hadoop集群搭建及编程实践
Hadoop集群搭建
- 前期准备及JDK,hadoop安装
- 设置主机名和添加主机映射
- 验证连通性
- SSH无密码登录
- 配置集群/分布式环境
- 分发到其他结点
- 格式化namenode
- 执行分布式实例
- java API与HDFS的编程
1.前期准备及JDK,hadoop安装
1.1JDK的下载地址,hadoop下载地址
选择JDK8
选择hadoop-3.3.5
注意点
查看镜像是32位还是64位
uname -m
当输出为x86_64时,说明是64位,不是的就是32位,此时需要重新下载镜像,32位不方便
1.2创建hadoop用户
在安装完linus镜像之后,需要创建一个专门的"hadoop"用户,这里的用户名为 “prettyspider"
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m prettyspider -s /bin/bash
-m:将prettyspider作为用户放入到用户登录目录
-s:指定用户登入后使用的shell
为用户设置登录密码
sudo passwd prettyspider
为用户添加管理员权限
sudo adduser prettyspider sudo
之后登出,登录"hadoop"用户
1.3更新apt
sudo apt-get update
同步时间
sudo apt-get install ntpdata
ntpdata -u time2.aliyun.com # 同步为阿里云NTP服务器
下载vim
sudo apt-get install vim
1.4安装SSH、配置SSH无密码登陆
sudo apt-get install openssh-server
安装完之后,登录本机
ssh localhost
在下方提示中输入yes,再根据提示输入“hadoop"用户的密码
设置免密登录之前,一定要先用密码登录一下
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
再使用ssh localhost登录
1.5配置远程登录
远程登录实现种类比较多,最轻便的是用vscode进行远程登录,这里使用的是MobaXterm软件
可到官网中下载MobaXterm Xserver with SSH, telnet, RDP, VNC and X11 - Download (mobatek.net)
1.6JDK安装
JDK版本为1.8.0_371
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
sudo tar -zxvf ~/jdk-8u371-linux-x64.tar.gz -C /usr/lib/jvm #将
设置环境变量
cd ~
vim ~/.bashrc
在其中添加
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371 # 对应的版本号为jdk1.8.0_对应下载版本8u后面的数字
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
是配置文件生效
source ~/.bashrc
查看是否安装成功
java -version
当出现下图,表明安装成功

1.7安装hadoop
sudo tar -zxvf ~/hadoop-3.3.5.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.3.5/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R prettyspider ./hadoop # 修改文件权限,prettyspider为你的”hadoop"用户名
查看hadoop是否可用
cd /usr/local/hadoop
./bin/hadoop version
出现下图,表示可用

依次配置3台主机,对应的hadoop用户名都为prettyspider
2.设置主机名和添加主机映射
2.1修改主机名
sudo vim /etc/hostname
3台主机分别设置为 node01 node02 node03
重启后,对应的主机名便会更改,如

2.2添加主机映射
在node01结点上
sudo vim /etc/hosts
添加主机的映射,设置成下图

相应的其他结点也需要设置成上图一样
3.验证连通性
用ping指令验证连通性
ping node02 -c 3
连通成功的结果

4.SSH无密码登录
在最开始配置的SSH是只针对当前主机而言的SSH密匙,但是不利用集群的操作,所以需要统一的配置SSH密匙
4.1在主节点上删除原有SSH,并再创建一个统一的SSH密匙
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
rm ./id_rsa* # 删除之前生成的公匙(如果已经存在)
ssh-keygen -t rsa # 执行该命令后,遇到提示信息,一直按回车就可以
将生成的密匙添加到用户的~/.ssh/authorized_keys,用于身份验证
cat ./id_rsa.pub >> ./authorized_keys
将密匙传入到对应的从结点上 传输到node02,node03
scp ~/.ssh/id_rsa.pub prettyspider@node02:/home/prettyspider/ # 此处@前后的名称为自定义的用户名和主机名 ,/home/后的为自定义的用户名
在对应的结点上实现
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在,则忽略本命令
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完以后就可以删掉
4.3查看是否成功
ssh nod02
如下,表示成功
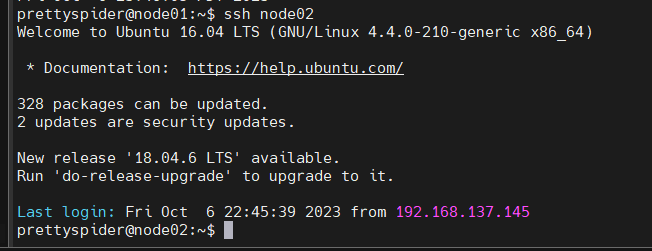
4.4为hadoop添加PATH
在~/.bashrc中添加
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin # 指向对应hadoop路径下的hadoop启动文件夹的目录
5.配置集群/分布式环境
5.1进入/usr/local/hadoop/etc/hadoop
/usr/local/hadoop/etc/hadoop
5.2修改workers
workers的作用:配置为DateNode的主机名,如下,删除localhost

