11111') NOT NULL,
"NUMERIC1" NUMERIC (11,6) DEFAULT ('11111') NOT NULL,
"INTEGER2" INTEGER DEFAULT ('1111111111') NOT NULL,
"BIGINT2" BIGINT DEFAULT ('1111111111') ,
"TEXT2" TEXT DEFAULT ('的捡垃圾拉法基拉法基垃圾啊独立开发经理就') NOT NULL,
"BLOB2" BLOB,
"CLOB2" CLOB,
CONSTRAINT PK_UNION_e25f0721c3fe4a4aa47781606200475f PRIMARY KEY ( "id",
"idd"))
4、建表sql—创建单个主键
- NOT CLUSTER的使用
CREATE TABLE SUBJECT2."T_DDD"(
"id" CHAR (10) NOT NULL,
not cluster PRIMARY KEY("id"),
"idd" CHAR (2) NOT NULL,
"VARCHAR21" VARCHAR2 (10) DEFAULT ('-33') ,
"NUMBER1" NUMBER (10,7) DEFAULT ('-45.56565665') ,
"DECIMAL1" DECIMAL (10,7) DEFAULT ('545.56565665') NOT NULL,
"DATE1" DATE DEFAULT (SYSDATE) ,
"time1" TIME (6) DEFAULT (SYSDATE) ,
"Timestamp1" TIMESTAMP (6) DEFAULT (SYSDATE) NOT NULL,
"SMALLINT1" SMALLINT DEFAULT ('11111') NOT NULL,
"NUMERIC1" NUMERIC (11,6) DEFAULT ('11111') NOT NULL,
"INTEGER2" INTEGER DEFAULT ('1111111111') NOT NULL,
"BIGINT2" BIGINT DEFAULT ('1111111111') ,
"TEXT2" TEXT DEFAULT ('的捡垃圾拉法基拉法基垃圾啊独立开发经理就') NOT NULL,
"BLOB2" BLOB,
"CLOB2" CLOB
)
-
指明 CLUSTER(默认是聚集索引),表明是主关键字上聚集索引;
- 聚集索引,是不能修改字段信息的
-
指明 NOT CLUSTER,表明是主关键字上非聚集索引;
- 一般用这个
5、建注释sql
- 注释字符串最大长度为4000
-表注释
comment on table "SUBJECT2"."T_DDD" is '备注注111';
-字段注释
comment on column "SUBJECT2"."T_DDD"."VARCHAR21" is '注释';
6、判断表是否存在
select * from user_tables where table_name = '表名'
7、创建索引——联合索引
create index "SUBJECT2"."索引名字" on "SUBJECT2"."T_DDD2"("idd","VARCHAR21","DECIMAL1","time1","INTEGER2")
8、创建索引——单个索引
create index "SUBJECT2"."索引名字" on "SUBJECT2"."T_DDD"("idd")
- 简约
create index "索引名字" on "T_DDD"("idd")
9、只查询表结构
SELECT * FROM TD_DI_NODE WHERE 1=0
10、Java构建SQL
1、判断参数工具类
public class Verify {
/** 字段类型判断:判断字段是否符合达梦建表要求
* @Description
* char、varchar2 ①不能设置精度 ②最大长度 1-8188 ③设置了默认值:默认值长度 <= 长度 (一个中文占两个长度)
* number、numeric、decimal:①精度(>=0) <= ②长度(0-38) ③设置了默认值:精度+默认值小数点前的长度 <= 长度
* smallint、integer、bigint:①不能设置长度、精度 ②默认值可以为小数,下面的范围是指小数点前面的数
* 默认值范围:-32768<=smallint<=32767 -2147483648<=integer<=2147483647
* 默认值范围:-9223372036854775808<=bigint<=9223372036854775807
* smallint、int、integer、bigint、number、numeric、decimal :①必须是数字(整数、小数)
* text:①不能设置长度、精度 ②不能设置主键、不能设置索引
* blob、clob:①不能设置长度、精度 ②不能设置默认值 ③不能设主键、不能建索引
* date:①不能设置长度、精度 ②时间格式:yyyy-MM-dd ④默认值还可以为:SYSDATE
* time:①不能设置长度 ②时间格式:HH:mm:ss ③可以设置精度(>=0 且 <=6) ④默认值还可以为:SYSDATE
* timestamp:①不能设置长度 ②时间格式:yyyy-MM-dd HH:mm:ss ③可以设置精度(>=0 且 <=6) ④默认值还可以为:SYSDATE
* @Author CC
* @Date 2021/11/9
* @Param [fieldName字段名字, fieldType字段类型, length字段长度,
* precision字段精度, defaultValue默认值]
* @return void
**/
public static void verDmFieldType(String fieldName, String fieldType,
Integer length, Integer precision,
String defaultValue,Integer isIndex,
Integer isPk
) {
Assert.isTrue(Constants.DM_FIELD_ALL.contains(fieldType), String.format("字段%s:类型不对!",fieldName));
//默认值长度
int defLen = StringUtils.isNotBlank(defaultValue) ? defaultValue.length() : 0;
int chineseNum = RegularVer.chineseNum(defaultValue);
defLen = chineseNum == 0 ? defLen : (defLen-chineseNum) + chineseNum * 2;
//判断1
if (Constants.DM_FIELD_CHAR.contains(fieldType)){
Assert.isTrue(length>=1 && length<=8188,
String.format("字段(%s):长度只能是1-8188",fieldName));
Assert.isTrue(defLen <= length,
String.format("字段(%s):默认值长度必须小于设置长度(一个中文占两个长度)",fieldName));
}
if (Constants.DM_FIELD_NUM_ALL.contains(fieldType) && StringUtils.isNotBlank(defaultValue)){
Assert.isTrue(RegularVer.isNumber(defaultValue),
