数仓实践丨表扫描时过滤行数过多引起的性能瓶颈问题
本文分享自华为云社区《GaussDB(DWS)性能调优:表扫描时过滤行数过多引起的性能瓶颈问题案例》,作者: O泡果奶~ 。
1、【问题描述】
SQL语句执行过程中,对12亿数据量的大表进行扫描,过滤99%的数据仅留617行数据,性能瓶颈位于扫描该表这里。
2、【原始语句】
set search_path = 'bi_dashboard'; WITH F_SRV_DB_DIM_PRD_D AS (SELECT EXTERNAL_NAME FROM ( SELECT MKT_NAME EXTERNAL_NAME FROM BI_DASHBOARD.DM_MSS_ITEM_PRODUCT_D PRD WHERE PRD.COMPANY_BRAND =any(array[string_to_array('HUAWEI',',')]) AND PRD.MKT_NAME =any(array[string_to_array('畅享 60,畅享 50,畅享 60X,畅享 60 Pro,畅享 50 Pro,畅享 50z,nova 10z,畅享 20e,畅享20 Pro,畅享 10e,畅享10 Plus,畅享20 SE,畅享10,nova 11i,畅享20 Plus,畅享9 Plus,畅享20 5G,nova Y90,畅享 10S,nova Y70,畅享Z,畅享 9S,nova 8 SE 活力版,麦芒9 5G,Y9s,麦芒9 5G',',')]) ) WHERE EXTERNAL_NAME<>'SNULL' GROUP BY EXTERNAL_NAME), V_PERIOD AS ( SELECT PERIOD_ID AS PERIOD_ID_M, LEAST(TO_CHAR(PERIOD_END_DATE, 'YYYYMMDD'), '20230630') AS PERIOD_ID, PERIOD_ID AS DATES FROM BI_DASHBOARD.RPT_TML_ACCOUNT_PERIOD_D WHERE PERIOD_TYPE = 'M' AND PERIOD_ID BETWEEN 202207 AND 202306 ), V_DATA_BASE AS ( SELECT A.PERIOD_ID, IFNULL(A.CHANNEL_NAME, 'SNULL') AS DISTRIBUTOR_CHANNEL_NAME, SUM(A.SO_QTY_MTD) AS SO_QTY, SUM(DECODE(A.PERIOD_ID, 20230630, A.SO_QTY_MTD)) AS SO_QTY_ORDER select count(*) FROM DM_MSS_CN_PC_REP_RP_ST_D_F A INNER JOIN F_SRV_DB_DIM_PRD_D PRD ON A.EXTERNAL_NAME = PRD.EXTERNAL_NAME WHERE 1 = 1 AND A.CHANNEL_ID IN ('100013388802') AND A.ORG_KEY IN (10000651) AND A.SALES_FLAG IN ('1', '0') AND A.PERIOD_ID IN (20220731,20221031,20220930,20220831,20221130,20221231,20230131,20230228,20230430,20230331,20230531,20230630) AND (A.SO_QTY_MTD <> 0) -- 过滤所有日期SO_QTY为0的数据 GROUP BY A.PERIOD_ID, IFNULL(A.CHANNEL_NAME, 