C++内存分区模型
C++内存分区模型
在执行C++程序的过程中,内存大致分为四个区域:
-
栈区(Stack):用于实现函数调用。由编译器自动分配释放,存放函数的参数值和局部变量等
-
堆区(Heap):用于存放动态分配的变量。由程序员动态分配和释放,使用new和delete操作符
-
全局/静态存储区(Data Segment & BSS Segment):存放全局变量和静态变量,程序结束时释放
数据段 Data Segment (全局/静态存储区) : 存放初始化了的全局变量和静态变量
BSS段 BSS Segment : 用于存放未初始化的全局变量和静态变量,节省空间,实际上不占用磁盘空间
-
代码区(Text Segment):通常也被称为文本区或只读区。存放程序的二进制代码和常量,代码段是只读的,可以被多个进程共享
也有人认为 常量存储区 在内存中是独立的,C++标准并没有明确将常量存储区单独列为内存分区模型的一部分。因此,内存分区模型的确切细节可以根据不同的观点和上下文而有所不同
注意:不同的操作系统对程序内存的管理和划分会有所不同。上述的C++内存区域划分主要是针对通用的情况,并不限定在某个特定操作系统上
1. 代码区
代码区 (Code Segment) 也被称为文本段 (Text Segment) 或者只读区,主要包括可以执行的文件 ELF (Executable and Linkable Format) 和常量
代码区(Code Segment)也被称为文本段(Text Segment)或只读区,它有以下几个主要特征:
- 代码区是程序的静态存储区域,存放程序执行所需的机器指令和常量数据,如字符串字面量和 const 变量的初始化值
- 代码区的内容为只读属性,不允许修改程序中的代码,保障程序的安全性和稳定性
- 程序运行前,代码区的内存大小已在可执行文件中确定,加载时系统会自动分配适当的内存
- 多个进程可以共享相同的代码区,节省内存空间
- 为提高效率,一些字符串字面量 (例如 "Hello") 可能会存放在共享的只读数据区而不是代码区
- 若代码区中的常量初始化需要运行时计算,会将其放在数据区而不是代码区
- 代码区也包含只读数据,如跳转表和常量表等
