Data Manipulation Language(DML 数据操作语言),如:对表中的记录操作增删改
Data Query Language(DQL 数据查询语言),如:对表中的查询操作
Data Control Language(DCL 数据控制语言),如:对用户权限的设置
DDL:操作数据库和表
操作数据库
CRUD
C: 创建
创建数据库:create database 数据库名称;
创建数据库前判断是否存在,如果存在就不创建,不存在再创建:create database if not exists 数据库名称;
创建数据库时设置字符集:create database 数据库名称 character set gbk;
创建数据库前判断是否存在并设置字符集:create database if not EXISTS db1 CHARACTER set gbk;
#语法:update 表名 set 列名1 = 值1,列名2 = 值2,……[where 条件];
UPDATE stu1 set name = "马保国666" where id = 3;
#注意
#如果不加条件,则会将表中所有记录全部修改
DQL:查询表中的数据
#语法
select
字段列表
from
表名列表
where
条件列表
group by
分组字段
having
分组之后的条件
order by
排序
limit
分页限定
基础查询
多个字段的查询
去除重复
计算列
起别名
多个字段的查询
# 查询所有字段 语法:select * from 表名
select * from student;
#多个字段查询,中间用逗号隔开
select
id, -- 字段1
name, -- 字段2
address -- 字段3
from
student; -- 表名
去除重复
#查询student表中的地址
select DISTINCT -- 去除重复:DISTINCT
address
from
student;
计算列
#计算math列和english列的和:math + english
select
name,
math,
english,
math + english -- 计算
from
student;
#注意:如果有null参与计算,结果为null
#如果需要在计算时将null替换为0,可以使用IFNULL(原始值,替换值)
select
name,
math,
english,
math + IFNULL(english,0) -- 计算时,如果english的值为null,则替换为0
from
student;
起别名
#计算math列和english列的和,并用sum代替
select
name,
math,
english,
math + english as sum -- 使用as起别名
# math + english sum -- 不写as也可以
from
student;
条件查询
where子句 + 条件
运算符:
> 、< 、<= 、>= 、= 、<>
BETWEEN...AND
IN( 集合)
LIKE ' 张%'
IS NULL
and 或 &&
or 或 ||
not 或 !
#查询年龄大于20岁
SELECT * from student WHERE age > 20;
#查询年龄大于等于20岁
SELECT * from student WHERE age >= 20;
#查询年龄等于20岁
#等于用=,而不是==
SELECT * from student WHERE age = 20;
#查询年龄不等于20岁
#<>在SQL中表示不等于,在mysql中也可以使用!=
SELECT * from student WHERE age <> 20;
SELECT * from student WHERE age != 20;
#查询年龄大于等于20岁,小于等于30岁
SELECT * from student WHERE age >= 20 && age <= 30; -- 不推荐
SELECT * from student WHERE age >= 20 AND age <= 30;
SELECT * from student WHERE age BETWbeEEN 20 AND 30;
# BETWbeEEN 20 AND 30,包括 20 和 30
#查询年龄为18,20,22岁的记录
SELECT * from student WHERE age = 18 || age = 20 || age = 22;
SELECT * from student WHERE age = 18 OR age = 20 OR age = 22;
SELECT * from student WHERE age IN(18,20,22);
#查询英语成绩为null的记录
select * from student where english = null; -- 这是错误的语法;null值不能用运算符判断
