go数据类型-map
go的map在面试时候经常会被问到。
最近看到群里有个被问到为什么map的每个桶中只装8个元素?
map 的结构

注:解决hash冲突还有一些别的方案:开放地址法 (往目标地址后面放)、再哈希法(再次hash)
底层定义
// A header for a Go map.
type hmap struct {
// 个数 size of map,当使用len方法,返回就是这个值
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
// 桶的以2为底的对数,后面在查找和扩容都用到这个值
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
// 溢出桶的数量 这里讲了 approximate 不是精准的
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
// 哈希的种子,在进行哈希运算算法是要用到
hash0 uint32 // hash seed
// 桶的数组,是 2^B个数,和B的定义对上了
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
// 扩容时用于保存之前 buckets 的字段
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
// 指示扩容进度,小于此地址的 buckets 迁移完成
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
跟进看 buckets的结构:
bucketCnt = abi.MapBucketCount =8
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// Followed by an overflow pointer.
}
每个桶 定义了 有8个哈希值的容量。 这里就解释了为什么一个桶只能放八个元素。
至于元素的存储,在这里没有定义,主要是不能写死类型。
但是在编译期间,会把要存储的key 和value写进来;
最后还跟了一个 溢出指针。
整体的结构是这样:

bmap的数量根据B确定,如果B为2,那么bmap为4个,图中B为3。
每个bmap容量为8,超过8个就要用到溢出桶。 意味着每个桶最多只能存储8个元素。
map的创建
func main() {
m := make(map[string]string, 10)
fmt.Println(m)
}
看下是如何创建的:
通过看下汇编,发现最终调用了runtime.makemap()方法
go build -gcflags -S main.go
MOVL $10, BX
XORL CX, CX
PCDATA $1, $0
NOP
CALL runtime.makemap(SB)
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// initialize Hmap 初始化 hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// 对B进行赋值
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
// 这里创建一个bucket的数组,而且也创建了一些溢出桶,用extra 存储。
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
这里可以返回去看下 bmap 的最后一个参数:
extra *mapextra // optional fields
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
通过上面能看到,给 h.extra.nextOverflow = nextOverflow 存放了下一个可用的溢出桶的位置。

map的访问
1. 计算桶位
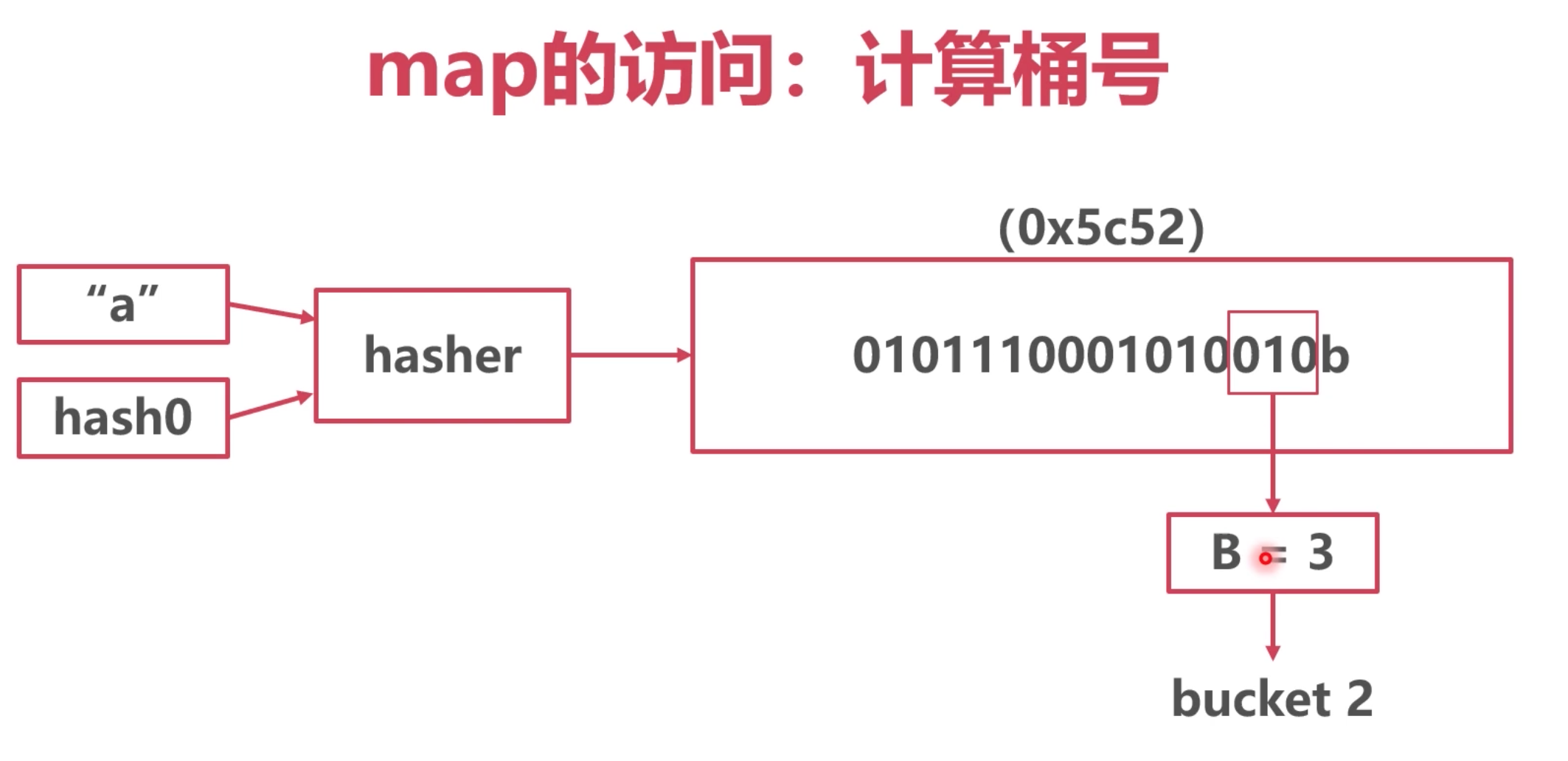
- 通过
key + hash0种子 通过hash算法,等到一串32位的字符串。具体多少位与操作系统有关。
- 取哈希值的后B位。图中B为3,得到了 010 就是 2号桶。
- 得到的值 就是 桶的位置。
2. 访问进行匹配

