一个mysql的group_concat导致的问题
好久都没有写点东西了,是时候有点写东西的必要了。
去年下年底离职了,躺了几个月,最近又兜兜转转换了一家公司继续当牛马了,前段时间八股文背了好多,难受呀,不过我也趁着前段时间自己也整理了属于我自己的八股文,有好几万字吧,哈哈哈,以后就不用到处去找八股文了。
说回正题,这个group_concat的问题是最近在修复一个问题的时候发现的,是以前的人挖的坑,最近都不知道填了多少坑了,特喵的。
一. 问题背景
一个机构树的表,就是那种有层级的,类似于下图这样的,然后我想查询某一个公司下所有部门的员工,我们就要把这个机构表递归找到一个公司下所有的部门,然后关联一下用户表查询就行了

但是有人为了追求性能高一点,就把递归查询机构的逻辑使用使用find_in_set()函数和group_concat()函数封装成了mysq的自定义函数,然后调用的时候在sql级别进行处理了,
DROP FUNCTION IF EXISTS queryChildrenAreaInfo; DELIMITER ;; CREATE FUNCTION queryChildrenAreaInfo(areaId INT) RETURNS VARCHAR(4000) BEGIN DECLARE sTemp VARCHAR(4000); DECLARE sTempChd VARCHAR(4000); SET sTemp='$'; SET sTempChd = CAST(areaId AS CHAR); WHILE sTempChd IS NOT NULL DO SET sTemp= CONCAT(sTemp,',',sTempChd); SELECT GROUP_CONCAT(id) INTO sTempChd FROM t_areainfo WHERE FIND_IN_SET(parent_id,sTempChd)>0; END WHILE; RETURN sTemp; END ;; DELIMITER ;
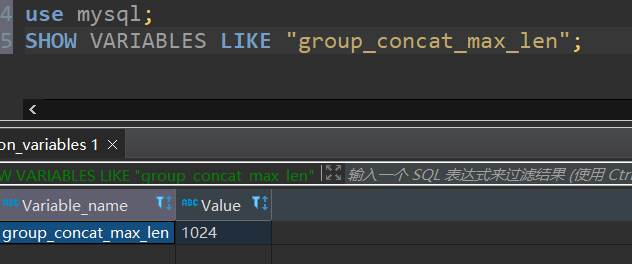
使用这种方式,在测试环境肯定没问题,但是到了生产环境机构表数据多了之后肯定就会踩坑,GROUP_CONCAT(id)返回的数据有最大限制的,可以使用SHOW VARIABLES LIKE "group_concat_max_len" 进行查询,默认是1024个字节,下图所示。
也就是如果查询的数据超过1024个字节后,只会保留前1024个字节的数据,至于修复方法,需要修改mysql配置文件或者使用sql语句临时修改:SET GLOBAL group_concat_max_len=10240000; SET SESSION group_concat_max_len=10240000;
如果没有修改的话,就可能导致一个问题,一样的代码在测试环境跑的很正常,一到生产上就拉胯,你肯定以为是代码哪里和生产不一致,可能比对了很久,然后测试环境自己也测试了n次,但就是生产上数据不完整,此时你就会两眼无神,怀疑人生....
二 解决方案
2.1. 直接修改mysql的配置文件,扩大group_concat_max_len的最大容量,至于扩大到多少,就要靠你自己去根据数据量去衡量了,不过一般的开发也不想去为了这个一点问题就改生产数据库配置吧,麻烦....
2.2 如果是oracle数据库,自带了递归查询的关键字:start with connect by prior, 有兴趣的可以自己研究一下,挺好用的,但是如果项目中是mysql数据库,那就不适用了
2.3 使用sql进行递归查询,不过这种sql就是很鸡儿难看懂,要是让你维护这样的sql你想打人的心都有了,所以我也不是很推荐
-- 根据⼀个⽗节点为id为1 查询所有⼦节点(包含⾃⾝) SELECT au.id, au.name, au.parent_id FROM (SELECT * FROM t_areainfo WHERE parent_id IS NOT NULL) au, (SELECT @pid := 1) pd WHERE FIND_IN_SET(parent_id, @pid) > 0 AND @pid := concat(@pid, ',', id) UNION SELECT id, name, parent_id FROM t_areainfo WHERE id = '1' ORDER BY id;
2.4. 其实我们陷入了误区了,想一想有必要把这么复杂的逻辑都放到sql语句上处理么?其实这种越复杂的sql,会给服务器的压力也是倍增的,而且特别难排查出问题,这点是最致命的,因为只要能排查出来的问题就都不是问题。
我的解决方案是: 首先查询出所有的机构信息,注意,如果机构信息太多,我们可以再细化,比如先查询一级机构,再查询二级机构....分批次去查询我们的数据,再内存级别进行组装; 然后根据我们查询的机构信息再调用一次数据库查询用户信息就好了,虽然和数据库交互可能多了两三次,但是逻辑变得简单了,有问题一下子就能排查出来了。
错误示范: 先查询一级机构下所有的部门,然后遍历每一个部门分别再去数据库中查询下一级部门.....这样你会被打死的,千万不要循环中嵌套着查询数据库的逻辑
三 还有话说
继续瞎逼逼几句,最近就是搞公司的历史遗留的项目,技术栈老,问题多,一个几万用户的对内商城项目,扣减库存的逻辑是查询数据库,内存中扣减了之后再将库存更新到数据库中......看到代码我都惊呆了呀。
由于我刚来没几个月,之前听他们讨论有什么超卖问题,我想着这尼玛不超卖就出了鬼了, 然后我就提出了这个缺陷, 并使用了数据库乐观锁嘎嘎优化了。这段时间帮着压测这个商城项目,真的就是一堆破代码,我还要去给各种优化,性能起码提升了好多倍都不止,尼玛数据库关键的索引都有不加的,有的sql执行都需要好几秒的,加了索引之后30ms......
继续苟着吧,现在这里最大的好处就是不怎么加班,干完自己的事情后五点半就可以走了,嘿嘿