全网最详细4W字Flink入门笔记(上)
本文已收录至Github,推荐阅读 👉 Java随想录
微信公众号:Java随想录
注:原文字数过多,单篇阅读时间过长,故将文章拆分为上下两篇。
因为公司用到大数据技术栈的缘故,之前也写过HBase,Spark等文章,公司离线用的是Spark,实时用的是Flink,所以这篇文章是关于Flink的,这篇文章对Flink的相关概念介绍的比较全面,希望对大家学习Flink能有所帮助。
Flink的一些概念和Spark非常像,看这篇文章之前,强烈建议翻看之前的Spark文章,这样学习Flink的时候能够举一反三,有助于理解。
流处理 & 批处理
事实上 Flink 本身是流批统一的处理架构,批量的数据集本质上也是流。在 Flink 的视角里,一切数据都可以认为是流,流数据是无界流,而批数据则是有界流,流数据每输入一条数据,就有一次对应的输出。
批处理,也叫作离线处理。针对的是有界数据集,非常适合需要访问海量的全部数据才能完成的计算工作,一般用于离线统计。
流处理主要针对的是数据流,特点是无界、实时,对系统传输的每个数据依次执行操作,一般用于实时统计。
无界流Unbounded streams
无界流有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
有界流Bounded streams
有界流有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。所以在Flink里批计算其实指的就是有界流。

Flink的特点和优势
- 同时支持高吞吐、低延迟、高性能。
- 支持事件时间(Event Time)概念,结合Watermark处理乱序数据
- 支持有状态计算,并且支持多种状态内存、 文件、RocksDB。
- 支持高度灵活的窗口(Window) 操作time、 count、 session。
- 基于轻量级分布式快照(CheckPoint) 实现的容错保证Exactly- Once语义。
- 基于JVM实现独立的内存管理。
- Save Points (保存点)。
Flink VS Spark
Spark 和 Flink 在不同的应用领域上表现会有差别。一般来说,Spark 基于微批处理的方式做同步总有一个“攒批”的过程,所以会有额外开销,因此无法在流处理的低延迟上做到极致。在低延迟流处理场景,Flink 已经有明显的优势。而在海量数据的批处理领域,Spark 能够处理的吞吐量更大。
Spark Streaming的流计算其实是微批计算,实时性不如Flink,还有一点很重要的是Spark Streaming不适合有状态的计算,得借助一些存储如:Redis,才能实现。而Flink天然支持有状态的计算。
Flink API
Flink 本身提供了多层 API:

- Stateful Stream Processing 最低级的抽象接口是状态化的数据流接口(stateful streaming)。这个接口是通过 ProcessFunction 集成到 DataStream API 中的。该接口允许用户自由的处理来自一个或多个流中的事件,并使用一致的容错状态。另外,用户也可以通过注册 event time 和 processing time 处理回调函数的方法来实现复杂的计算。
- DataStream/DataSet API DataStream / DataSet API 是 Flink 提供的核心 API ,DataSet 处理有界的数据集,DataStream 处理有界或者无界的数据流。用户可以通过各种方法(map / flatmap / window / keyby / sum / max / min / avg / join 等)将数据进行转换 / 计算。
- Table API Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起来却更加简洁,可以在表与 DataStream/DataSet 之间无缝切换,也允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
- SQL Flink 提供的最高层级的抽象是 SQL,这一层抽象在语法与表达能力上与 Table API 类似,SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
Dataflows数据流图
所有的 Flink 程序都可以归纳为由三部分构成:Source、Transformation 和 Sink。
-
Source 表示“源算子”,负责读取数据源。
-
Transformation 表示“转换算子”,利用各种算子进行处理加工。
-
Sink 表示“下沉算子”,负责数据的输出。
source数据源会源源不断的产生数据,transformation将产生的数据进行各种业务逻辑的数据处理,最终由sink输出到外部(console、kafka、redis、DB......)。
基于Flink开发的程序都能够映射成一个Dataflows。
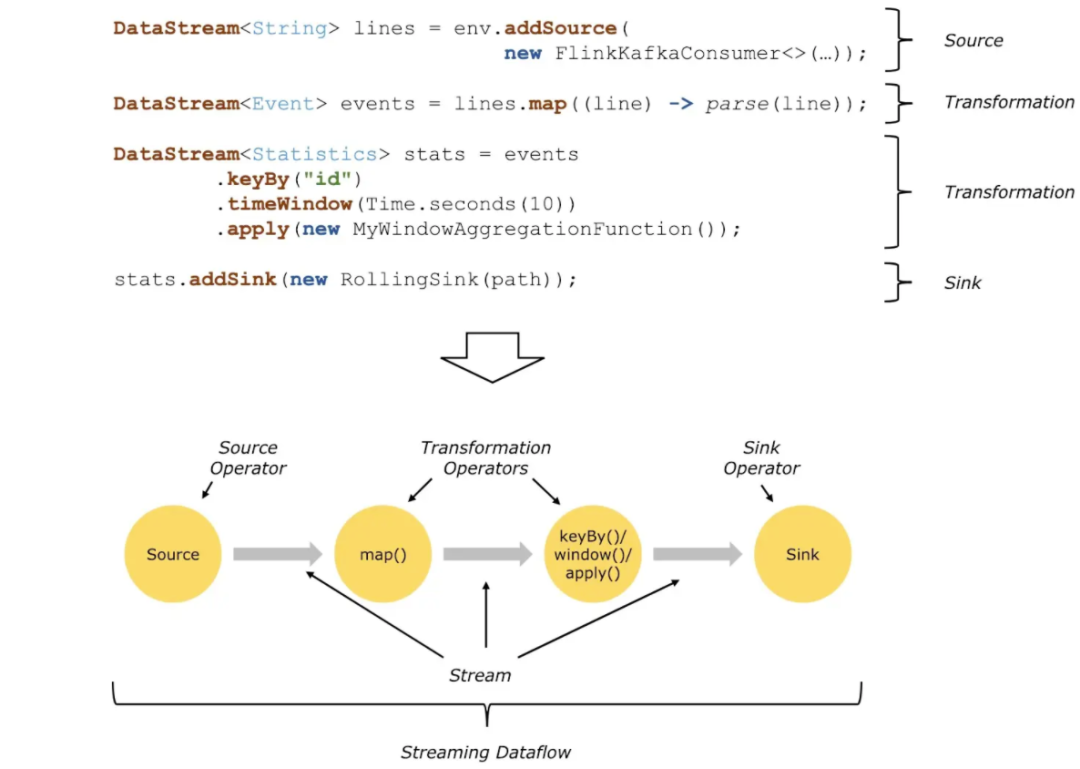
当source数据源的数量比较大或计算逻辑相对比较复杂的情况下,需要提高并行度来处理数据,采用并行数据流。
通过设置不同算子的并行度, source并行度设置为2 , map也是2。代表会启动2个并行的线程来处理数据:

Flink基本架构
Flink系统架构中包含了两个角色,分别是JobManager和TaskManager,是一个典型的Master-Slave架构。JobManager相当于是Master,TaskManager相当于是Slave。

Job Manager & Task Manager
在Flink中,JobManager负责整个Flink集群任务的调度以及资源的管理。它从客户端中获取提交的应用,然后根据集群中TaskManager上TaskSlot的使用情况,为提交的应用分配相应的TaskSlot资源并命令TaskManager启动从客户端中获取的应用。
TaskManager负责执行作业流的Task,并且缓存和交换数据流。在TaskManager中资源调度的最小单位是Task slot。TaskManager中Task slot的数量表示并发处理Task的数量。一台机器节点可以运行多个TaskManager 。
TaskManager会向JobManager发送心跳保持连接。
集群 & 部署
部署模式
Flink支持多种部署模式,包括本地模式、Standalone模式、YARN模式、Mesos模式和Kubernetes模式。
- 本地模式:本地模式是在单个JVM中启动Flink,主要用于开发和测试。它不需要任何集群管理器,但也不能跨多台机器运行。本地模式的优点是部署简单,缺点是不能利用分布式计算的优势。
- Standalone模式:Standalone模式是在一个独立的集群中运行Flink。它需要手动启动Flink集群,并且需要手动管理资源。Standalone模式的优点是部署简单,可以跨多台机器运行,缺点是需要手动管理资源。
- YARN模式:YARN模式是在Hadoop YARN集群中运行Flink。它可以利用YARN进行资源管理和调度。YARN模式的优点是可以利用现有的Hadoop集群,缺点是需要安装和配置Hadoop YARN,这是在企业中使用最多的方式。
- Mesos模式:Mesos模式是在Apache Mesos集群中运行Flink。它可以利用Mesos进行资源管理和调度。Mesos模式的优点是可以利用现有的Mesos集群,缺点是需要安装和配置Mesos。
- Kubernetes模式:Kubernetes模式是在Kubernetes集群中运行Flink。它可以利用Kubernetes进行资源管理和调度。Kubernetes模式的优点是可以利用现有的Kubernetes集群,缺点是需要安装和配置Kubernetes。
每种部署模式都有其优缺点,选择哪种部署模式取决于具体的应用场景和需求。
Session、Per-Job和Application是Flink在YARN和Kubernetes上运行时的三种不同模式,它们不是独立的部署模式,而是在YARN和Kubernetes部署模式下的子模式。
- Session模式:在Session模式下,Flink集群会一直运行,用户可以在同一个Flink集群中提交多个作业。Session模式的优点是作业提交快,缺点是作业之间可能会相互影响。
- Per-Job模式:在Per-Job模式下,每个作业都会启动一个独立的Flink集群。Per-Job模式的优点是作业之间相互隔离,缺点是作业提交慢。
- Application模式:Application模式是在Flink 1.11版本中引入的一种新模式,它结合了Session模式和Per-Job模式的优点。在Application模式下,每个作业都会启动一个独立的Flink集群,但是作业提交快。
这三种模式都可以在YARN和Kubernetes部署模式下使用。
提交作业流程
- Session 模式:
- 在 Session 模式下,Flink 运行在交互式会话中,允许用户在一个 Flink 集群上连续地提交和管理多个作业。
- 用户可以通过 Flink 命令行界面(CLI)或 Web UI 进行交互。
- 提交流程如下:
- 用户启动 Flink 会话,并连接到 Flink 集群。
- 用户使用 CLI 或 Web UI 提交作业,提交的作业被发送到 Flink 集群的 JobManager。
- JobManager 接收作业后,会对作业进行解析和编译,生成作业图(JobGraph)。
- 生成的作业图被发送到 JobManager 的调度器进行调度。
- 调度器将作业图划分为任务并将其分配给 TaskManager 执行。
- TaskManager 在其本地执行环境中运行任务。
- Per-Job 模式:
- 在 Per-Job 模式下,每个作业都会启动一个独立的 Flink 集群,用于执行该作业。
- 这种模式适用于独立的批处理或流处理作业,不需要与其他作业共享资源。
- 提交流程如下:
- 用户准备好作业程序和所需的配置文件。
- 用户使用 Flink 提供的命令行工具或编程 API 将作业程序和配置文件打包成一个作业 JAR 文件。
- 用户将作业 JAR 文件上传到 Flink 集群所在的环境(例如 Hadoop 分布式文件系统)。
- 用户使用 Flink 提供的命令行工具或编程 API 在指定的 Flink 集群上提交作业。
- JobManager 接收作业 JAR 文件并进行解析、编译和调度。
- 调度器将作业图划分为任务并将其分配给可用的 TaskManager 执行。
- TaskManager 在其本地执行环境中运行任务。
- Application 模式:
- Application 模式是 Flink 1.11 版本引入的一种模式,用于在常驻的 Flink 集群上执行多个应用程序。
- 在 Application 模式下,用户可以在运行中的 Flink 集群上动态提交、更新和停止应用程序。
