HBase
请回答以下问题。
1.由于数据过多,HBase 频繁地 Region 分裂,什么方法最合适?
A.预分 Region B.增大 Region 大小 C.增大 MemStore,减少 Flush D.提升 RegionServer 资源。

一、HBase 简介
HBase 数据模型
HBase 的底层物理存储结构(K-V)来看,HBase 更像是一个 Multi-dimensional(多维) Map。
HBase 逻辑结构
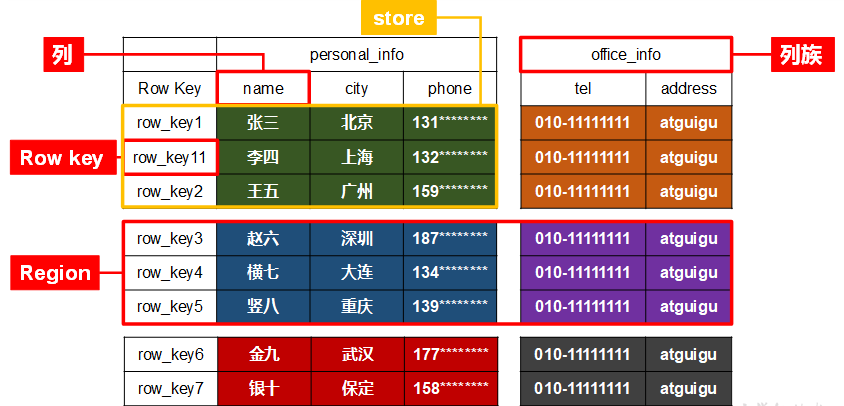
HBase 存储结构

StoreFile(HFile)
StoreFile 以 HFile 格式保存在 HDFS 上,是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
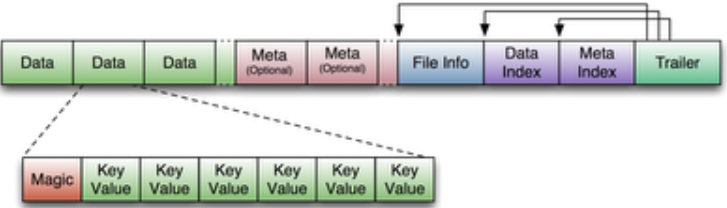
- Data Block:保存表中的数据,这部分可以被压缩。数据存放在 Data 块中,Data 块的大小可以用户指定,大的 Data 块适合 Scan,小的 Data 块适合随机查找。
- Meta Block(可选):保存用户自定义的 Key-Value 对,可以被压缩。HFile 里面的每个 KeyValue 对就是一个简单的 Byte 数组。但是这个 Byte 数组里面包含了很多项,并且有固定的结构。
- File Info:HFile 的元信息,不可被压缩,用户也可以在着一部分添加自己的元信息。
- Data Block Index:Data Block 的索引。每条索引的 Key 是被索引的 Block 的第一条记录的 Key,同时需要将索引一次性读入内存。
- Meta Block Index:Meta Block 的索引,同 Data Block Index 段。
- Trailer:这一段是定长的。保存了每一段的偏移量,读取一个 HFile 时,会首先读取 Trailer,Trailer 保存了每个段的起始位置(段的 Magic Number 用来做安全 Check),然后 DataBlock Index 会被读取到内存中。DataBlock Index 采用 LRU 机制淘汰。
HFile 中 Block 存储的数据
HFile 里面的每个 KeyValue 对就是一个简单的 Byte 数组。但是这个 Byte 数组里包含了很多项,并且有固定结构。

开始是两个固定长度的数值,分别表示 Key 的长度和 Value 的长度。紧接着是 Key,开始是固定长度的数值,表示 Rowkey 的长度,紧接着是 Rowkey,然后是固定长度的数值,表示 Family 的长度,然后是 Column Family,接着 Column Qualifier(限定符),然后是两个固定长度的数值,表示 TimeStamp 和 Key Type(Put/Delete)。Value 部分没有这么复杂的结构,就是纯粹的二进制数据了。
在 HFile 中的数据是按 Rowkey、Column Family、Column 排序,对相同的 Cell(即这三个值都一样),则按 TimeStamp 倒序排列。
