分库分表之拆分键设计
众所周知,在现实世界中,每一个资源都有其提供能力的最大上限,当单一资源达到最大上限后就得让多个资源同时提供其能力来满足使用方的需求。同理,在计算机世界中,单一数据库资源不能满足使用需求时,我们也会考虑使用多个数据库同时提供服务来满足需求。当使用了多个数据库来提供服务时,最为关键的点是如何让每一个数据库比较均匀的承担压力,而不至于其中的某些数据库压力过大,某些数据库没什么压力。这其中的关键点之一就是拆分键的设计。
1 水平、垂直拆分
在关系数据库中,当单个库的负载、连接数、并发数等达到数据库的最大上限时,就得考虑做数据库和表的拆分。如一个简单的电商数据库,在业务初期,为了快速验证业务模式,把用户、商品、订单都放到一个数据库中,随着业务的发展及用户量的增长,单数据库逐渐不能支撑业务(MySQL中单记录容量超过1K时,单表数据量建议不超过一千万条),这时就得考虑把数据库和表做出拆分。
1.1 垂直拆分
简单的说就是将数据库及表由一个拆分为多个,如我们这里的电商数据库,可以垂直拆分为用户数据库、商品数据库和订单数据库,订单表可以垂直拆分为订单基本信息表,订单收货地址表、订单商品表等,每一个表里保存了一个订单的一部分数据。

1.2 水平拆分
简单的说就是将一个库、一个表扩展为多个库,多个表,每一个拆分后的表中保存的依然是一个订单的完整信息。如电商数据库,我们按水平拆分数据库和表后,每一个拆分后的数据库表与现有未拆分前的都保持一致。

1.3 常用拆分方法
上述仅从理论上讲解了可行的水平、垂直拆分方法,在实际的生产上,我们拆分一般是按照水平拆表、垂直拆库这一原则进行,在业务比较复杂的场景下也会对表进行垂直拆分。
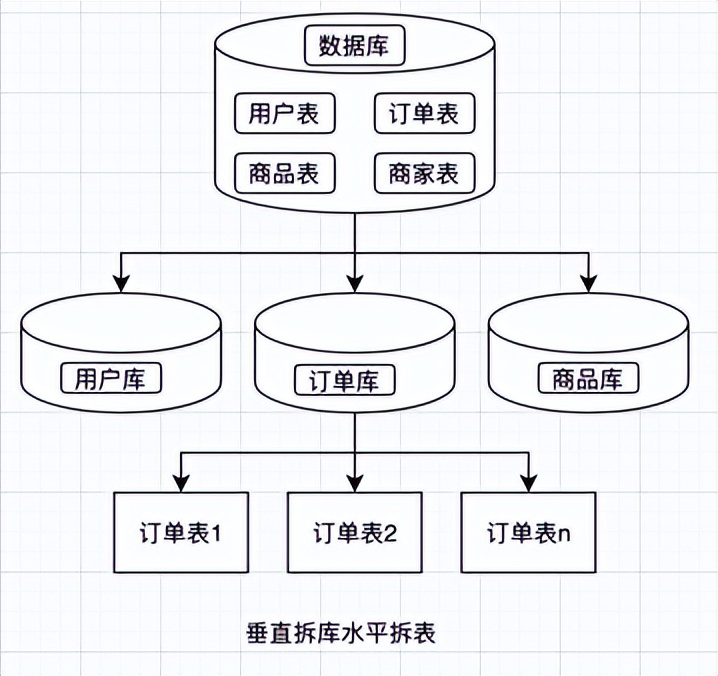
2 拆分键的选取
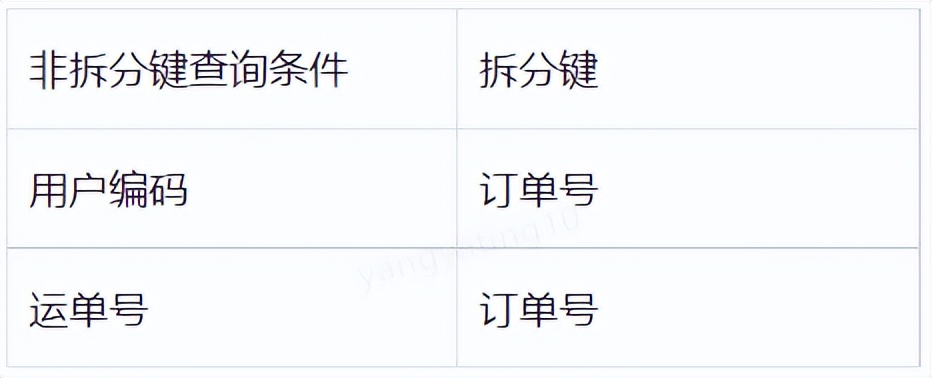
分库分表的关键项之一是拆分键的选取,一般情况下,拆分键的选取遵循以什么维度进行查询就选取该维度为拆分键。如:订单表就以订单号作为拆分键,商品表就以商品编号作为拆分键。拆分键选取后,对于一些非拆分键的单条件查询,我们需要怎么支持呢?在这里提供3种方法供参考。
2.1 等值法
对于非拆分键的单条件查询,对这一个单条件的赋值,可以将其值与拆分键保持一致。比如在电商场景中,用户下订单后,需要通过物流给用户把商品送到用户手上。对于用户来说仅能看到订单信息,订单上展示的物流信息用户也是通过订单号查询而来;但对于物流系统来说,其系统里的业务主键(拆分键)是运单号,此时,运单号如果和订单号相同,即可完美解决这一问题。订单表和运单表的基本数据模型如下:
1)订单表

