对比 SQL Server中的VARCHAR(max) 与VARCHAR(n) 数据类型
VARCHAR(max) SQL Server数据类型概述
CREATE TABLE dbo.Employee_varchar_2000 (id INT IDENTITY PRIMARY KEY, Col1 VARCHAR(2000) ); CREATE TABLE dbo.Employee_Varchar_4500 (id INT IDENTITY PRIMARY KEY, Col1 VARCHAR(4500) ); CREATE TABLE dbo.Employee_Varchar_8000 (id INT IDENTITY PRIMARY KEY, Col1 VARCHAR(8000) ); CREATE TABLE dbo.Employee_Varchar_Max (id INT IDENTITY PRIMARY KEY, Col1 VARCHAR(MAX) );
INSERT INTO Employee_varchar_2000 (Col1) SELECT REPLICATE('A', 2000); INSERT INTO Employee_varchar_4500 (Col1) SELECT REPLICATE('A', 4500); INSERT INTO Employee_varchar_8000 (Col1) SELECT REPLICATE('A', 8000); INSERT INTO Employee_varchar_max (Col1) SELECT REPLICATE('A', 8000);
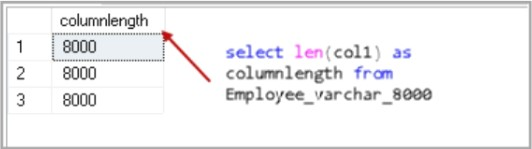
Use SQLShackDemo go SELECT LEN(col1) AS columnlength FROM Employee_varchar_2000; SELECT LEN(col1) AS columnlength FROM Employee_varchar_4500; SELECT LEN(col1) AS columnlength FROM Employee_varchar_8000; SELECT LEN(col1) AS columnlength FROM Employee_varchar_max;
SELECT OBJECT_NAME([object_id]) AS TableName, alloc_unit_type_desc, record_count, page_count, round(avg_page_space_used_in_percent,0) as avg_page_space_used_in_percent , min_record_size_in_bytes, max_record_size_in_bytes FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'DETAILED') WHERE OBJECT_NAME([object_id]) LIKE 'Employee_varchar%';

INSERT INTO Employee_varchar_8000 (Col1) SELECT REPLICATE(CONVERT(VARCHAR(max), 'x'), 8001);
它成功地在Employee_varchar_max表中插入了记录。


我们可以得出以下结论:
如果数据小于或等于8000字节,SQL Server使用IN_ROW_DATA页来存储varchar(max)数据类型的数据。
如果数据超过8000字节,SQL Server使用LOB_DATA页来存储varchar(max)数据类型的数据。
varchar(max)和varchar(n)数据类型之间的性能比较
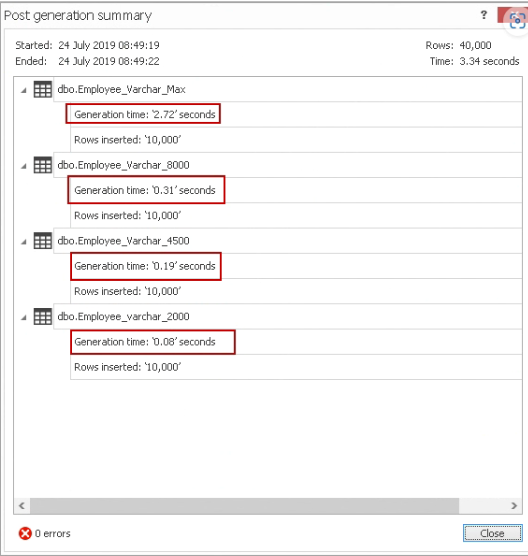
让我们将10,000条记录插入到我们之前创建的每个表中。我们想检查数据插入时间。您可以使用ApexSQL Generate工具插入数据,而无需编写T-SQL代码。
在下面的屏幕截图中,您可以注意到以下几点。 译者注:我们无需关注原文作者使用的工具本身,只需要看他的测试方法和得到的结论
Employee_varchar_2000插入时间0.08秒
Employee_varchar_4500插入时间0.19秒
Employee_varchar_8000插入时间0.31秒
Employee_varchar_Max插入时间2.72秒
在 VARCHAR(N) and VARCHAR(MAX) 列上创建索引
CREATE INDEX IX_Employee_varchar_2000_1 ON dbo.Employee_varchar_2000(col1) GO
CREATE INDEX IX_Employee_varchar_max ON dbo.Employee_varchar_max(col1) GO
Msg 1919, Level 16, State 1, Line 23 Column ‘col1’ in table ‘dbo.Employee_varchar_max’ is of a type that is invalid for use as a key column in an index.