String.format("字段(%s):默认值必须是纯数字",fieldName));
String front = defaultValue.split("\\.")[0];
if (DmFieldEnums.SMALLINT.getName().equals(fieldType)){
String min = String.valueOf(Short.MIN_VALUE);
String max = String.valueOf(Short.MAX_VALUE);
Assert.isTrue(Verify.verNumInMinMax(front, min, max),
String.format("字段(%s):默认值小数点前数字必须大于等于%s,且小于等于%s",fieldName,min,max));
}
if (DmFieldEnums.INTEGER.getName().equals(fieldType)){
String min = String.valueOf(Integer.MIN_VALUE);
String max = String.valueOf(Integer.MAX_VALUE);
Assert.isTrue(Verify.verNumInMinMax(front, min, max),
String.format("字段(%s):默认值小数点前数字必须大于等于%s,且小于等于%s",fieldName,min,max));
}
if (DmFieldEnums.BIGINT.getName().equals(fieldType)){
String min = String.valueOf(Long.MIN_VALUE);
String max = String.valueOf(Long.MAX_VALUE);
Assert.isTrue(Verify.verNumInMinMax(front, min, max),
String.format("字段(%s):默认值小数点前数字必须大于等于%s,且小于等于%s",fieldName,min,max));
}
}
if (Constants.DM_FIELD_NUM.contains(fieldType)){
Assert.isTrue(precision <= length,
String.format("字段(%s):精度必须小于设置长度",fieldName));
if (StringUtils.isNotBlank(defaultValue)){
String[] split = defaultValue.split("\\.");
Assert.isTrue(precision + split[0].length() <= length,
String.format("字段(%s):精度+默认值小数点前的长度 必须不大于 设置长度",fieldName));
}
}
if(StringUtils.isNotBlank(defaultValue)){
if (DmFieldEnums.DATE.getName().equals(fieldType) && !Constants.SYSDATE.equals(defaultValue)) {
Assert.isTrue(RegularVer.isValidDate(defaultValue),
String.format("字段(%s):默认值不是指定时间格式(yyyy-MM-dd)",fieldName));
}
if (DmFieldEnums.TIME.getName().equals(fieldType) && !Constants.SYSDATE.equals(defaultValue)) {
Assert.isTrue(RegularVer.isValidTime(defaultValue),
String.format("字段(%s):默认值不是指定时间格式(HH:mm:ss)",fieldName));
}
if (DmFieldEnums.TIMESTAMP.getName().equals(fieldType) && !Constants.SYSDATE.equals(defaultValue)) {
Assert.isTrue(RegularVer.isValidTimestamp(defaultValue),
String.format("字段(%s):默认值不是指定时间格式(yyyy-MM-dd HH:mm:ss)",fieldName));
}
}
if (fieldType.contains(DmFieldEnums.TIME.getName())){
Assert.isTrue(precision <= 6,
String.format("字段(%s):精度只能是0-6之间",fieldName));
}
if (fieldType.contains(Constants.LOB) || fieldType.contains(DmFieldEnums.TEXT.getName())){
Assert.isTrue(isIndex == 0,
String.format("字段(%s):不能设置索引",fieldName));
Assert.isTrue(isPk == 0,
String.format("字段(%s):不能设置为主键",fieldName));
}
if (fieldType.contains(Constants.LOB)) {
Assert.isNull(length,String.format("字段%s:长度必须为空",fieldName));
Assert.isNull(precision,String.format("字段%s:精度必须为空",fieldName));
Assert.isNull(defaultValue,String.format("字段%s:默认值必须为空",fieldName));
} else if (fieldType.contains(DmFieldEnums.TEXT.getName()) ) {
Assert.isNull(length,String.format("字段%s:长度必须为空",fieldName));
Assert.isNull(precision,String.format("字段%s:精度必须为空",fieldName));
} else if (fieldType.contains(Constants.INT)) {
Assert.isNull(length,String.format("字段%s:长度必须为空",fieldName));
Assert.isNull(precision,String.format("字段%s:精度必须为空",fieldName));
} else if (fieldType.contains(DmFieldEnums.TIME.getName())) {
Assert.isNull(length,String.format("字段%s:长度必须为空",fieldName));
}else if (fieldType.contains(DmFieldEnums.CHAR.getName())) {
Assert.isNull(precision,String.format("字段%s:精度必须为空",fieldName));
}else if (fieldType.contains(DmFieldEnums.DATE.getName())) {
Assert.isNull(length,String.format("字段%s:长度必须为空",fieldName));
Assert.isNull(precision,String.format("字段%s:精度必须为空",fieldName));