select * from student where english is null; -- 这是正确的语法;null值要用is判断
#查询英语成绩不为null的记录
select * from student where english is NOT null; -- 使用 is not判断不为null
条件查询-模糊查询
_:表示单个任意字符
%:表示多个任意字符
#模糊查询:查询姓马的人
#查询姓马的人
select * from student WHERE name LIKE '马%';
#查询姓马的,姓名为两个字的人
select * from student WHERE name LIKE '马_';
#查询姓名第二个字是“化”的人
select * from student WHERE name LIKE '_化%';
#查询姓名最后一个字是“涛”的人
select * from student WHERE name LIKE '%涛';
#查询姓名为3个字的人
select * from student WHERE name LIKE '___'; -- 三个下划线
#查询姓名中包含“德”的人
select * from student WHERE name LIKE '%德%';
排序查询
语法:order by 子句
order by 排序字段1 排序方式1,排序字段2 排序方式2……
排序方式:
ASC:升序,默认的
DESC:降序
#按照升序的方式查询数学成绩
SELECT * FROM student ORDER BY math ASC;
SELECT * FROM student ORDER BY math; -- 不写排序方式,默认为升序
#按照降序的方式查询数学成绩
SELECT * FROM student ORDER BY math DESC;
#按照升序的方式查询数学成绩;
#如果有几条记录的数学成绩相同,则这几条记录按照英语成绩升序排序
SELECT *
FROM
student
ORDER BY
math ASC, -- 第一条件
english ASC; -- 第二条件(只有当第一条件相同时,才会使用第二条件)
聚合函数
将一列数据作为一个整体,进行纵向计算
count:个数
一般使用主键:SELECT COUNT(*) FROM 表名;
count( * ):不推荐使用
max:最大值
min:最小值
sum:求和
avg:求平均数
注意:聚合函数计算时,null值不加入计算
计算个数
语法:SELECT COUNT(列名) FROM 表名;
#计算student表中有多少个math
SELECT COUNT(math) FROM student;
#如果要计算包含null值的列数,使用IFNULL
select COUNT(IFNULL(math,0)) FROM student;
最大值
语法:select MAX(列名) FROM 表名;
#计算student表中math列的最大值
select MAX(math) FROM student;
最小值
语法:select MIN(列名) FROM 表名;
#计算student表中math列的最小值
select MIN(math) FROM student;
求和
语法:select SUM(列名) FROM 表名;
#计算student表中math列的和
select SUM(math) FROM student;
平均值
语法:select AVG(列名) FROM 表名;
#计算student表中math列的平均值
select AVG(math) FROM student;
分组查询
语法:group by 分组字段;
注意:
分组之后查询的字段:分组字段、聚合函数
where和having的区别?
where在分组之前进行限定,如果不满足限定条件,就不参与分组
having在分组之后进行限定,如果不满足限定条件,就不显示出来
where后不可以跟聚合函数,having后可以加上聚合函数的判断
#按照性别分组,分别查询男同学和女同学的数学平均分
select
sex, -- 性别
AVG(math) -- 数学平均分
FROM
student -- 表名
GROUP BY
sex; -- 按照性别分组
#按照性别分组,分别查询 男同学和女同学的 数学平均分和人数
select
sex, -- 性别
AVG(math), -- 数学平均分
COUNT(id) -- 人数
FROM
student -- 表名
GROUP BY
sex; -- 按照性别分组
#按照性别分组,分别查询 男同学和女同学 的 数学平均分和人数
#要求数学成绩低于70分的人,不参与分组
select
sex, -- 性别
AVG(math), -- 数学平均分
COUNT(id) -- 人数
FROM
student -- 表名
WHERE
math > 70 -- 数学成绩大于70分的才参与分组
GROUP BY
sex; -- 按照性别分组
#按照性别分组,分别查询 男同学和女同学 的 数学平均分和人数
#要求:数学成绩低于70分的人,不参与分组