Store(HStore)
HFile 存储在 Store 中,一个 Store 对应 HBase 表中的一个列族 Column Family,即每个 Column Family 就是一个集中的存储单元,因此最好就具有相近 IO 特性的 Column 存储在一个 Column Family,以实现高效读取(数据局部性原理,可以提高缓存的命中率)。
一个 HRegion 由多个 Store 组成,一个 Store 由一个 MemStore 和 0 个或多个 HFile 组成,Store 包括内存的 MemStore 和位于硬盘的 StoreFile。
MemStore
内存存储,位于内存中,用来保存当前的数据操作。
每个 HStore 中都有一个 MemStore,即它是一个 HRegion 的一个 Column Family 对应一个实例。它的排列顺序以 Rowkey、Column Family、Column 的顺序以及 TimeStamp 的倒序(HFile 已经说过)。客户端检索数据时,先在 MemStore 找,找不到再找 StoreFile。
写操作先写入 MemStore,当 MemStore 中的数据量达到某个阈值(默认为 128M),或者 HRegionServer 上所有 MemStore 的大小超过了机器上默认 40% 的内存使用量,或者 WAL 过大这三种情况下,HRegionServer 启动 Flashcache 进程写入 StoreFile,每次写入形成单独一个 StoreFile,输出多个 StoreFile 后,当 StoreFile 数量达到阈值时,将多个合并成一个大的 StoreFile。当 StoreFile 大小超过一定阈值后,会把当前的 Region 分割成两个,并由 HMaster 分配给相应的 Region 服务器,实现负载均衡。
HBase 物理结构
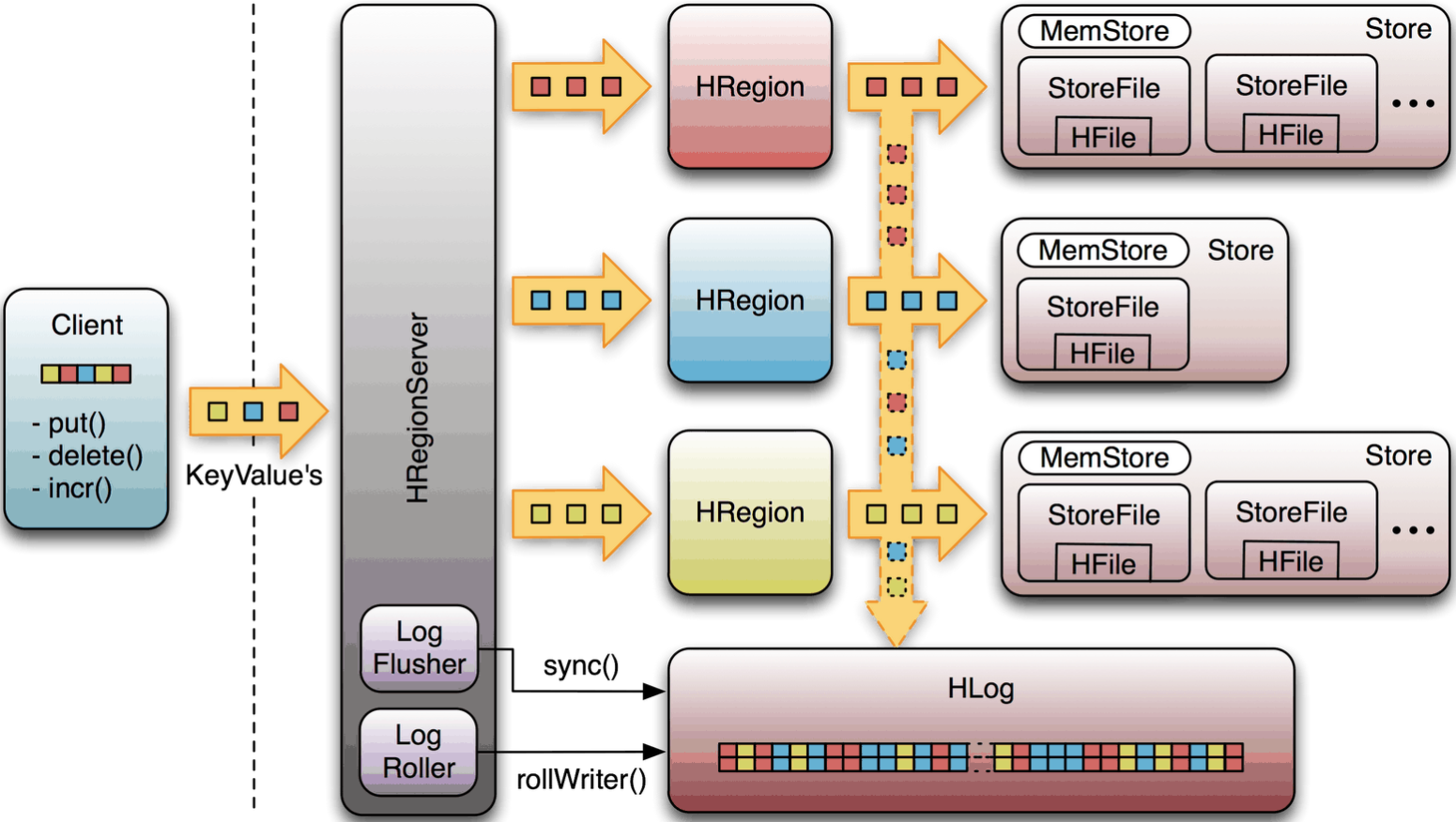
- Table 中的所有行都按照 Rowkey 的字典顺序进行排列,HBase 就是一个庞大的 HashMap,Rowkey 字典顺就是类似 HashMap 中的 Key 的哈希算法排序的。
- Table 在通过 Rowkey 来进行行的方向上分割为多个 HRegion,类似于 Hadoop 下 MapReduce 中的文件切割。
- HRgion 是按大小分割的(默认为 10G),每个表一开始只有一个 HRegion,随着表中的数据不断增加,HRegion 不断增大,当增大到一个阈值的时候,HRegion 就会分为两个新的 HRegion,当表中的行不断增多,就会有越来越多的 HRgion。
- HRegion 是 HBase 中分布式存储和负载均衡的最小单元。最小单元表示不同 HRegion 可以分布在不同的 HRegionServer 上。但是一个 HRegion 是不会拆分到多个 Server 上的。