- 提交流程如下:
- 用户准备好应用程序程序和所需的配置文件。
- 用户使用 Flink 提供的命令行工具或编程 API 将应用程序程序和配置文件打包成一个应用程序 JAR 文件。
- 用户将应用程序 JAR 文件上传到 Flink 集群所在的环境(例如 Hadoop 分布式文件系统)。
- 用户使用 Flink 提供的命令行工具或编程 API 在指定的 Flink 集群上提交应用程序。
- JobManager 接收应用程序 JAR 文件并进行解析、编译和调度。
- 调度器将应用程序图划分为任务并将其分配给可用的 TaskManager 执行。
- TaskManager 在其本地执行环境中运行任务。
配置开发环境
每个 Flink 应用都需要依赖一组 Flink 类库。Flink 应用至少需要依赖 Flink APIs。许多应用还会额外依赖连接器类库(比如 Kafka、Cassandra 等)。 当用户运行 Flink 应用时(无论是在 IDEA 环境下进行测试,还是部署在分布式环境下),运行时类库都必须可用
开发工具:IntelliJ IDEA
配置开发Maven依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
注意点:
- 如果要将程序打包提交到集群运行,打包的时候不需要包含这些依赖,因为集群环境已经包含了这些依赖,此时依赖的作用域应该设置为provided。
- Flink 应用在 IntelliJ IDEA 中运行,这些 Flink 核心依赖的作用域需要设置为 compile 而不是 provided 。 否则 IntelliJ 不会添加这些依赖到 classpath,会导致应用运行时抛出
NoClassDefFountError异常。
添加打包插件:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!--不要拷贝 META-INF 目录下的签名,
否则会引起 SecurityExceptions 。 -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>my.programs.main.clazz</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
WordCount流批计算程序
配置好开发环境之后写一个简单的Flink程序。
实现:统计HDFS文件单词出现的次数
读取HDFS数据需要添加Hadoop依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
批计算:
val env = ExecutionEnvironment.getExecutionEnvironment
val initDS: DataSet[String] = env.readTextFile("hdfs://node01:9000/flink/data/wc")
val restDS: AggregateDataSet[(String, Int)] = initDS.flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1)
restDS.print()
流计算:
/** 准备环境
* createLocalEnvironment 创建一个本地执行的环境,local
* createLocalEnvironmentWithWebUI 创建一个本地执行的环境,同时还开启Web UI的查看端口,8081
* getExecutionEnvironment 根据你执行的环境创建上下文,比如local cluster
*/
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
/**
* DataStream:一组相同类型的元素 组成的数据流
*/
val initStream:DataStream[String] = env.socketTextStream("node01",8888)
val wordStream = initStream.flatMap(_.split(" "))
val pairStream = wordStream.map((_,1))
val keyByStream = pairStream.keyBy(0)
val restStream = keyByStream.sum(1)
restStream.print()
//启动Flink 任务
env.execute("first flink job")
并行度
特定算子的子任务(subtask)的个数称之为并行度(parallel),并行度是几,这个task内部就有几个subtask。
怎样实现算子并行呢?其实也很简单,我们把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行的“子任务”(subtasks),再将它们分发到不同节点,就真正实现了并行计算。
整个流处理程序的并行度,理论上是所有算子并行度中最大的那个,这代表了运行程序需要的 slot 数量。
并行度设置
在 Flink 中,可以用不同的方法来设置并行度,它们的有效范围和优先级别也是不同的。
代码中设置
- 我们在代码中,可以很简单地在算子后跟着调用
setParallelism()方法,来设置当前算子的并行度:stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);这种方式设置的并行度,只针对当前算子有效。 - 我们也可以直接调用执行环境的
setParallelism()方法,全局设定并行度:env.setParallelism(2);这样代码中所有算子,默认的并行度就都为 2 了。
提交应用时设置
在使用 flink run 命令提交应用时,可以增加 -p 参数来指定当前应用程序执行的并行度,它的作用类似于执行环境的全局设置。如果我们直接在 Web UI 上提交作业,也可以在对应输入框中直接添加并行度。
配置文件中设置
我们还可以直接在集群的配置文件 flink-conf.yaml 中直接更改默认并行度:parallelism.default: 2(初始值为 1)
这个设置对于整个集群上提交的所有作业有效。
在开发环境中,没有配置文件,默认并行度就是当前机器的 CPU 核心数。
并行度生效优先级
- 对于一个算子,首先看在代码中是否单独指定了它的并行度,这个特定的设置优先级最高,会覆盖后面所有的设置。
- 如果没有单独设置,那么采用当前代码中执行环境全局设置的并行度。
- 如果代码中完全没有设置,那么采用提交时-p 参数指定的并行度。
- 如果提交时也未指定-p 参数,那么采用集群配置文件中的默认并行度。
这里需要说明的是,算子的并行度有时会受到自身具体实现的影响。比如读取 socket 文本流的算子 socketTextStream,它本身就是非并行的 Source 算子,所以无论怎么设置,它在运行时的并行度都是 1。
Task
在 Flink 中,Task 是一个阶段多个功能相同 subTask 的集合,Flink 会尽可能地将 operator 的 subtask 链接(chain)在一起形成 task。每个 task 在一个线程中执行。将 operators 链接成 task 是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。
要是之前学过Spark,这里可以用Spark的思想来看,Flink的Task就好比Spark中的Stage,而我们知道Spark的Stage是根据宽依赖来拆分的。所以我们也可以认为Flink的Task也是根据宽依赖拆分的(尽管Flink中并没有宽依赖的概念),这样会更好理解,如下图:
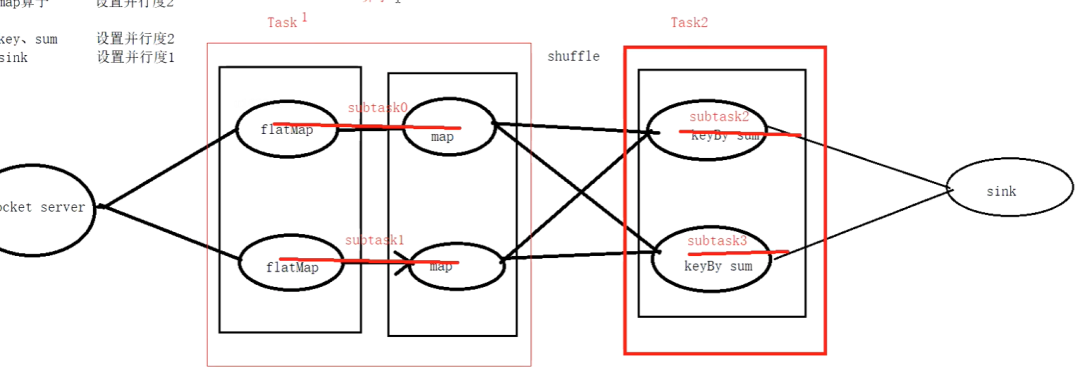
Operator Chain(算子链)
在Flink中,为了分布式执行,Flink会将算子子任务链接在一起形成任务。每个任务由一个线程执行。将算子链接在一起形成任务是一种有用的优化:它减少了线程间切换和缓冲的开销,并增加了整体吞吐量,同时降低了延迟。
举个例子,假设我们有一个简单的Flink流处理程序,它从一个源读取数据,然后应用map和filter操作,最后将结果写入到一个接收器。这个程序可能看起来像这样:
DataStream<String> data = env.addSource(new CustomSource());
data.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.toUpperCase();
}
})
.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("A");
}
})
.addSink(new CustomSink());
在这个例子中,map和filter操作可以被链接在一起形成一个任务,被优化为算子链,这意味着它们将在同一个线程中执行,而不是在不同的线程中执行并通过网络进行数据传输。
Task Slots
Task Slots即是任务槽,slot 在 Flink 里面可以认为是资源组,Flink 将每个任务分成子任务并且将这些子任务分配到 slot 来并行执行程序,我们可以通过集群的配置文件来设定 TaskManager 的 slot 数量:taskmanager.numberOfTaskSlots: 8。
例如,如果 Task Manager 有2个 slot,那么它将为每个 slot 分配 50% 的内存。 可以在一个 slot 中运行一个或多个线程。 同一 slot 中的线程共享相同的 JVM。
需要注意的是,slot 目前仅仅用来隔离内存,不会涉及 CPU 的隔离。在具体应用时,可以将 slot 数量配置为机器的 CPU 核心数,尽量避免不同任务之间对 CPU 的竞争。这也是开发环境默认并行度设为机器 CPU 数量的原因。
分发规则
- 不同的Task下的subtask要分发到同一个TaskSlot中,降低数据传输、提高执行效率。
- 相同的Task下的subtask要分发到不同的TaskSlot。
Slot共享组
如果希望某个算子对应的任务完全独占一个 slot,或者只有某一部分算子共享 slot,在Flink中,可以通过在代码中使用slotSharingGroup方法来设置slot共享组。Flink会将具有相同slot共享组的操作放入同一个slot中,同时保持不具有slot共享组的操作在其他slot中。这可以用来隔离slot。
例如,你可以这样设置:
dataStream.map(...).slotSharingGroup("group1");
默认情况下,所有操作都被分配相同的SlotSharingGroup。
这样,只有属于同一个 slot 共享组的子任务,才会开启 slot 共享;不同组之间的任务是完全隔离的,必须分配到不同的 slot 上。
并行度和Slots的例子
