Springboot操作Poi进行Excel导入
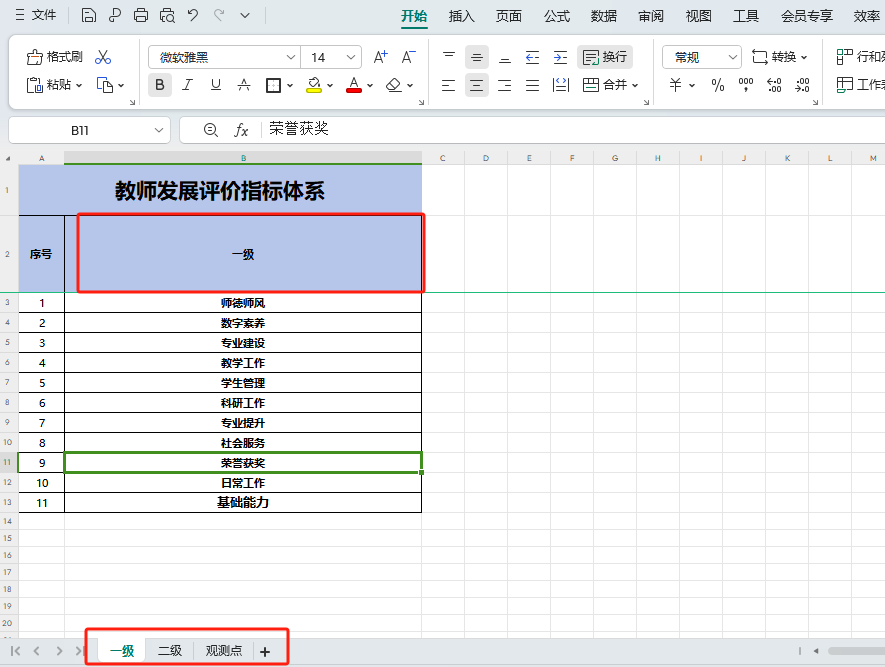
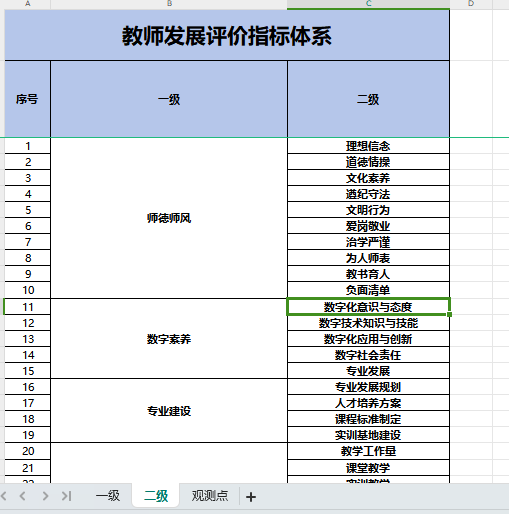
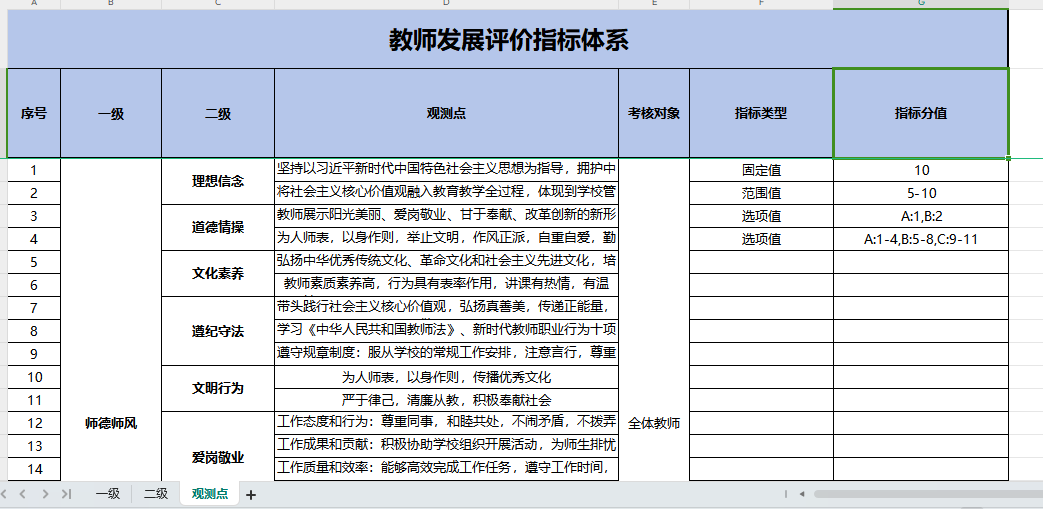
以上就是我所要导入的Excel模板。
需求重点
经过这次需求的实现,发现这个需求最难的点 就在 模板模板模板!