5.3修改文件core-site.xml
指定namenode的位置和设置hadoop文件系统的基本配置
5.4修改hdfs-site.xml
配置namenode和datanode存放文件的基本路径及配置副本的数量,最小值为3

5.5修改mapred-site.xml
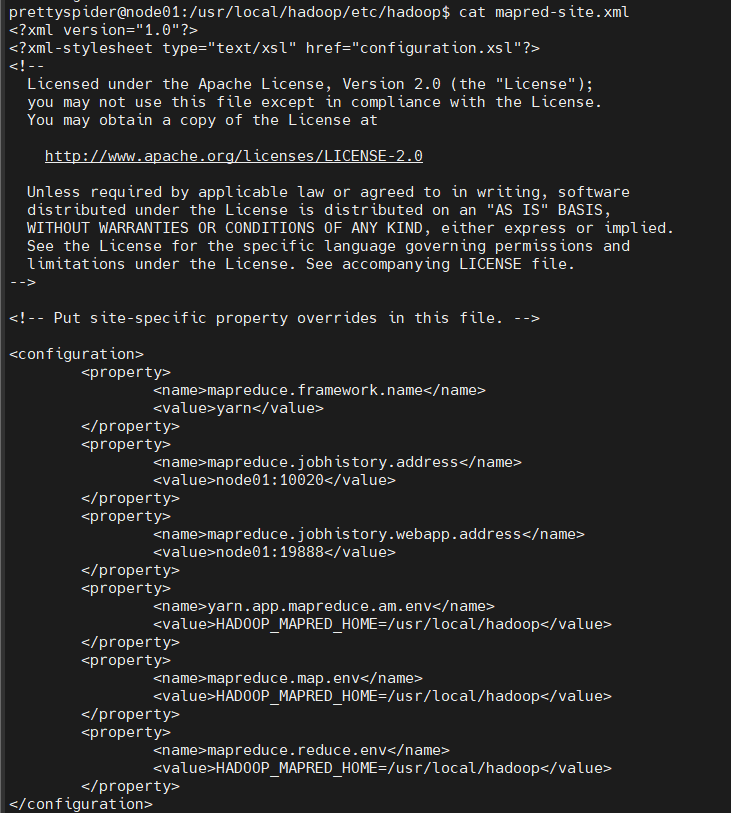
5.6修改yarn-site.xml
设置resourceManager运行在哪台机器上,设置NodeManager的通信方式

6.分发到其他结点
6.1分发其他结点
cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz node02:/home/prettyspider
其中
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
很重要,在后期配置hbase集群时有用
6.2从节点解压并设置用户组
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R prettyspider /usr/local/hadoop
7.格式化namenode
在从结点上完成了部署hadoop,在主节点上执行名称结点的格式化
hdfs namenode -format
自此,hadoop集群搭建完成,启动集群
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver

hadoop集群的规划为

8.执行分布式实例
8.1创建HDFS上的用户目录
hdfs dfs -mkdir -p /user/prettyspider
hadoop用户名是什么,user后的用户就是什么
8.2创建input目录
hdfs dfs -mkdir input # input文件夹默认在用户目录下,也就是prettyspider目录下
hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input
8.3运行MapReduce作业
这个测试是用正则表达式获取指定前缀的任意长的字段
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar grep input output 'dfs[a-z.]+'
结果为