听了上面并行度和Slots的理论,可能有点疑惑,通过一个例子简单说明下:
假设一共有3个TaskManager,每一个TaskManager中的slot数量设置为3个,那么一共有9个task slot,表示最多能并行执行9个任务。
假设我们写了一个WordCount程序,有四个转换算子:source —> flatMap —> reduce —> sink。
当所有算子并行度相同时,容易看出source和flatMap可以优化合并算子链,于是最终有三个任务节点:source & flatMap,reduce 和sink。
如果我们没有任何并行度设置,而配置文件中默认parallelism.default=1,那么程序运行的默认并行度为1,总共有3个任务。由于不同算子的任务可以共享任务槽,所以最终占用的slot只有1个。9个slot只用了1个,有8个空闲。如图所示:

我们可以直接把并行度设置为 9,这样所有 3*9=27 个任务就会完全占用 9 个 slot。这是当前集群资源下能执行的最大并行度,计算资源得到了充分的利用。
另外再考虑对于某个算子单独设置并行度的场景。例如,如果我们考虑到输出可能是写入文件,那会希望不要并行写入多个文件,就需要设置 sink 算子的并行度为 1。这时其他的算子并行度依然为 9,所以总共会有 19 个子任务。根据 slot 共享的原则,它们最终还是会占用全部的 9 个 slot,而 sink 任务只在其中一个 slot 上执行,通过这个例子也可以明确地看到,整个流处理程序的并行度,就应该是所有算子并行度中最大的那个,这代表了运行程序需要的 slot 数量。
DataSource数据源
Flink内嵌支持的数据源非常多,比如HDFS、Socket、Kafka、Collections。Flink也提供了addSource方式,可以自定义数据源,下面介绍一些常用的数据源。
File Source
- 通过读取本地、HDFS文件创建一个数据源。
如果读取的是HDFS上的文件,那么需要导入Hadoop依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
代码示例:每隔10s去读取HDFS指定目录下的新增文件内容,并且进行WordCount。
import org.apache.flink.api.java.io.TextInputFormat
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.source.FileProcessingMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
//在算子转换的时候,会将数据转换成Flink内置的数据类型,所以需要将隐式转换导入进来,才能自动进行类型转换
import org.apache.flink.streaming.api.scala._
object FileSource {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//读取hdfs文件
val filePath = "hdfs://node01:9000/flink/data/"
val textInputFormat = new TextInputFormat(new Path(filePath))
//每隔10s中读取 hdfs上新增文件内容
val textStream = env.readFile(textInputFormat,filePath,FileProcessingMode.PROCESS_CONTINUOUSLY,10)
textStream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1).print()
env.execute()
}
}
readTextFile底层调用的就是readFile方法,readFile是一个更加底层的方式,使用起来会更加的灵活
Collection Source
基于本地集合的数据源,一般用于测试场景,没有太大意义。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
object CollectionSource {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.fromCollection(List("hello flink msb","hello msb msb"))
stream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1).print()
env.execute()
}
}
Socket Source
接受Socket Server中的数据。
val initStream:DataStream[String] = env.socketTextStream("node01",8888)
Kafka Source
Flink接受Kafka中的数据,首先要配置flink与kafka的连接器依赖。
Maven依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.9.2</version>
</dependency>
代码:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val prop = new Properties()
prop.setProperty("bootstrap.servers","node01:9092,node02:9092,node03:9092")
prop.setProperty("group.id","flink-kafka-id001")
prop.setProperty("key.deserializer",classOf[StringDeserializer].getName)
prop.setProperty("value.deserializer",classOf[StringDeserializer].getName)
/**
* earliest:从头开始消费,旧数据会频繁消费
* latest:从最近的数据开始消费,不再消费旧数据
*/
prop.setProperty("auto.offset.reset","latest")
val kafkaStream = env.addSource(new FlinkKafkaConsumer[(String, String)]("flink-kafka", new KafkaDeserializationSchema[(String, String)] {
override def isEndOfStream(t: (String, String)): Boolean = false
override def deserialize(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
val key = new String(consumerRecord.key(), "UTF-8")
val value = new String(consumerRecord.value(), "UTF-8")
(key, value)
}
//指定返回数据类型
override def getProducedType: TypeInformation[(String, String)] =
createTuple2TypeInformation(createTypeInformation[String], createTypeInformation[String])
}, prop))
kafkaStream.print()
env.execute()
Transformations
Transformations算子可以将一个或者多个算子转换成一个新的数据流,使用Transformations算子组合可以进行复杂的业务处理。
Map
DataStream → DataStream
遍历数据流中的每一个元素,产生一个新的元素。
FlatMap
DataStream → DataStream
遍历数据流中的每一个元素,产生N个元素 N=0,1,2,......。
Filter
DataStream → DataStream
过滤算子,根据数据流的元素计算出一个boolean类型的值,true代表保留,false代表过滤掉。
KeyBy
DataStream → KeyedStream
根据数据流中指定的字段来分区,相同指定字段值的数据一定是在同一个分区中,内部分区使用的是HashPartitioner。
指定分区字段的方式有三种:
1、根据索引号指定
2、通过匿名函数来指定
3、通过实现KeySelector接口 指定分区字段
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1, 100)
stream
.map(x => (x % 3, 1))
//根据索引号来指定分区字段
// .keyBy(0)
//通过传入匿名函数 指定分区字段
// .keyBy(x=>x._1)
//通过实现KeySelector接口 指定分区字段
.keyBy(new KeySelector[(Long, Int), Long] {
override def getKey(value: (Long, Int)): Long = value._1
})
.sum(1)
.print()
env.execute()
Reduce
KeyedStream:根据key分组 → DataStream
注意,reduce是基于分区后的流对象进行聚合,也就是说,DataStream类型的对象无法调用reduce方法。
.reduce((v1,v2) => (v1._1,v1._2 + v2._2))
代码例子:读取kafka数据,实时统计各个卡口下的车流量。
- 实现kafka生产者,读取卡口数据并且往kafka中生产数据:
val prop = new Properties()
prop.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
prop.setProperty("key.serializer", classOf[StringSerializer].getName)
prop.setProperty("value.serializer", classOf[StringSerializer].getName)
val producer = new KafkaProducer[String, String](prop)
val iterator = Source.fromFile("data/carFlow_all_column_test.txt", "UTF-8").getLines()
for (i <- 1 to 100) {
for (line <- iterator) {