#要求:显示人数大于2的记录
select
sex, -- 性别
AVG(math), -- 数学平均分
COUNT(id) -- 人数
FROM
student -- 表名
WHERE
math > 70 -- 数学成绩大于70分的才参与分组
GROUP BY
sex -- 按照性别分组
HAVING
COUNT(id) > 2; -- 聚合函数,显示人数大于2的记录
#按照性别分组,分别查询 男同学和女同学 的 数学平均分和人数
#要求:数学成绩低于70分的人,不参与分组
#要求:显示人数大于2的记录
select
sex, -- 性别
AVG(math), -- 数学平均分
COUNT(id) 人数 -- 别名:人数
FROM
student
WHERE
math > 70 -- 数学成绩大于70分的才参与分组
GROUP BY
sex -- 按照性别分组
HAVING
人数 > 2; -- 显示别名人数大于2的记录
# 查询用户
#1.切换数据库到mysql
USE mysql;
#2.查询user表
SELECT * FROM USER;
# host的值
# localhost 表示当前主机可登录
# % 表示任意主机可登录,可用于远程操作
添加用户
# 添加用户
# 语法:create user '用户名'@'主机名' identified by '密码';
CREATE USER 'JHF'@'localhost' IDENTIFIED BY '123';
CREATE USER 'JHF'@'%' IDENTIFIED BY '123';
修改密码
注意:
旧版需要 password()函数给密码加密
新版取消了password关键字,改为了authentication_string关键字
新版取消了password()函数
# 修改用户密码
# 需求:修改用户JHF的密码为abc
# 方式一
# 旧版语法:update user set password = password('新密码') where user = '用户名';
# 新版语法:update user set authentication_string = '新密码' where user = '用户名';
UPDATE USER SET authentication_string = 'abc' WHERE USER = 'JHF';
# 方式二
# 旧版语法:set password for '用户名'@'主机名' = password('新密码');
# 新版语法:set PASSWORD for '用户名'@'主机名' = 'abc';
SET PASSWORD FOR 'JHF'@'localhost' = 'abc123';
如果忘记root用户的密码,该怎么办?
在命令提示符管理员的权限下,停止mysql服务:net stop mysql;
使用无验证方式,启动MySQL服务:mysqld --skip-grant-tables,回车;
新打开一个命令提示符窗口输入:MySQL,回车;
登录之后,使用命令更改root账户的密码;
使用任务管理器,手动结束mysqld.exe进程;
在命令提示符管理员的权限下,打开mysql服务:net start mysql;
通过更改之后的 root账户的密码,登录MySQL数据库;
删除用户
# 删除用户
# 语法:drop user '用户名'@'主机名';
DROP USER 'JHF'@'localhost';
DROP USER 'JHF'@'%';
管理用户权限
# 查询用户权限
# 语法:SHOW GRANTS FOR '用户名'@'主机名';
SHOW GRANTS FOR 'JHF'@'localhost';
授予用户的权限(权限列表)
如 CREATE、ALTER、SELECT、INSERT、UPDATE 等;
如果要授予所有的权限则使用 ALL;
# 授予用户权限
# 语法:grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
# 给Tom设置只能查看demo1数据库中的account表,并进行(权限列表)操作。
GRANT SELECT ON demo1.`account` TO 'Tom'@'localhost';
GRANT ALL ON demo1.`account` TO 'Tom'@'localhost';
# 给Jerry设置所有数据库所有表的所有权限
GRANT ALL ON *.* TO 'Jerry'@'%';
# 一般来讲,要先在mysql数据库中的user表下,使用CREATE USER语法创建用户,再进行权限授权。
# 撤销权限
# 语法:REVOKE 权限列表 on 数据库名.表名 from '用户名'@'主机名';
REVOKE ALL ON demo1.`account` FROM 'Tom'@'localhost';
REVOKE UPDATE ON *.* FROM 'Jerry'@'%';
约束