9.java API与HDFS的编程
1.导入Maven依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.上传本地文件到HDFS文件系统,将HDFS文件系统中的文件下载到本地并压缩
1.创建ConnectionJavaBean类,用于登录HDFS
package com.prettyspider.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author prettyspider
* @ClassName Connection
* @description: TODO
* @date 2023/10/7 19:00
* @Version V1.0
*/
public class Connection {
// HDFS文件系统web地址
private String hdfsUrl;
// hadoop用户名
private String hadoopHost;
// 文件系统对象
private FileSystem fs;
public Connection() {}
public Connection(String hdfsUrl, String hadoopHost) {
this.hdfsUrl = hdfsUrl;
this.hadoopHost = hadoopHost;
}
public Connection(String hdfsUrl, String hadoopHost, FileSystem fs) {
this.hdfsUrl = hdfsUrl;
this.hadoopHost = hadoopHost;
this.fs = fs;
}
public String getHadoopHost() {
return hadoopHost;
}
/**
* 将web地址和hadoop用户名传入,生成文件系统对象
* @return HDFS文件系统对象
* @throws Exception
*/
public FileSystem init() {
Configuration configuration = new Configuration();
try {
fs = FileSystem.newInstance(new URI(hdfsUrl), configuration, hadoopHost);
} catch (IOException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (URISyntaxException e) {
throw new RuntimeException(e);
}
return fs;
}
public void fsClose() {
try {
fs.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 获取
* @return hdfsUrl
*/
public String getHdfsUrl() {
return hdfsUrl;
}
/**
* 设置
* @param hdfsUrl
*/
public void setHdfsUrl(String hdfsUrl) {
this.hdfsUrl = hdfsUrl;
}
/**
* 设置
* @param hadoopHost
*/
public void setHadoopHost(String hadoopHost) {
this.hadoopHost = hadoopHost;
}
/**
* 获取
* @return fs
*/
public FileSystem getFs() {
return fs;
}
/**
* 设置
* @param fs
*/
public void setFs(FileSystem fs) {
this.fs = fs;
}
public String toString() {
return "Connection{hdfsUrl = " + hdfsUrl + ", hadoopHost = " + hadoopHost + ", fs = " + fs + "}";
}
}
2.创建文件转化工具类FileTransferUtil,实现对文件夹的上传和下载
package com.prettyspider.hadoop.updateanddownload;
import org.apache.hadoop.fs.*;
import java.io.*;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
/**
* @author prettyspider
* @ClassName update
* @description: TODO
* @date 2023/10/7 19:23
* @Version V1.0
*/
public class FileTransferUtil {
private FileTransferUtil() {
}
/**
* 将本地指定路径下的文件上传到HDFS文件系统上
*
* @param localPath 本地文件路径
* @param hdfsPath HDFS文件系统路径
* @param fs HDFS文件系统对象
*/
public static void update(String localPath, String hdfsPath, FileSystem fs) {
/**
* 细节:
* 两次getName()的意义不同,第一次是获取文件夹或者文件的名称,第二次是获取文件的名称,不能共用
*/
String name1 = new File(localPath).getName();
hdfsPath = hdfsPath + "/" + name1;
// 获取本地文件的文件集合
File[] files = new File(localPath).listFiles();
if (files != null) {
for (File file : files) {
// 当为文件是便上传
if (file.isFile()) {
String absolutePath = file.getAbsolutePath();
String name = file.getName();
try {
System.out.println(hdfsPath + "/" + name);
fs.copyFromLocalFile(new Path("file:///" + absolutePath), new Path(hdfsPath + "/" + name));
} catch (IOException e) {