执行计划(Execution plan)对比
让我们比较两个select语句的执行计划。
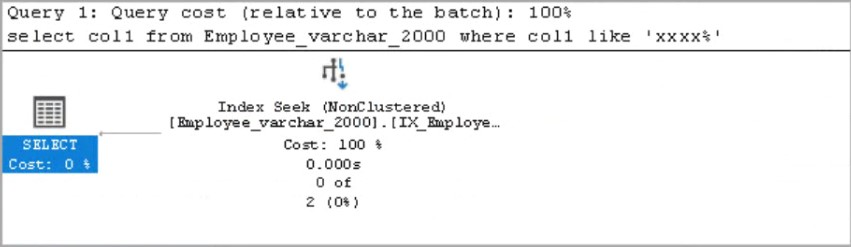
在第一个查询中,我们想从Employee_Varchar_2000表中检索数据并获取实际的执行计划。
在实际的执行计划中,我们可以看到一个非聚集索引查找操作符。
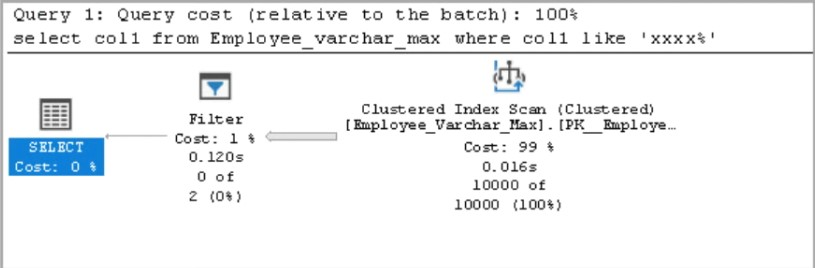
如果我们使用varchar(max)数据类型运行相同的查询,它会使用聚集索引扫描操作符,并且根据表中的行数,它可能是一个资源密集型操作符。
select col1 from Employee_varchar_max where col1 like ‘xxxx%’
让我们使用SSMS的Compare Showplan选项比较执行计划。
要比较两个执行计划,右键单击其中一个执行计划并选择Save Execution Plan As,然后提供要保存该计划的路径。在另一个查询执行计划中,右键单击并选择Compare Showplan。它打开一个窗口,您可以在其中指定先前保存的执行计划的路径。在下面的屏幕截图中,您可以看到两个执行计划之间的比较。
2,对于varchar(max),它使用聚集索引扫描操作符并扫描所有记录。您可以看到,估计的行数是10000行,而在varchar(2000)数据类型中,它使用索引查找操作符,估计的行数是1.96078行
3,估计的行大小4035 B大于varchar(max)中的1011 B,与varchar(2000)数据类型相比
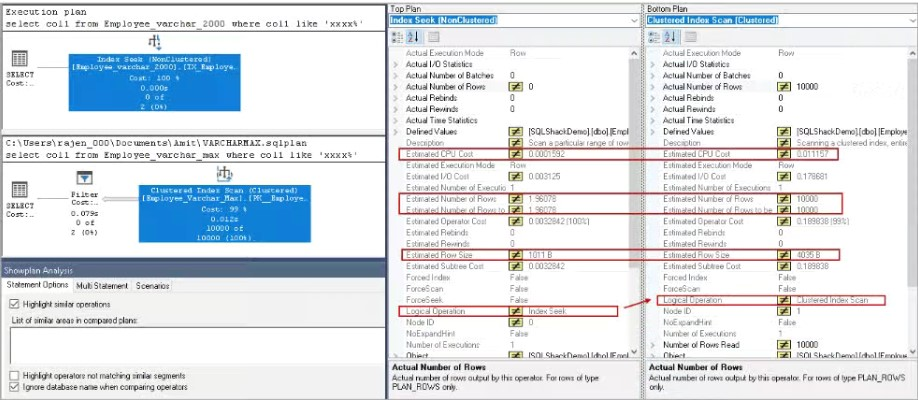
译者注:这部分原作者想表达的是:对于varchar(max)类型字段,数据库优化器在编译SQL生成执行计划的时候会需要更多的CPU资源,同时对于数据行的预估也没有varchar(n)准确
varchar(max) and varchar(n) 数据类型的不同之处
| varchar(max) | varchar(n) |
