Apache Paimon流式湖仓学习交流群成立

Apache Paimon是一个流式数据湖平台。致力于构建一个实时、高效的流式数据湖平台。这个项目采用了先进的流式计算技术,使企业能够实时处理和分析大量数据。Apache Paimon 的核心优势在于它对于大数据生态系统中流式处理的支持,尤其是在高并发和低延迟方面表现出色。
目前业界主流数据湖存储格式项目都是面向 Batch 场景设计的,在数据更新处理时效性上无法满足 Streaming Lakehouse 的需求,因此 Flink 社区在一年多前内部孵化了 Flink Table Store (简称 FTS )子项目,一个真正面向 Streaming 以及 Realtime 的数据湖存储项目。
为了让 Flink Table Store 能够有更大的发展空间和生态体系,Flink PMC 经过讨论决定将其捐赠 Apache 进行独立孵化。
2023年3月12日,FTS进入 Apache 软件基金会 (ASF) 的孵化器,改名为 Apache Paimon (incubating)。
第一个流式数据湖项目诞生,流式湖仓一体成为可能,一个真正意义上的批流一体技术可能就此出现,传统Kappa架构的实时数仓体系,也迎来了一次巨大变革。
其Github地址为:https://github.com/apache/incubator-paimon
官网地址为:https://paimon.apache.org/
目前Paimon在蓬勃发展中。
Paimon 创新的结合了 湖存储 + LSM + 列式格式 (ORC, Parquet),为湖存储带来大规模实时更新能力。
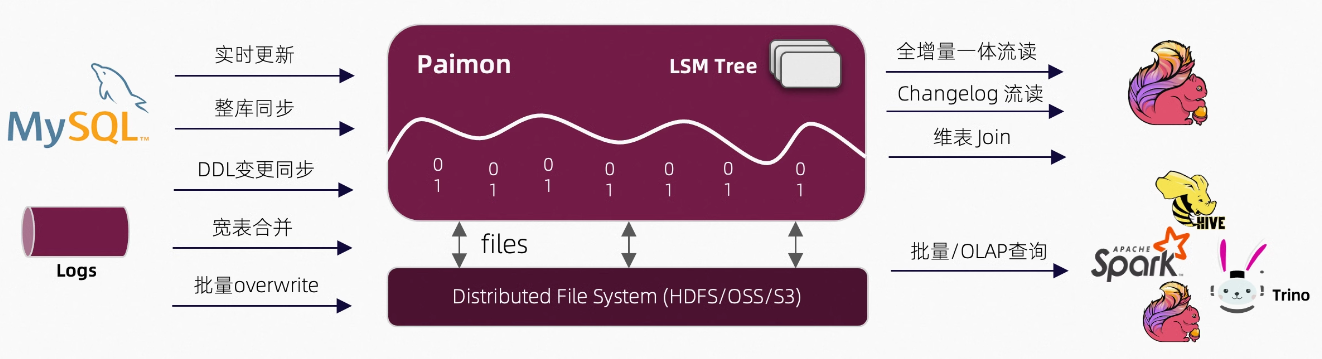
流式湖仓(Streaming Data Lakehouse)是一个结合了数据湖和数据仓库特点的新型数据存储和处理架构。它不仅支持海量数据存储,还提供了对实时数据流的处理能力,能够满足企业对数据即时分析和决策的需求。流式湖仓的出现,标志着数据处理从批处理向实时处理的转变。
目前,数据处理领域正在经历一场重大变革,流式湖仓被认为是未来的发展趋势。其原因在于:
- 实时数据处理需求日益增长:随着物联网和在线服务的发展,企业需要实时处理和分析数据以快速做出决策。
- 技术进步:流式处理技术的不断进步,使得处理大规模实时数据成为可能。
- 数据集成和治理:流式湖仓可以整合来自不同来源的数据,并提供更好的数据治理。
Apache Paimon 正是在这样的背景下应运而生。它通过提供一个高效、可伸缩、易于管理的平台,帮助企业把握实时数据处理的机遇。随着技术的不断发展和应用场景的拓展,Apache Paimon 及类似的流式湖仓解决方案将会在数据处理领域扮演越来越重要的角色。
鉴于此,大数据流动社群决定成立Apache Paimon流式湖仓学习交流社群,也希望更多对Apache Paimon感兴趣的同学加入进来。
更多大数据、数据治理、人工智能知识学习,加入学习社群,请关注大数据流动。
加入学习交流群请关注大数据流动后台回复:Paimon学习交流群
热门相关:惊世第一妃 全系灵师:魔帝嗜宠兽神妃 百炼成仙 傲娇总裁:蜜宠小甜妻! 仙碎虚空