NoSQL简介
1、什么是NoSQL
-
NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。
-
NoSQL主要指非关系型、分布式、不提供ACID的数据库设计模式。
-
在现代的计算系统上每天网络上都会产生庞大的数据量。
-
这些数据有很大一部分是由关系数据库管理系统(RDBMS)来处理。 1970年 E.F.Codd's提出的关系模型的论文 "A relational model of data for large shared data banks",这使得数据建模和应用程序编程更加简单。
-
通过应用实践证明,关系模型是非常适合于客户服务器编程,远远超出预期的利益,今天它是结构化数据存储在网络和商务应用的主导技术。
-
NoSQL 是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
-
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
2、什么是分布式系统
-
分布式系统(distributed system)由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成。
-
分布式系统是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。
-
因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。
-
分布式系统可以应用在不同的平台上如:Pc、工作站、局域网和广域网上等。
3、分布式计算的优劣
1、优点
- 可靠性(容错) :
分布式计算系统中的一个重要的优点是可靠性。一台服务器的系统崩溃并不影响到其余的服务器。
- 可扩展性:
在分布式计算系统可以根据需要增加更多的机器。
- 资源共享:
共享数据是必不可少的应用,如银行,预订系统。
- 灵活性:
由于该系统是非常灵活的,它很容易安装,实施和调试新的服务。
- 更快的速度:
分布式计算系统可以有多台计算机的计算能力,使得它比其他系统有更快的处理速度。
- 开放系统:
由于它是开放的系统,本地或者远程都可以访问到该服务。
- 更高的性能:
相较于集中式计算机网络集群可以提供更高的性能(及更好的性价比)。
2、缺点
- 故障排除:
故障排除和诊断问题。
- 软件:
更少的软件支持是分布式计算系统的主要缺点。
- 网络:
网络基础设施的问题,包括:传输问题,高负载,信息丢失等。
- 安全性:
开放系统的特性让分布式计算系统存在着数据的安全性和共享的风险等问题。
4、为什么要使用NoSQL
- 今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL 数据库的发展却能很好的处理这些大的数据。
1、RDBMS vs NoSQL
-
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL) (SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
-
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
2、CAP定理(CAP theorem)
-
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
-
一致性(Consistency) (所有节点在同一时间具有相同的数据)
-
可用性(Availability) (保证每个请求不管成功或者失败都有响应)
-
分区容错性(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
-
-
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
-
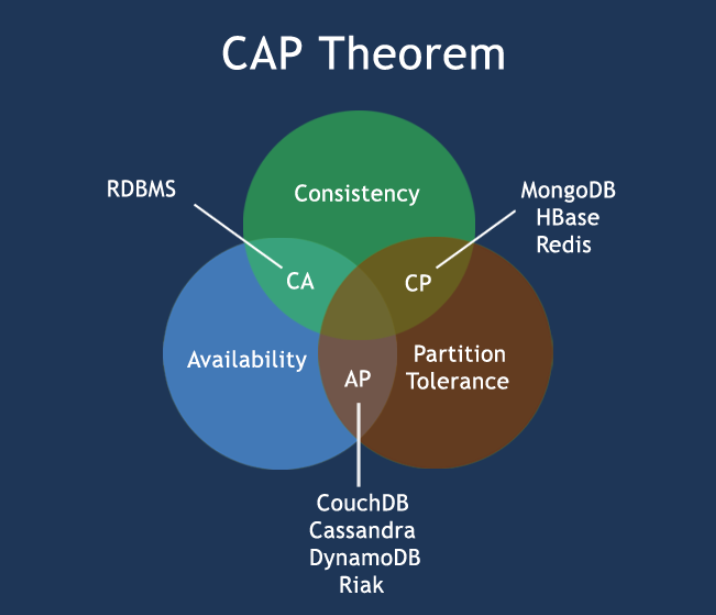
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
-
CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
-
CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
-
AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
-
5、NoSQL的优缺点
-
优点:
-
高可扩展性
-
分布式计算
-
低成本
-
架构的灵活性,半结构化数据
-
没有复杂的关系
-
-
缺点:
-
没有标准化
-
有限的查询功能(到目前为止)
-
最终一致是不直观的程序
-
6、ACID vs BASE

7、NoSQL数据库分类