- 程序运行时,代码区通常不会改变大小,若需扩展,依赖操作系统提供的机制
2. 全局/静态存储区
全局/静态存储区主要包括以下两个部分:
-
数据段(Initialized Data Segment)
-
用于存放初始化了的全局变量和静态变量
-
存储在此段的数据在程序运行前分配,运行结束后释放
-
有初始化值的全局变量和静态变量存放在此
-
数据段属于可读可写区域
-
-
BSS段(Block Started by Symbol)
-
用于存放未初始化的全局变量和静态变量
-
不占用实际的磁盘空间,只在编译时预留内存空间
-
无初始化值的全局变量和静态变量存放在此
-
程序启动时会自动初始化为默认值
-
属于可读写区域
-
两者的主要区别在于初始化状况。全局变量和静态变量可以显式初始化,如果没有显式初始化,它们会被自动初始化为默认值(0 或 nullptr,取决于变量的类型),该区域的数据在程序整个运行周期中一直存在
3. 栈区
栈区是用于实现函数调用和局部变量存储的一种内存区域。在 C++ 中,每当调用一个函数时,系统会自动在栈区为该函数分配一块内存,称为栈帧(Stack Frame)。栈帧用于存储函数的参数值、局部变量以及函数执行期间的一些控制信息 ^f6a053
以下是栈区的一些关键特点:
- LIFO(Last-In-First-Out)原则:栈区采用后进先出的原则,即最后压入栈的数据会最先弹出。这是因为每次调用函数时,会将函数的栈帧压入栈顶,函数执行结束后,栈帧会从栈顶弹出
- 自动分配和释放:栈区的内存分配和释放是由编译器自动管理的,当进入函数时,会为该函数分配一块连续的内存区域,并在函数返回时自动释放这块内存。这样的自动分配和释放使得栈区的内存管理相对高效,但也意味着栈上的数据生命周期必须在函数调用内部
- 局部变量存储:栈区主要用于存储函数的局部变量,这些变量的生命周期与函数的调用和返回相对应。当函数调用结束,栈帧会被销毁,其中的局部变量也会被销毁,因此在函数外部无法访问这些局部变量
- 函数调用:当调用函数时,函数的参数值和返回地址会被压入栈帧中,函数执行过程中的其他局部变量也会存储在栈帧中。函数返回时,栈帧会从栈顶弹出,恢复调用函数的现场