概念:对表中的数据进行限定,保证数据的正确性、有效性和完整性。
约束的分类:
主键约束:primary key
非空约束:not null
唯一约束:unique
外键约束:foreign key
非空约束
非空约束:某一列的值不能为null
添加非空约束的两种方式
创建表时,添加非空约束
创建完表之后,添加非空约束
#1.创建stu表时,对name列添加非空约束
CREATE table stu(
id INT,
NAME VARCHAR(20) NOT NULL #NAME非空
);
#2.测试:给name列插入null数据
INSERT INTO stu(id) VALUES(3);
#3.结果报错
#报错原因:添加非空约束的字段不能为null
Field 'NAME' doesn't have a default value
#但如果name列没有设置非空约束,则可以添加null值
#1.更改name列的类型,删除非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20);
#2.执行成功,name为null时可以插入数据
INSERT INTO stu(id) VALUES(3);
#创建完stu表之后,对name列添加非空约束
#1.删除name为null的数据
DELETE FROM stu where id = 3;
#2.更改name列的类型,设置非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20) NOT NULL;
#3.测试:给name列插入null数据
#结果报错,添加非空约束的字段不能为null
INSERT INTO stu(id) VALUES(3);
唯一约束
某一列的值不能重复
唯一约束可以有null值,但只能有一条记录为null
删除唯一约束
ALTER TABLE 表名 DROP INDEX 列名;
添加唯一约束的两种方式
创建表时,添加唯一约束
创建完表之后,添加唯一约束
#1.创建stu表时,对phoneNumber列添加唯一约束
CREATE table stu(
id INT,
phoneNumber VARCHAR(20) UNIQUE #电话号码不能重复
);
#2.添加数据
INSERT INTO stu(id,phoneNumber) VALUES(1,15291011111);
#3.执行报错
INSERT INTO stu(id,phoneNumber) VALUES(2,15291011111);
#报错原因:设置唯一约束的列不能重复
Duplicate entry '15291011111' for key 'phoneNumber'
#4.执行成功,phoneNumber列的值不重复
INSERT INTO stu(id,phoneNumber) VALUES(2,15291011112);
#1.删除唯一约束,更改phoneNumber列的类型
ALTER TABLE stu MODIFY phoneNumber VARCHAR(20);
#2.添加数据
#执行失败,以更改类型的方式删除唯一约束,是不行的
INSERT INTO stu(id,phoneNumber) VALUES(1,15291011111);
#3.DROP INDEX:以删除索引的方式,删除唯一约束
ALTER TABLE stu DROP INDEX phoneNumber;
#4.添加数据成功
#没有添加唯一约束时,数据可以重复
INSERT INTO stu(id,phoneNumber) VALUES(3,15291011111);
#创建完表之后,添加唯一约束
#1.删除phoneNumber列有重复的数据
DELETE FROM stu WHERE id=3;
#2.更改phoneNumber列的类型,添加唯一约束
ALTER TABLE stu MODIFY phoneNumber VARCHAR(20) UNIQUE;
#3.添加数据失败
#设置唯一约束的列不能重复
INSERT INTO stu(id,phoneNumber) VALUES(3,15291011111);
主键约束
主键:非空且唯一
一张表只能有一个字段为主键
主键就是表中记录的唯一标识
添加主键约束的两种方式
创建表时,添加主键约束
创建完表之后,添加主键约束
删除主键:ALTER TABLE 表名 DROP PRIMARY KEY;
4.主键自动增长:auto_increment
自动跟随上一条记录的最大值进行+1
#1.创建表时,添加主键约束
create table stu(
id int PRIMARY KEY, #给id添加主键约束
name VARCHAR(30)
);
#2.添加记录
INSERT INTO stu(id,name) VALUES(1,"马保国");
#添加失败
INSERT INTO stu(id,name) VALUES(1,"马保国");
#报错原因:主键重复
Duplicate entry '1' for key 'PRIMARY'
