MySQL数据结构和索引
一、MySQL数据结构
InnoDB引擎
MySQL默认引擎是InnoDB引擎,这个引擎的主要特点是支持事务和行锁,
数据结构
2.1 二叉树(二叉查找树)
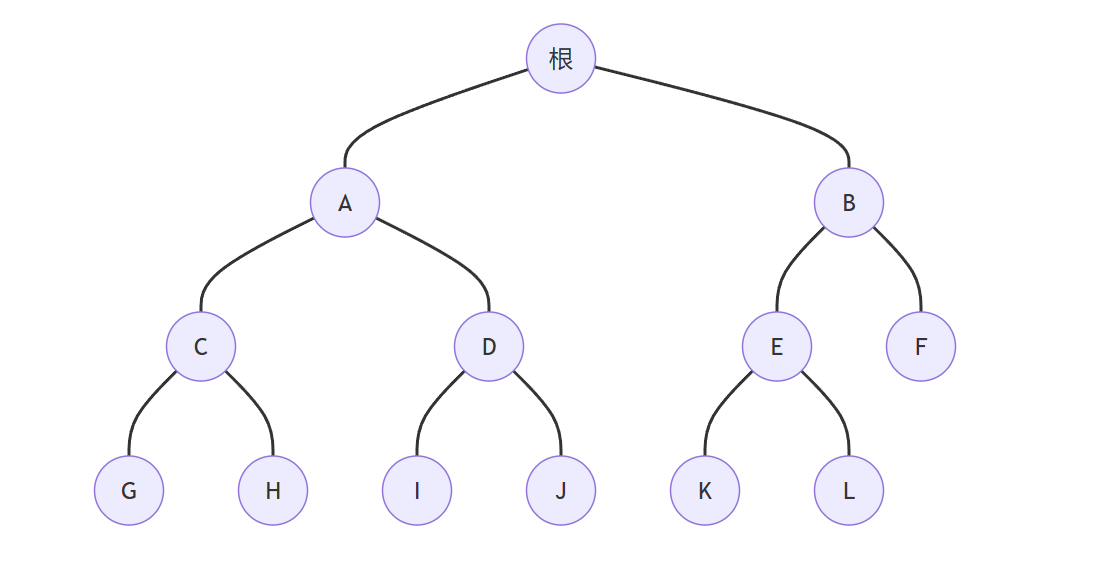
- 二叉树是一种特殊的树,二叉树中每个节点的度都不能大于2,就是说每个节点最多只能有左右两个子节点
- 当我们像二叉查找树储存数据的时候,是安装从大到小(或从小到大)的顺序保存的,这样有可能会形成一个单项链表的结构,搜索性能就会大打折扣。
为了解决平衡避免出现这种链表的结构,所以才有了平衡二叉树
2.2 平衡二叉树
平衡二叉树就能解决上面的问题

(1)非叶子节点最多拥有两个子节点
(2)非叶子节值大于左边子节点、小于右边子节点;
(3)树的左右两边的层级数相差不会大于1,
(4)没有值相等重复的节点
平衡二叉树会通过左旋右旋来平衡二叉树,避免变成单向链表结构,但过度要求平衡,会频繁的左右旋,
所以后面就出现了红黑树
2.3 红黑树
红黑树只是减少左右旋,本身还是会左旋和右旋
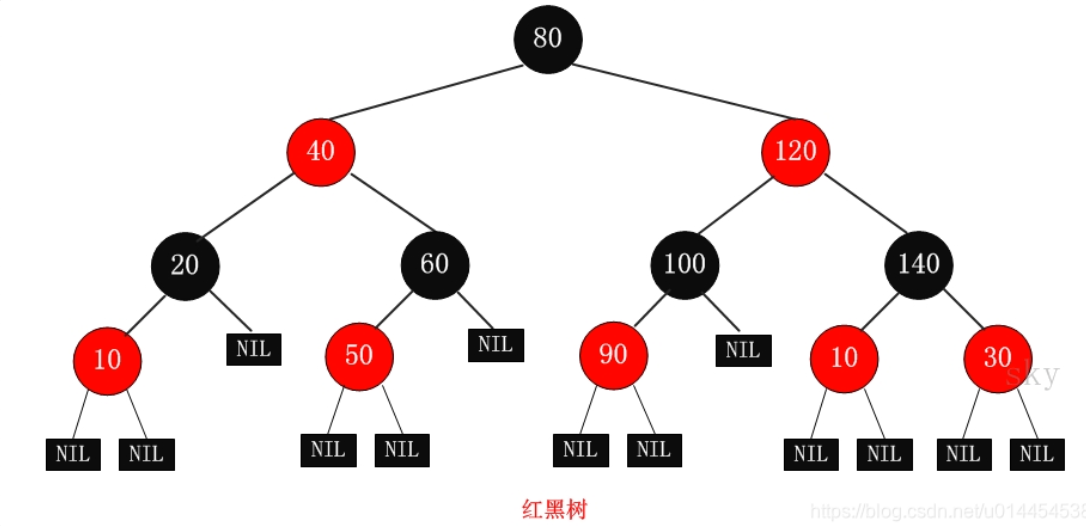
- 性质1:每个节点要么是红色,要么是黑色。
- 性质2:根节点是黑色。
- 性质3:每个叶子节点(NIL节点,也就是 NULL 节点)是黑色。
- 性质4:如果一个节点是红色的,则它的两个子节点都是黑色的(从每个叶子到根的所有路径上不能有两个连续的红色节点)。
- 性质5:从任一节点到其每个叶子的所有简单路径都包含相同数量的黑色节点。
- 平衡性:
- 红黑树通过上述性质确保了树的高度保持在 O(log n),其中 n 是树中的节点数。
- 这种性质保证了红黑树的操作(查找、插入、删除)的时间复杂度为 O(log n)。
- 插入操作:
- 插入新节点时,新节点默认着色为红色。
- 插入后,如果破坏了红黑树的性质,需要通过旋转和重新着色来恢复性质。
- 可能的旋转操作包括左旋、右旋、左右旋和右左旋。
- 删除操作:
- 删除节点可能导致红黑树失去平衡。
- 删除后,需要通过旋转和重新着色来恢复性质。
- 删除操作可能涉及复杂的颜色调整和旋转。
- 旋转操作:
- 左旋(Left Rotation):如果需要将一个节点的右子节点提升到更高的位置,可以进行左旋。