模板中数据的关系,理清楚思路
模板中的数据,到底是多sheet还是说有合并单元进行导入
实现感悟
不管是多个sheet、还是说合并单元格、最重要的思想都是说将Excel中的数据进行拼接为一条一条的List记录进行新增数据。
/**
* 用于检测是否是表头行,此方法就是说代码再执行的时候找到一级这个字段的名称,然后知道获取字段从此开始
*
* @param row
* @return
*/
private boolean isHeaderRow(Row row) {
Cell firstCell = row.getCell(1);
return firstCell != null && "一级".equals(firstCell.getStringCellValue().trim());
}
/**
*
* 上传文件,进行解析
* @param file 文件
* @return
*/
public Result<?> importExcels(MultipartFile file) {
Map<Integer, List<Object>> sheetDataMap = new HashMap<>();
try {
// 获取工作簿,解析整个Excel文件
Workbook workbook = new XSSFWorkbook(file.getInputStream());
// 循环遍历每个Sheet
for (int i = 0; i < workbook.getNumberOfSheets(); i++) {
Sheet sheet = workbook.getSheetAt(i);
// 解析每个Sheet的数据
List<Object> sheetData = parseSheet(sheet);
// 将Sheet的数据存储到Map中,以Sheet名称为Key
sheetDataMap.put(i, sheetData);
}
} catch (Exception e) {
e.printStackTrace();
}
// 处理数据
processingData(sheetDataMap);
return Result.ok(sheetDataMap);
}
/**
* 解析给定的Sheet,并将数据存储到List中
*
* @param sheet 要解析的Sheet
* @return 包含每行数据的List
*/
private List<Object> parseSheet(Sheet sheet) {
List<Object> data = new ArrayList<>();
boolean isHeaderFound = false;
// 循环遍历每一行数据
for (int rowIndex = 1; rowIndex <= sheet.getLastRowNum(); rowIndex++) {
Row row = sheet.getRow(rowIndex);
if (row == null) continue; // 跳过空行
// 检查是否为标题行
if (!isHeaderFound) {
if (isHeaderRow(row)) {
isHeaderFound = true; // 找到标题行
}
continue; // 跳过标题行的处理
}
// 收集每列的数据
List<Object> rowData = new ArrayList<>();
for (int cellIndex = 1; cellIndex <= row.getLastCellNum(); cellIndex++) {
Cell cell = row.getCell(cellIndex);
if (cell != null && isMergedCell(sheet, row, cell)) {
rowData.add(getMergedCellValue(sheet, row, cell));
} else if (cell != null && !cell.toString().trim().isEmpty()) {
rowData.add(cell.toString()); // 仅当单元格不为空且不为空字符串时才添加
}
}
if (!rowData.isEmpty()) {
data.add(rowData); // 仅在行数据非空时才添加到数据列表中
}
}
return data;
}
/**
* 获取合并单元格的值
*/
private String getMergedCellValue(Sheet sheet, Row row, Cell cell) {
int rowIndex = row.getRowNum();
int colIndex = cell.getColumnIndex();
for (int i = 1; i < sheet.getNumMergedRegions(); i++) {
CellRangeAddress range = sheet.getMergedRegion(i);
if (range.isInRange(rowIndex, colIndex)) {
Row firstRow = sheet.getRow(range.getFirstRow());
Cell firstCell = firstRow.getCell(range.getFirstColumn());