//将需要的字段值 生产到kafka集群 car_id monitor_id event-time speed
//车牌号 卡口号 车辆通过时间 通过速度
val splits = line.split(",")
val monitorID = splits(0).replace("'","")
val car_id = splits(2).replace("'","")
val eventTime = splits(4).replace("'","")
val speed = splits(6).replace("'","")
if (!"00000000".equals(car_id)) {
val event = new StringBuilder
event.append(monitorID + "\t").append(car_id+"\t").append(eventTime + "\t").append(speed)
producer.send(new ProducerRecord[String, String]("flink-kafka", event.toString()))
}
Thread.sleep(500)
}
}
- 实现kafka消费者:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers","node01:9092,node02:9092,node03:9092")
props.setProperty("key.deserializer",classOf[StringDeserializer].getName)
props.setProperty("value.deserializer",classOf[StringDeserializer].getName)
props.setProperty("group.id","flink001")
props.getProperty("auto.offset.reset","latest")
val stream = env.addSource(new FlinkKafkaConsumer[String]("flink-kafka", new SimpleStringSchema(),props))
stream.map(data => {
val splits = data.split("\t")
val carFlow = CarFlow(splits(0),splits(1),splits(2),splits(3).toDouble)
(carFlow,1)
}).keyBy(_._1.monitorId)
.sum(1)
.print()
env.execute()
Aggregations
KeyedStream → DataStream
Aggregations代表的是一类聚合算子,具体算子如下:
keyedStream.sum(0)
keyedStream.sum("key")
keyedStream.min(0)
keyedStream.min("key")
keyedStream.max(0)
keyedStream.max("key")
keyedStream.minBy(0)
keyedStream.minBy("key")
keyedStream.maxBy(0)
keyedStream.maxBy("key")
代码例子:实时统计各个卡口最先通过的汽车的信息
val stream = env.addSource(new FlinkKafkaConsumer[String]("flink-kafka", new SimpleStringSchema(),props))
stream.map(data => {
val splits = data.split("\t")
val carFlow = CarFlow(splits(0),splits(1),splits(2),splits(3).toDouble)
val eventTime = carFlow.eventTime
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val date = format.parse(eventTime)
(carFlow,date.getTime)
}).keyBy(_._1.monitorId)
.min(1)
.map(_._1)
.print()
env.execute()
Union 真合并
DataStream → DataStream
Union of two or more data streams creating a new stream containing all the elements from all the streams
合并两个或者更多的数据流产生一个新的数据流,这个新的数据流中包含了所合并的数据流的元素。
注意:需要保证数据流中元素类型一致
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds1 = env.fromCollection(List(("a",1),("b",2),("c",3)))
val ds2 = env.fromCollection(List(("d",4),("e",5),("f",6)))
val ds3 = env.fromCollection(List(("g",7),("h",8)))
val unionStream = ds1.union(ds2,ds3)
unionStream.print()
env.execute()
输出:
("a", 1)
("b", 2)
("c", 3)
("d", 4)
("e", 5)
("f", 6)
("g", 7)
("h", 8)
Connect 假合并
DataStream,DataStream → ConnectedStreams
合并两个数据流并且保留两个数据流的数据类型,能够共享两个流的状态
val ds1 = env.socketTextStream("node01", 8888)
val ds2 = env.socketTextStream("node01", 9999)
val wcStream1 = ds1.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)
val wcStream2 = ds2.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)
val restStream: ConnectedStreams[(String, Int), (String, Int)] = wcStream2.connect(wcStream1)
CoMap, CoFlatMap
ConnectedStreams → DataStream
CoMap, CoFlatMap并不是具体算子名字,而是一类操作名称
凡是基于ConnectedStreams数据流做map遍历,这类操作叫做CoMap
凡是基于ConnectedStreams数据流做flatMap遍历,这类操作叫做CoFlatMap
CoMap第一种实现方式:
restStream.map(new CoMapFunction[(String,Int),(String,Int),(String,Int)] {
//对第一个数据流做计算
override def map1(value: (String, Int)): (String, Int) = {
(value._1+":first",value._2+100)
}
//对第二个数据流做计算
override def map2(value: (String, Int)): (String, Int) = {
(value._1+":second",value._2*100)
}
}).print()
CoMap第二种实现方式:
restStream.map(
//对第一个数据流做计算
x=>{(x._1+":first",x._2+100)}
//对第二个数据流做计算
,y=>{(y._1+":second",y._2*100)}
).print()
代码例子:现有一个配置文件存储车牌号与车主的真实姓名,通过数据流中的车牌号实时匹配出对应的车主姓名(注意:配置文件可能实时改变)
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val filePath = "data/carId2Name"
val carId2NameStream = env.readFile(new TextInputFormat(new Path(filePath)),filePath,FileProcessingMode.PROCESS_CONTINUOUSLY,10)
val dataStream = env.socketTextStream("node01",8888)
dataStream.connect(carId2NameStream).map(new CoMapFunction[String,String,String] {
private val hashMap = new mutable.HashMap[String,String]()
override def map1(value: String): String = {
hashMap.getOrElse(value,"not found name")
}
override def map2(value: String): String = {
val splits = value.split(" ")
hashMap.put(splits(0),splits(1))
value + "加载完毕..."
}
}).print()
env.execute()
CoFlatMap第一种实现方式:
ds1.connect(ds2).flatMap((x,c:Collector[String])=>{
//对第一个数据流做计算
x.split(" ").foreach(w=>{
c.collect(w)
})
}
//对第二个数据流做计算
,(y,c:Collector[String])=>{
y.split(" ").foreach(d=>{
c.collect(d)
})
}).print
CoFlatMap第二种实现方式:
ds1.connect(ds2).flatMap(
//对第一个数据流做计算
x=>{
x.split(" ")
}
//对第二个数据流做计算
,y=>{
y.split(" ")
}).print()
CoFlatMap第三种实现方式:
ds1.connect(ds2).flatMap(new CoFlatMapFunction[String,String,(String,Int)] {
//对第一个数据流做计算
override def flatMap1(value: String, out: Collector[(String, Int)]): Unit = {
val words = value.split(" ")