}
}
/** 判断数字num在min和max之间:min <= num <= max
* @Description
* num在min和max之间返回true,反之false
* @Author CC
* @Date 2021/11/11
* @Param [defDec, min, max]
* @return boolean
**/
public static boolean verNumInMinMax(String num, String min, String max) {
Assert.isTrue(RegularVer.isNumber(num),String.format("%s,不是纯数字!",num));
Assert.isTrue(RegularVer.isNumber(min),String.format("%s,不是纯数字!",min));
Assert.isTrue(RegularVer.isNumber(max),String.format("%s,不是纯数字!",max));
BigDecimal defDec = new BigDecimal(num);
return defDec.compareTo(new BigDecimal(min)) > -1 && defDec.compareTo(new BigDecimal(max)) < 1;
}
}
常量类
@Data
public class Constants {
public static final List<String> DM_FIELD_ALL =
Lists.newArrayList(
DmFieldEnums.CHAR.getName(),
DmFieldEnums.VARCHAR2.getName(),
DmFieldEnums.NUMERIC.getName(),
DmFieldEnums.DECIMAL.getName(),
DmFieldEnums.NUMBER.getName(),
DmFieldEnums.INTEGER.getName(),
DmFieldEnums.BIGINT.getName(),
DmFieldEnums.SMALLINT.getName(),
DmFieldEnums.DATE.getName(),
DmFieldEnums.TIME.getName(),
DmFieldEnums.TIMESTAMP.getName(),
DmFieldEnums.TEXT.getName(),
DmFieldEnums.BLOB.getName(),
DmFieldEnums.CLOB.getName()
);
public static final List<String> DM_FIELD_NUM_ALL =
Lists.newArrayList(
DmFieldEnums.SMALLINT.getName(),
DmFieldEnums.INTEGER.getName(),
DmFieldEnums.BIGINT.getName(),
DmFieldEnums.NUMBER.getName(),
DmFieldEnums.NUMERIC.getName(),
DmFieldEnums.DECIMAL.getName()
);
public static final List<String> DM_FIELD_NUM =
Lists.newArrayList(
DmFieldEnums.NUMBER.getName(),
DmFieldEnums.NUMERIC.getName(),
DmFieldEnums.DECIMAL.getName()
);
public static final List<String> DM_FIELD_INT =
Lists.newArrayList(
DmFieldEnums.SMALLINT.getName(),
DmFieldEnums.INTEGER.getName(),
DmFieldEnums.BIGINT.getName()
);
public static final List<String> DM_FIELD_CHAR =
Lists.newArrayList(
DmFieldEnums.CHAR.getName(),
DmFieldEnums.VARCHAR2.getName()
);
public static final String LOB = "LOB";
public static final String TEXT = "TEXT";
public static final String INT = "INT";
public static final String SYSDATE = "SYSDATE";
}
枚举类
/** 达梦字段类型,数据字典类型A11
* @Description
* @Author CC
* @Date 2021/11/9
* @Version 1.0
*/
public enum DmFieldEnums {
//达梦字段类型
CHAR("CHAR","A1101"),
VARCHAR2("VARCHAR2","A1102"),
NUMERIC("NUMERIC","A1103"),
DECIMAL("DECIMAL","A1104"),
NUMBER("NUMBER","A1105"),
INTEGER("INTEGER","A1106"),
BIGINT("BIGINT","A1107"),
SMALLINT("SMALLINT","A1108"),
DATE("DATE","A1109"),
TIME("TIME","A1110"),
TIMESTAMP("TIMESTAMP","A1111"),
TEXT("TEXT","A1112"),
BLOB("BLOB","A1113"),
CLOB("CLOB","A1114")
;
DmFieldEnums(String name, String code) {
this.name = name;
this.code = code;
}
DmFieldEnums() {
}
private String name;
private String code;
//getter/setter……
}
2、表信息实体类
@Data
public class TableEntity implements Serializable {
private static final long serialVersionUID = -3523824212672386937L;
private String name;//表名
private String alias;//表别名
private String schmeName;// 库名
private List<ColumnEntity> columnEntities;//字段信息
}
@Data
public class ColumnEntity {
private String tableName;
private String name;//字段名
private String alias;//字段别名
private String type;//字段类型
private Integer length;//字段长度
private Integer precision;//字段精度
private String defaultValue;//默认值
private Integer isNull;//是否可以为空 0:不能为空,1:可为空。
private Integer isKey = 0;//是否主键 0:否1:是
private String describe; //字段描述
}
