【scipy 基础】--聚类
物以类聚,聚类算法使用最优化的算法来计算数据点之间的距离,并将它们分组到最近的簇中。
Scipy的聚类模块中,进一步分为两个聚类子模块:
vq(vector quantization):提供了一种基于向量量化的聚类算法。
vq模块支持多种向量量化算法,包括K-means、GMM(高斯混合模型)和WAVG(均匀分布)。
hierarchy:提供了一种基于层次聚类的聚类算法。
hierarchy模块支持多种层次聚类算法,包括ward、elbow和centroid。
总之,Scipy中的vq和hierarchy模块都提供了一种基于最小化平方误差的聚类算法,
它们可以帮助我们快速地对大型数据集进行分组,从而更好地理解数据的分布和模式。
1. vq 聚类
vq 聚类算法的原理是将数据点映射到一组称为“超空间”的低维向量空间中,然后将它们分组到最近的簇中。
首先,我们创建一些测试数据:(创建3个类别的测试数据)
import numpy as np
import matplotlib.pyplot as plt
data1 = np.random.randint(0, 30, (100, 3))
data2 = np.random.randint(30, 60, (100, 3))
data3 = np.random.randint(60, 100, (100, 3))
data = np.concatenate([data1, data2, data3])
fig, ax = plt.subplots(subplot_kw={"projection": "3d"})
ax.scatter(data[:, 0], data[:, 1], data[:, 2])
plt.show()

data1,data2,data3分布在3个区域,
每个数据集有100条数据,每条数据有3个属性。
1.1. 白化数据
聚类之前,一般会对数据进行白化,所谓白化数据,是指将数据集中的每个特征或每个样本的值都统一为同一个范围。
这样做的目的是为了消除特征之间的量纲和数值大小差异,使得不同特征具有相似的重要性,从而更容易进行聚类算法。
在聚类之前对数据进行白化处理也被称为预处理阶段。
from scipy.cluster.vq import whiten
# 白化数据
normal_data = whiten(data)
# 绘制白化后的数据
fig, ax = plt.subplots(subplot_kw={"projection": "3d"})
ax.scatter(normal_data[:, 0], normal_data[:, 1], normal_data[:, 2])
plt.show()

从图中可以看出,数据的分布情况没有改变,只是数据的范围从0~100变成0.0~3.5。
这就是白化的效果。
1.2. K-means
白化之后,就可以用K-meas方法来进行聚类运算了。scipy的vq模块中有2个聚类函数:kmeans和kmeans2。
kmeans函数最少只要传入两个参数即可:
- 需要聚类的数据,也就是上一步白化的数据
- 聚类的数目
返回值有2部分:
- 各个聚类的中心点
- 各个点距离聚类中心点的欧式距离的平均值
from scipy.cluster.vq import kmeans
center_points, distortion = kmeans(normal_data, 3)
print(center_points)
print(distortion)
# 运行结果
[[1.632802 1.56429847 1.51635413]
[0.48357948 0.55988559 0.48842058]
[2.81305235 2.84443275 2.78072325]]
0.5675874109728244
把三个聚类点绘制在图中来看更加清楚:
fig, ax = plt.subplots(subplot_kw={"projection": "3d"})
ax.scatter(normal_data[:, 0],
normal_data[:, 1],
normal_data[:, 2])
ax.scatter(
center_points[:, 0],
center_points[:, 1],
center_points[:, 2],
color="r",
marker="^",
linewidths=5,
)
plt.show()