- HRegion 虽然是负载均衡的最小单元,但并不是物理存储的最小单元。事实上,HRegion 是由一个或多个 Store 组成,每个 Store 保存一个 Column Family。每个 Store 又由一个 MemStore 和 0 到多个 StoreFile 组成。
HBase 术语解释
NameSpace:命名空间,类似关系型数据库 DataBase。HBase 默认自带两个命名空间,分别为 Hbase、default,hbase 中存放的是 HBase 内置系统表,default 表是用户默认使用的命名空间。
Table:表,类似关系型数据库 Table。HBase 定义表只需要声明列族即可,数据属性比如超时时间(TTL),压缩算法(COMPRESSION)等,都在列族的定义中定义,不需要声明具体的列,这意味着,往 HBase 写入数据时,字段可以动态、按需指定。
Row:行,HBase 的行数据都由一个 Rowkey 和多个 Column (列)组成。一个行包含了多个列,这些列通过列族来分类,行中的数据所属列族只能从该表所定义的列族中选取,不能查询这个表中不存在的列族,否则报错。
Rowkey:行健,Rowkey 有用户指定的一串不重复的字符串定义,是一行的唯一标识!数据是按照 Rowkey 的字典顺序存储的,并且查询数据时只能根据 Rowkey 进行检索,所以 Rowkey 的设计十分重要,设计 Key 时,要充分考虑排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
HRegion 大小达到一定值值时,会进行按 Rowkey 裂变,HBase Table 中的行的三种方式。
- 通过单个 Rowkey 访问
- 通过 Rowkey 的 Range(正则)
- 全表扫描
Column Family:列族,是多个列的集合,一个列族可以动态地灵活定义多个列。表的相关属性大部分都定义在列族上,同一个表里的不同列族可以有完全不同的属性配置,但是同一个列族内的所有列都会有相同的属性。
每个列族对应一个 Store,也对应 HDFS 一个目录,类似于 Hive 分区操作一样,HBase 相当于按列族进行了分区。列族是表的 Schema 的一部分(而列不是,Schema 包含表名和列族)。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。列族越多,在取一行数据时所要参与 IO、搜寻的文件就越多。如果没有必要,不要设置太多列族。
Column Qualifier:列限定符,列是可以随意定义的,一个行的列不限名字、不限数量,只限定列族。因此列必须依赖于列族存在!列的名称前必须要戴着其所属的列族!例如 info:name, info:age。
TimeStamp:时间戳,用于标识数据的不同版本(version)。时间戳默认由系统指定,读取默认获取最新版本的数据返回。
每个 Cell 都保存着同一份数据的多个版本,版本通过时间戳来索引,时间戳的类型是 64 为整型。一定要用单 Cell 中不重复的时间戳。HBase 提供两种机制:保留最新的 N 条数据,或保留截止当下多长时间的数据。