- 栈溢出:栈区的大小是有限的,如果递归调用过深或者函数中使用了大量的局部变量,可能导致栈溢出(Stack Overflow)错误,即栈区的内存已被耗尽
- 线程私有:每个线程都有自己的栈区,栈区的内存是线程私有的,不同线程之间的栈区不共享
3.1 栈溢出
栈溢出(Stack Overflow)是指程序在运行过程中,不断调用函数,导致栈空间被占满,无法再分配新的栈帧。栈是一种先进后出的数据结构,用于存储局部变量、参数、返回地址等信息。栈的大小是有限的,一般为8~10MB。栈溢出通常发生在递归调用过深或死循环的情况下
以下是一个程序在栈区的示例图。在主函数调用自定义的函数,函数内部形成递归

当程序一直运行时,递归的函数会不断占用栈区的内存空间,从而导致 栈溢出

3.2 缓冲区溢出
在C++中,缓冲区溢出通常发生在栈区。栈区用于存储函数调用时的局部变量和函数调用的返回地址
当函数调用时,函数的栈帧(包含局部变量和其他控制信息)被压入栈中。如果函数中使用了缓冲区(数组)并且没有进行足够的边界检查,很容易导致写入超出缓冲区边界的数据,从而覆盖栈上其他变量和控制信息,这就是缓冲区溢出
例如以下代码就是一个缓冲区溢出的案例:
#include <iostream>
int main()
{
//创建并初始化数组
char arr[3] = {'a', 'a', 'a'};
//向数组写入数据,但超出了数组的边界
for (int i = 0; i <= 4; i++)
{
arr[i] = 'b';
}
}
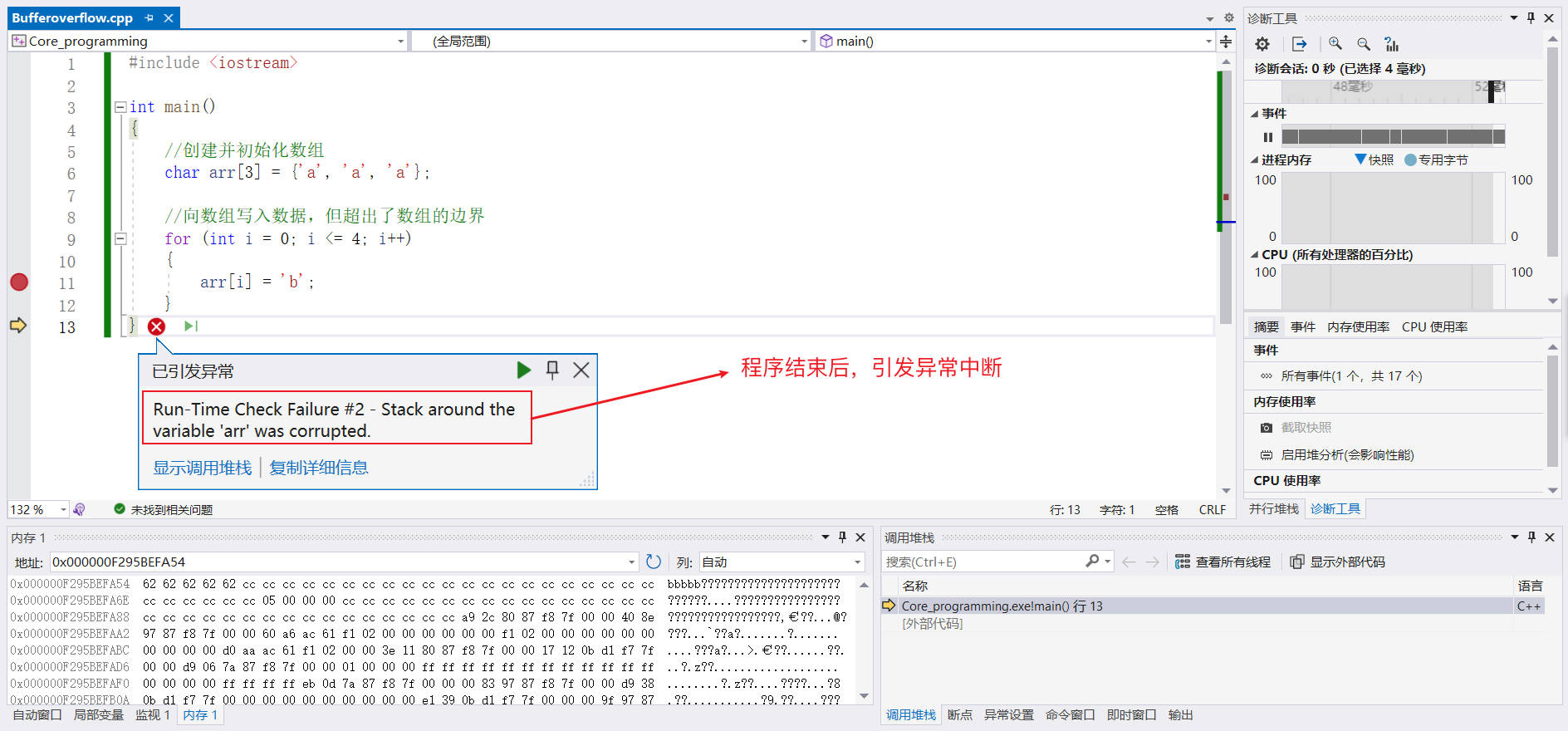
我们在合适的位置添加调试断点,并对数组arr添加监视,观察内存变化

找到数组对应的地址,观察内存中的变化

按下F11逐语句调试,发现数组越界后仍然向未被允许访问的内存中写入数据

显示数组所申请的内存附近堆栈被损坏,这就是缓冲区溢出的危害
3.3 数据不稳定
栈区中的局部变量生命周期与函数的调用和返回相关。当函数返回后,栈帧会被销毁,其中的局部变量也会被销毁。如果在函数内部使用了指向栈区局部变量的指针,并在函数返回后继续使用这些指针,会导致悬空指针(Dangling Pointers)也就是野指针的问题,访问已被销毁的局部变量的内存区域,可能引发未定义的行为