'SNULL') ), V_DATA AS ( SELECT PERIOD_ID, NVL(DISTRIBUTOR_CHANNEL_NAME, 'Total') AS DISTRIBUTOR_CHANNEL_NAME, SUM(SO_QTY) AS SO_QTY, SUM(SO_QTY_ORDER) AS SO_QTY_ORDER FROM V_DATA_BASE A GROUP BY GROUPING SETS ((PERIOD_ID), (PERIOD_ID, DISTRIBUTOR_CHANNEL_NAME)) ) SELECT STRING_AGG(P.DATES, ',' ORDER BY P.PERIOD_ID_M) AS PERIOD_LIST, B.DISTRIBUTOR_CHANNEL_NAME, STRING_AGG(NVL(TO_CHAR(ROUND(A.SO_QTY)), '0'), ',' ORDER BY P.PERIOD_ID_M) AS SO_QTY FROM V_PERIOD P FULL JOIN (SELECT DISTINCT DISTRIBUTOR_CHANNEL_NAME FROM V_DATA) B ON 1 = 1 LEFT JOIN V_DATA A ON A.PERIOD_ID = P.PERIOD_ID AND A.DISTRIBUTOR_CHANNEL_NAME = B.DISTRIBUTOR_CHANNEL_NAME GROUP BY B.DISTRIBUTOR_CHANNEL_NAME ORDER BY DECODE(B.DISTRIBUTOR_CHANNEL_NAME, 'Total', 0, 'SOURCE IS NULL', 2, '源为空', 3, 'SNULL', 4, 1), SUM(A.SO_QTY_ORDER) DESC NULLS LAST LIMIT 50 OFFSET 0
3、【性能分析】
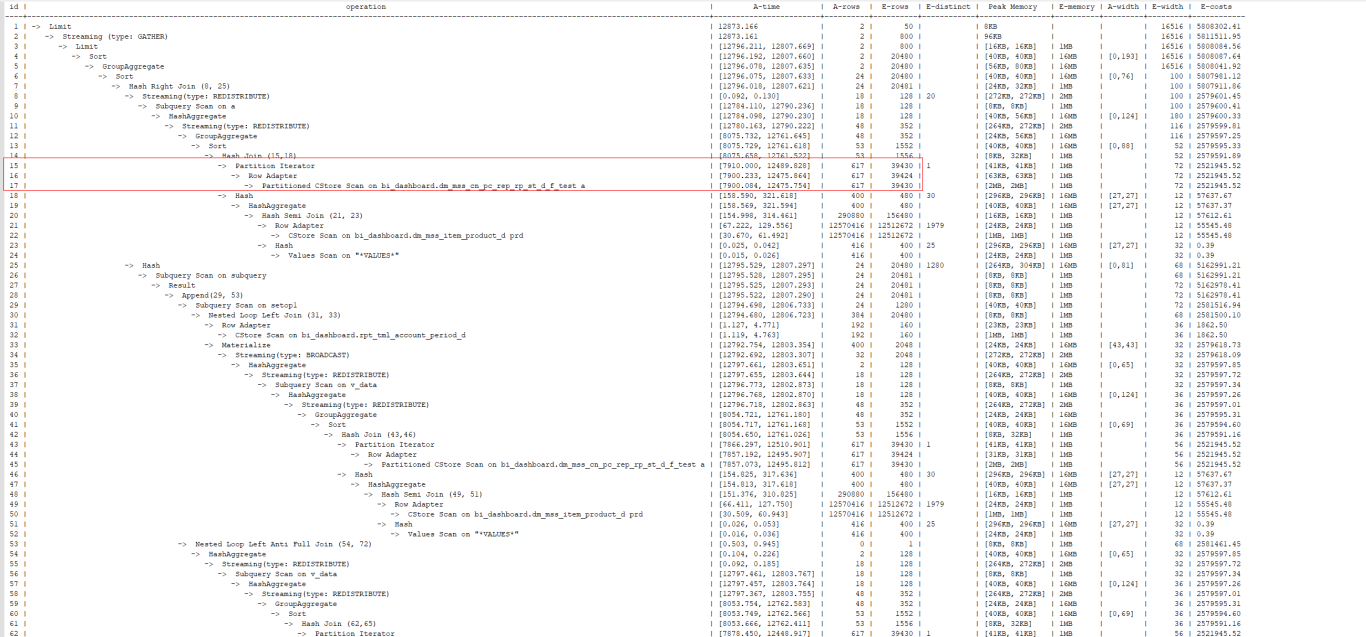

从上图的performance执行计划中可以看出(完整执行计划放在附件一),该SQL语句慢在扫描表a(bi_dashboard.dm_mss_cn_pc_rep_rp_st_d_f_test)。扫描时过滤条件包括:sales_flag、so_qty_mtd、channel_id、org_key、period_id,该表上原本的局部聚簇键PCK只包含了period_id,并没有包括其余三个过滤条件之一,因此,可以调整PCK,以减少扫描表a的执行时间。
补充:局部聚簇键
局部聚簇 (Partial Cluster Key, 简称PCK),列存储下一种通过min/max稀疏索引实现基表快速扫描的索引技术。Partial Cluster Key可以指定多列,但是一般不建议超过2列。PCK适用于列存大表点查询加速。另外,查看语句中where条件中in值较多(12个),在DWS中,in后面的条件默认就只能是5个,超过6个就过滤不下推,此时,可以用or将12个值改写,
A.PERIOD_ID IN (20220731,20221031,20220930,20220831,20221130) or A.PERIOD_ID IN (20221231,20230131,20230228,20230430,20230331) or A.PERIOD_ID IN (20230531,20230630)

此时,SQL语句执行时间减少为487ms,完整performance计划如附件二所示。
- 附件:优化后—performance.txt 466.64KB
- 附件:优化前—performance.txt 449.47KB