Region:域。
Region 由一个表若干行组成!在 Region 中行的排序按照行健(Rowkey)字典排序。
Region 不能跨 RegionServer,且当数据量大的时候,HBase 会拆分 Region。
Region 由 RegionServer 进程管理。HBase 在进行负载均衡的时候,一个 Region 有可能会从当前 RegionServer 移动到其他 RegionServer 上。
Region 是基于 HDFS 的,它的所有数据存取操作都是调用了 HDFS 的客户端接口来实现的。
Cell:单元格,Cell 是存储数据的最小单元Cell 由{Rowkey, Column Family: Column Qualifier, TimeStamp} 确定,Cell 中的数据是没有类型的,全部是字节码形式存贮的。
VersionNum:版本号,每条数据可以有多个版本号,默认值为系统时间戳,类型为 Long。
WAL:WAL 意为 Write-Ahead logs,HLog 文件就是一个普通的 Hadoop Sequence File,类似 MySQL 中的 BinLog,用来做灾难恢复时用,HLog 记录数据的所有变更,一旦数据修改,就可以从 Log 中进行恢复。
当对 HBase 读写数据的时候,数据不是直接写进磁盘,她会在内存中保留一段时间(时间以及数据量阈值可以设定)。所有写操作都会先保证将数据写入这个 Log 文件(每个 RegionServer 维护一个 HLog,每个 HRegionServer 只有一个)后,才会真正更新 MemStore,最后写入 HFile 中。这样即使 HRegionServer 宕机,我们依然可以从 HLog 中恢复数据。
HLog 的切分机制:
- 当数据写入 HLog 以后,HBase 发生异常,关闭当前的 HLog 文件。
- 当日志的大小达到 HDFS 数据块的 0.95 倍的时候,关闭当前日志,生成新的日志。
- 每隔一小时生成一个新的日志文件。
HBase 1.0 以后的版本,多个 WAL 并行写(MultiWAL),实现采用 HDFS 的多个管道写,以单个 HRegion 为单位。
HFile 内部优化
在最新版本的 HBase 中,为了解决 HFile 中不定长部分的内存占用,特别是 Bloom File(海量数据 Block File 所占内存空间)和 Block Index 过大。吧 Bloom File 和 Block Index 打散放入 Data,每次查询不用加载全部信息。它本质上就是一个多层的类B+树索引,采用这种设计,可以实现不需要读取整个文件。
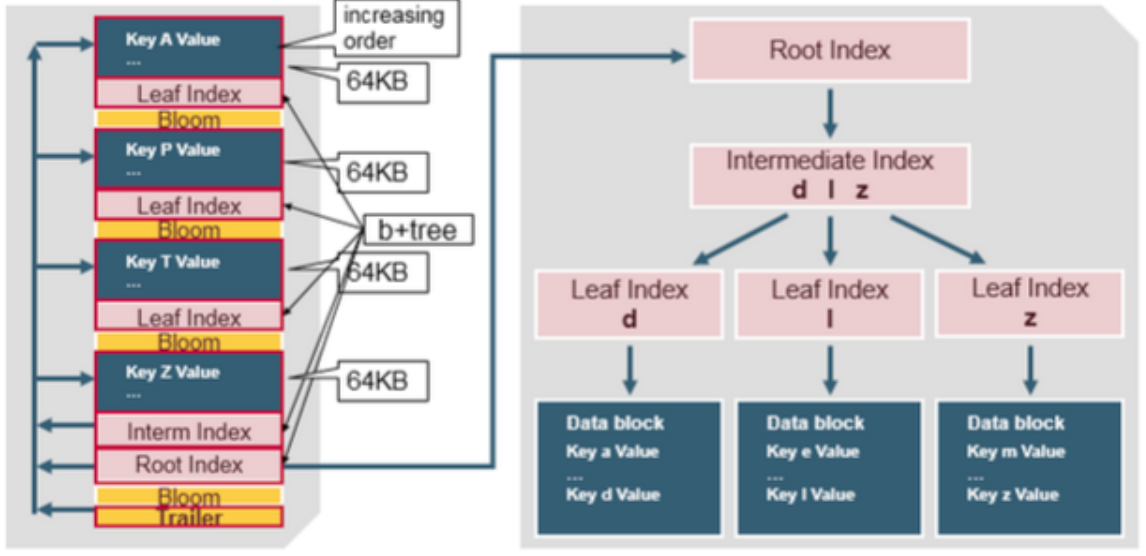
Data Block 中的 Cell 都是升序排列,每个 Block 都有它自己的 Leaf-Index,每个 Block 的最后一个 Key 被放入 Intermediate-Index 中,Root-Index 指向 Intermediate-Index。Bloom 过滤器用于快速定位没有在 DataBlock 中的数据。
