轻松编排工作流,浅谈DolphinScheduler如何使用Python调用API接口?
最近,在做某大型零售企业项目时,有客户用到DolphinScheduler,并咨询是否可以用Python脚本编排工作流?该如何实现?相信有很多人会有这样的疑问,那么,本文将为我们简单分享DolphinScheduler的优势和实际使用。
为什么企业数据开发要使用海豚调度?
当企业在做数据开发时,任务调度平台会扮演自动执行预设任务的重要角色,是业务开展过程中不可或缺的一环。
随着企业业务的快速发展,总是会需要定时执行各种类型的任务,这些任务之间还可能存在着各种依赖关系。而且在使用任务调度平台往往会遇到一些问题,比如:
- 企业历史累计的离线任务数量庞大,可能已达到1w+的规模,平台的稳定性能否支持。
- 企业离线任务增量大,平台是否拥有良好的扩展性和处理能力。
- 企业非专业开发人员对于配置调度的易用性要求严格,需要能支持SQL化操作及友好的配置界面,以达到'平民化'且易于使用的体验。
这些场景在数据开发领域十分的常见,那么怎么才能很好的解决这些个问题呢?
可以说,DolphinScheduler就能很好地解决上述问题。本文的内容也比较简单,下面我会先明海豚调度有什么优势,再分享使用Python来调用 API 接口的实操演示。
什么是海豚调度?有什么优势?
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。 适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
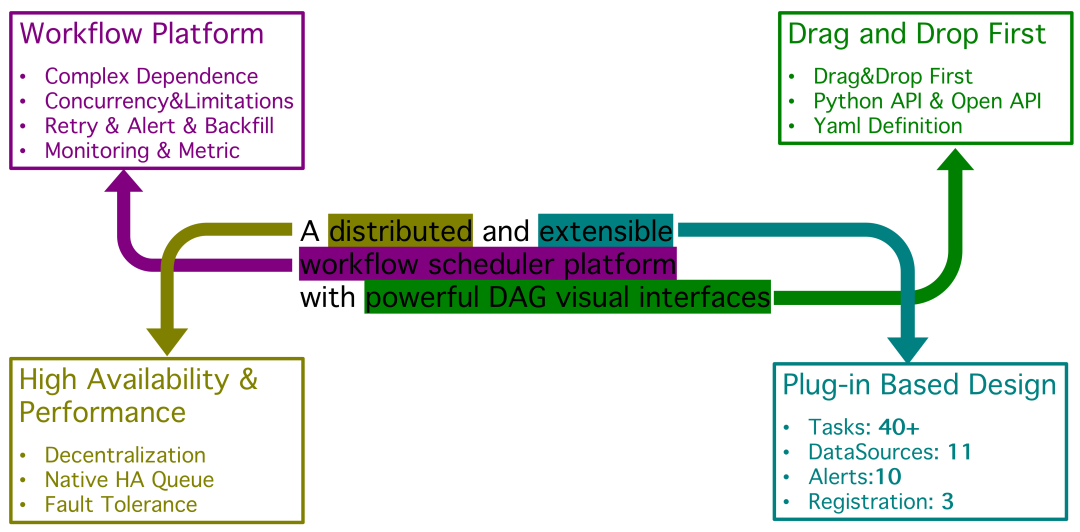
Apache DolphinScheduler 在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
DolphinScheduler 的主要特性如下:
- 易于部署
提供四种部署方式,包括Standalone、Cluster、Docker和Kubernetes。 - 简单易用
通过四种方式创建和管理工作流(Web UI、Python SDK、Yaml文件和Open API),还有可视化DAG和模块化操作。 - 高可靠性
多主多从的去中心化架构,原生支持横向扩展。 - 性能强大
性能比其他编排平台快N倍,每天可支持千万级任务。 - 云原生
DolphinScheduler支持编排多云/数据中心工作流,支持自定义任务类型。 - 高扩展性
支持多租户和在线资源管理。支持每天10万个数据任务的稳定运行。
海豚调度使用Python编写API接口有什么好处?
