Redis基础知识(学习笔记20--高并发场景)
一. 高并发场景下常见的3种问题
1.1 缓存穿透
当用户访问的数据既不存在缓存中也不在数据库中时,就会导致每个用户查询都会“穿透”缓存“直抵”数据库。这种情况就成为缓存穿透。当高并发的请求到达时,缓存穿透不仅增加了响应时间,而且还会引发对DBMS的高并发查询,这种高并发查询很可能会导致DBMS的奔溃。
缓存穿透产生的主要原因有两个:一是在数据库中没有相应的查询结果,二是查询结果为空时,不对查询结果进行缓存。所以,针对以上两点,解决方案也有两个:
* 对非法请求进行限制;
* 对结果为空的查询给出默认值。
1.2 缓存击穿
对于某一个缓存,在高并发情况下若其访问量特别巨大,当该缓存的有效时间达到时,可能会出现大量的访问都要重建该缓存,即这些访问请求发现缓存中没有该数据,则立即到DBMS中进行查询,那么这就有可能会引发对DBMS的高并发查询,从而导致DBMS的崩溃。这种情况称为缓存击穿,而该缓存数据称为热点数据。
对于缓存击穿的解决方案,较典型的是使用“双重检测锁”机制。
1.3 缓存雪崩
对于缓存中的数据,很多都是有过期时间的。若大量缓存的过期时间在同一很短的时间段内几乎同时达到,那么在高并发访问场景下就可能会引发对DBMS的高并发查询,而这将可能直接导致DBMS的奔溃。这种情况称为缓存雪崩。
对于缓存雪崩没有很直接的解决方案,最好的解决方案就是预防,即提前规划好缓存的过期时间。要么就是让缓存永久有效,当DB中数据发生变化时清除相应的缓存。如果DBMS采用的是分布式部署,则将热点数据均匀分布在不同数据库节点中,则可能到来的访问负载均衡开来。
二. 数据库缓存双写不一致
以上三种情况都是针对高并发 读 场景中可能会出现的问题,而数据库缓存双写不一致问题,则是在高并发 写 场景下出现的问题。
对于数据库缓存双写不一致问题,以下两种场景均有可能会发生:
2.1 “修改DB更新缓存”场景
对于具有缓存warmup功能的系统,DBMS中常用数据的变更,都会引发缓存中相关数据的更新。
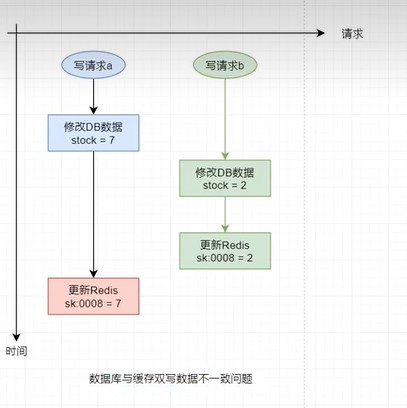
在高并发 写 操作场景下,若多个请求要对DBMS中同一个数据进行修改,修改后还需要更新缓存中相关数据,那么就有可能出现缓存与数据库中数据不一致的情况。
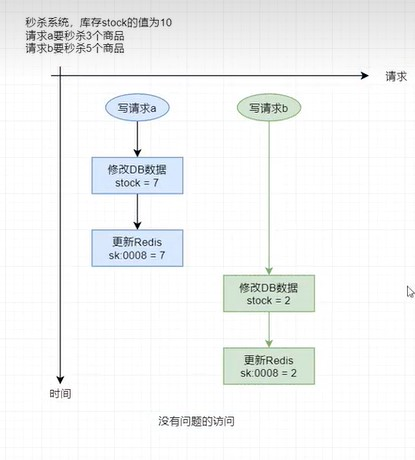
概况举例如下,
理想情况下的访问:
异常情况
2.2 修改DB删除缓存”场景
在很多系统中是没有缓存warmup功能的,为了保持缓存与数据库数据的一致性,一般都是在对数据库执行了写操作后,就会删除相应缓存。
在高并发 读写 请求场景下,若这些请求对DBMS中同一个数据的操作既包含写也包含读,且修改后还要删除缓存中相关数据,那么就有可能会出现缓存与数据库中数据不一致的情况。
概况举例如下:
仍然为秒杀系统,库存stock的值为10,请求a要秒杀3个商品,请求b仅查看商品剩余数量,暂时不参与抢购。
理想情况下的访问:
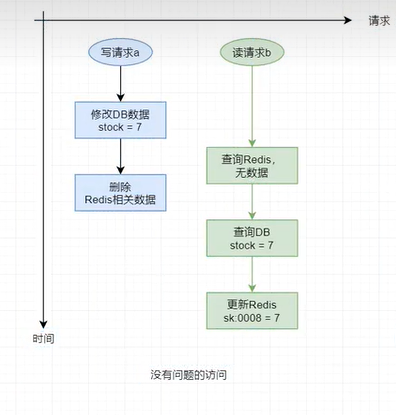
异常情况(即 数据库与缓存双写数据不一致问题)

三. 解决方案
3.1 延迟双删
延迟双删方案是专门针对于“修改DB删除缓存”场景的解决方案。但该方案并不能彻底解决数据不一致的状况,其只可能降低发生数据不一致的概率。
延迟双删方案是指,在写操作完毕后会立即执行一次缓存的删除操作,然后再停止一段时间(一般为几秒)后再进行一次删除。而两次删除中间的间隔时长,要大于一次缓存写操作的时长。

难点在于双删之间的停顿时间大小的设置。
3.2 队列
以上两种场景中,之所以会出现数据库与缓存中数据不一致,主要是因为对请求的处理出现了并行。只要将请求写入到一个统一的队列,只有处理完一个请求后才可以处理下一个请求,即 系统对用户的请求处理串行化,这样就可以解决数据不一致的问题。
主要问题:并发性差。
3.3 分布式锁
使用队列的串行化虽然可以解决数据库与缓存中数据不一致,但系统失去了并发性,降低了性能。使用分布式锁可以在不影响并发的前提下,协调各处理线程间的关系,使数据库与缓存中的数据达成一致性。
只需要对数据库中的这个共享数据的访问,通过分布式锁来协调对其的操作即可。
学习笔记--参阅特别声明
【Redis视频从入门到高级】
【https://www.bilibili.com/video/BV1U24y1y7jF?p=11&vd_source=0e347fbc6c2b049143afaa5a15abfc1c】