Store(HStore):
HFile 存储在 Store
HBase 基础架构
HBase 依然采用 Master/Worker 架构搭建集群,它隶属于 Hadoop 生态圈,依附于 Zookeeper 集群的协调一致性服务,有HMaster 节点和 HRegionServer 节点组成。而在底层,将数据存储在 HDFS 中,因而涉及到 HDFS 的 NameNode、DataNOde 等,总体结构如下:

Client 客户端
HBase 有一张特殊的表 META 存储了用户 Table 的 RegionInfo 信息,它可以被切分成多个 Region。
Zookeeper 也有一张特殊的表 ROOT 存储了 META 表的 RegionInfo 信息。 而 META 表则
Zookeeper 集群协调一致性服务
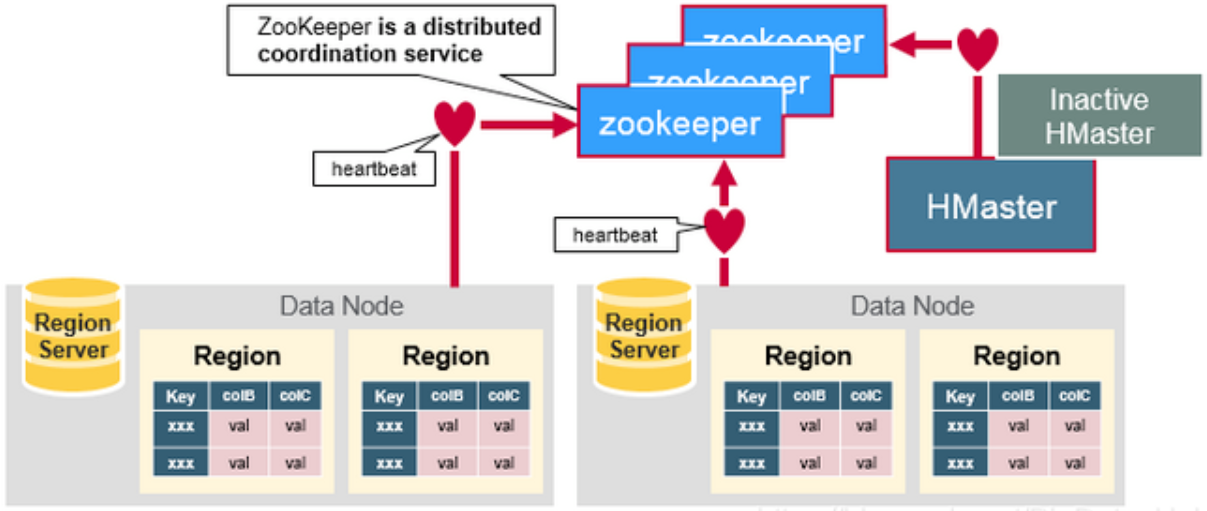
- 协调监督保障 HMaster 高可用,通过 Failover 竞争机制产生新的 HMaster。
- 监控 HRegionServer 的状态,HMaster 会通过 Zookeeper 收到 HRegionServer 上下线状态。
- 元数据入口地址,ROOT 表在哪台服务器上,ROOT 这张表的位置信息,存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family,包括具体的数据段放在哪个 RegionServer 上。Zookeeper 中记录了读取数据所需要的源数据表 hbase:meta,因此关闭 Zookeeper 后,客户端无法实现读操作的!
HMaster 主节点
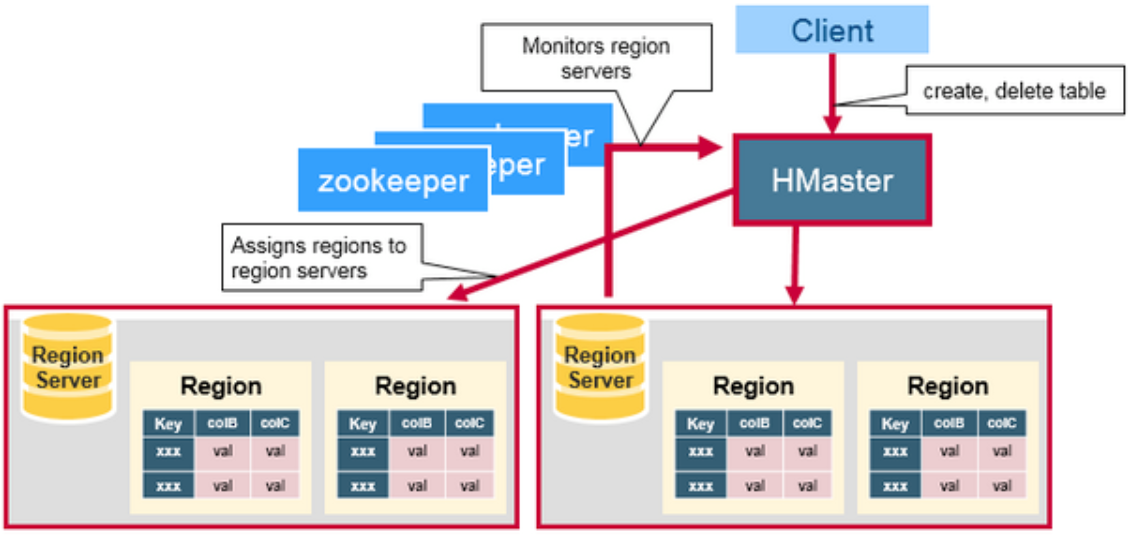
- 故障转移:监控 HRegionServer,当某 HRegionServer 异常或死亡,将 HRegion 转移到其他 HRegionServer 上执行(通过与 Zookeeper 的 HeartBeat 和监听 Zookeeper 中的状态,并https://img2024.cnblogs.com/blog/1644206/202405/1644206-20240520143213793-1512492846.png不直接和 Slave 相连)。
- 新 HRegion:HRegion 分裂后的重新分配。
- 元数据变更(Admin 职能):增删改 Table 操作:Create、Delete、alter,这些操作可能需要跨多个 RegionServer,需要 HMaster 来进行协调。
- 数据负载均衡:空闲时在 HRegionServer 之间迁移 HRegion。
- 发送自己位置给 Client:通过 Zookeeper 实现。
HMaster 主节点类似于 Hadoop 系统 Yarn 核心体系中的组件 ResourceManager 的 ResourceScheduler,进行资源分配和调度。
即使 HMaster 进程宕机,集群依然可以执行数据的读写,只是不能进行表的创建和修改操作!