2)运单表

在订单表中,拆分键order_id与运单表中的拆分键waybill_code值相同,当按订单号查询运单表里的运单信息时,可以直接查询拆分键waybill_code获取订单对应的运单信息。
2.2 索引法
对于常用的非拆分键,我们可以将其与拆分键之间建立一个索引关系,当按该条件进行查询时,先查询对应的拆分键,再通过拆分键查询对应的数据信息。订单表的索引法查询表模型如下:
1)索引表
例:用户user001在商城上购买了一支笔下单的订单号为10001,商家发货后,物流公司给的运单号是Y0023
2)该用户的订单表、运单表模型如下:
订单表:

运单表:

索引表:

当查询用户(user001)的下单记录时,通过用户编码先查询索引表,查询出user001的所有下单的订单号(10001),再通过订单号查询订单表获取用户的订单信息;同理,根据运单号(Y00232)查询订单信息时,在索引表里先查询到对应的订单号,再根据订单号查询对应的订单信息。
2.3 基因法
拆分键与非拆分键的单号生成规则中,存在相同规则的部分且该部分被用作拆分键来进行库表的定位。比如:订单号生成时,生成一个Long类型的单号,由于Long是64位的,我们可以用其低4位取模来定位该订单存储的数据库及表,其他表的拆分键也用Long类型的低4位取模来定位对应的数据库及表。还是用订单表和运单表的模型做解释如下:
1)订单表

2)运单表

当通过订单表里的订单号查运单表时,通过订单号的低4位定位到该订单号在运单数据库及表的位置,再直接通过脚本查询出订单号对应的运单信息。
3 拆分键的生成
拆分键选取后,接下来是拆分键的生成,拆分键的生成有多种方式,建议根据业务量及并发量的大小来确定拆分键生成的规则,在这里介绍几种常用的拆分键生成规则。
3.1 数据库自增主键
在并发量不大的情况下,我们可以使用MySQL数据库里的自增主键来实现拆分键。
3.2 UUID
在Java里,可以使用Java自带的UUID工具类直接生成,UUID的组成:UUID=当前日期和时间+时钟序列+全局唯一的IEEE机器识别号组成。其中,全局唯一的IEEE机器识别号一般是通过网卡的MAC地址获得,没有网卡时以其他的方式获得。UUID生成的编号不会重复,但不利于阅读和理解。
import java.util.UUID;
public class UUIDTest {
public static void main(String[] args) {
UUID uuid = UUID.randomUUID();
System.out.println(uuid.toString());
}
}
3.3 雪花算法
雪花算法生成的ID是一个64位大小的整数,结构如下:

从其结构可以看出,第一位是符号位,在使用时一般不使用,后面的41位是时间位,是由时间戳来确定的,后面的10位是机器位,最后的12位是生成的ID序列,是每豪秒生成的ID数,即每毫秒可以生成4096个ID。从该结构可以看出,10位机器位决定了使用机器的上限,在某些业务场景下,需要所有的机器使用同一个业务空间,这可能导致机器超限;同时,每一个机器分配后如果机器宕机需要更换时,对ID的回收也需要有相应的策略;最为关键的一点是机器的时间是动态调整的,有可能会出现时间回退几毫秒的情况,如果这个时候获取到这个时间,则会生成重复的ID,导致数据重复。
4 提升总结
单数据库不能满足业务场景的情况下,主要的思路还是要进行拆分,无论是NoSQL还是关系数据库,随着业务量的增长,都得需要把多个服务器资源组合成一个整体共同来支撑业务。数据库拆分后,如果业务上有多个复杂查询条件的需求,一般就得把数据同步到NoSQL数据库里,由NoSQL来提供支持。无论什么时候,数据库提供的主要能力是存储能力,对于复杂的计算需求,一般是需要在业务逻辑里实现。
作者:京东物流 廖宗雄
来源:京东云开发者社区 自猿其说Tech 转载请注明来源