words.foreach(x=>{
out.collect((x,1))
})
}
//对第二个数据流做计算
override def flatMap2(value: String, out: Collector[(String, Int)]): Unit = {
val words = value.split(" ")
words.foreach(x=>{
out.collect((x,1))
})
}
}).print()
Split
DataStream → SplitStream
根据条件将一个流分成两个或者更多的流
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,100)
val splitStream = stream.split(
d => {
d % 2 match {
case 0 => List("even")
case 1 => List("odd")
}
}
)
splitStream.select("even").print()
env.execute()
Select
SplitStream → DataStream
从SplitStream中选择一个或者多个数据流
splitStream.select("even").print()
Iterate
DataStream → IterativeStream → DataStream
Iterate算子提供了对数据流迭代的支持
迭代由两部分组成:迭代体、终止迭代条件,不满足终止迭代条件的数据流会返回到stream流中,进行下一次迭代,满足终止迭代条件的数据流继续往下游发送:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val initStream = env.socketTextStream("node01",8888)
val stream = initStream.map(_.toLong)
stream.iterate {
iteration => {
//定义迭代逻辑
val iterationBody = iteration.map ( x => {
println(x)
if(x > 0) x - 1
else x
} )
//> 0 大于0的值继续返回到stream流中,当 <= 0 继续往下游发送
(iterationBody.filter(_ > 0), iterationBody.filter(_ <= 0))
}
}.print()
env.execute()
函数类和富函数类
在使用Flink算子的时候,可以通过传入匿名函数和函数类对象。
函数类分为:普通函数类、富函数类。
富函数类相比于普通的函数,可以获取运行环境的上下文(Context),拥有一些生命周期方法,管理状态,可以实现更加复杂的功能
| 普通函数类 | 富函数类 |
|---|---|
| MapFunction | RichMapFunction |
| FlatMapFunction | RichFlatMapFunction |
| FilterFunction | RichFilterFunction |
| ...... | ...... |
- 使用普通函数类过滤掉车速高于100的车辆信息
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("./data/carFlow_all_column_test.txt")
stream.filter(new FilterFunction[String] {
override def filter(value: String): Boolean = {
if (value != null && !"".equals(value)) {
val speed = value.split(",")(6).replace("'", "").toLong
if (speed > 100)
false
else
true
}else
false
}
}).print()
env.execute()
- 使用富函数类,将车牌号转化成车主真实姓名,映射表存储在Redis中
添加redis依赖,数据写入到redis。
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>${redis.version}</version>
</dependency>
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("node01", 8888)
stream.map(new RichMapFunction[String, String] {
private var jedis: Jedis = _
//初始化函数 在每一个thread启动的时候(处理元素的时候,会调用一次)
//在open中可以创建连接redis的连接
override def open(parameters: Configuration): Unit = {
//getRuntimeContext可以获取flink运行的上下文环境 AbstractRichFunction抽象类提供的
val taskName = getRuntimeContext.getTaskName
val subtasks = getRuntimeContext.getTaskNameWithSubtasks
println("=========open======"+"taskName:" + taskName + "\tsubtasks:"+subtasks)
jedis = new Jedis("node01", 6379)
jedis.select(3)
}
//每处理一个元素,就会调用一次
override def map(value: String): String = {
val name = jedis.get(value)
if(name == null){
"not found name"
}else
name
}
//元素处理完毕后,会调用close方法
//关闭redis连接
override def close(): Unit = {
jedis.close()
}
}).setParallelism(2).print()
env.execute()
ProcessFunction(处理函数)
ProcessFunction属于低层次的API,我们前面讲的map、filter、flatMap等算子都是基于这层高层封装出来的。
越低层次的API,功能越强大,用户能够获取的信息越多,比如可以拿到元素状态信息、事件时间、设置定时器等
-
代码例子:监控每辆汽车,车速超过100迈,2s钟后发出超速的警告通知:
object MonitorOverSpeed02 { case class CarInfo(carId:String,speed:Long) def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.socketTextStream("node01",8888) stream.map(data => { val splits = data.split(" ") val carId = splits(0) val speed = splits(1).toLong CarInfo(carId,speed) }).keyBy(_.carId) //KeyedStream调用process需要传入KeyedProcessFunction //DataStream调用process需要传入ProcessFunction .process(new KeyedProcessFunction[String,CarInfo,String] { override def processElement(value: CarInfo, ctx: KeyedProcessFunction[String, CarInfo, String]#Context, out: Collector[String]): Unit = { val currentTime = ctx.timerService().currentProcessingTime() if(value.speed > 100 ){ val timerTime = currentTime + 2 * 1000 ctx.timerService().registerProcessingTimeTimer(timerTime) } } override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, CarInfo, String]#OnTimerContext, out: Collector[String]): Unit = { var warnMsg = "warn... time:" + timestamp + " carID:" + ctx.getCurrentKey out.collect(warnMsg) } }).print() env.execute() } }
总结
使用Map Filter....算子的适合,可以直接传入一个匿名函数、普通函数类对象(MapFuncation FilterFunction),富函数类对象(RichMapFunction、RichFilterFunction),传入的富函数类对象:可以拿到任务执行的上下文,生命周期方法、管理状态.....。
如果业务比较复杂,通过Flink提供这些算子无法满足我们的需求,通过process算子直接使用比较底层API(获取上下文、生命周期方法、测输出流、时间服务等)。
KeyedDataStream调用process,KeyedProcessFunction 。
DataStream调用process,ProcessFunction 。
Sink
Flink内置了大量sink,可以将Flink处理后的数据输出到HDFS、kafka、Redis、ES、MySQL等。
工程场景中,会经常消费kafka中数据,处理结果存储到Redis或者MySQL中
Redis Sink
Flink处理的数据可以存储到Redis中,以便实时查询
Flink内嵌连接Redis的连接器,只需要导入连接Redis的依赖就可以
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
</dependency>
WordCount写入到Redis中,选择的是HSET数据类型,代码如下:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("node01",8888)
val result = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
.sum(1)
//若redis是单机
val config = new FlinkJedisPoolConfig.Builder().setDatabase(3).setHost("node01").setPort(6379).build()