#3.主键不重复,则添加记录成功
INSERT INTO stu(id,name) VALUES(2,"马保国");
#1.删除主键
ALTER TABLE stu MODIFY id INT; #错误方式
#2.添加记录失败
INSERT INTO stu(id,name) VALUES(1,"马保国");
#3.删除主键
ALTER TABLE stu DROP PRIMARY KEY; #正确方式
#4.id重复时,没有设置主键约束,可以添加记录成功
INSERT INTO stu(id,name) VALUES(1,"马保国");
#创建完表之后,添加主键约束
#1.删除表中所有记录
delete FROM stu;
#2.更改id类型,添加主键约束
ALTER TABLE stu MODIFY id INT PRIMARY KEY;
#3.添加记录
INSERT INTO stu(id,name) VALUES(1,"马保国");
#4.添加记录失败
INSERT INTO stu(id,name) VALUES(1,"马保国");
#报错原因:主键重复
Duplicate entry '1' for key 'PRIMARY'
主键约束-自动增长
如果某列是数值类型,可以使用auto_increment实现自动增长
自动增长一般配合主键id使用
主键id自动增长,会自动跟随上一条记录的id最大值进行+1
#1.删除旧表
drop table stu;
#2.创建新表
create table stu(
id int PRIMARY KEY auto_increment, #设置主键自动增长
name VARCHAR(30)
);
#3.插入数据
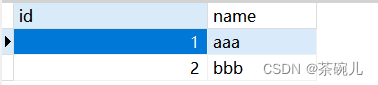
INSERT INTO stu VALUES(null,"aaa");
INSERT INTO stu VALUES(null,"bbb");
#4.查询表中所有数据
select * from stu;
运行结果:id自动增长成功
#删除自动增长
#1.更改id类型,删除自动增长
ALTER TABLE stu MODIFY id INT;
#2.添加数据失败
INSERT INTO stu VALUES(null,"aaa");
#报错原因:删除自动增长之后,主键不能为空
Column 'id' cannot be null
#添加自动增长
#1.更改id类型,添加自动增长
ALTER TABLE stu MODIFY id INT auto_increment;
#2.添加数据成功
#设置自动增长后,id虽然为null,但可以根据上一条记录的值,实现自动增长
INSERT INTO stu VALUES(null,"aaa");
#1.创建emp表
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(30),
age INT,
dep_name VARCHAR(30),
dep_location VARCHAR(30)
);
#2.添加数据
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('张三', 20, '研发部', '广州');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('李四', 21, '研发部', '广州');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('王五', 20, '研发部', '广州');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('老王', 20, '销售部', '深圳');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('大王', 22, '销售部', '深圳');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('小王', 18, '销售部', '深圳');
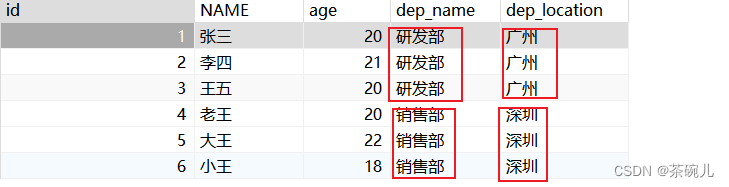
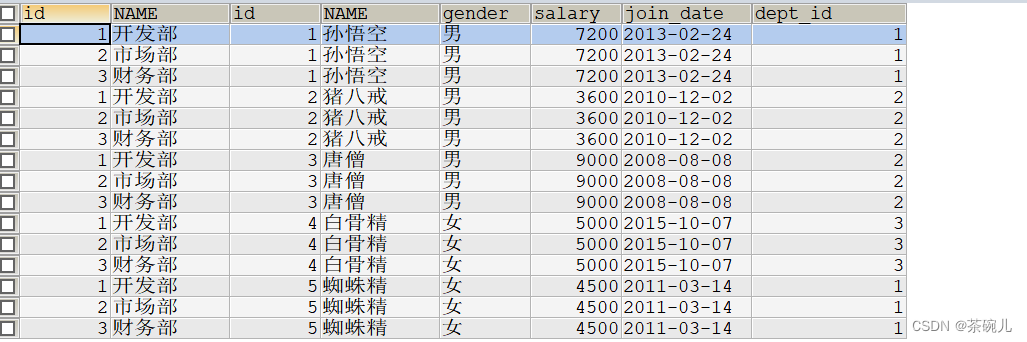
#3.查询表的所有记录
select * from emp;
发现emp表中有多条重复的内容
dep_name:部门名称
dep_location:部门位置
使用外键约束进行优化
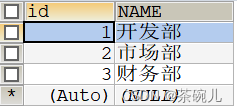
1.创建部门表department,并添加数据
#1.创建部门表
create table department( #部门表
id int primary key auto_increment, #主键id自增
dep_name varchar(20), #部门名称