3、判断表是否存在、删除表、创建表—SQL
public class CreateTableSql {
public static final String ORACLE = "oracle";
public static final String MYSQL = "mysql";
public static final String KINGBASE = "kingbase";
public static final String DM = "dm";
/**封装查询表是否存在的sql
* @param type 数据库类型 mysql oracle dm kingbase
* @param tableName 表名
* @return 查询sql
*/
public static String getIsExistTableSql(String type, String tableName) {
String sql = "";
switch (type) {
case ORACLE:
StringBuffer oracleQueryTable = new StringBuffer().append("select table_name from tabs where table_name ='").append(tableName).append("'");
sql = oracleQueryTable.toString();
break;
case MYSQL:
StringBuffer mysqlQueryTable = new StringBuffer().append("show tables like '").append(tableName).append("'");
sql = mysqlQueryTable.toString();
break;
case KINGBASE:
StringBuffer kingbaseQueryTable = new StringBuffer().append("select * from SYS_TABLES where tablename = '").append(tableName.toUpperCase()).append("'");
sql = kingbaseQueryTable.toString();
break;
case DM:
StringBuffer dmQueryTable = new StringBuffer().append("select * from user_tables where table_name ='").append(tableName).append("'");
sql = dmQueryTable.toString();
break;
default:throw new QzBizException("类型只能是:oracle、mysql、dm、kingbase");
}
return sql;
}
/** 删除表
* @param type 类型:oracle、dm
* @param tableName 表名
* @return 删除sql
**/
public static String dropTable(String type, String tableName) {
String sql = "";
switch (type) {
case ORACLE:
StringBuffer oracleQueryTable = new StringBuffer().append("drop table \"").append(tableName).append("\"");
sql = oracleQueryTable.toString();
break;
case DM:
StringBuffer dmQueryTable = new StringBuffer().append("DROP TABLE \"").append(tableName).append("\"");
sql = dmQueryTable.toString();
break;
default:break;
}
return sql;
}
/**
* 达梦 建表语句
* char、varchar2 ①不能设置精度 ②最大长度 1-8188 ③设置了默认值:默认值长度 <= 长度 (一个中文占两个长度)
* number、numeric、decimal:①精度(>=0) <= ②长度(0-38) ③设置了默认值:精度+默认值小数点前的长度 <= 长度
* smallint、int、integer、bigint:①不能设置长度、精度 ②默认值长度 <= 5、10、10、19
* smallint、int、integer、bigint、number、numeric、decimal :①必须是数字(整数、小数)
* text:①不能设置长度、精度 ②不能设置主键、不能设置索引
* blob、clob:①不能设置长度、精度 ②不能设置默认值 ③不能设主键、不能建索引
* date:①不能设置长度、精度 ②时间格式:yyyy-MM-dd ④默认值还可以为:SYSDATE
* time:①不能设置长度 ②时间格式:HH:mm:ss ③可以设置精度(>=0 且 <=6) ④默认值还可以为:SYSDATE
* timestamp:①不能设置长度 ②时间格式:yyyy-MM-dd HH:mm:ss ③可以设置精度(>=0 且 <=6) ④默认值还可以为:SYSDATE
*/
public static String sqlCreateTableDM(TableEntity tableEntity) {
StringBuffer creatTable = new StringBuffer().append("create table ");
if (StringUtils.isNotEmpty(tableEntity.getSchmeName())) {
creatTable.append(tableEntity.getSchmeName()).append(".");
}
creatTable.append("\"").append(tableEntity.getName()).append("\"(");
//主键字段
List<ColumnEntity> keyColumnList = tableEntity.getColumnEntities().stream().filter(e -> e.getIsKey() != null &&
e.getIsKey().equals(1)).collect(Collectors.toList());
//是否设置联合主键
boolean isUnionKey = false;
//主键字段个数大于1,则设置联合主键
if (!CollectionUtils.isEmpty(keyColumnList) && keyColumnList.size() > 1) {
isUnionKey = true;
}
for (int i = 0; i < tableEntity.getColumnEntities().size(); i++) {
ColumnEntity columnEntity = tableEntity.getColumnEntities().get(i);
String type = columnEntity.getType().toUpperCase();
String columnName = "\"" + columnEntity.getName() + "\"";
creatTable.append(columnName).append(" ");
if (type.contains("CLOB") || type.contains("BLOB")) {