- 右旋(Right Rotation):如果需要将一个节点的左子节点提升到更高的位置,可以进行右旋。
- 左右旋(Left-Right Rotation):先对节点的左子节点进行左旋,然后对节点本身进行右旋。
- 右左旋(Right-Left Rotation):先对节点的右子节点进行右旋,然后对节点本身进行左旋。
2.4 B-Tree(平衡多路查找树)

每一个节点都储存完整的一条数据,这是和B+Tree最明显的区别,对于范围查询效率不高。
InnoDB存储引擎中有页(Page)的概念,页是其磁盘管理的最小单位。InnoDB存储引擎中默认每个页的大小为16KB(16384/1024),InnoDB在把磁盘数据读入到内存时会以页为基本单位
假如说:每个磁盘块的大小是1k(一个指针+一个数据节点是1k),那么一页就是有16个磁盘块,如果每次加载一页,也有16个指针,而且每个指针指向一个磁盘块(第二层),那么对于一个三层的b-树来说。能存储的节点数就是:16X16X16 = 4096
当需要查询的数据很多时,也就是十万百万级别的时候,B-Tree结构对于查询的效率就不怎么管用了,因为这个时候树的层级会很高,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数。
所以后面的B+Tree进一步优化这件事。
2.5 B+Tree

和B-Tree的主要区别是B+Tree的所有数据存储在叶子结点中,非叶子节点只存储键值信息和指针,而有数据的叶子结点会形成一个双向链表的结构,可以范围查询。
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为1000。也就是说一个深度为3的B+Tree索引可以维护1000 * 1000 * 50(最后一层每个磁盘块存多少数据节点,假设是50个) = 5千万条记录。深度一般是三到四层
特点:
- 所有的叶子结点中包含了全部关键字的信息,非叶子节点只存储键值信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接,所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B树的非终节点也包含需要查找的有效信息)
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
二、索引
什么是索引?