dep_location varchar(20) #部门地址
);
#2.添加部门数据
insert into department values(null, '研发部','广州'),(null, '销售部', '深圳');
#3.查询部门表的所有内容
select * from department;
这样就没有了重复内容
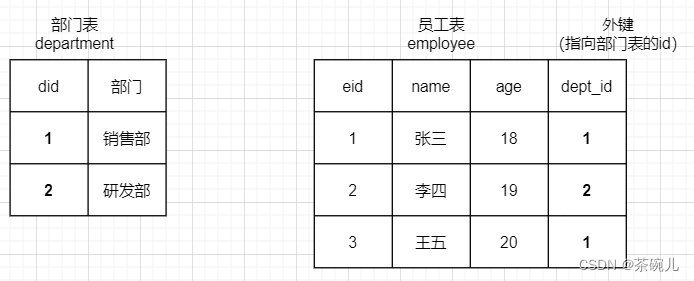
2.创建员工表employee
#1.创建员工表
create table employee( #员工表
id int primary key auto_increment, #主键id自增
name varchar(20), #员工名称
age int, #员工年龄
dep_id int #部门表的id(外键对应主表的主键)
)
#2.添加员工数据
#添加员工,dep_id 表示员工所在的部门
INSERT INTO employee (NAME, age, dep_id) VALUES ('张三', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('李四', 21, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('王五', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('老王', 20, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('大王', 22, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('小王', 18, 2);
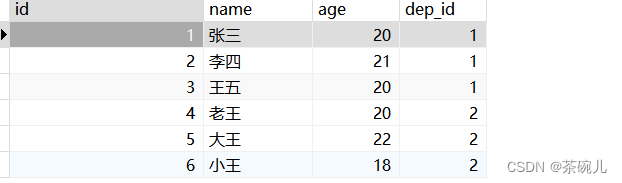
#3.查询员工表所有内容
select * from employee;
dep_id关联department表中的部门信息
但是这样并没有真正的起作用
让我们使用外键约束来重新设计表吧
3.在创建表时,添加外键约束
使用外键约束,重新设计数据库表
#1.删除emp表、department表和employee表
drop table emp;
drop table department;
drop table employee;
#1.重新创建部门表department
create table department(
id int primary key auto_increment,
dep_name varchar(20),
dep_location varchar(20)
);
#2.重新创建employee表,加入外键约束
create table employee(
id int primary key auto_increment,
name varchar(20),
age int,
dep_id int, #外键列
CONSTRAINT #约束
emp_dep_fk #自定义的外键名称
FOREIGN KEY (dep_id) #外键:此表的外键列
REFERENCES department(id) #关联:主表的主键列
);
#3.添加数据
#添加两个部门
insert into department values(null, '研发部','广州'),(null, '销售部', '深圳');
#添加员工信息
INSERT INTO employee (NAME, age, dep_id) VALUES ('张三', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('李四', 21, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('王五', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('老王', 20, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('大王', 22, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('小王', 18, 2);
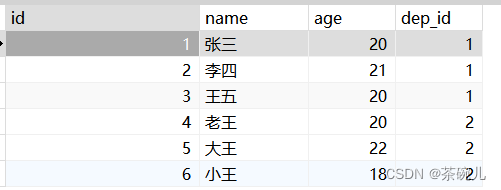
select * from department;
select * from employee;
此时employee表已经和主表department通过外键约束关联起来了
#1.删除主表department中的一条记录
DELETE FROM department WHERE id = 1;
#报错:主表的数据正在通过外键被其他表关联着,所以删不掉
Cannot delete or update a parent row: a foreign key constraint fails (`demo`.`employee`, CONSTRAINT `emp_dep_fk` FOREIGN KEY (`dep_id`) REFERENCES `department` (`id`))