columnEntity.setLength(null);
columnEntity.setPrecision(null);
columnEntity.setDefaultValue(null);
} else if (type.contains("TEXT") ) {
columnEntity.setLength(null);
columnEntity.setPrecision(null);
} else if (type.contains("INT")) {
columnEntity.setLength(null);
columnEntity.setPrecision(null);
} else if (type.contains("TIME")) {
columnEntity.setLength(null);
}else if (type.contains("CHAR")) {
columnEntity.setPrecision(null);
}else if (type.contains("DATE")) {
columnEntity.setLength(null);
columnEntity.setPrecision(null);
}
creatTable.append(type);
String defaultValue = columnEntity.getDefaultValue();
Integer precision = columnEntity.getPrecision();
//有长度、不是date、也不是time类型
if (columnEntity.getLength() != null && columnEntity.getLength() != 0 &&
!type.contains("DATE") && !type.contains("TIME") && !type.contains("INT")
) {
creatTable.append(" (").append(columnEntity.getLength());
if ((type.contains("DECIMAL") || type.contains("NUM")
) && Objects.nonNull(precision) && 0 != precision) {
creatTable.append(",").append(precision);
}
creatTable.append(")");
}
if (type.contains("TIME") && Objects.nonNull(precision) && 0 != precision){
creatTable.append(" (").append(precision).append(") ");
}
if (StringUtils.isNotBlank(defaultValue)) {
if (type.contains("TIME") || type.contains("DATE")){
creatTable.append(" DEFAULT (").append(defaultValue).append(") ");
}else {
creatTable.append(" DEFAULT ('").append(defaultValue).append("') ");
}
}
//不能为空
if (columnEntity.getIsNull() != null && 0 == columnEntity.getIsNull()) {
creatTable.append(" not null");
}
if (columnEntity.getIsKey() != null && 1 == columnEntity.getIsKey() && !isUnionKey) {
creatTable.append(", primary key(").append(columnName).append(")");
}
if (i == (tableEntity.getColumnEntities().size() - 1)) {
//需要设置联合主键
if (isUnionKey) {
// creatTable.append(",CONSTRAINT PK_UNION PRIMARY KEY (");
creatTable.append(",CONSTRAINT ");
creatTable.append(" PK_UNION").append("_").append(UUIDGeneratorUtil.generate());
creatTable.append(" PRIMARY KEY ( ");
for (ColumnEntity c : keyColumnList) {
creatTable.append("\"").append(c.getName()).append("\",");
}
//去掉最后一个逗号
creatTable.deleteCharAt(creatTable.length() - 1);
creatTable.append(")");
}
creatTable.append(")");
} else {
creatTable.append(",");
}
}
return creatTable.toString();
}
4、创建表注释、字段注释—SQL
java实现sql
/**设置表注释sql
* @param serviceName 数据库名(dm:模式名)
* @param tableName 表名
* @param remark 注释
* @return 构造sql
* @author CC
*/
public static String setTableRemarkSql(String serviceName,String tableName, String remark) {
remark = remark == null ? "''" : "'" + remark + "'";
StringBuilder sb = new StringBuilder();
sb.append("comment on table ");
if (StringUtils.isNotBlank(serviceName)){
sb.append("\"").append(serviceName).append("\".");
}
sb.append("\"").append(tableName).append("\"");
sb.append(" is ").append(remark);
return sb.toString();
}
/**设置字段注释sql
* @param serviceName 数据库名(dm:模式名)
* @param tableName 表名
* @param fieldName 字段名称
* @param remarks 注释
* @return 构造sql
* @author gw
*/
public static String setFieldRemarksSql(String serviceName,String tableName, String fieldName, String remarks) {
remarks = remarks == null ? "''" : "'" + remarks + "'";
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("comment on column ");
if (StringUtils.isNotBlank(serviceName)){
stringBuilder.append("\"").append(serviceName).append("\".");