图中3个红色的点就是聚类的中心点。
1.3. K-means2
kmeans2函数使用起来和kmeans类似,但是返回值有区别,kmeans2的返回的是:
- 聚类的中心点坐标
- 每个聚类中所有点的索引
from scipy.cluster.vq import kmeans2
center_points, labels = kmeans2(normal_data, 3)
print(center_points)
print(labels)
# 运行结果
[[2.81305235 2.84443275 2.78072325]
[1.632802 1.56429847 1.51635413]
[0.48357948 0.55988559 0.48842058]]
[2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
... ...
0 0 0 0]
可以看出,计算出的聚类中心点center_points和kmeans一样(只是顺序不一样),labels有0,1,2三种值,代表normal_data中每个点属于哪个分类。
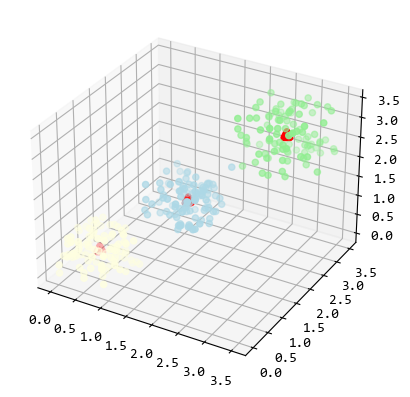
kmeans2除了返回了聚类中心点,还有每个数据点属于哪个聚类的信息,
所以我们绘图时,可以将属于不同聚类的点标记不同的颜色。
fig, ax = plt.subplots(subplot_kw={"projection": "3d"})
arr_data = [[], [], []]
for idx, nd in enumerate(normal_data):
arr_data[labels[idx]].append(nd)
data = np.array(arr_data[0])
ax.scatter(data[:, 0], data[:, 1], data[:, 2], color='lightblue')
data = np.array(arr_data[1])
ax.scatter(data[:, 0], data[:, 1], data[:, 2], color='lightgreen')
data = np.array(arr_data[2])
ax.scatter(data[:, 0], data[:, 1], data[:, 2], color='lightyellow')
ax.scatter(
center_points[:, 0],
center_points[:, 1],
center_points[:, 2],
color="r",
marker="^",
linewidths=5,
)
plt.show()
2. hierarchy 聚类
hierarchy聚类算法的步骤比较简单:
- 将每个样本视为一个簇
- 计算各个簇之间的距离,将距离最近的两个簇合并为一个簇
- 重复第二个步骤,直至到最后一个簇
from scipy.cluster.hierarchy import ward, fcluster, dendrogram
from scipy.spatial.distance import pdist
# 计算样本数据之间的距离
# normal_data是之前白化之后的数据
dist = pdist(normal_data)
# 在距离上创建Ward连接矩阵
Z = ward(dist)
# 层次聚类之后的平面聚类
S = fcluster(Z, t=0.9, criterion='distance')
print(S)
# 运行结果
[20 26 23 18 18 22 18 28 21 22 28 26 27 27 20 17 23 20 26 23 17 25 20 22
... ...
5 13 3 4 2 9 9 13 13 8 11 6]
返回的S中有300个数据,和normal_data中的数据一样多,S中数值接近的点,分类越接近。
从数值看聚类结果不那么明显,scipy的层次聚类提供了一个dendrogram方法,内置了matpltlib的功能,
可以把层次聚类的结果用图形展示出来。
P = dendrogram(Z, no_labels=True)
plt.show()
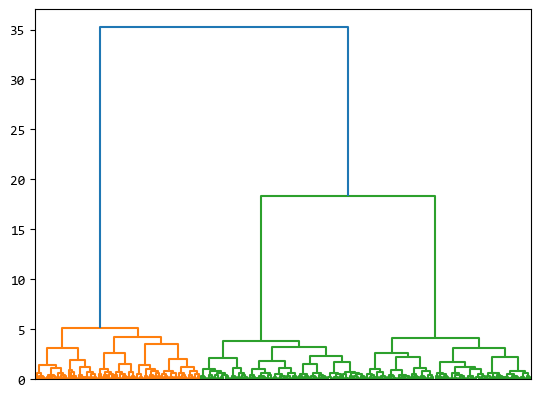
从这个图可以看出每个数据分别属于哪个层次的聚类。
最底层的叶子节点就是normal_datad中的各个数据,这些数据的索引信息可以从 P 中获取。
# P是一个字典,包含聚类之后的信息
# key=ivl 是图中最底层叶子节点在 normal_data 中的索引
print(P["ivl"])
# 运行结果
['236', '269', '244', ... ... '181', '175', '156', '157']
3. 总结
聚类分析可以帮助我们发现数据集中的内在结构、模式和相似性,从而更好地理解数据。
使用Scipy库,可以帮助我们高效的完成数据的聚类分析,而不用去具体了解聚类分析算法的实现方式。