HRegionServer 节点
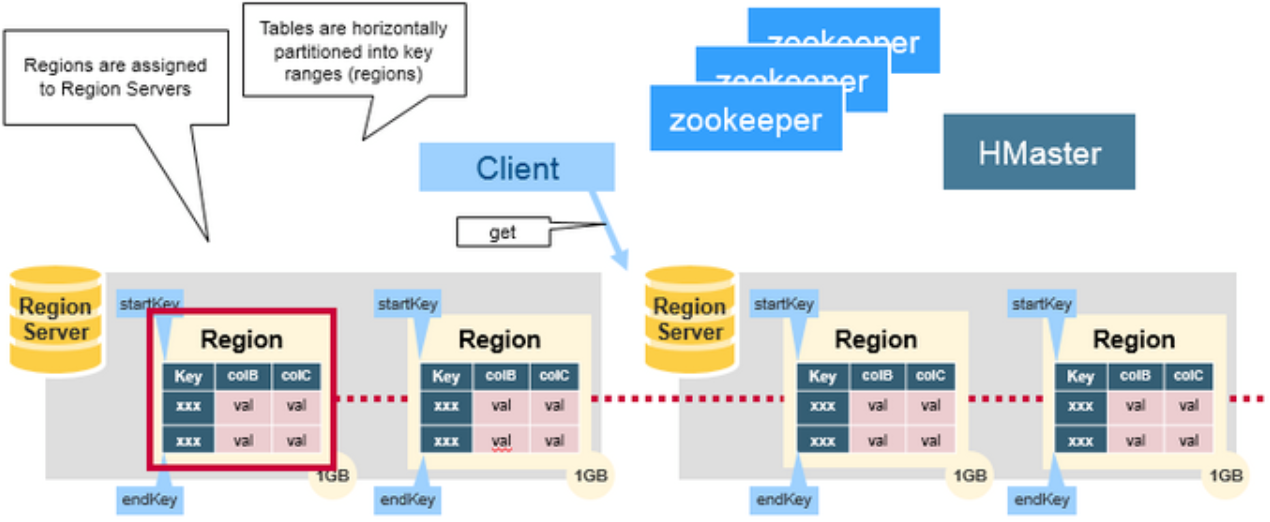
- 处理分配的 HRegion,对于数据的操作:get、put、delete。
- 刷新 Cache(读写缓存) 到 HDFS
- 维护 WAL(Write Ahead Log, HLog)(高容错)
- 处理来自用户 Client 的读写请求
- 处理 HRegion 变大后的拆分 SplitRegion。
- 负责 StoreFile 的合并工作 CompactRegion。
Client 访问 HBase 数据的过程不需要 HMaster 参与,从 Zookeeper 获取 RegionServer 地址,HMaster 仅仅维护着 Table 和 Region 的元数据信息,负载很低。
BigTable 指出:一个 HRegionServer 可以存放 1000 个 HRegion(通过配置文件更改)
HBase 使用 Rowkey 将表水平切割成多个 HRegion,从 HMaster 的角度,每个 HRegion 都纪录了它的 StartKey 和 EndKey(第一个 HRegion 的 StartKey 为空,最后一个 HRegion 的 EndKey 为空,类似链表),由于 Rowkey 是排序的,因而 Client 可以通过 HMaster 快速定位每个 Rowkey 在哪个 HRegion 中。
底层 Table 数据存储于 HDFS 中,而 HRegion所处理的数据尽量和数据所在的 DataNode 在一起,实现数据的本地化,数据本地化并不是总能实现,比如在 HRegion (因 Split)移动,需要等到下一次 Compact 才能继续回到本地化。
HDFS
- 提供元数据和表数据的底层分布式存储服务。
- WAL(Write Ahead Log, HLog) 落盘。
- 数据多副本,保证高可靠、高可用。
二、HBase 安装
略(2024-09 补充)
三、HBase Shell 操作
其他操作
# 进入HBase Shell 命令行
hbase shell
# 查看集群状态
status
# 查看版本
version
# 查看操作用户及组信息
whoami
# 查看表操作信息
table help
