第二单元 数据库操作
主数据文件
-
主要数据文件的建议文件扩展名是
.mdf。 -
主要数据文件包含数据库的启动信息,并指向数据库中的其他文件,存储部分或全部的数据。用户数据和对象可存储在此文件中,也可以存储在次要数据文件中。
-
每个数据库有一个主要数据文件。
-
mdf文件并非普通文件,因此不借助相应软件是无法打开mdf文件的。打开mdf文件的常用虚拟光驱软件主要有:Daemon Tools 、东方光驱魔术师等。
次要数据文件 (*.ndf)
-
次要数据文件的建议文件扩展名是 .
ndf。 -
次要数据文件是可选的,由用户定义并存储用户数据,用于存储主数据文件未能存储的剩余数据和一些数据库对象。
-
通过将每个文件放在不同的磁盘驱动器上,次要文件可用于将数据分散到多个磁盘上。
-
如果数据库超过了单个 Windows 文件的最大大小,可以使用次要数据文件,这样数据库就能继续增长。
事务日志 (*.ldf)
-
事务日志的建议文件扩展名是 .
ldf。 -
事务日志文件保存用于恢复数据库的事务日志信息。数据库的插入、删除、更新等操作都会记录在日志文件中,而查询不会记录在日志文件中。整个的数据库有且仅有一个日志文件。
-
每个数据库必须至少有一个日志文件。
2. 文件组
不同的文件可以存分布到不同的物理硬盘上,这样便于分散硬盘IO,提高数据的读取速度。
数据文件的组合,称作文件组(File Group),数据库不能直接设置存储数据的数据文件,而是通过文件组来指定。
文件和文件组的关系
SQL Server 的数据存储在文件中,文件是实际存储数据的物理实体,文件组是逻辑对象,SQL Server 通过文件组来管理文件。
一个数据库有一个或多个文件组,其中主文件组(Primary File Group)是系统自动创建的,用户可以根据需要添加文件组。 每一个文件组管理一个或多个文件,其中主文件组中包含主要数据文件(*.mdf),主文件组中也可以包含次要数据文件 。(主要数据文件是系统默认生成的,并且在数据库中是唯一的;次要数据文件是用户根据需要添加的。) 除了主文件组之外,其他文件组只能包含辅助文件。 如下示例数据库,系统已自动创建主文件组 PRIMARY,勾选 Default 表示将主文件组设置为默认文件组,即如果在 create table 和 create index 时没有指定 FileGroup 选项,那么 SQL Server 将使用默认的 PRIMARY 文件组来存储数据。
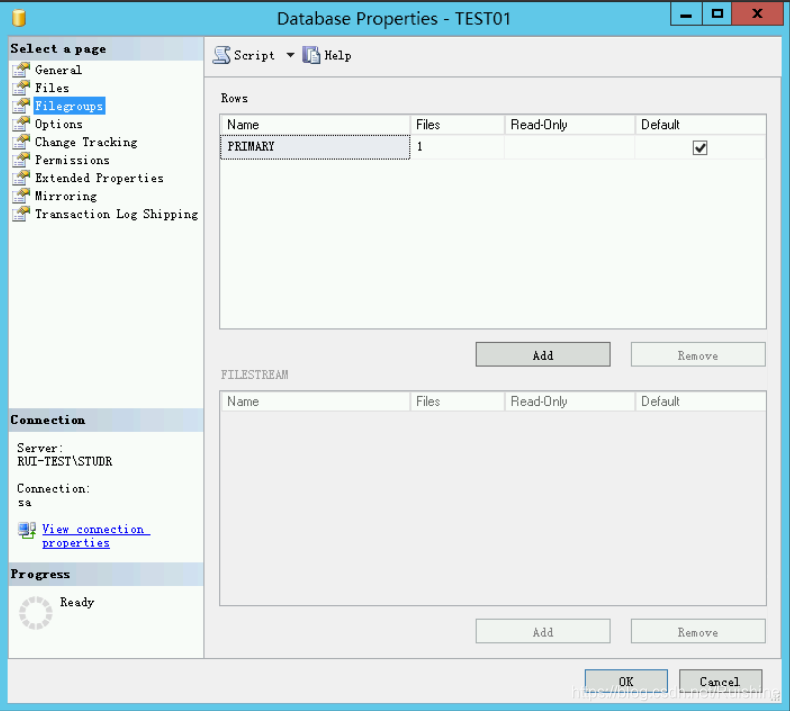
文件组是一个逻辑实体,实际上,数据存储在文件中(.mdf和.ndf)中,每一个文件组中都包含文件,如下图:

