python数据分析实践总结
“我的惩罚是什么?”伊萨克问艾尔曼。
“孤寂。”艾尔曼回答道。
引言:
在近日的python数据分析实战课中,我学习到使用python进行数据分析的流程、方法,对常使用的函数有一些认识和了解,对 numpy, pandas 包有了一定的理解但不深。
这篇博客将是我自己用于总结归纳的圣地,我将对整个项目的 key point 进行归纳总结,提取其中精华之所在,汲取之加以奋发向前。

一、分析数据文件:
在拿到数据的第一刻,莫急,先打开数据文件看一看,明白文件里的数据能够说明什么。于是乎我们得以提出分析的目标,并开始思索如何能够实现我们的目的。例如,我们手里有一份某电商平台一年的营销数据,这份数据中包含了达成交易订单的用户ID、本次订单对应的商品数量、总价、时间,思考:我们可以利用这些数据得到哪些结论?——从时间维度:分析不同月份的营销额;从客户维度:分析回购率、复购率、新老用户比例。根据得出的结论,我们得以制定相应的策略来提高商家的盈利。
二、数据预处理:
提一嘴,在文件最开始导入包的时候输入 plt.rcParams['font.sans-serif'] = 'SimHei' 以让中文能够正常显示(IPython中如此)
首先读取文件,利用 pandas 根据不同文件类型选择不同的读取函数:
-
csv: pd.read_csv('name.csv', encoding='utf-8/GBK')
-
text: pd.read_table('name.txt', names=columns, sep='\s+') # names指定每一列数据的含义,sep是划分数据时的参考,\s+表示跳过任意多的空格
-
excel: pd.read_excel('name.xlsx')
接着进行数据的预处理:
-
对于出现NAN的行或列且需要删除的:data.dropna(axis=0, how='any', inplace=True) # 删除带有NAN的一整行数据,并修改原值
-
对于重复出现的行或列:data.drop_duplicates(axis=0, inplace=True) # 删除重复的行,并修改原值
-
对于无用的行或列:data.drop(columns='order_id', axis=1, inplace=True) # 删除 order_id 这一列
-
对于需要更新索引的数据:data.reset_index(drop=True, inplace=True) 把原来的索引index列删除,并更新index
-
对于单位不统一的数据:如下图
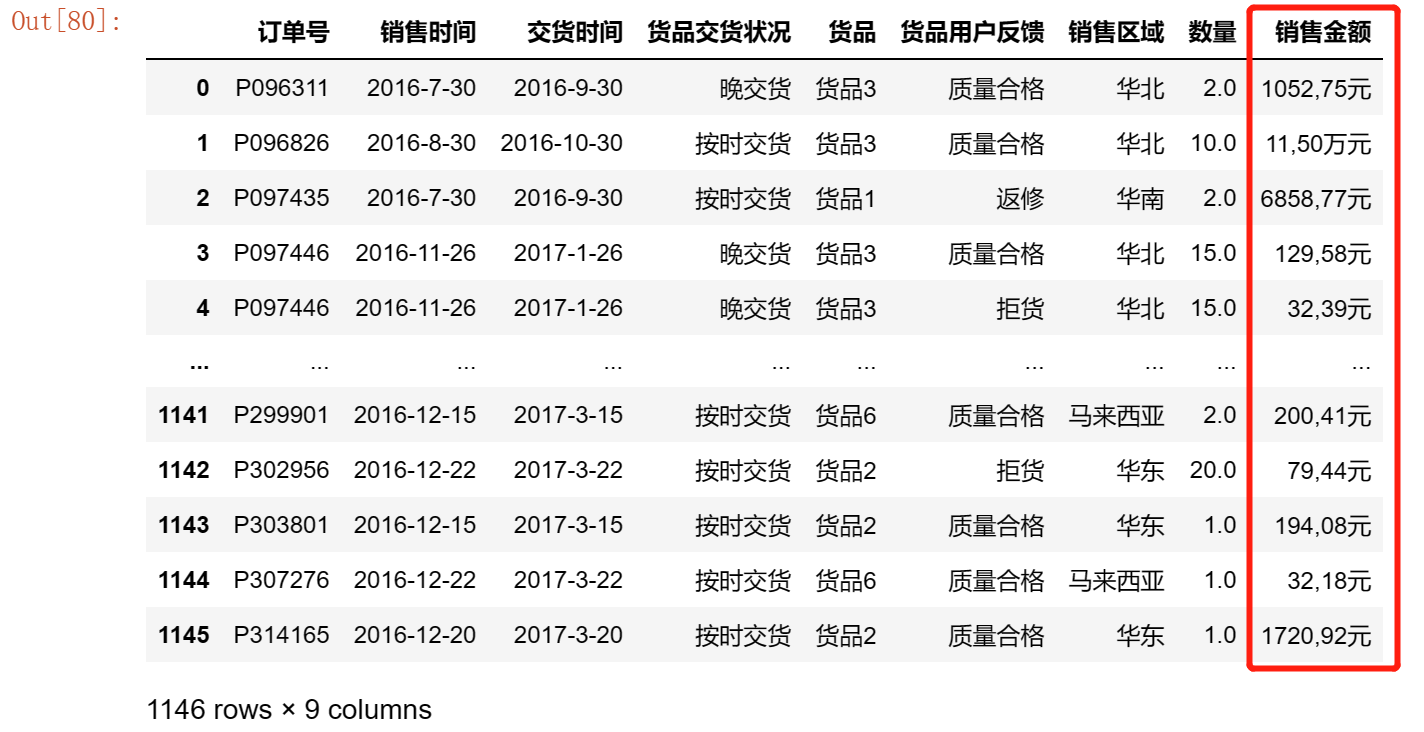
看到销售金额一列的单位有元也有万元,并且含有逗号,为了方便处理,我们将其格式化。
def data_deal(number):
if number.find('万元')!= -1:#找到带有万元的,取出数字,去掉逗号,转成float,*10000
number_new = float(number[:number.find('万元')].replace(',',''))*10000
else: # 找到带有元的并处理
number_new = float(number[:number.find('元')].replace(',',''))
return number_new
data['销售金额'] = data['销售金额'].map(data_deal)
这里我们使用到了 Series.map() 函数,该函数的作用与 apply 和 applymap 类似,接收一个函数或含有映射关系的字典型对象,区别如下:
-
apply:作用于dataframe的整行或整列
-
applymap:作用于dataframe的每一个元素
-
map:作用于series中的每一个元素,在df结构中无法使用map函数
Time:2023年7月13日23:22:21