//如果是 redis集群
/*val addresses = new util.HashSet[InetSocketAddress]()
addresses.add(new InetSocketAddress("node01",6379))
addresses.add(new InetSocketAddress("node01",6379))
val clusterConfig = new FlinkJedisClusterConfig.Builder().setNodes(addresses).build()*/
result.addSink(new RedisSink[(String,Int)](config,new RedisMapper[(String,Int)] {
override def getCommandDescription: RedisCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET,"wc")
}
override def getKeyFromData(t: (String, Int)) = {
t._1
}
override def getValueFromData(t: (String, Int)) = {
t._2 + ""
}
}))
env.execute()
Kafka Sink
处理结果写入到kafka topic中,Flink也是默认支持,需要添加连接器依赖,跟读取kafka数据用的连接器依赖相同,之前添加过就不需要再次添加了
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink-version}</version>
</dependency>
import java.lang
import java.util.Properties
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaProducer, KafkaSerializationSchema}
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.common.serialization.StringSerializer
object KafkaSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("node01",8888)
val result = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
.sum(1)
val props = new Properties()
props.setProperty("bootstrap.servers","node01:9092,node02:9092,node03:9092")
// props.setProperty("key.serializer",classOf[StringSerializer].getName)
// props.setProperty("value.serializer",classOf[StringSerializer].getName)
/**
public FlinkKafkaProducer(
FlinkKafkaProducer(defaultTopic: String, serializationSchema: KafkaSerializationSchema[IN], producerConfig: Properties, semantic: FlinkKafkaProducer.Semantic)
*/
result.addSink(new FlinkKafkaProducer[(String,Int)]("wc",new KafkaSerializationSchema[(String, Int)] {
override def serialize(element: (String, Int), timestamp: lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
new ProducerRecord("wc",element._1.getBytes(),(element._2+"").getBytes())
}
},props,FlinkKafkaProducer.Semantic.EXACTLY_ONCE))
env.execute()
}
}
MySQL Sink
Flink处理结果写入到MySQL中,这并不是Flink默认支持的,需要添加MySQL的驱动依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>
因为不是内嵌支持的,所以需要基于RichSinkFunction自定义sink。
代码例子:消费kafka中数据,统计各个卡口的流量,并且存入到MySQL中
注意点:需要去重,操作MySQL需要幂等性
import java.sql.{Connection, DriverManager, PreparedStatement}
import java.util.Properties
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, KafkaDeserializationSchema}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringSerializer
object MySQLSink {
case class CarInfo(monitorId: String, carId: String, eventTime: String, Speed: Long)
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置连接kafka的配置信息
val props = new Properties()
//注意 sparkstreaming + kafka(0.10之前版本) receiver模式 zookeeper url(元数据)
props.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
props.setProperty("group.id", "flink-kafka-001")
props.setProperty("key.deserializer", classOf[StringSerializer].getName)
props.setProperty("value.deserializer", classOf[StringSerializer].getName)
//第一个参数 : 消费的topic名
val stream = env.addSource(new FlinkKafkaConsumer[(String, String)]("flink-kafka", new KafkaDeserializationSchema[(String, String)] {
//什么时候停止,停止条件是什么
override def isEndOfStream(t: (String, String)): Boolean = false
//要进行序列化的字节流
override def deserialize(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
val key = new String(consumerRecord.key(), "UTF-8")
val value = new String(consumerRecord.value(), "UTF-8")
(key, value)
}
//指定一下返回的数据类型 Flink提供的类型
override def getProducedType: TypeInformation[(String, String)] = {
createTuple2TypeInformation(createTypeInformation[String], createTypeInformation[String])
}
}, props))
stream.map(data => {
val value = data._2
val splits = value.split("\t")
val monitorId = splits(0)
(monitorId, 1)
}).keyBy(_._1)
.reduce(new ReduceFunction[(String, Int)] {
//t1:上次聚合完的结果 t2:当前的数据
override def reduce(t1: (String, Int), t2: (String, Int)): (String, Int) = {
(t1._1, t1._2 + t2._2)
}
}).addSink(new MySQLCustomSink)
env.execute()
}
//幂等性写入外部数据库MySQL
class MySQLCustomSink extends RichSinkFunction[(String, Int)] {
var conn: Connection = _
var insertPst: PreparedStatement = _
var updatePst: PreparedStatement = _
//每来一个元素都会调用一次
override def invoke(value: (String, Int), context: SinkFunction.Context[_]): Unit = {
println(value)
updatePst.setInt(1, value._2)
updatePst.setString(2, value._1)
updatePst.execute()
println(updatePst.getUpdateCount)
if(updatePst.getUpdateCount == 0){
println("insert")
insertPst.setString(1, value._1)
insertPst.setInt(2, value._2)
insertPst.execute()
}
}
//thread初始化的时候执行一次
override def open(parameters: Configuration): Unit = {
conn = DriverManager.getConnection("jdbc:mysql://node01:3306/test", "root", "123123")
insertPst = conn.prepareStatement("INSERT INTO car_flow(monitorId,count) VALUES(?,?)")