由上图可以看到,数据库文件的元数据:
Logical Name – 文件的逻辑名称,用于数据压缩 DBCC ShrinkFile 等; File Type – 文件类型,有两种:Rows Data(存储数据)和 Log(存储日志); Initial Size – 文件初始大小; Autogrowth/Maxsize – Autogrowth 表示文件自动增加的步长,
Maxsize 表示文件大小的最大值限制; Path – 文件存放路径; File Name – 文件的物理名称,逻辑名称和物理名可以不同 。
使用文件组的优势
在实际开发数据库的过程中,通常情况下,用户需要关注文件组,而不用关心文件的物理存储,即使DBA改变文件的物理存储,用户也不会察觉到,也不会影响数据库去执行查询。除了逻辑文件和物理文件的分离之外,SQL Server使用文件组还有一个优势,那就是分散IO负载,其实现的原理是:
对于单分区表,数据只能存到一个文件组中。如果把文件组内的数据文件分布在不同的物理硬盘上,那么SQL Server能同时从不同的物理硬盘上读写数据,把IO负载分散到不同的硬盘上。 对于多分区表,每个分区使用一个文件组,把不同的数据子集存储在不同的磁盘上,SQL Server在读写某一个分组的数据时,能够调用不同的硬盘IO。
3. 数据库操作
1. 使用SSMS方式
SSMS : Microsoft SqlServer Management Studio, 也就是数据库管理软件。
-
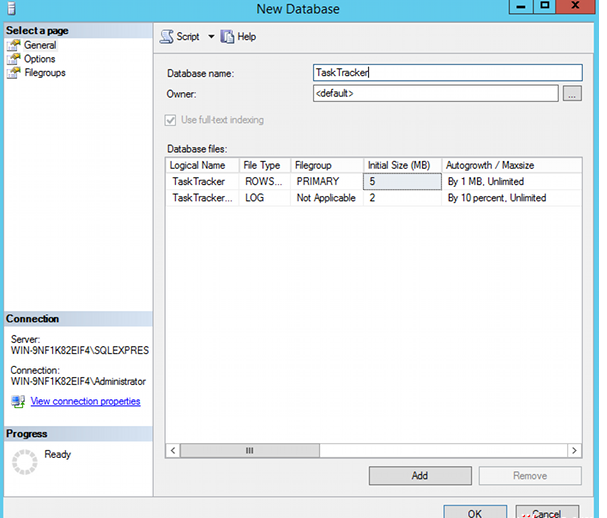
在对象资源管理器中,右键单击数据库文件夹/图标,然后选择 New database...

-
进行数据库命名,此处叫 “TaskTracker”,然后点击 “OK”
-
数据库展示

2. T-SQL 方式
1. 创建数据库
-- 创建数据库 create database 第二单元测试 -- 指定数据文件存储的文件组 on:在。。。。这上,primary:主文件组 on primary ( -- 数据库的逻辑名称:相当于是某人的外号 Name = '第二单元测试', -- 逻辑名称需要是唯一 filename = 'D:\test\第二单元测试_物理名称.mdf', -- 物理名称 size=5mb, -- 文件初始大小,初始化必须>=5 ,因为创建数据库的model 模板信息 必须是5mb以上 filegrowth = 4mb, -- 每次增长多少 maxsize =200mb -- 文件的最大值 );
2. 创建次文件
alter database 第二单元测试 add file ( -- 数据库的逻辑名称:相当于是某人的外号 Name = '第二单元测试_次文件', filename = 'E:\test\第二单元测试_次文件.ndf', -- 物理名称 size=5mb, -- 文件初始大小,初始化必须>=5 ,因为创建数据库的model 模板信息 必须是5mb以上 filegrowth = 4mb, -- 每次增长多少 maxsize =200mb -- 文件的最大值 )
3. 简化创建数据库(初学者推荐)
-- create database <数据库名称>; create database 任我行教学管理系统;
4. 删除数据库
-- 切换数据库 use master; -- drop database <数据库名称>; drop database 任我行教学管理系统;
5. 查看数据库信息
-- exec sp_helpdb '<数据库名称>' exec sp_helpdb 'Soa模拟考试'
6. 修改数据库名称
-- exec sp_renamedb '<需要修改的数据库的名称>','<新的数据库名称>' ; exec sp_renamedb '第二单元测试', -- 需要修改的数据库的名称 '第二单元' -- 新的数据库名称
7. 切换数据库
-- use <数据库名称> use 任我行教学管理系统;
4. 备份与还原
可能有一天,数据库遭黑客攻击,数据库遭破坏,这个时候就需要时常的做文件的备份。也有可能公司来了一个马大哈,把数据库给删除(删库跑路),这个时候也需要备份。
备份
-- backup database <数据库名称> to disk = '磁盘路径'; backup database 第二单元测试 to disk ='D:\test\第二单元测试.bak';
还原
-
数据库不存在的情况下
-- restore database <数据库名称> from disk = '磁盘路径' restore database 第二单元测试 from disk = 'D:\test\第二单元测试.bak'
-
数据库存在的情况下
-- with replace:替换 -- restore database <数据库名称> from disk = '磁盘路径' with replace; restore database 第二单元测试 from disk = 'E:\test\第二单元测试.bak' with replace;
5. 附加与分离
假设我有一个比较好的数据库,大家都想要,我可以发给你们,但是直接发送不了,因为会提示“这个文件在数据库SqlServer中打开”, 这个时候就需要使用分离,将这个数据库文件中SqlServer中 T 出去。
现在数据库已经分离并且数据库也发给你们了,我自己也想要用这个数据库,这个时候就要重新的附加到SQLSERVER中来
分离
-- execute:执行 -- sp_detach_db:分离的存储过程(理解为一个函数) -- execute sp_detach_db '<数据库名称>' execute sp_detach_db 'Soa模拟考试'
附加
-- 附加 -- sp_attach_db:附加的存储过程 -- exec sp_attach_db '<数据库名称>','<数据库文件所在路径>' ; exec sp_attach_db 'Soa模拟考试','C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\Soa模拟考试.mdf'
配套视频链接:【阶段二】 - SQLServer 基础(超级详细,口碑爆盆)_哔哩哔哩_bilibili