#2.向employee表中添加一条记录,关联department中不存在的部门
INSERT INTO employee (NAME, age, dep_id) VALUES ('马保国', 70, 3);
#报错:使用了外键约束的表,只能关联主表中存在的记录
Cannot add or update a child row: a foreign key constraint fails (`demo`.`employee`, CONSTRAINT `emp_dep_fk` FOREIGN KEY (`dep_id`) REFERENCES `department` (`id`))
删除外键
#1.删除外键
ALTER TABLE employee DROP FOREIGN KEY emp_dep_fk;
#2.向employee表中添加一条记录,关联department中不存在的部门
INSERT INTO employee (NAME, age, dep_id) VALUES ('马保国', 70, 3);
#执行成功,删除了外键之后,可以向表中添加记录关联主表中不存在的记录
在创建表之后,添加外键约束
#1.删除之前向employee表中添加的,关联主表中不存在记录的那条数据
DELETE FROM employee WHERE id = 8;
#2.添加外键
ALTER TABLE employee ADD CONSTRAINT emp_dep_fk FOREIGN KEY (dep_id) REFERENCES department(id);
#3.向employee表中添加一条记录,关联department中不存在的部门
INSERT INTO employee (NAME, age, dep_id) VALUES ('马保国', 70, 3);
#报错:使用了外键约束的表,只能关联主表中存在的记录
Cannot add or update a child row: a foreign key constraint fails (`demo`.`employee`, CONSTRAINT `emp_dep_fk` FOREIGN KEY (`dep_id`) REFERENCES `department` (`id`))
外键约束-级联操作
主表中的列,被外键约束之后,就不能随意更改了;如果想要更改,就要设置级联操作
添加外键时,设置级联操作: ALTER TABLE 表名 ADD constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称) ON UPDATE CASCADE ON DELETE CASCADE;
级联操作的分类
级联更新:ON UPDATE CASCADE
表的外键列,随着关联的主表列的改变,而自动改变
级联删除:ON DELETE CASCADE
表中的记录,随着主表数据的删除,而自动删除
#添加外键时,设置级联更新
#1.删除外键
ALTER TABLE employee DROP FOREIGN KEY emp_dep_fk;
#2.添加外键,设置级联更新
ALTER TABLE employee ADD CONSTRAINT emp_dep_fk FOREIGN KEY (dep_id) REFERENCES department(id) ON UPDATE CASCADE;
#3.设置级联更新之后,就可以将主表中的关联列数据进行更改了
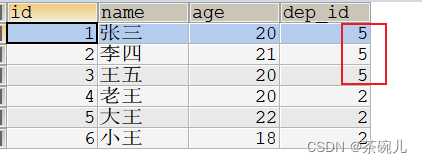
UPDATE department SET id = 5 WHERE id = 1;
查看更改后的主表department数据
SELECT * FROM department;
主表数据更改之后,employee表中的外键也随之更新了
SELECT * FROM employee;
#添加外键,设置级联更新,设置级联删除
#1.删除外键
ALTER TABLE employee DROP FOREIGN KEY emp_dep_fk;
#2.添加外键,设置级联更新,设置级联删除
ALTER TABLE employee ADD CONSTRAINT emp_dep_fk FOREIGN KEY (dep_id) REFERENCES department(id) ON UPDATE CASCADE ON DELETE CASCADE;
#3.设置级联删除后,删除主表department中的记录
DELETE FROM department WHERE id = 5;
查看删除数据之后的主表department数据
SELECT * FROM department;
可以看到删除主表department中的数据之后,employee表中与之相关联的数据也被删除了
SELECT * FROM employee;