下面是示例代码,证明栈帧销毁后局部变量也被销毁,造成悬挂指针的问题:
#include <iostream>
int* dangPtr;
void test() {
int x = 10;
dangPtr = &x;
std::cout << "dangPtr in test: " << *dangPtr << std::endl;
}
int main() {
test();
std::cout << "dangPtr in main: " << *dangPtr << std::endl;
return 0;
}
在函数test调用完成之后,此时test函数中的所有局部变量已经被销毁了。这时候指针dangPtr指向的变量x的内存地址被系统释放,指针变为悬空指针 (Dangling Pointers) 也就是野指针,这在内存中是非法的,引发程序中断

此时函数还未结束,局部变量x还存在没有被系统销毁
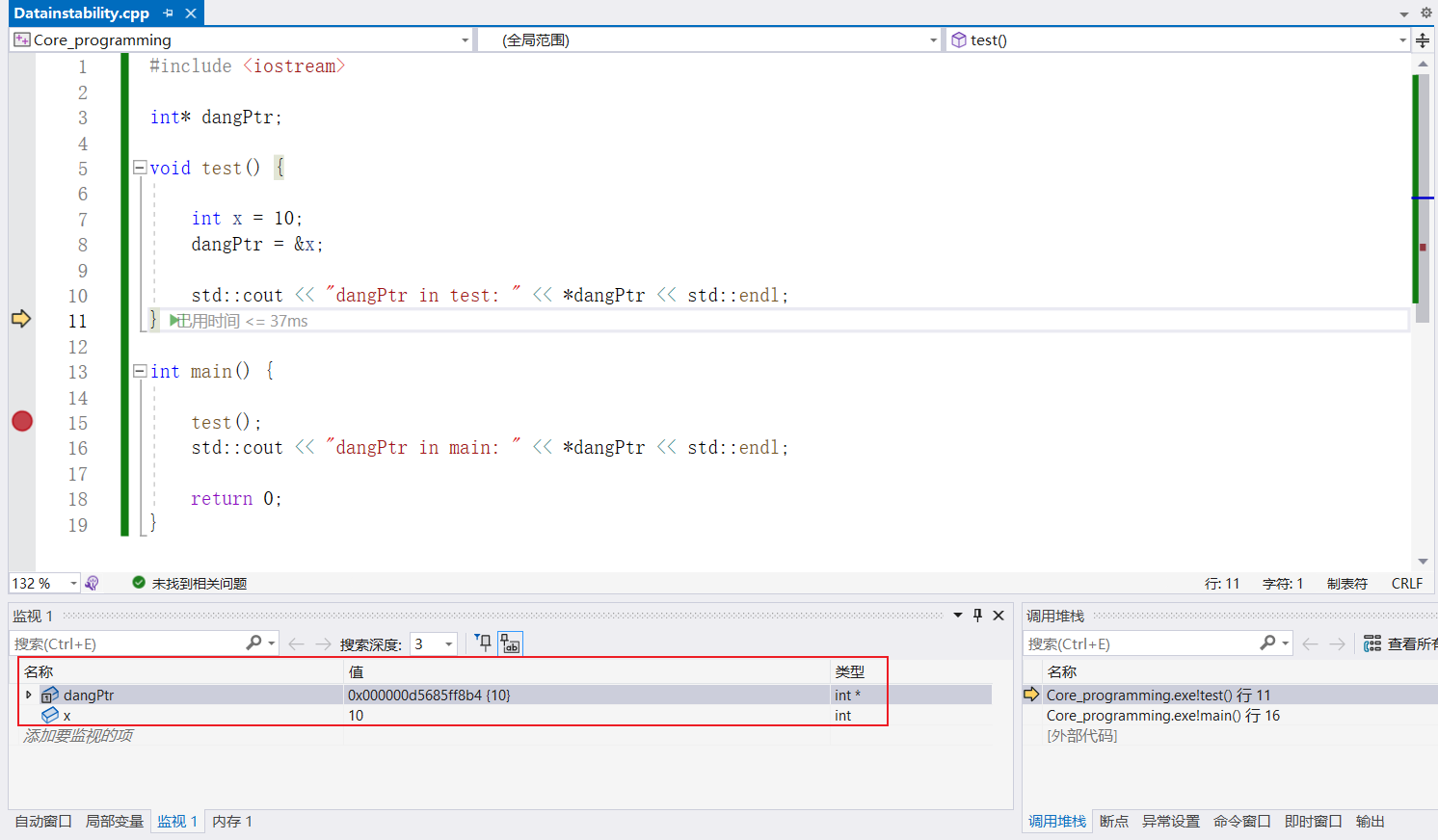
此时test函数执行结束,局部变量被系统销毁,同样的变量x所存的值也被销毁
这时候指针解引用访问地址后的值就变成了野指针,非法访问未申请的内存

3.4 栈帧重用(Stack Frame Reuse)
栈帧重用(Stack Frame Reuse) 是一种编译器优化技术,旨在减少函数调用时的栈内存分配和释放开销。它是通过在不同函数调用中复用栈空间来实现的,使得多个函数调用可以共享同一块栈空间
除了"栈帧重用",这种优化技术也可能被称为其他类似的术语,例如:
- 栈内存优化(Stack Memory Optimization):指代对栈内存的优化措施,其中栈重用是可能的一种优化方式
- 栈空间复用(Stack Space Reuse):强调的是复用栈空间,使得多个函数调用可以共享同一块栈空间
栈帧重用是一种现象,出现在自动变量(由编译器自动分配并回收栈上生命周期仅在函数内的变量)位于函数的栈帧上时。在函数执行过程中,每个函数都会为其局部变量在栈上分配内存空间,并在函数结束时释放这些栈内存。当后续函数再次向栈上请求内存时,有可能会获得先前函数释放的栈内存。如果后续函数中出现了和先前函数相同名称和类型的局部变量,那么这些变量的地址可能会重叠,即它们在同一片栈内存区域中