数据库管理系统(DBMS)中用于加快数据检索速度的一种数据结构,InnoDB用的是B+Tree的结构
特点:
- 占用磁盘空间
- 大大提高查询效率,减少磁盘IO
- 降低增删改的效率
索引的类型
- 聚簇索引(Clustered Index):数据按照索引顺序存储,每个表只能有一个聚簇索引。
- 非聚簇索引(Nonclustered Index):数据和索引分开存储,一个表可以有多个非聚簇索引。
- 唯一索引(Unique Index):保证索引中的键值唯一。
- 全文索引(Full-text Index):用于全文搜索,支持复杂的内容搜索
聚簇索引和非聚簇索引
聚簇索引,每个节点都存有完整的数据
非聚簇索引,只存了Key和指针和ID
回表和索引覆盖:
回表:当查询一个或一些数据的时候,如:select * from table where name = Joker 的时候,假设索引字段是 name,非聚簇索引查到了名字,但需要的是全部的数据,这时候和根据查到ID进行聚簇索引查询,这就是回表。
索引覆盖,以上,如果是 select name from table where name = Joker,需要的数据刚好可以通过非聚簇索引查询,不需要回表,这时候就是索引覆盖。(所以MySQL优化中有一个要求是:避免使用select *)
索引失效
可以使用Explain来查询是否使用了索引
避免索引失效对于提高数据库查询性能至关重要。以下是几种常见的方法来确保索引的有效使用:
1. 最左前缀原则
- 全值匹配:确保 WHERE 子句中的条件与索引列的顺序相匹配。
- 不要跳过索引列:如果索引是复合索引(多个列组成的索引),查询时应该从最左边的列开始,依次向右进行匹配,不能跳过中间的列。
2. 避免在索引列上进行操作
- 不要在索引列上使用函数:例如
WHERE UPPER(column) = 'value'。 - 不要在索引列上进行表达式操作:例如
WHERE column * 2 = 10。 - 避免类型转换:确保查询中的常量与索引列的数据类型一致。
3. 范围条件后的列不可用
- 如果使用了范围条件(如
<,<=,>,>=,BETWEEN,LIKE开头的模式匹配等),则在范围条件之后的索引列无法被使用。
4. 使用覆盖索引
- 覆盖索引:当索引包含了所有需要查询的字段时,可以避免回表查询(即不需要再从主键索引中查找数据)。
- 减少 SELECT * 的使用:明确指定所需的列,而不是使用
SELECT *。
5. LIKE 语句的使用
- 避免以通配符开头:如果使用
LIKE '%value%',则索引可能失效。但如果使用LIKE 'value%'或LIKE '%value',则索引仍可有效利用。
6. 数据类型的匹配
- 确保索引列和查询中的值的数据类型一致,避免隐式类型转换。
7. 避免使用 NOT IN 和 NOT EXISTS
- 使用
NOT IN或NOT EXISTS可能会导致索引失效。可以尝试使用LEFT JOIN或NOT EXISTS结合子查询的方式代替。
8. 选择合适的数据类型
- 为索引列选择合适的数据类型,尤其是当有多种数据类型可以选择时,选择占用空间较小的数据类型可以节省存储空间,提高索引的效率。
9. 维护索引
- 定期检查和优化索引,例如使用
ANALYZE TABLE和OPTIMIZE TABLE命令。
10. 避免使用 SELECT *
- 明确列出需要查询的字段,减少不必要的数据传输。
11. 使用全文索引
- 对于全文搜索,使用全文索引(如
FULLTEXT索引)。
12. 限制使用 OR
- 当使用
OR时,确保至少有一个条件能够使用有效的索引。
通过遵循以上原则,可以有效地避免索引失效的问题,从而提升数据库查询的性能。
热门相关:帝少宠妻有点甜 绝色符师:龙皇的狂傲妃 校花之贴身高手 首席的亿万老婆 翻天