经常使用ETL工具的同学应该都知道,调用API接口可以用里面HTTP的插件进行对接。然而在数据安全性要求越来越高的今天,API方通常都会在请求参数里面添加自定义加密算法加密后的参数,普通的HTTP插件已经无法满足接口安全性的需求。
面对复杂的加密算法,使用一门编程语言来编写无疑是不二之选,至于为什么使用Python来编写,有以下几个理由:
- Python简单易上手,生态丰富。
- 只需要一个py文件就能在DolphinScheduler被直接调用,无需复杂的语言环境以及安装部署。
- API接口通常都会有Python版的样例代码,加密算法甚至可以直接引用,更加便于开发者开发。
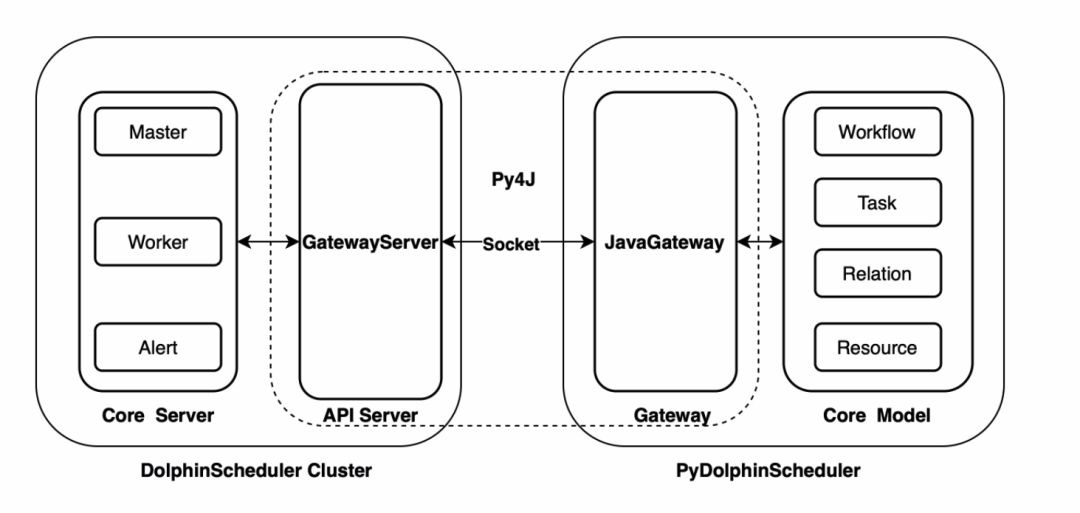
2.0.5 版本更新之后,Apache DolphinScheduler 新增了 Python API 功能,用户可以通过 Python 脚本编排工作流,最后实现工作流的创建、更新、调度等操作,这给 Python 用户带来了很多便利。