return firstCell.toString().replace("\n", " ");
}
}
return null;
}
/**
* 对于读取的Excel数据进行处理。
*
* @param data
*/
private boolean processingData(Map<Integer, List<Object>> data) {
boolean flag = false;
try {
// 遍历每个层级的数据,从0开始,每个level对应一个sheet的数据
for (int level = 0; level < data.size(); level++) {
List<Object> levelList = data.get(level);
if (levelList == null) {
continue; // 如果当前层级没有数据,跳过
}
// 遍历当前层级中的每一行数据
for (Object o : levelList) {
List<String> rowData = (List<String>) o;
// 获取父类名称(如果是第一级,则父类名称为null)
String parentName = level == 0 ? null : rowData.get(level - 1);
// 获取当前的名称
String currentName = rowData.get(level);
try {
String parentId = "0"; // 默认父类ID为"0",表示顶级目录
if (level > 0 && parentName != null) {
// 如果不是第一级,通过父类名称查询父类ID
Zbk parentZbk = zbkMapper.selectOne(new LambdaQueryWrapper<Zbk>()
.eq(Zbk::getName, parentName.replace("\n", "")) // 去除换行符后匹配名称
.eq(Zbk::getType, 1) // 类型为目录
.eq(Zbk::getDeleted, 0)); // 未被删除
if (parentZbk != null) {
parentId = parentZbk.getId(); // 如果找到父类,获取父类ID
} else {
log.warn("父类不存在: " + parentName);
continue;
}
}
// 查询是否已经存在当前名称的指标/目录
Zbk existingZbk = zbkMapper.selectOne(new LambdaQueryWrapper<Zbk>()
.eq(Zbk::getName, currentName.replace("\n", "")) // 去除换行符后匹配名称
.eq(Zbk::getType, level == data.size() - 1 ? 0 : 1) // 如果是最后一级,类型为指标,否则为目录
.eq(Zbk::getDeleted, 0) // 未被删除
.eq(Zbk::getPid, parentId)); // 父类ID匹配
// 如果当前名称的指标/目录不存在,插入新的记录
if (existingZbk == null) {
Zbk zbk = new Zbk();
zbk.setName(currentName);
zbk.setDeleted(0); // 逻辑删除标志设为未删除
zbk.setType(level == data.size() - 1 ? 0 : 1); // 设置类型,0为指标,1为目录
zbk.setEvaluationObject("1382586667761336322");
zbk.setZbSourceType("build");
zbk.setDisable(false); // 未禁用
zbk.setPid(parentId); // 设置父类ID
zbkMapper.insert(zbk); // 插入新记录
// 如果是最后一级(观测点),处理观测点的额外逻辑
if (level == data.size() - 1) {
flag = true;
// 获取指标类型
String indicatorType = rowData.get(rowData.size() - 2);
// 获取指标分值
String indicatorScore = rowData.get(rowData.size() - 1);
if (!StringUtils.isEmpty(indicatorType) && !StringUtils.isEmpty(indicatorScore)) {
// 处理指标数据
processingIndicators(indicatorType, indicatorScore, zbk.getId());
}
}
}
} catch (Exception e) {
log.error("处理数据时发生异常: ", e);
continue; // 如果发生异常,跳过当前循环
}
}
}
} catch (Exception e) {
log.error("处理数据时发生异常: ", e);
e.printStackTrace();
}
return flag; // 返回处理结果的标志
}