栈区采用自动管理机制,编译器可能出于效率考虑而选择复用先前函数释放的栈空间。这种自动的栈帧重用特性对于那些只关心变量生命周期而不依赖于其地址的代码来说,并不会产生影响
#include <iostream>
void funcA() {
int a = 10;
std::cout << "Address of variable 'a' in funcA: " << &a << std::endl;
}
void funcB() {
int b = 20;
std::cout << "Address of variable 'b' in funcB: " << &b << std::endl;
}
int main() {
funcA();
funcB();
return 0;
}
输出结果:
Address of variable 'a' in funcA: 0000009F4A6FF884
Address of variable 'b' in funcB: 0000009F4A6FF884

如果确实需要保证变量地址不变,可以采用以下方法:
- 使用
static关键字:在函数内部声明static局部变量,这样变量的生命周期将持续到程序的整个执行过程,而不是只在函数执行时存在 - 将变量置于堆或全局区中:通过使用动态内存分配(例如
new、malloc等)在堆上分配内存,或者将变量声明为全局变量,可以保证其地址在函数调用之间不变
需要注意的是,栈帧重用是编译器的一种优化行为,开发者不需要显式地实现它。了解栈帧重用的概念有助于理解编译器的优化机制,但在实际编程中,重要的是编写简洁、易读和正确的代码,而非过度关注微观优化。优化应该基于实际的性能分析和需求。
4. 堆区
当涉及堆区时,需要理解动态内存分配的概念。堆区是程序运行时用于存储动态分配的数据的一部分内存,它的管理与栈区不同
-
动态内存分配:在堆区进行动态内存分配意味着程序员可以在运行时请求额外的内存空间来存储数据。与栈区不同,栈区的内存是在编译时自动分配和释放的,而堆区的内存是在运行时手动申请并在不再使用时手动释放
-
操作符new和delete:在C++中,使用