# 查看帮助信息
help
# 查看具体命令的帮助(引号是必须的)
help 'get'
表操作
# 列举表(list 后可以使用 * 通配符来进行表的过滤)
list
# 创建表,需要指定表名和列族名,至少需要指定一个列族
# 可以指定表的列,表的列需要指定在列族上
create 'tablename',{}
附录:概念介绍
HBase 大规模采用的原因。
关系型数据库查询瓶颈:
① 高并发的更新(插入、修改、删除)
② 多表关联后的复杂查询,频繁的 group by、order by。
CAP 定理
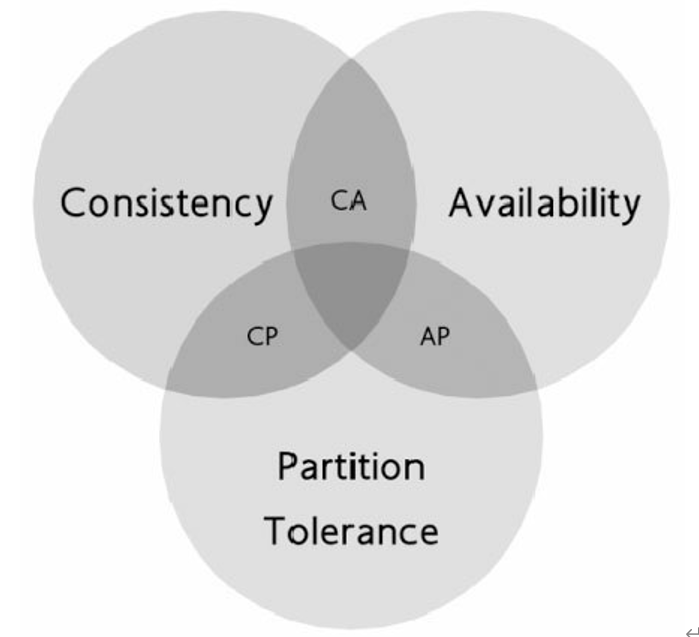
- Consistency(强一致性):数据更新操作的一致性,所有数据变动都是同步的。
- Availabbility(高可用性):良好的响应性能。
- Partition tolerance:可靠性。
Brewer 教授给出的定理是:任何分布式可同时满足二点,没法三者兼顾。
Brewer 教授给出的忠告是:架构师不要将精力 浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。
NoSQL(分布式、不支持事务、键值对存储)
最早出现于 1998 年,Carlo Strozzi 开发的一个轻量、开源、不提供 SQL 功能的数据库。
NoSQL 被普遍理解为"Not Only SQL",NoSQL 和传统的关系型数据库在很多场景下是相辅相成的,谁也不能完全替代谁。
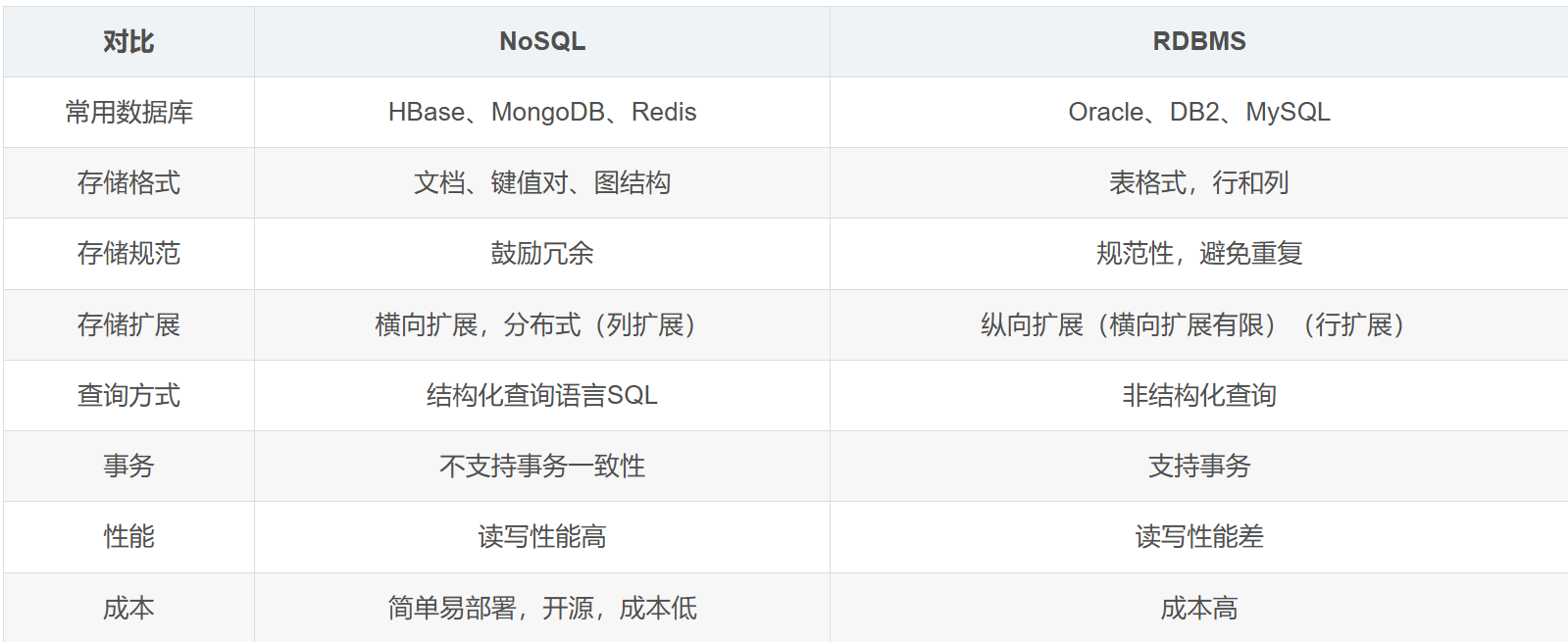
NoSQL 与 RDBMS 对比
HBase 起源
2006 年 Google 技术人员 Fay Chang 发布了一篇文章 Bigtable:ADistributed Storage System for Structured Data。
2007 年 Powerset 公司基于此文研发了 BigTable 的 Java 开源版本,即 HBase。刚开始它只是 Hadoop 的一部分。
2008 年 HBase 成为了 Apache 顶级项目,HBase 几乎实现了 BigTable 的所有特性。
2010 年 HBase 的开发速度打破了一直以来跟 Hadoop 版本一致的惯例。
