Kubernetes 系列:了解 k8s 架构(一)
Kubernetes 概述
当下,我们很多项目于都在Cloud Native(云原生)的上面,这种方法旨在使组织能够确保可用性并快速响应和适应变化,云原生其实就是一组本质上支持在不同云环境(公共云、私有云或混合云)上大规模构建、运行和管理应用程序的实践和技术。
云原生离不开两个概念:容器和微服务,这两个概念是任何云原生应用程序的构建块:
- 微服务是小型、独立的服务(软件)的集合,可以在容器中轻松打包和执行。
- 容器基于容器镜像, 容器是一个标准的软件单元,它打包代码及其所有依赖项,无论基础设施如何, 都允许应用程序快速可靠地运行
- 容器镜像是一个轻量级的、独立的、可执行的软件包,其中包含运行应用程序所需的一切,容器镜像在运行时成为容器
使用微服务架构是确保应用程序速度、敏捷性、增长和可用性的基础,因此,它改善了用户体验。
例如,随着网络流量的增加或减少,放置在单体专用服务器上的整体应用程序比一组微服务更难扩展和缩减。
然而,微服务架构的快速采用导致生产环境中容器数量的增加,这使得容器的管理和维护变得非常困难。并且,如果服务的请求量上来,已部署的服务响应不过来的时候怎么办呢?传统的做法是,如果请求量、内存、CPU超过阈值做了告警,运维马上再加几台服务器,部署好服务之后,接入负载均衡来分担已有服务的压力。这样从监控告警到部署服务,中间需要人力介入。 因此,Kubernetes 的诞生就是为了解决这个问题。k8s实现自动完成服务的部署、更新、卸载和扩容、缩容等功能
Kubernetes(也称为 K8s)是一个开源平台,旨在自动化容器化应用程序的配置、管理、可扩展性和可用性。(或者简单地说,它是一个编排工具)
Kubernetes 最初是一个名为 Borg 的 Google 内部项目。 然后它被交给开源社区,现在由云原生计算基金会(CNCF)维护。
架构
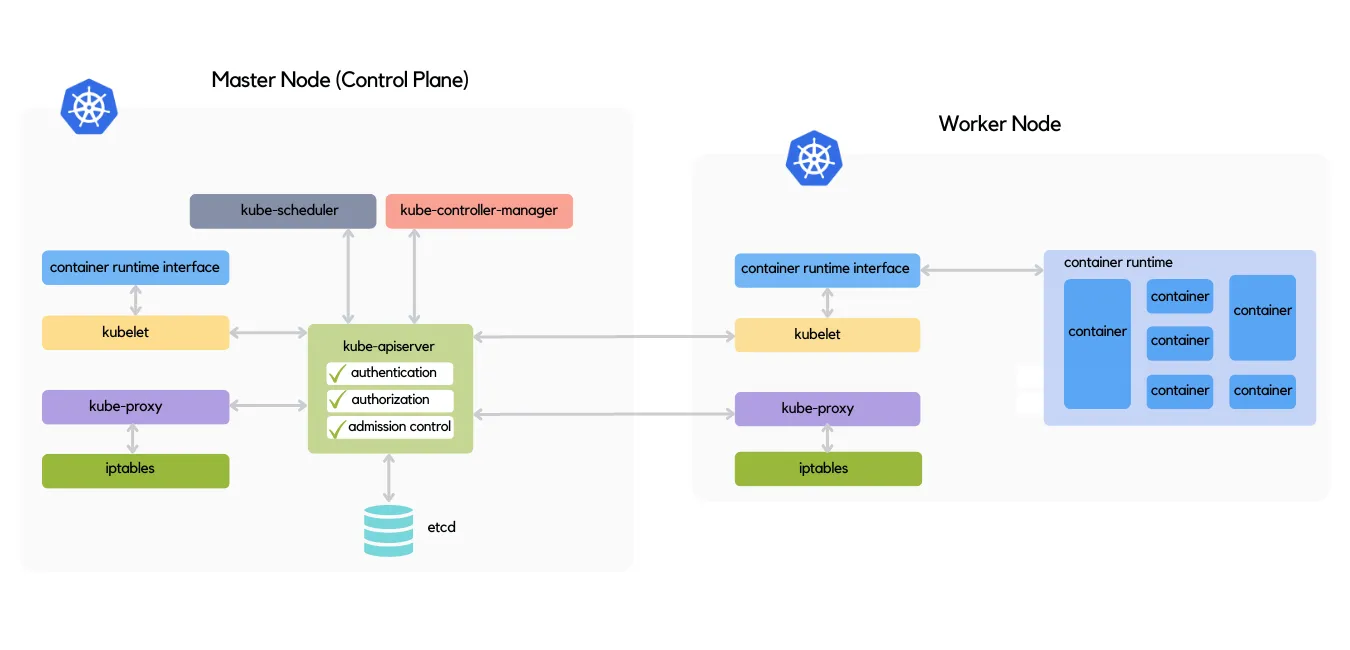
从上图可以看到:
Kubernetes 集群由Control Plane和工作节点(Worker Node)组成。
Control Plane
Control Plane 是集群中的决策者,它负责编排运行、调度和维护应用程序所需的所有进程。Control Plane可以安装到任何节点,但是作为最佳实践,不建议在WorkerNode上安装Control Plane。我们在后续文章中讨论如何构建 Kubernetes 集群。
kube-apiserver: 公开 API 服务器的组件etcd: 分布式键值存储。Kubernetes使用它作为所有集群数据的后备存储kube-scheduler: 监视新创建的Pod并为其分配节点的组件kube-controller-manager: 负责控制器进程的组件。 Kubernetes 中的控制流程各不相同,例如控制节点是否关闭的节点控制器或创建endpoints的端点控制器。cloud-controller-manager: 这是一个可选组件,仅在云上创建 Kubernetes 集群时才需要。该组件将 Kubernetes 集群链接到云提供商
Worker Nodes
Worker Node负责托管称为 Pod 的 k8s 对象。而Pod是k8s对象的最小单位。它在其中运行一个容器化应用程序。
所有 k8s 节点都运行三个主要代理:
Container Runtime: 在节点上运行容器, 负责从注册表加载容器镜像、监视容器资源、将容器彼此隔离以及管理容器生命周期(即 docker)kube-proxy: 它通过监视两个主要的 k8s 对象:Services和Endpoints来维护 k8s 节点上的网络规则。这些网络规则允许Pods在 k8s 集群内部或外部可访问kubelet:一个systemd进程。它接收PodSpecAPI调用并与Container Runtime通信,以确保遵守PodSpec。