new操作符可以在堆区动态地分配内存。new返回所分配内存的指针,该指针指向存储分配的数据的堆区内存。而使用delete操作符可以释放堆区内存并将其返回给操作系统,以便其他程序可以使用。注意,堆区内存的释放是程序员的责任,避免内存泄漏cppCopy codeint* ptr = new int; // 分配一个int大小的堆区内存 *ptr = 10; // 将值10存储在堆区内存中 delete ptr; // 释放堆区内存 -
生命周期:堆区的生命周期由程序员控制。在使用
new分配内存后,内存将一直存在,直到使用delete释放内存或程序结束。如果忘记释放内存,将导致[[^内存泄漏]],堆区的内存将永远无法回收,直到程序结束 -
不稳定性:由于堆区的内存是手动管理的,如果程序员使用指针错误地引用已释放的堆区内存(悬空指针),或者释放后继续访问已释放的内存(野指针),会导致不稳定性和未定义行为
-
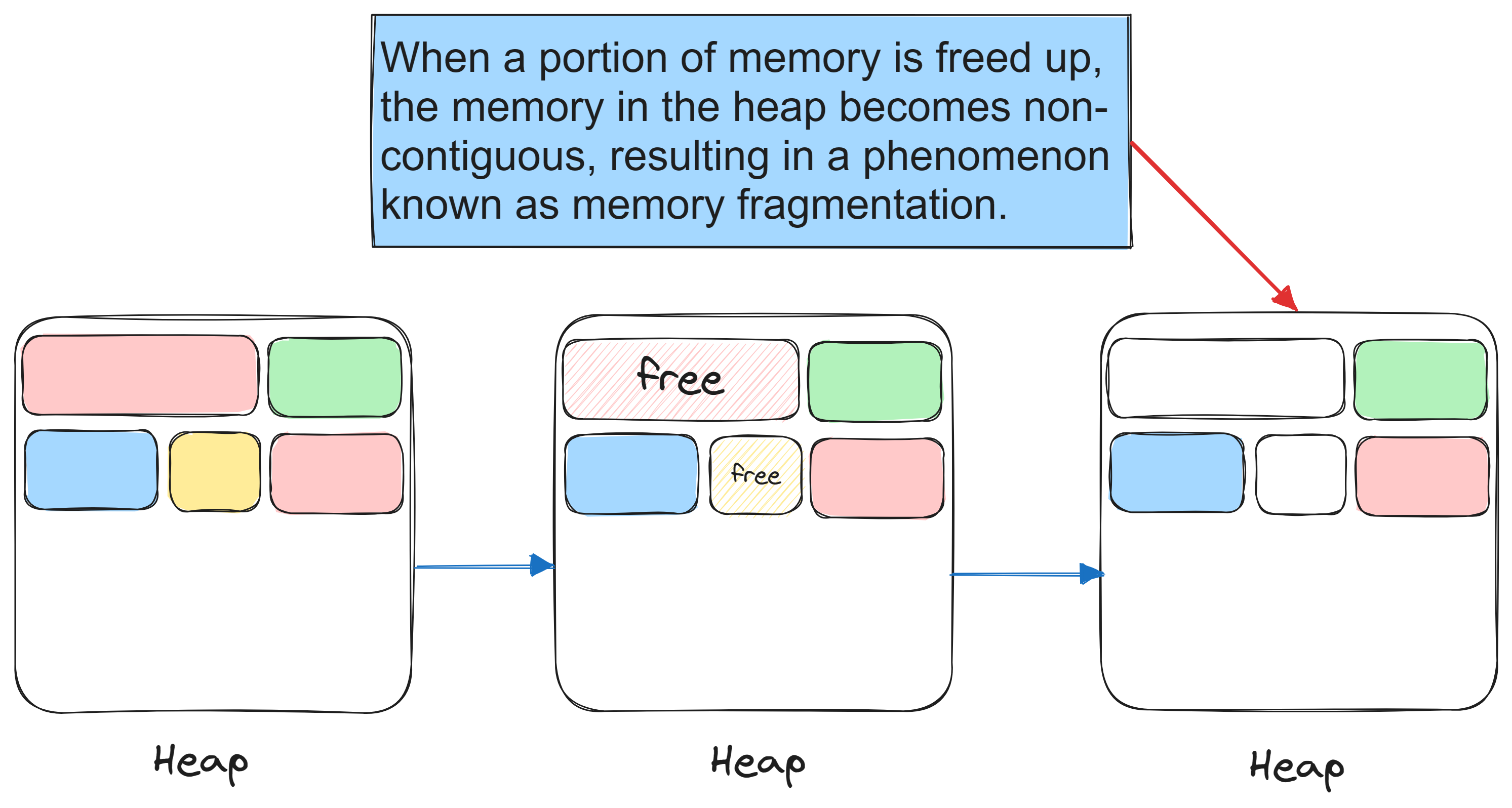
堆区碎片:随着时间的推移,动态内存的频繁分配和释放可能导致堆区出现碎片。堆区碎片是指堆中剩余的不连续、无法利用的小块内存。虽然这不会直接影响程序的正确性,但在某些情况下,可能会降低内存的利用率
-
线程共享:堆区内存可以在线程之间共享,多个线程可以访问和使用堆区的相同内存。这使得堆区在多线程编程中非常有用,但也需要注意同步和避免竞争条件
-
异常安全性:由于堆区内存的手动管理,需要特别注意异常安全性。如果在使用
new分配内存后,出现异常而未能释放内存,可能导致内存泄漏。为了确保异常安全性,可以使用智能指针等资源管理工具来管理动态内存,避免手动释放内存的繁琐工作
4.1 内存溢出
内存溢出(Out of Memory)是指程序在运行过程中,创建了大量的对象或线程,导致堆空间或方法区空间被占满,无法再分配新的内存
堆和方法区是两种动态分配的内存区域,用于存储对象实例、类信息、常量等信息。堆和方法区的大小是可配置的,一般为几百MB到几GB。内存溢出通常发生在对象或线程泄漏、内存分配过大、GC效率低下的情况下
#include <iostream>
int main() {
// 请求分配一个非常大的整数数组(堆区内存)