具体实操步骤
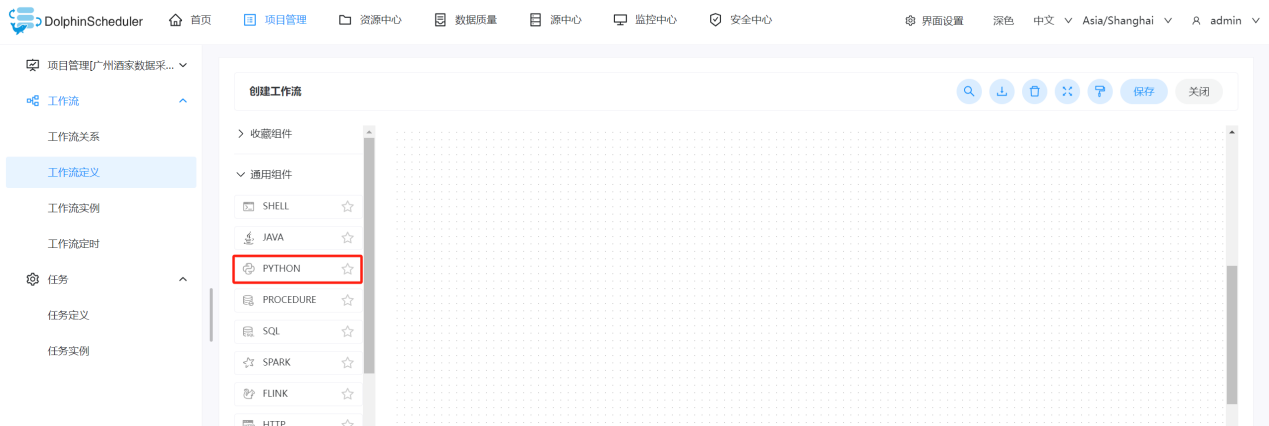
1、在创建工作流的时候拖出Python插件,填写节点名称,以及写入对应的Python脚本(图中资源栏的python文件需要在第2点中上传)。
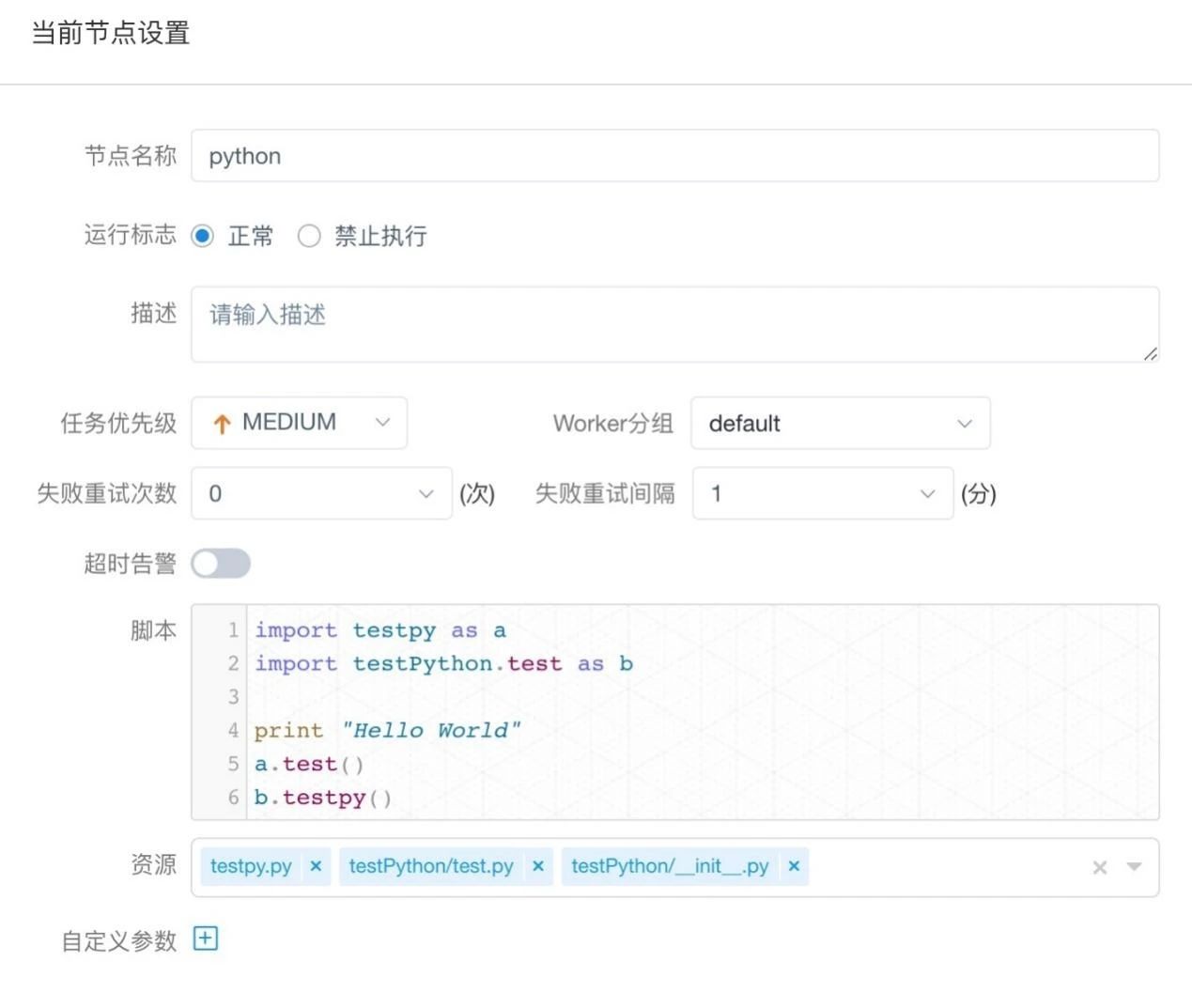
2、资源中心的文件管理可以上传py文件作为资源,供第1点创建工作流的时候使用(第1点中import的文件就是文件管理中的资源)。
如果企业有任务调度需求的场景,可以尝试使用DolphinScheduler,丰富的任务类型可以满足我们实际场景下复杂的逻辑。
以上的内容,我相信能够解决大家日常工作遇到对于DolphinScheduler使用Python调用API接口的问题。如果您想要进一步了解DolphinScheduler,欢迎进入DolphinScheduler开源社区交流群。(V17743592110)
本文由 白鲸开源 提供发布支持!