throw new RuntimeException(e);
}
} else {
update(file.toString(), hdfsPath, fs);
}
}
}
}
/**
*
* @param localPath 本地文件路径
* @param hdfsPath HDFS文件系统路径
* @param fs HDFS文件系统对象
* @param username 用户名
* @throws IOException
*/
public static void download(String localPath, String hdfsPath, FileSystem fs,String username) throws IOException {
RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = locatedFileStatusRemoteIterator = fs.listFiles(new Path(hdfsPath), true);
while (locatedFileStatusRemoteIterator.hasNext()) {
LocatedFileStatus next = locatedFileStatusRemoteIterator.next();
// 用用户名做切分点,获取从用户名开始的文件路径
String name = next.getPath().toString().split(username)[1];
/**
* 细节:
* 将获取的用户名进行切分,再组合
*/
String[] arr = name.split("/");
String fileName = "";
for (int i = 0; i < arr.length - 1; i++) {
fileName += arr[i] + "/";
}
// 获取HDFS文件系统的路径
Path path = next.getPath();
FSDataInputStream getMessage = fs.open(path);
BufferedReader reader = new BufferedReader(new InputStreamReader(getMessage));
/**
* 细节:
* 输出时需要先创建文件目录
*/
File file = new File(localPath, fileName);
if (!file.exists()) {
file.mkdirs();
}
BufferedWriter writer = new BufferedWriter(new FileWriter(new File(file, arr[arr.length - 1])));
String line;
while ((line = reader.readLine()) != null) {
writer.write(line);
writer.newLine();
}
writer.close();
reader.close();
}
// 压缩
ZipOutputStream zipOutputStream = new ZipOutputStream(new FileOutputStream(new File(localPath, hdfsPath + ".zip")));
toZIp(new File(localPath,hdfsPath), zipOutputStream, hdfsPath);
}
/**
*
* @param src 文件夹对象
* @param zipOutputStream 压缩流
* @param path 指定文件夹下的根目录
* @throws IOException
*/
private static void toZIp(File src, ZipOutputStream zipOutputStream, String path) throws IOException {
File[] files = src.listFiles();
if (files != null) {
for (File file : files) {
if (file.isFile()) {
ZipEntry zipEntry = new ZipEntry(path + "\\" + file.getName());
zipOutputStream.putNextEntry(zipEntry);
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(file));
byte[] bytes = new byte[1024 * 1024 * 8];
int len;
while ((len = bufferedInputStream.read(bytes))!=-1) {
zipOutputStream.write(bytes, 0, len);
}
bufferedInputStream.close();
} else {
toZIp(file, zipOutputStream, path + "\\" + file.getName());
}
}
zipOutputStream.close();
}
}
}
测试类
FileTransferTest
import org.apache.hadoop.fs.FileSystem;
import org.junit.Test;
import java.io.IOException;
/**
* @author prettyspider
* @ClassName fileTransferTest
* @description: TODO
* @date 2023/10/7 19:47
* @Version V1.0
*/
public class fileTransferTest {
@Test
public void testUpdate() throws IOException {
Connection connection = new Connection("hdfs://node01:9000", "prettyspider");
FileSystem fs = connection.init();
FileTransferUtil.update("E:\\test\\wordcount","input",new ConnectionTest().testInit());
// fileTransfer.download("E:\\test","input",fs,connection.getHadoopHost());
connection.fsClose();
}
}
结果
本地