}
stringBuilder.append("\"").append(tableName).append("\".");
stringBuilder.append("\"").append(fieldName).append("\"");
stringBuilder.append(" is ").append(remarks);
return stringBuilder.toString();
}
5、创建联合索引—SQL
java实现sql
/**
* 表字段创建索引
*
* @param tableName 表名
* @param indexFieldIdList 设置了索引的字段集合
* @return 构造sql
* @author gw
*/
public static String createTableIndexSql(String tableName, List<String> indexFieldIdList) {
String indexName = tableName.toUpperCase() + "_INDEX";
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("create index ").append(indexName);
stringBuilder.append(" on ").append("\"").append(tableName).append("\"(");
for (String field : indexFieldIdList) {
stringBuilder.append("\"").append(field).append("\",");
}
//去掉最后一个逗号
stringBuilder.deleteCharAt(stringBuilder.length() - 1);
stringBuilder.append(")");
return stringBuilder.toString();
}
7、分页
7.1、Oracle
方式一(推荐)
- (效率高、可写where、order by)
-- page :第几页
-- pageSize :每页条数
-- end = page*pageSize
-- start = end-pageSize+1
-- 例如:
-- page pageSize end-pageSize+1 page*pageSize
-- 1 2 start=1 end=2
-- 2 2 start=3 end=4
-- 3 2 start=5 end=6
-- 1 3 start=1 end=3
-- 2 3 start=4 end=6
-- 2 4 start=5 end=8
SELECT
*
FROM
(
SELECT
a.*,
ROWNUM rn
FROM
(
SELECT
*
FROM
SUBJECT2.EEE_EEE AS e
) a
WHERE
ROWNUM <= end
) AS rn
WHERE
rn >= start
- 写where、order
SELECT
*
FROM
(
SELECT
a.*,
ROWNUM rn
FROM
(
SELECT
*
FROM
SUBJECT2.EEE_EEE AS e
WHERE e."AREA_ORIGIN_ID" IN (22,33,44,55,66,77)
ORDER BY e."AREA_ORIGIN_ID" DESC
) a
WHERE
ROWNUM <= end
) AS rn
WHERE
rn >= start
方式二
- 不能写where、order
-- endNum = page*pageSize
-- startNum = endNum-pageSize
-- 分页查询 page:第1页,pageSize:每页2条数据 endNum=2 startNum=0
-- 分页查询 page:第2页,pageSize:每页2条数据 endNum=4 startNum=2
-- 分页查询 page:第3页,pageSize:每页1条数据 endNum=3 startNum=2
-- 分页查询 page:第3页,pageSize:每页2条数据 endNum=6 startNum=4
-- 分页查询 page:第1页,pageSize:每页4条数据 endNum=4 startNum=0
SELECT
*
FROM
(
SELECT
ROWNUM AS rnum,
e.*
FROM
SUBJECT2."EEE_EEE" AS e
WHERE
ROWNUM <= endNum
) AS re
WHERE
re.rnum > startNum;
有字段:
SELECT
*
FROM
(
SELECT
ROWNUM AS rowno,
"AREA_ORIGIN_ID",
"Province",
"City",
"AREA_ORIGIN_NAME",
"MEMONIC",
"Remark",
"rrrr"
FROM
SUBJECT2."EEE_EEE" AS e
WHERE
ROWNUM <= endNum
) as rn
WHERE
rn.rowno > startNum
错误写法:
SELECT
*
FROM
(
SELECT
ROWNUM AS rnum,
e.*
FROM
SUBJECT2.EEE_EEE AS e
WHERE
ROWNUM <= 4
AND e."AREA_ORIGIN_ID" IN (22,33,44,55,66,77)
ORDER BY e."AREA_ORIGIN_ID" DESC
) AS re
WHERE
re.rnum > 0;
7.2、Mysql
-- page pageSize start end
-- - - (page-1)*pageSize pageSize
-- 1 2 0 2
-- 2 2 2 2
-- 3 3 6 3
SELECT
*
FROM
trg
limit start,end
SELECT
*
FROM
trg
limit (page-1)*pageSize,pageSize
- 写where、order by
SELECT
*
FROM
trg
WHERE
id IN ( 10, 11, 12, 13, 14 )
ORDER BY id DESC
LIMIT start,end
7.3、达梦
- Oracle、Mysql的方式都可以用(推荐用Mysql的limit方式)
8、连接字符串(concat)
8.1、oracle、达梦
① ||
- 不推荐,其他数据库不支持
SELECT 'q'||'w'||'e'||'r' AS str
结果:qwer
SELECT 'q'||'w'||null||'r' AS str
结果:qwr
② concat
- 推荐
SELECT CONCAT('q','w','e','r') AS str
结果:qwer
SELECT CONCAT('q','w',null,'r') AS str
结果:qwr
③ CONCAT_WS :连接字符串
SELECT CONCAT_WS('-','w','e','r') AS str
结果:w-e-r
SELECT CONCAT_WS('-','w',NULL,'r') AS str
结果:w--r
- 在oracle中,null也被当做一个字符串
8.2、mysql
①concat
CONCAT(str1,str2,…)
返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。
select concat('c','d','f');
结果:cdf
②拼接字符串并连接
CONCAT_WS(separator,str1,str2,...)