updatePst = conn.prepareStatement("UPDATE car_flow SET count = ? WHERE monitorId = ?")
}
//thread关闭的时候 执行一次
override def close(): Unit = {
insertPst.close()
updatePst.close()
conn.close()
}
}
}
Socket Sink
Flink处理结果发送到套接字(Socket),基于RichSinkFunction自定义sink:
import java.io.PrintStream
import java.net.{InetAddress, Socket}
import java.util.Properties
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTuple2TypeInformation, createTypeInformation}
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, KafkaDeserializationSchema}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringSerializer
//sink 到 套接字 socket
object SocketSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置连接kafka的配置信息
val props = new Properties()
//注意 sparkstreaming + kafka(0.10之前版本) receiver模式 zookeeper url(元数据)
props.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
props.setProperty("group.id", "flink-kafka-001")
props.setProperty("key.deserializer", classOf[StringSerializer].getName)
props.setProperty("value.deserializer", classOf[StringSerializer].getName)
//第一个参数 : 消费的topic名
val stream = env.addSource(new FlinkKafkaConsumer[(String, String)]("flink-kafka", new KafkaDeserializationSchema[(String, String)] {
//什么时候停止,停止条件是什么
override def isEndOfStream(t: (String, String)): Boolean = false
//要进行序列化的字节流
override def deserialize(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
val key = new String(consumerRecord.key(), "UTF-8")
val value = new String(consumerRecord.value(), "UTF-8")
(key, value)
}
//指定一下返回的数据类型 Flink提供的类型
override def getProducedType: TypeInformation[(String, String)] = {
createTuple2TypeInformation(createTypeInformation[String], createTypeInformation[String])
}
}, props))
stream.map(data => {
val value = data._2
val splits = value.split("\t")
val monitorId = splits(0)
(monitorId, 1)
}).keyBy(_._1)
.reduce(new ReduceFunction[(String, Int)] {
//t1:上次聚合完的结果 t2:当前的数据
override def reduce(t1: (String, Int), t2: (String, Int)): (String, Int) = {
(t1._1, t1._2 + t2._2)
}
}).addSink(new SocketCustomSink("node01",8888))
env.execute()
}
class SocketCustomSink(host:String,port:Int) extends RichSinkFunction[(String,Int)]{
var socket: Socket = _
var writer:PrintStream = _
override def open(parameters: Configuration): Unit = {
socket = new Socket(InetAddress.getByName(host), port)
writer = new PrintStream(socket.getOutputStream)
}
override def invoke(value: (String, Int), context: SinkFunction.Context[_]): Unit = {
writer.println(value._1 + "\t" +value._2)
writer.flush()
}
override def close(): Unit = {
writer.close()
socket.close()
}
}
}
File Sink
Flink处理的结果保存到文件,这种使用方式不是很常见
支持分桶写入,每一个桶就是一个目录,默认每隔一个小时会产生一个分桶,每个桶下面会存储每一个Thread的处理结果,可以设置一些文件滚动的策略(文件打开、文件大小等),防止出现大量的小文件。
Flink默认支持,导入连接文件的连接器依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_2.11</artifactId>
<version>1.9.2</version>
</dependency>
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTuple2TypeInformation, createTypeInformation}
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, KafkaDeserializationSchema}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringSerializer
object FileSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置连接kafka的配置信息
val props = new Properties()
//注意 sparkstreaming + kafka(0.10之前版本) receiver模式 zookeeper url(元数据)
props.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
props.setProperty("group.id", "flink-kafka-001")
props.setProperty("key.deserializer", classOf[StringSerializer].getName)
props.setProperty("value.deserializer", classOf[StringSerializer].getName)
//第一个参数 : 消费的topic名
val stream = env.addSource(new FlinkKafkaConsumer[(String, String)]("flink-kafka", new KafkaDeserializationSchema[(String, String)] {
//什么时候停止,停止条件是什么
override def isEndOfStream(t: (String, String)): Boolean = false
//要进行序列化的字节流
override def deserialize(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
val key = new String(consumerRecord.key(), "UTF-8")
val value = new String(consumerRecord.value(), "UTF-8")
(key, value)
}
//指定一下返回的数据类型 Flink提供的类型
override def getProducedType: TypeInformation[(String, String)] = {
createTuple2TypeInformation(createTypeInformation[String], createTypeInformation[String])
}
}, props))
val restStream = stream.map(data => {
val value = data._2
val splits = value.split("\t")
val monitorId = splits(0)
(monitorId, 1)
}).keyBy(_._1)
.reduce(new ReduceFunction[(String, Int)] {
//t1:上次聚合完的结果 t2:当前的数据
override def reduce(t1: (String, Int), t2: (String, Int)): (String, Int) = {
(t1._1, t1._2 + t2._2)
}
}).map(x=>x._1 + "\t" + x._2)
//设置文件滚动策略
val rolling:DefaultRollingPolicy[String,String] = DefaultRollingPolicy.create()
//当文件超过2s没有写入新数据,则滚动产生一个小文件
.withInactivityInterval(2000)
//文件打开时间超过2s 则滚动产生一个小文件 每隔2s产生一个小文件
.withRolloverInterval(2000)
//当文件大小超过256 则滚动产生一个小文件
.withMaxPartSize(256*1024*1024)
.build()
/**
* 默认:
* 每一个小时对应一个桶(文件夹),每一个thread处理的结果对应桶下面的一个小文件
* 当小文件大小超过128M或者小文件打开时间超过60s,滚动产生第二个小文件
*/
val sink: StreamingFileSink[String] = StreamingFileSink.forRowFormat(
new Path("d:/data/rests"),
new SimpleStringEncoder[String]("UTF-8"))
.withBucketCheckInterval(1000)
.withRollingPolicy(rolling)
.build()
// val sink = StreamingFileSink.forBulkFormat(
// new Path("./data/rest"),
// ParquetAvroWriters.forSpecificRecord(classOf[String])
// ).build()
restStream.addSink(sink)
env.execute()
}
}
HBase Sink
计算结果写入sink 两种实现方式:
- map算子写入,频繁创建hbase连接。
- process写入,适合批量写入hbase。
导入HBase依赖包