HBase 生态全技术
- Lily — 基于 HBase 的 CRM(客户关系数据系统管理)
- OpenTSDB — HBase 面向时间序列数据管理
- Kylin — HHBase 上的 OLAP(联机分析处理)
- Phoenix — SQL 操作 HBase 工具
- Splice Machine — 基于 HBase 的 OLTP(联机事务处理)
- APache Tephra — HBase 事务支持
- TiDB — 分布式 SQL DB
- Apache Omid — 优化事务管理
- Yarn Application Timeline Server v.2 迁移到 HBase
- Hive MetaData 存储可以迁移到 HBase
- Ambari Metrics Server 将使用 HBase 做数据存储
HBase 特点
- 海量存储:HBase 良好的扩展性,才为海量数据的存储提供了便利。适合单表超千万,上亿,且高并发的场景,不适合实时性要求不高,数据规模不大,有数据分析的场景。
- 列式存储:HBase 根据列族来存储数据,列族下面可以有很多的列,列族在创建表时就必须指定。需要注意的是,列族理论上可以很多,但实际上建议不要超过 6 个。
- 极易扩展:基于上层处理能力(RegionServer)的扩展,基于存储的扩展(HDFS)。
- 高并发:在高并发的情况下,HBase 单个 IO 延迟下降并不多,能获得高并发、低延迟的服务。
- 稀疏:HBase 列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
HBase 优点
- 高容错,高扩展。HBase 基于 HDFS 实现数据的存储,拥有与生俱来的超强的扩展性和吞吐量。
- HBase 采用的是 Key/Value 的存储方式,这意味着,即便面临海量数据的增长,也不会导致查询性能下降。
- HBase 是列式数据库,可以将相同的列(以 Region 为单位)存储到不同的服务示例上,分散负载压力。
HBase 缺点
- 架构设计复杂,只适合存储海量数据。
- HBase 不支持表的关联操作,数据分析是 HBase 的弱项,常见的 group by 或者 order by 只能通过编写 Spark、MapReduce 来实现!