HDFS文件系统Web端

3.根据HDFS文件系统查看学生是否提交作业
假设用HDFS文件系统管理学生作业,如何获取学生是否提交作业
实现:
1.根据HDFS文件系统获取指定”班级"下的所有的已经提交作业的学生
2.与班级的学生名单进行比较,获取没有提交作业的学生
创建JobSunmissionUtil工具类,实现获取没有提交做的学生
package com.prettyspider.hadoop.jobsubmission;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.*;
import java.util.ArrayList;
/**
* @author prettyspider
* @ClassName Search
* @description: TODO
* @date 2023/10/8 11:23
* @Version V1.0
*/
public class JobSubmissionUtil {
private JobSubmissionUtil(){}
public static void search(FileSystem fs) throws Exception {
File file = new File(".\\src\\main\\java\\com\\prettyspider\\hadoop\\jobsubmission\\stu.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(file)));
String line;
ArrayList<String> list = new ArrayList<>();
ArrayList<String> nameList = new ArrayList<>();
while ((line = reader.readLine()) != null) {
list.add(line.split("-")[0]);
}
System.out.println(list);
FileStatus[] fileStatuses = fs.listStatus(new Path("input/stu"));
for (FileStatus fileStatus : fileStatuses) {
String[] arr = fileStatus.getPath().toString().split("/");
String s = arr[arr.length - 1].split("\\.")[0];
nameList.add(s);
}
System.out.println(nameList);
// 去重
for (String name : nameList) {
list.remove(name);
}
System.out.println("没有交作业的是"+list);
}
}
测试类
JobsubmissionTest
package com.prettyspider.hadoop.updateanddownload;
import com.prettyspider.hadoop.Connection;
import com.prettyspider.hadoop.jobsubmission.JobSubmissionUtil;
import org.apache.hadoop.fs.FileSystem;
import org.junit.Test;
/**
* @author prettyspider
* @ClassName SearchTest
* @description: TODO
* @date 2023/10/8 11:30
* @Version V1.0
*/
public class JobSubmissionTest {
@Test
public void testsearch() throws Exception {
Connection connection = new Connection("hdfs://node01:9000", "prettyspider");
FileSystem fs = connection.init();
JobSubmissionUtil.search(fs);
connection.fsClose();
}
}
4.实现HDFS文件系统指定文件夹内的文件词频统计(手搓)
MapReduce是hadoop两个核心之一,MapReduce框架由Map和Reduce组成。 Map ()负责把一个大的block块进行切片并计算。 Reduce () 负责把Map ()切片的数据进行汇总、计算。
那么可以通过简化,实现切片和数据统计
实现步骤:
1.将HDFS文件系统指定文件夹下的文件合并到一个文件中
2.对文件进行切分
3.将切分之后的数据利用Map集合实现统计
创建WordCountUtil工具类
package com.prettyspider.hadoop.wordcount;
import org.apache.hadoop.fs.*;
import java.io.*;
import java.util.*;
/**
* @author prettyspider
* @ClassName wordcount
* @description: TODO
* @date 2023/10/8 12:46
* @Version V1.0
*/
public class WordCountUtil {
private WordCountUtil() {}
/**
* 将指定文件夹下的文件合并到一个文件中,再对文件进行词频统计
* @param fs HDFS文件系统对象
* @param hdfsPath 要统计词频的文件夹地址
* @param mergePath 合并后的文件地址
* @throws IOException
*/
public static void wordcount(FileSystem fs,String hdfsPath,String mergePath) throws IOException {
merge(fs, hdfsPath, mergePath);
wordcount(fs, mergePath);
}
/**
* 利用Map对数据进行统计
* @param fs HDFS文件系统
* @param mergePath 合并的文件地址
* @throws IOException
*/
private static void wordcount(FileSystem fs, String mergePath) throws IOException {
FSDataInputStream open = fs.open(new Path(mergePath));
// 用集合获取数据
ArrayList<String> list = new ArrayList<>();
BufferedReader reader = new BufferedReader(new InputStreamReader(open));
String line;
while ((line = reader.readLine()) != null) {
list.add(line);
}
StringBuilder stringBuilder = new StringBuilder();
for (String s : list) {
stringBuilder.append(s);
}
String[] arr = stringBuilder.toString().split("\\W+");
// 词频统计
wordstatistic(arr);
}
/**
*
* @param arr 被拆分后的词的数组
*/
private static void wordstatistic(String[] arr) {
HashMap<String, Integer> map = new HashMap<>();
for (int i = 0; i < arr.length; i++) {
String s = arr[i];
// map中不存在数据
if (!map.containsKey(s)) {
map.put(s, 1);
} else {
int count = map.get(s) + 1;
map.put(s,count);
}
}
// 输出结果
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("key="+key+",value="+value);
}
}
/**
*
* @param fs HDFS文件系统对象
* @param hdfsPath 要统计的文件夹地址
* @param mergePath 合并后文件地址
* @throws IOException
*/
private static void merge(FileSystem fs, String hdfsPath, String mergePath) throws IOException {
FSDataOutputStream fsDataOutputStream = fs.create(new Path(mergePath));
FileStatus[] fileStatuses = fs.listStatus(new Path(hdfsPath));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(fsDataOutputStream));
for (FileStatus fileStatus : fileStatuses) {
FSDataInputStream open = fs.open(new Path(fileStatus.getPath().toUri()));
BufferedReader reader = new BufferedReader(new InputStreamReader(open));
String line;
while ((line = reader.readLine()) != null) {
writer.write(line);
writer.newLine();
}
reader.close();
open.close();
}
writer.close();
fsDataOutputStream.close();
}
}
测试类
WordCountTest
package com.prettyspider.hadoop.updateanddownload;
import com.prettyspider.hadoop.Connection;
import com.prettyspider.hadoop.wordcount.WordCountUtil;
import org.apache.hadoop.fs.FileSystem;
import org.junit.Test;
import java.io.IOException;
/**
* @author prettyspider
* @ClassName WordCountTest
* @description: TODO
* @date 2023/10/8 13:15
* @Version V1.0
*/
public class WordCountTest {
@Test
public void testwordcount() throws IOException {
Connection connection = new Connection("hdfs://node01:9000", "prettyspider");
FileSystem fs = connection.init();
WordCountUtil.wordcount(fs,"input/wordcount","output/merge.txt");
connection.fsClose();
}
}
结果