// 这里如果开辟单个数组没办法报错
// 所以为了模拟更确切的情况,假设就在程序中一次性开辟很大的空间
int* hugeArray0 = new int[999999999];
int* hugeArray1 = new int[999999999];
int* hugeArray2 = new int[999999999];
int* hugeArray3 = new int[999999999];
// 使用堆区内存,可能导致内存溢出
for (int i = 0; i < 999999999; i++) {
hugeArray0[i] = i;
}
// 不要忘记释放堆区内存
delete[] hugeArray0;
system("pause");
return 0;
}
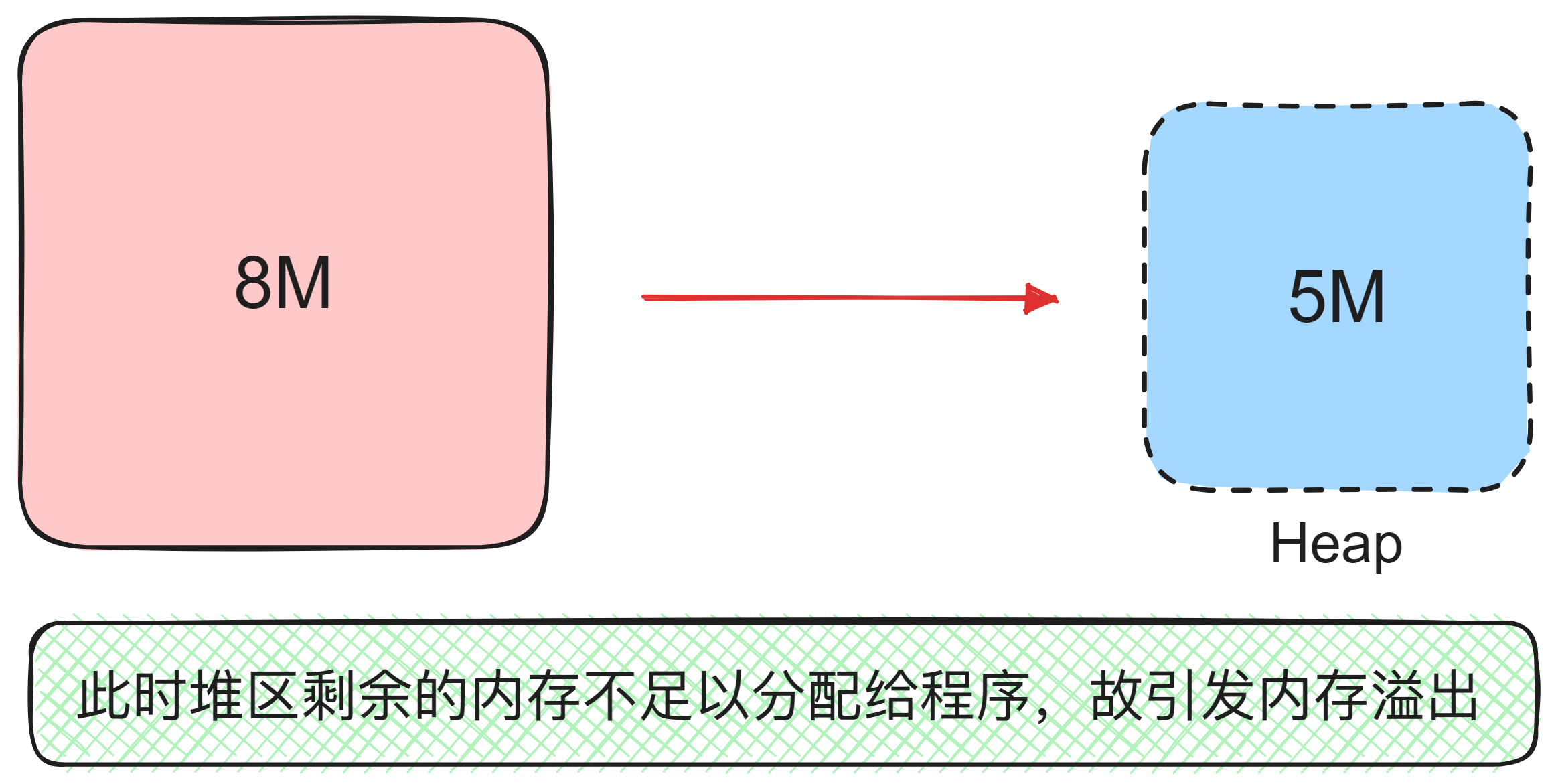

内存分配失败,抛出 std::bad_alloc 异常并终止执行,而且可以看到右侧进程内存已经快达到极限了

4.2 内存泄漏
堆区的内存泄漏是指在程序中动态分配了内存(使用 new 或 malloc 等操作符),但在不再需要这些内存时未及时释放,导致程序无法再访问这些内存,从而造成了资源浪费
内存泄漏是一种常见的编程错误,特别是在长时间运行的程序中,如果频繁地分配内存而不释放,最终可能会耗尽可用内存,导致程序崩溃或系统变慢
#include <iostream>
int main() {
while (true) {
// 在堆区动态分配一个整数数组,但未释放内存
int* ptr = new int[1000];
// 未释放内存,重复分配,导致内存泄漏
}
return 0;
}

4.3 多重释放与非法指针
多重释放:在堆区释放了内存后,如果再次尝试释放相同的内存,就会导致多重释放问题。这会破坏堆的内存管理结构,可能导致程序崩溃
#include <iostream>
int main()
{
int* arr = new int[10];
delete[] arr;
delete[] arr;
system("pause");
return 0;
}