| 这种数据类型最多可以存储2gb的数据 | 这种数据类型最多可以存储8000字节的数据 |
| 它使用分配单元IN_ROW_Data最多8000字节的数据。如果数据大于8000字节,则使用LOB_Data页,并将其指针存储在IN_ROW_Data页中 | 它将数据存储在标准数据页中 |
| 不能在varchar(max)数据类型的键列上创建索引 | 可创建索引 |
| 不能压缩LOB数据 | 可压缩 |
| LOB数据的数据检索和更新相对较慢 | 在varchar(n)数据类型中不会遇到这样的问题 |
总结
笔者补充
1,执行计划差异
鉴于varchar(max)字段不支持创建索引,其实已经完全没有进一步做性能测试的必要了,为了把问题说清楚,那么就在没有索引的情况下继续对比测试下去,单纯地比较两种字段类型在生产执行计划时的差异。create table sb_test1 ( c1 int identity(1,1), c2 varchar(50), c3 varchar(50), c4 varchar(50), c5 varchar(50), c6 varchar(50), c7 varchar(50), c8 varchar(50), c9 varchar(50), c10 datetime2 ); create table sb_test2 ( c1 int identity(1,1), c2 varchar(max), c3 varchar(max), c4 varchar(max), c5 varchar(max), c6 varchar(max), c7 varchar(max), c8 varchar(max), c9 varchar(max), c10 datetime2 ); declare @i int = 0; begin tran while @i<1000000 begin insert into sb_test1 values (newid(),newid(),newid(),newid(),newid(),newid(),newid(),newid(),sysdatetime()) set @i = @i + 1; end commit go 10 insert into sb_test2 select c2,c3,c4,c5,c6,c7,c8,c9,c10 from sb_test1
以上新建两张表结构和数据一样的表,sb_test1表字段用varchar(50),sb_test2表字段用varchar(max),都是1000W行数据。
1,对于同一个查询,执行计划的Memory Grant明显不一样,varchar(max)类型字段的表的执行计划内存(memory grant)明显要高很多。


2,对于同一个查询,谓词predicate过滤的时机也不一样,varchar(n)可以再扫描的过程中实现谓词过滤(边扫描边过用where条件滤),而varchar(max)只能在将表扫描完之后,在内存中单独执行谓词过滤(完全扫描之后再用where条件过滤)
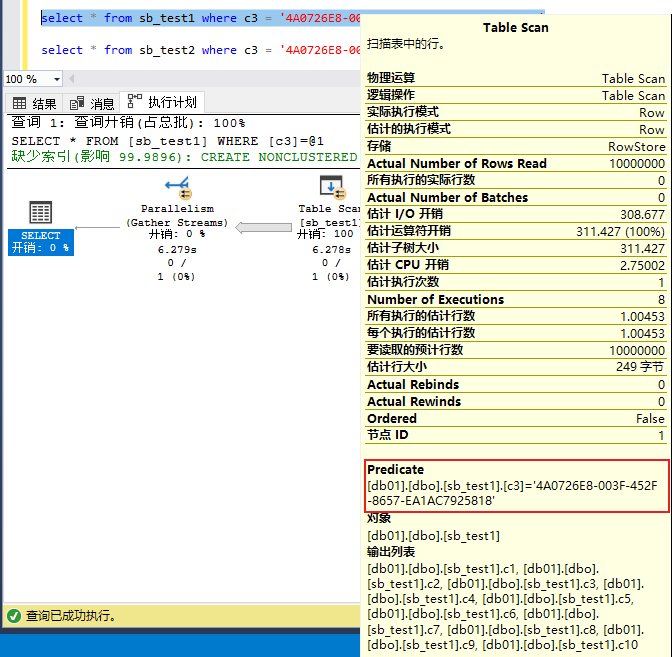
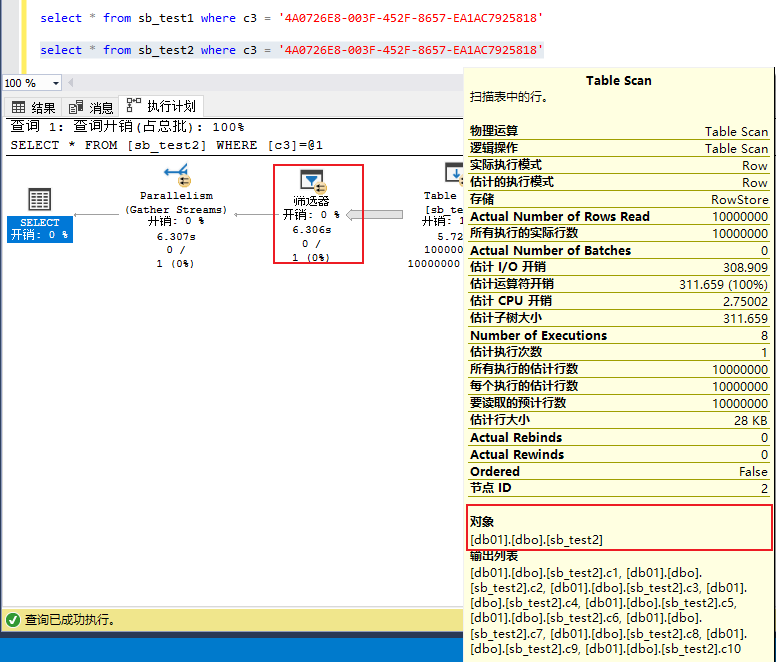
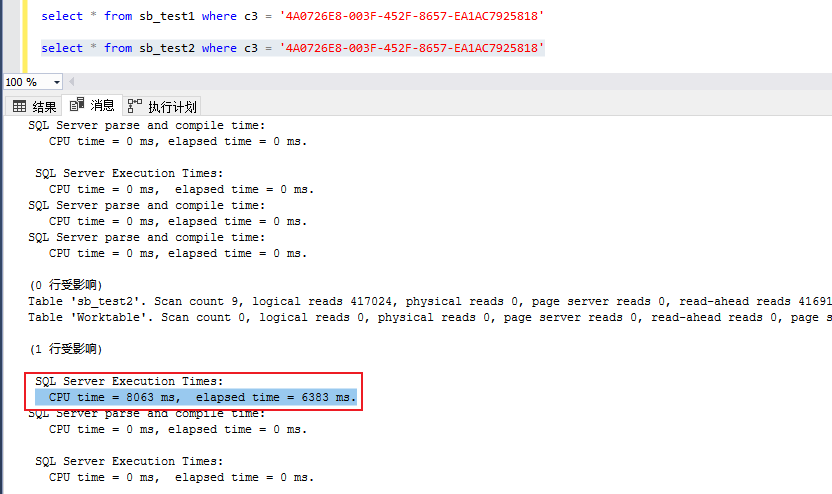
3,对于同一个查询,执行结果中的的CPU资源消耗明显不一样(基于上述中的2,执行计划无法再扫描的时候进行谓词过滤),varchar(max)类型字段的表的查询要varchar(n)高2倍多。

再总结
不单单是字符型数据,包括整型(tinyint,smallint,int,bigint),时间类型(date,time,smalldatetime,datetime,datetime2)等等,具体的类型选择是基于业务的,不是基于ORM好不好处理的问题。
错误的做法没有造成特别明显的问题,这并不是说明这就是可行的,而是是因为数据量没到,不要把错误的经验当成经验使用。
热门相关:我的黑月光女友 诛天至极 惊世第一妃:魔帝,宠上身! 万道龙皇 万道龙皇