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。
select concat_ws('-','11','22','33');
结果:11-22-33
③字符串中有null值
- concat
select concat('c','d',null);
结果:null
- concat_ws
select concat_ws('-',null,'22','33');
结果:22-33
9、Oracle的函数
9.1、TO_CHAR(格式化时间)
-
TO_CHAR 把日期或数字转换为字符串
-
获取系统日期: SYSDATE
格式化日期:
TO_CHAR(SYSDATE, 'YY/MM/DD HH24:MI:SS)
或 TO_DATE(SYSDATE, 'YY/MM/DD HH24:MI:SS)
格式化数字: TO_NUMBER -
TO_CHAR(number, '格式')
TO_CHAR(salary, '$99,999.99')
TO_CHAR(date, '格式')
日期:
12小时制:
SELECT TO_CHAR(SYSDATE() ,'yyyy-MM-dd HH:MI:SS')
结果:2021-12-14 05:22:42
24小时制:
SELECT TO_CHAR(SYSDATE() ,'yyyy-MM-dd HH24:MI:SS')
结果:2021-12-14 17:16:43
转换的格式:
表示 year 的: y 表示年的最后一位 、
yy 表示年的最后2位 、
yyy 表示年的最后3位 、
yyyy 用4位数表示年
表示month的: mm 用2位数字表示月 、
mon 用简写形式, 比如11月或者nov 、
month 用全称, 比如11月或者november
表示day的: dd 表示当月第几天 、
ddd 表示当年第几天 、
dy 当周第几天,简写, 比如星期五或者fri 、
day 当周第几天,全称, 比如星期五或者friday
表示hour的: hh 2位数表示小时 12进制 、
hh24 2位数表示小时 24小时
表示minute的:mi 2位数表示分钟
表示second的:ss 2位数表示秒 60进制
表示季度的:q 一位数 表示季度 (1-4)
另外还有ww 用来表示当年第几周 w用来表示当月第几周。
24小时制下的时间范围:00:00:00-23:59:59
12小时制下的时间范围:1:00:00-12:59:59
9.2、TO_NUMBER
格式
数字格式: 9 代表一个数字
0 强制显示0
$ 放置一个$符
L 放置一个浮动本地货币符
. 显示小数点
, 显示千位指示符
截取两位小数(trunc)
select trunc(to_number('1.1271113'),2);
9.3、NVL(返回非null的值)
- 从两个表达式返回一个非 null 值。
- 语法:NVL(A, B)
如果A为null,则返回B,否则返回A。
例如NVL(A,0),如果A为null,返回0。
SELECT NVL(1,null)
结果:1
SELECT NVL(null,2)
结果:2
9.4、连接字符串|| 和 concat 见8.1
10、drop-删除表
10.1、oracle、dm
- 级联删除
drop table "SYSDBA"."TABLE_NAME" cascade;
- 普通删除
drop table "SUBJECT_CS"."A_by" restrict;
11、UNION ALL 连表
- 问题:A一张表有字段Z,B表没有字段Z,是否可以连表?
- 答案:可以的。B表连表,对应字段Z时,用 null 或者 '' 表示
如下:是 "TYPE" 字段第二张表没有。用 '3' 来表示
SELECT
drs.ID,drs.RESOURCE_ID,drs."TYPE"
,drs.CREATOR_ID,drs.CREATOR_NAME ,drs.ORG_ID ,drs.CREATE_TIME
FROM TD_DR_DATA_RESOURCE_STATISTICS AS drs
WHERE RESOURCE_ID = 'fc937912543b49bca9f54ae18eb568e9'
UNION ALL
SELECT
urc.ID,urc.RESOURCE_ID,'3' AS "TYPE"
,urc.CREATOR_ID,urc.CREATOR_NAME ,urc.ORG_ID ,urc.CREATE_TIME
FROM TD_PORTAL_USER_RESOURCE_COLLECT AS urc
WHERE RESOURCE_ID = 'fc937912543b49bca9f54ae18eb568e9'
UNION ALL:合并重复的行
UNION:不合并重复的行
12、递归查询数据(树结构)-达梦、oracle
学习网址:https://blog.csdn.net/wang_yunj/article/details/51040029/
12.1、语法:
select * from table [start with condition1] connect by [prior] id=parentid

12.2、示例:
12.2.1、指定根节点查找叶子节点(↓)
示例:
select t.*, level, CONNECT_BY_ROOT(id)
from tab_test t
start with t.id = 0
connect by prior t.id = t.fid;

12.2.2、从叶子节点查找上层节点(↑)
示例:
--第一种,修改prior关键字位置
select t.*, level, CONNECT_BY_ROOT(id)
from tab_test t
start with t.id = 4
connect by t.id = prior t.fid;
--第二种,prior关键字不动 调换后面的id=fid逻辑关系的顺序
select t.*, level, CONNECT_BY_ROOT(id)
from tab_test t
start with t.id = 4
connect by prior t.fid = t.id;