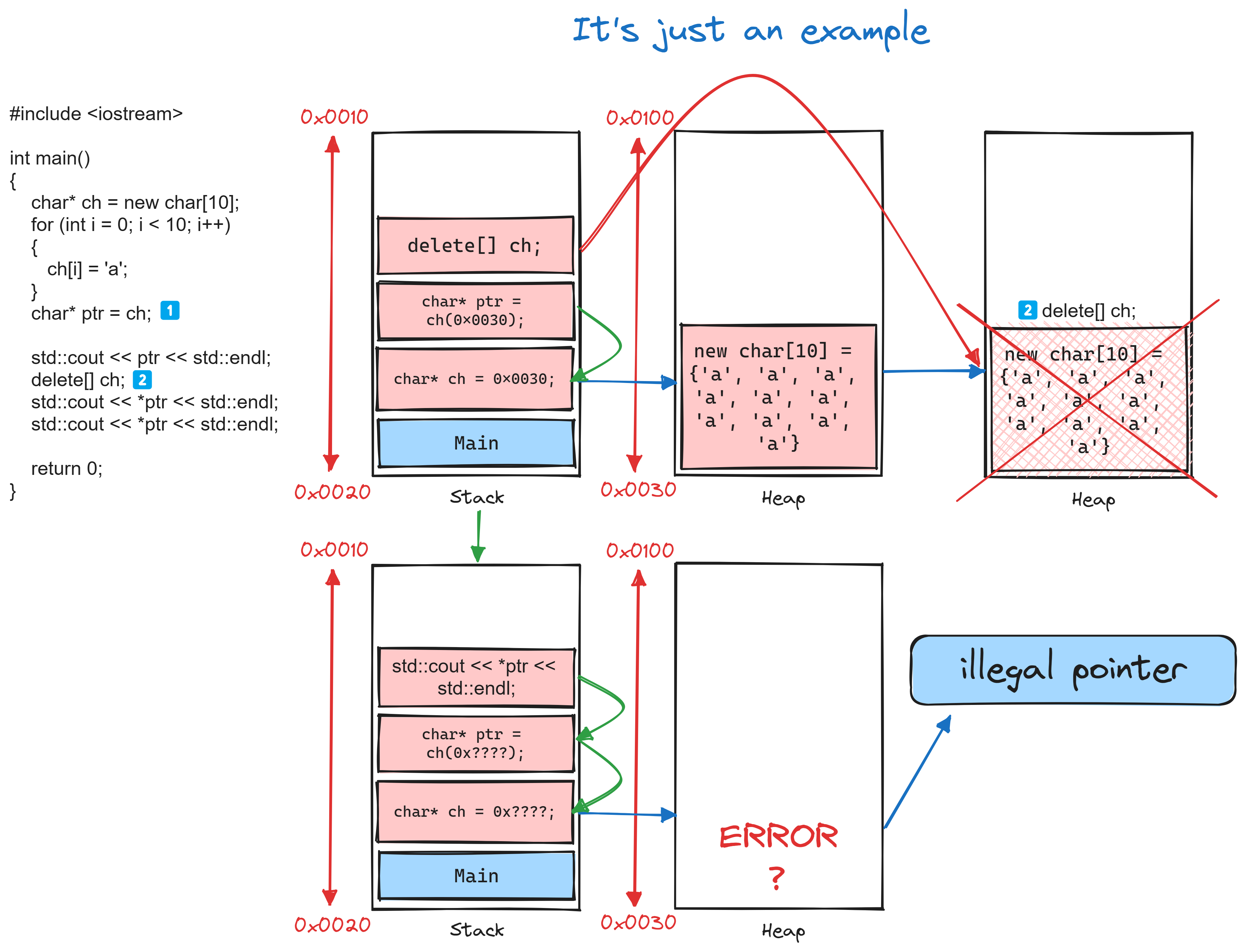
非法指针:在堆区释放了内存后,如果仍然保留指向该内存的指针,就会导致悬空指针。而指向未初始化或已释放的内存的指针称为野指针。使用悬空指针或野指针可能导致程序崩溃或产生不可预测的行为
#include <iostream>
int main()
{
char* ch = new char[10];
for (int i = 0; i < 10; i++)
{
ch[i] = 'a';
}
char* ptr = ch;
std::cout << ptr << std::endl;
delete[] ch;
std::cout << *ptr << std::endl;
std::cout << *ptr << std::endl;
return 0;
}

4.4 产生堆内存碎片
内存块碎片化: 多次动态分配和释放堆区内存可能导致内存块碎片化,使得分配大块连续内存变得困难,从而降低堆区内存的效率
#include <iostream>
int main() {
const int N = 1000;
const int M = 100;
// 创建一个数组用于存储指向动态分配的内存块的指针
int* ptrArray[N];
// 模拟多次动态分配和释放内存
for (int i = 0; i < N; i++) {
// 每次动态分配 M 个 int 大小的内存块
ptrArray[i] = new int[M];
// 将内存块清零,以模拟实际使用场景
for (int j = 0; j < M; j++) {
ptrArray[i][j] = 0;
}
}
// 输出每个内存块的首地址,用于观察地址分布情况
for (int i = 0; i < N; i++) {
std::cout << "Block " << i + 1 << ": " << ptrArray[i] << std::endl;
}
// 释放动态分配的内存
for (int i = 0; i < N; i++) {
delete[] ptrArray[i];
}
return 0;
}
热门相关:倾心之恋:总裁的妻子 富贵不能吟 富贵不能吟 闺范 戏精老公今天作死没