这里有个 tophash,只存储了hash值的前8位。map里面挺多8的。
开始对比key为a的哈希值的前8位,如果找到了,则需要对比下key,因为前8位可能会有一样的
如果不匹配,则继续往后找,溢出桶,找到则返回值。
如果都找不到,则没有这个key。
map写入

基本和查找类似。
map扩容
当map 溢出桶太多时会导致严重的性能下降,就需要对map的桶进行扩容。
可能会触发扩容的情况: 后面会具体解释
装载因子超过 6.5(平均每个槽6.5个key)
使用了太多溢出桶(溢出桶超过了普通桶)
具体实现在 runtime.mapassign()中:
//截取其中的关键代码:
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
loadFactor:=count / (2^B) 即 装载因子 = map中元素的个数 / map中当前桶的个数
通过计算公式我们可以得知,装载因子是指当前map中,每个桶中的平均元素个数。
如果没有溢出桶,那么一个桶中最多有8个元素,当平均每个桶中的数据超过了6.5个,那就意味着当前容量要不足了,发生扩容。
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
// If the threshold is too low, we do extraneous work.
// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.
// "too many" means (approximately) as many overflow buckets as regular buckets.
// See incrnoverflow for more details.
if B > 15 {
B = 15
}
// The compiler doesn't see here that B < 16; mask B to generate shorter shift code.
return noverflow >= uint16(1)<<(B&15)
}
当 B < 15 时,如果overflow的bucket数量超过 2^B。
当 B >= 15 时,overflow的bucket数量超过 2^15。
map的扩容的类型
- 等量扩容:数据不多但是溢出桶太多了 (整理)
- 翻倍扩容:数据太多了
第一步:
创建一组新桶
oldbuckets 指向原有的桶数组
buckets 指向新的桶数组
map标记为扩容状态
实现源码:
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
// 新建桶
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
//更改B的值
h.B += bigger
// 更改map状态
h.flags = flags
// oldbuckets 指向原来的
h.oldbuckets = oldbuckets
// buckets 指向新桶
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// 赋值新的溢出桶
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}
步骤2
将所有的数据从!日桶驱逐到新桶
采用渐进式驱逐
每次操作一个日桶时,将1日桶数据驱逐到新桶
读取时不进行驱逐,只判断读取新桶还是旧桶

例如图中:原本的2号桶中的数据,要么去新的2号010,要么去新的6号桶。110
这部分的代码也在map.go中
在 mapassign中有这个逻辑:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h.growing() {
growWork(t, h, bucket)
}
}
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 具体的逻辑就在这个 evacuate中实现的。
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
步骤3
所有的日桶驱逐完成后
oldbuckets回收
热门相关:性感模特 我的性青春女老板与我 女职员:职场恋爱 偷情的后裔 小姑子的味道2