12.3、我的示例sql
SELECT
t.*,
LEVEL,
CONNECT_BY_ROOT(ID)
FROM
TD_SYS_POINT AS t
START WITH
t.ID = #{id}
CONNECT BY PRIOR t.ID = t.P_ID;
13、开启、关闭数据库主外键
13.1、达梦
-- 1开启、0关闭
call "dmcompare"."FOREIGN_KEY_CHECKS"(1,'T_DATA_PROCESS','T_DATA_PROCESS');
13.2、mysql
13.3、oracle
- 达梦应该和oracle一样
14、清空表中的数据(TRUNCATE)
TRUNCATE TABLE "TD_SYS_USER_ORG";
15、生成32位字符串
15.1、达梦、oracle
函数:sys_guid()、newid()
select rawtohex(sys_guid());
-- 推荐使用newid()
select REPLACE(newid(),'-','');
16、边查询边插入
insert into TD_SYS_USER_ORG
(ID,USER_ID,ORG_ID,ORG_TYPE)
(
select
rawtohex(sys_guid()),
ID,
ORG_ID,
2
from TD_SYS_USER
);
- select 查询出来的是列表
17、替换字符串
17.1、oracle、达梦
一、replce方法
用法1:REPLACE(sourceStr, searchStr, replacedStr)
sourceStr标识要被替换的字段名或字符串,searchStr表示要被替换掉的字符串,replacedStr表示要替换成的字符串。
用法2:REPLACE(sourceStr, searchStr)
sourceStr标识要被替换的字段名或字符串,searchStr表示要被剔除掉的字符串。
如:
select REPLACE(newid(),'-','');
18、查询数据库所有对象
18.1、oracle、dm
- ALL_OBJECTS 表
- 数据库所有对象表:包括表、视图、物化视图、函数……等
-- 查询所有对象
SELECT * from ALL_OBJECTS
-- 筛选条件 - OWENR:哪个数据库。- OBJECT_TYPE 类型:
SELECT OBJECT_NAME,OBJECT_TYPE from ALL_OBJECTS
WHERE OWNER = 'MIDDLE' AND OBJECT_TYPE = 'MATERIALIZED VIEW'
查询(当前用户的)物化视图(USER_MVIEWS):
SELECT MVIEW_NAME,REFRESH_METHOD FROM USER_MVIEWS
-- oracle的
-- 整个数据库的物化视图
select * from DBA_MVIEWS where OWNER = 'MIDDLE'
-- 当前用户的物化视图
SELECT * FROM USER_MVIEWS WHERE MVIEW_NAME = 'V2'
-- 创建物化日志
create materialized view log on "Z_ZZX" with rowid, sequence (ID_CPM_JH, CODE) including new values;
-- 查询物化视图的日志
select * from MLOG$_Z_ZZX
-- 查询物化视图日志表
SELECT * from ALL_OBJECTS WHERE OWNER = 'MIDDLE' and OBJECT_NAME LIKE '%MLOG$%'
-- 查询物化视图
SELECT * from ALL_OBJECTS
WHERE OWNER = 'MIDDLE' AND OBJECT_TYPE = 'MATERIALIZED VIEW'
-- 查询物化视图需要的表
select REFERENCED_NAME from ALL_DEPENDENCIES WHERE OWNER = 'MIDDLE' AND TYPE = 'MATERIALIZED VIEW' AND NAME = 'WH_LOG' AND REFERENCED_NAME <> 'WH_LOG'
-- 连表查询
SELECT * FROM user_mviews um left join SYS.ALL_DEPENDENCIES ad on ad.NAME = um.MVIEW_NAME WHERE ad.OWNER = 'MIDDLE' AND ad.TYPE = 'MATERIALIZED VIEW' AND ad.NAME = 'WH_LOG' AND ad.REFERENCED_NAME <> 'WH_LOG'
-- 获取DDL语句(根据不同类型)
SELECT dbms_metadata.get_ddl('MATERIALIZED_VIEW','WH_LOG') FROM DUAL
-- 获取DDL-物化视图日志
SELECT dbms_metadata.get_ddl('TABLE','MLOG$_Z_ZZX') FROM DUAL
-- 获取DDL-物化视图
SELECT dbms_metadata.get_ddl('MATERIALIZED_VIEW','CS_COMMIT_COMPLETE') FROM DUAL
SELECT dbms_metadata.get_ddl('MATERIALIZED_VIEW_LOG','MLOG$_Z_ZZX') FROM DUAL
-- 获取DDL-视图
SELECT dbms_metadata.get_ddl('VIEW','V1') FROM DUAL
19、获取两个表中差异数据:minus(减法)
-
mysql没有。需要用别的方式替换
-
表结构必须一致,数据也必须一致才能减去
-
真实意思:T_1中的数据减去T_2中的数据。返回还多余的数据
-
相当于 3-2=1、3-0=3。这个例子中的0、1、2、3表示的是一行一行的数据
SELECT * from T_1
minus
SELECT * from T_2