Redis哨兵
吹哨人巡查监控后台master主机是否故障,如果故障了根据投票数自动将某一个从库转为新主库,继续对外服务
能干嘛

-
主从监控:监控主从Redis库运行是否正常
-
消息通知:哨兵可以将故障转移的结果发送给客户端
-
故障转移:如果Master异常,则会进行主从切换,将其中一个Slave作为新Master
-
配置中心:客户端通过连接哨兵来获得当前Redis服务的主节点地址
案例演示
架构
-
3个哨兵:自动监控和维护集群,不存放数据,只是吹哨人
-
1主2从:用于数据读取和存放

sentinel.conf
重点参数:
-
bind:服务监听地址,用于客户端连接,默认本机地址
-
daemonize:是否以后台daemon方式运行
-
protected-mode:安全保护模式
-
port:端口
-
logfile:日志文件路径
-
pidfile:pid文件路径
-
dir:工作目录
-
sentinel monitor < master-name > < ip > < redis-port > < quorum >:
-
设置要监控的Master服务器
-
quorum表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数
-
-
sentinel auth-pass < master-name > < password >:Master设置了密码,连接Master服务的密码
其它参数:
-
sentinel down-after-milliseconds < master-name > < milliseconds >:指定多少毫秒之后,主节点没有应答哨兵,此时哨兵主观上认为主节点下线
-
sentinel parallel-syncs < master-name > < nums >:表示允许并行同步的slave个数,当Master挂了后,哨兵会选出新的Master,此时,剩余的slave会向新的master发起同步数据
-
sentinel failover-timeout < master-name > < milliseconds >:故障转移的超时时间,进行故障转移时,如果超过设置的毫秒,表示故障转移失败
-
sentinel notification-script < master-name > < script-path > :配置当某一事件发生时所需要执行的脚本
-
sentinel client-reconfig-script < master-name > < script-path >:客户端重新配置主节点参数脚本
本次案例配置
由于硬件配置关系,本次3个哨兵都配置进同一台机器(192.168.111.169)
sentinel26379.conf
bind 0.0.0.0
daemonize yes
protected-mode no
port 26379
logfile "/myredis/sentinel26379.log"
pidfile /var/run/redis-sentinel26379.pid
dir /myredis
sentinel monitor mymaster 192.168.111.169 6379 2
sentinel auth-pass mymaster 111111
sentinel26380.conf
bind 0.0.0.0
daemonize yes
protected-mode no
port 26380
logfile "/myredis/sentinel26380.log"
pidfile /var/run/redis-sentinel26380.pid
dir "/myredis"
sentinel monitor mymaster 192.168.111.169 6379 2
sentinel auth-pass mymaster 111111
sentinel26381.conf
bind 0.0.0.0
daemonize yes
protected-mode no
port 26381
logfile "/myredis/sentinel26381.log"
pidfile /var/run/redis-sentinel26381.pid
dir "/myredis"
sentinel monitor mymaster 192.168.111.169 6379 2
sentinel auth-pass mymaster 111111
-
先启动一主两从3个Redis实例,测试正常的主从复制

设置好 replicaof < masterip> < masterport>

设置好masterauth项访问密码,(6379后续可能会变成从机,故需要设置访问新主机的密码)不然后续可能报错 master_link_status:down

-
再启动3个哨兵,完成监控
redis-sentinel sentinel26379.conf --sentinel
redis-sentinel sentinel26380.conf --sentinel
redis-sentinel sentinel26381.conf --sentinel
-
手动关闭6379服务器,模拟master挂了。
两台从机数据是否OK?OK!
是否会从剩下的2台机器上选出新的master?会!
之前宕机的master机器重启回来,谁将是新的老大?会不会双master冲突?已经被篡位了,回来变小弟!
-
关闭6379后另外两个服务器可能会出现以下两种情况中的一种:


然后过几秒钟就会恢复正常,两台剩余从机中会选出新的master
by the way
配置文件内容在运行期间会发生改变,被sentinel动态更改了。
Master-Slave切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换。
备注
-
哨兵本身不涉及业务,不涉及高并发,压力不大。
-
生产都是不同机房不同服务器,很少出现3个哨兵全挂掉的情况。
-
可以同时监控多个master,一行一个。
哨兵的运行流程和选举原理
当一个主从配置中的master失效之后,sentinel可以选举出一个新的master用于自动接替原master的工作,主从配置中的其他redis服务器自动指向新的master同步数据。一般建议sentinel采取奇数台,防止某一台sentinel无法连接到master导致误切换。
过程:
-
三个哨兵一主二从,正常运行中。。。。。。