PodSpec: 是描述Pod的文件,它的文件格式可以是YAML或JSON格式。每次更改后,会由kube-controller-manager通过kube-apiserver发送到Kubelet代理,以便Kubelet可以执行必要的更新以实现当前状态和所需状态之间的匹配。它还会发送到kube-scheduler以决定在哪个节点上运行 pod。
Control Plane Node
Control Plane由与Worker Node相同的代理加上几个其他代理组成。大多数进程在容器内执行,其中一些是 systemd 进程。他们负责确保集群的当前状态与所需状态匹配
kube-apiserver: apiserver k8s 集群的单一入口,它主要负责根据用户的具体请求,去通知其他组件
从架构图可以看出k8s各个代理之间不直接通信。 数据通过kube-apiserver在代理之间传递。因此,kube-apiserver是 k8s 集群的单个入口,处理所有内部和外部的 k8s 流量(API 调用)。
apiserver调用时会为每个 API 调用执行身份验证(authentication)、授权(authorization)和admission control。
authentication:当客户端提供有效的 TLS 证书时建立(有效的 TLS 证书是由集群的 CA 签名并受apiserver信任的证书)
authorization:通过RBAC,指定客户端是否可以对某些 k8s 对象执行CRUD 操作
admission controlCRUD operation: 如果客户端对 k8s对象执行的操作合法,则成立。例如,当集群有一个 ResourceQuota 对象将命名空间 dev 中可以创建的 pod 数量限制为 2 时。如果用户尝试创建 第3个 pod,则其请求将被拒绝
kube-controller-manager:由一组称为控制器的 k8s 对象组成
在 k8s 中,Controller负责监控和调整在Worker Node上部署的服务的状态,比如用户要求A服务部署2个副本,当其中一个服务挂了,Controller会马上调整,让Scheduler再选择一个Worker Node重新部署服务。kube-scheduler: K8S 所有Worker Node的调度器。当用户要部署服务时,Scheduler会选择最合适的Worker Node(服务器)来部署etcd: K8S的存储服务。etcd存储了K8S的关键配置和用户配置,K8S中仅API Server才具备读写权限,其他组件必须通过API Server的接口才能读写数据
最好是始终确保有 etcd 数据的备份
总结
好了,到这里就简单的说明了k8s内部的一些组件作用和他的一个主要架构,总的来说k8s的Master Node具备:请求入口管理(API Server),Worker Node调度(Scheduler),监控和自动调节(Controller Manager),以及存储功能(etcd);而Worker Node具备:状态和监控收集(Kubelet),网络和负载均衡(Kube-Proxy)、保障容器化运行环境(Container Runtime)
下一篇我们介绍k8s里面一些重要的概念:Pod,Volume,Container,Deployment 和 ReplicaSet以及Service和Ingress等。
热门相关:亿万盛宠只为你 变身蜘蛛侠 重生野性时代 回眸医笑,冷王的神秘嫡妃 重生野性时代