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
读取kafka数据,统计卡口流量保存至HBase数据库中
- HBase中创建对应的表
create 'car_flow',{NAME => 'count', VERSIONS => 1}
- 实现代码
import java.util.{Date, Properties}
import com.msb.stream.util.{DateUtils, HBaseUtil}
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.util.Collector
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{HTable, Put}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.kafka.common.serialization.StringSerializer
object HBaseSinkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置连接kafka的配置信息
val props = new Properties()
//注意 sparkstreaming + kafka(0.10之前版本) receiver模式 zookeeper url(元数据)
props.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
props.setProperty("group.id", "flink-kafka-001")
props.setProperty("key.deserializer", classOf[StringSerializer].getName)
props.setProperty("value.deserializer", classOf[StringSerializer].getName)
val stream = env.addSource(new FlinkKafkaConsumer[String]("flink-kafka", new SimpleStringSchema(), props))
stream.map(row => {
val arr = row.split("\t")
(arr(0), 1)
}).keyBy(_._1)
.reduce((v1: (String, Int), v2: (String, Int)) => {
(v1._1, v1._2 + v2._2)
}).process(new ProcessFunction[(String, Int), (String, Int)] {
var htab: HTable = _
override def open(parameters: Configuration): Unit = {
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181")
val hbaseName = "car_flow"
htab = new HTable(conf, hbaseName)
}
override def close(): Unit = {
htab.close()
}
override def processElement(value: (String, Int), ctx: ProcessFunction[(String, Int), (String, Int)]#Context, out: Collector[(String, Int)]): Unit = {
// rowkey:monitorid 时间戳(分钟) value:车流量
val min = DateUtils.getMin(new Date())
val put = new Put(Bytes.toBytes(value._1))
put.addColumn(Bytes.toBytes("count"), Bytes.toBytes(min), Bytes.toBytes(value._2))
htab.put(put)
}
})
env.execute()
}
}
分区策略
在 Apache Flink 中,分区(Partitioning)是将数据流按照一定的规则划分成多个子数据流或分片,以便在不同的并行任务或算子中并行处理数据。分区是实现并行计算和数据流处理的基础机制。Flink 的分区决定了数据在作业中的流动方式,以及在并行任务之间如何分配和处理数据。
在 Flink 中,数据流可以看作是一个有向图,图中的节点代表算子(Operators),边代表数据流(Data Streams)。数据从源算子流向下游算子,这些算子可能并行地处理输入数据,而分区就是决定数据如何从一个算子传递到另一个算子的机制。
shuffle
场景:增大分区、提高并行度,解决数据倾斜
DataStream → DataStream
分区元素随机均匀分发到下游分区,网络开销比较大
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(1)
println(stream.getParallelism)
stream.shuffle.print()
env.execute()
console result:上游数据比较随意的分发到下游
2> 1
1> 4
7> 10
4> 6
6> 3
5> 7
8> 2
1> 5
1> 8
1> 9
rebalance
场景:增大分区、提高并行度,解决数据倾斜
DataStream → DataStream
轮询分区元素,均匀的将元素分发到下游分区,下游每个分区的数据比较均匀,在发生数据倾斜时非常有用,网络开销比较大
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(3)
val stream = env.generateSequence(1,100)
val shuffleStream = stream.rebalance
shuffleStream.print()
env.execute()
console result:上游数据比较均匀的分发到下游
8> 6
3> 1
5> 3
7> 5
1> 7
2> 8
6> 4
4> 2
3> 9
4> 10
rescale
场景:减少分区 防止发生大量的网络传输 不会发生全量的重分区
DataStream → DataStream
通过轮询分区元素,将一个元素集合从上游分区发送给下游分区,发送单位是集合,而不是一个个元素
注意:rescale发生的是本地数据传输,而不需要通过网络传输数据,比如taskmanager的槽数。简单来说,上游的数据只会发送给本TaskManager中的下游。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.rescale.writeAsText("./data/stream2").setParallelism(4)
env.execute()
console result:stream1:1内容分发给stream2:1和stream2:2
stream1:1
1
3
5
7
9
stream1:2
2
4
6
8
10
stream2:1
1
5
9
stream2:2
3
7
stream2:3
2
6
10
stream2:4
4
8
broadcast
场景:需要使用映射表、并且映射表会经常发生变动的场景
DataStream → DataStream
上游中每一个元素内容广播到下游每一个分区中
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.broadcast.writeAsText("./data/stream2").setParallelism(4)
env.execute()
console result:stream1:1、2内容广播到了下游每个分区中
stream1:1
1
3
5
7
9
stream1:2
2
4
6
8
10
stream2:1
1
3
5
7
9
2
4
6
8
10
global
场景:并行度降为1
DataStream → DataStream
上游分区的数据只分发给下游的第一个分区
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.global.writeAsText("./data/stream2").setParallelism(4)
env.execute()
console result:stream1:1、2内容只分发给了stream2:1
stream1:1
1
3
5
7
9
stream1:2
2
4
6
8
10
stream2:1
1
3
5
7
9
2
4
6
8
10
forward
场景:一对一的数据分发,map、flatMap、filter 等都是这种分区策略
DataStream → DataStream
上游分区数据分发到下游对应分区中
partition1->partition1
partition2->partition2
注意:必须保证上下游分区数(并行度)一致,不然会有如下异常:
Forward partitioning does not allow change of parallelism
* Upstream operation: Source: Sequence Source-1 parallelism: 2,
* downstream operation: Sink: Unnamed-4 parallelism: 4
* stream.forward.writeAsText("./data/stream2").setParallelism(4)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.forward.writeAsText("./data/stream2").setParallelism(2)
env.execute()
console result:stream1:1->stream2:1、stream1:2->stream2:2
stream1:1
1
3
5
7
9
stream1:2
2
4
6
8
10
stream2:1
1
3
5
7
9
stream2:2
2
4
6
8
10
keyBy
场景:与业务场景匹配
DataStream → DataStream
根据上游分区元素的Hash值与下游分区数取模计算出,将当前元素分发到下游哪一个分区
MathUtils.murmurHash(keyHash)(每个元素的Hash值) % maxParallelism(下游分区数)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.keyBy(0).writeAsText("./data/stream2").setParallelism(2)
env.execute()
console result:根据元素Hash值分发到下游分区中
PartitionCustom
DataStream → DataStream
通过自定义的分区器,来决定元素是如何从上游分区分发到下游分区
object ShuffleOperator {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
val stream = env.generateSequence(1,10).map((_,1))
stream.writeAsText("./data/stream1")
stream.partitionCustom(new customPartitioner(),0)
.writeAsText("./data/stream2").setParallelism(4)
env.execute()
}
class customPartitioner extends Partitioner[Long]{
override def partition(key: Long, numPartitions: Int): Int = {
key.toInt % numPartitions
}
}
}
本篇文章就到这里,感谢阅读,如果本篇博客有任何错误和建议,欢迎给我留言指正。文章持续更新,可以关注公众号第一时间阅读。