-
SDown主观下线(Subjectively Down)
SDown(主观不可用)是单个sentinel自己主观上检测到的关于master的状态,从sentinel的角度来看,如果发送了PING心跳后,在一定时间内没有收到合法的回复,就达到了SDown的条件。
sentinel配置文件中的down-after-milliseconds设置了判断主观下线的时间长度。
说明:
所谓主观下线(Subjectively Down, 简称 SDOWN)指的是单个Sentinel实例对服务器做出的下线判断,即单个sentinel认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。主观下线就是说如果服务器在[sentinel down-after-milliseconds]给定的毫秒数之内没有回应PING命令或者返回一个错误消息, 那么这个Sentinel会主观的(单方面的)认为这个master不可以用了,o(╥﹏╥)o

sentinel down-after-milliseconds < masterName > < timeout >
表示master被当前sentinel实例认定为失效的间隔时间,这个配置其实就是进行主观下线的一个依据
master在多长时间内一直没有给Sentine返回有效信息,则认定该master主观下线。也就是说如果多久没联系上redis-servevr,认为这个redis-server进入到失效(SDOWN)状态。
-
ODown客观下线(Objectively Down)
ODOWN需要一定数量的sentinel,多个哨兵达成一致意见才能认为一个master客观上已经宕掉。
说明:
四个参数含义:
masterName是对某个master+slave组合的一个区分标识(一套sentinel可以监听多组master+slave这样的组合)

quorum这个参数是进行客观下线的一个依据,法定人数/法定票数
意思是至少有quorum个sentinel认为这个master有故障才会对这个master进行下线以及故障转移。因为有的时候,某个sentinel节点可能因为自身网络原因导致无法连接master,而此时master并没有出现故障,所以这就需要多个sentinel都一致认为该master有问题,才可以进行下一步操作,这就保证了公平性和高可用。
-
选出领导者哨兵(哨兵中选出兵王)
当主节点被判断客观下线后,各个哨兵节点会进行协商,先选举出一个领导者哨兵节点(兵王)并由该领导者节点,进行failover(故障迁移)。
哨兵领导者(兵王)是如何选出来的?Raft算法。
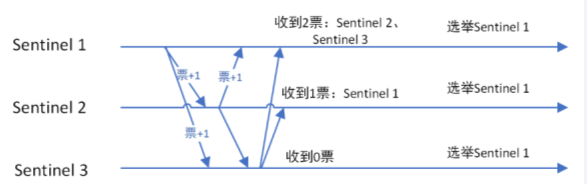
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得:
即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者。
-
由兵王开始推动故障切换流程并选出一个新的master
-
新主登基:某个slave被选中称为新Master。
规则:剩余slave节点健康的前提下:
-
redis.conf文件中,优先级slave-priority或者replica-priority最高的从节点(数字越小优先级越高)
-
复制偏移位置offset最大的从节点
-
最小的Run ID从节点(字典顺序,ASCII码)

-
-
群臣俯首:一朝天子一朝臣,换个码头重新拜
执行slaveof no one命令让选出来的从节点成为新的主节点,并通过slaveof命令让其他节点成为其从节点。
sentinel leader会对选举出的新Master执行slaveof no one操作,将其提升为Master节点。
sentinel leader向其他slave发送命令,让剩余的slave成为新的Master节点的slave。
-
旧主拜服:老Master回来也得低头
将之前已下线的老Master设置为心选出的新Master的从节点,当老Master重新上线后,它会成为新Master的从节点。
sentinel leader会让原来的Master降级为slave并恢复正常工作。
上述的failover操作均由sentinel自己独立完成,完全无需人工干预。
-
哨兵使用建议
-
哨兵节点的数量应该为多个,哨兵本身应该集群,保证高可用。
-
哨兵节点的数量应该是奇数
-
各个哨兵节点的配置应一致
-
如果哨兵节点部署在Docker等容器里面,尤其要注意端口的正确映射
-
哨兵集群+主从复制 并不能保证数据零丢失!承上启下引出集群!
-