SpringBoot责任链与自定义注解:优雅解耦复杂业务
引言
责任链模式是一种行为设计模式,它允许你将请求沿着处理者链进行传递,直到有一个处理者处理请求。在实际应用中,责任链模式常用于解耦发送者和接收者,使得请求可以按照一定的规则被多个处理者依次处理。
首先,本文会通过一个实例去讲解SpringBoot使用责任链模式以及自定义注解优雅的实现一个功能。我们现在有如下图一样的一个创建订单的业务流程处理,我们选择使用责任链模式去实现。

我们分析下流程,发现从条件x开始,就分为了两条业务线,我们定义走业务节点A的叫规则A,走业务节点B的叫规则B。这样就形成了两条业务链路:
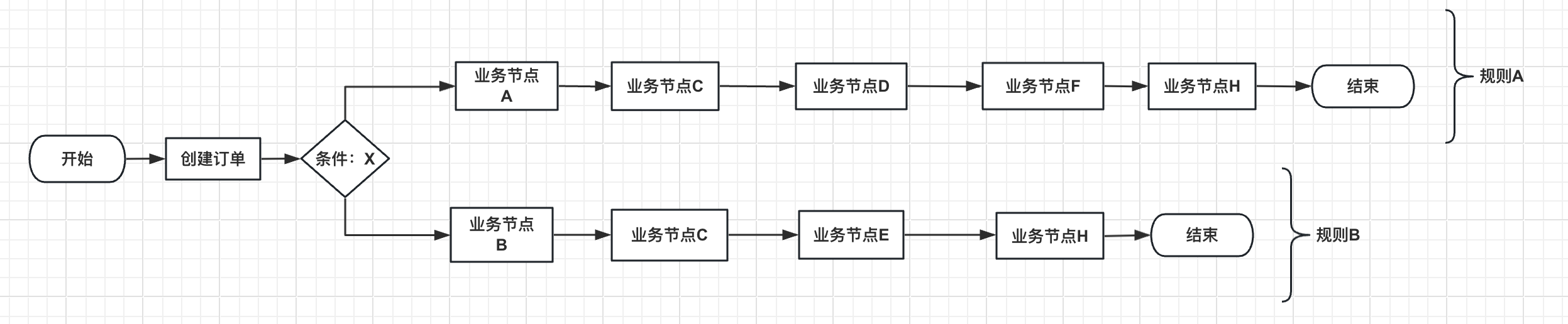
那我就开始使用自定义注解定义规则A,以及规则B。
规则注解
定义@RuleA标识处理规则A的节点:
@Qualifier
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface RuleA {
}
定义@RuleB标识处理规则B的节点:
@Qualifier
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface RuleB {
}
在Spring框架中,@Qualifier注解用于指定要注入的具体bean的名称。当一个接口或抽象类有多个实现类时,通过@Qualifier注解可以明确告诉Spring框架要注入哪一个实现类。
自定义注解与@Qualifier结合使用的含义在于,你可以通过自定义注解为特定的实现类分组,并在使用@Qualifier时引用这个自定义注解。这样做的主要目的是提高代码的可读性和可维护性,使得注入的意图更加清晰。
业务处理
各业务节点处理的数据是同一份,处理方法是一个,只是处理的业务不同。所以我们定义一个业务处理点的接口,让各业务节点去实现业务处理接口。
public interface INodeComponent{
/**
* 定义所有数据处理节点的接口
* @param orderContext 数据上下文
* @param orderParam 数据处理入参参数
*/
void handleData(OrderContext orderContext, OrderParam orderParam);
}
然后我们实现业务处理接口:
我们定义在规则A流程中执行的节点都是用注解@RuleA去标记,如下:
@Slf4j
@Component
@RuleA
@Order(1)
public class ANodeComponent implements INodeComponent {
@Override
public void handleData(OrderContext orderContext, OrderParam orderParam) {
log.info("RuleA流程执行处理业务节点A");
final List<String> executeRuleList = Optional.ofNullable(orderContext.getExecuteRuleList()).orElse(new ArrayList<>());
executeRuleList.add("ANodeComponent");
orderContext.setExecuteRuleList(executeRuleList);
// 不同类型订单,订单号不同,可在节点中个处理
orderContext.setOrderId("TOC11111");
}
}
@Slf4j
@Component
@RuleA
@RuleB
@Order(10)
public class CNodeComponent implements INodeComponent {
// 省略具体的业务处理逻辑
}
@Slf4j
@Component
@RuleA
@Order(20)
public class DNodeComponent implements INodeComponent {
// 省略具体的业务处理逻辑
}
@Slf4j
@Component
@RuleA
@Order(30)
public class FNodeComponent implements INodeComponent {
// 省略具体的业务处理逻辑
}
@Slf4j
@Component
@RuleA
@RuleB
@Order(40)
public class HNodeComponent implements INodeComponent {
// 省略具体的业务处理逻辑
}
我们定义在规则B流程中执行的节点都是用注解@RuleB去标记,如下:
@Slf4j
@Component
@RuleB
@Order(1)
public class BNodeComponent implements INodeComponent {
log.info("RuleB流程执行处理业务节点B");
final List<String> executeRuleList = Optional.ofNullable(orderContext.getExecuteRuleList()).orElse(new ArrayList<>());
executeRuleList.add("BNodeComponent");
orderContext.setExecuteRuleList(executeRuleList);
orderContext.setOrderId("TOB11111");
}
@Slf4j
@Component
@RuleA
@RuleB
@Order(10)
public class CNodeComponent implements INodeComponent {
// 省略具体的业务处理逻辑
}
@Slf4j
@Component
@RuleB
@Order(20)
public class ENodeComponent implements INodeComponent {
// 省略具体的业务处理逻辑
}
@Slf4j
@Component
@RuleA
@RuleB
@Order(40)
public class HNodeComponent implements INodeComponent {
// 省略具体的业务处理逻辑
}
可以看到如果规则A和规则B都需要执行的业务用了@RuleA和@RuleB去标记。同时我们使用@Order注解定义NodeComponent的注入顺序,值越小越先注入。
基于@Order定义
NodeComponent的注入顺序不是那么的友好,最好的方式是与规则注解耦合,即一个规则下定义注入顺序,
规则处理器
我们在定义条件X节点对应的针对处理规则A和规则B的处理器。
同理,因规则A以及规则B处理数据的数据是同一份,方法也是同一个,所以我们还是定义一个处理器超类:
@Slf4j
public abstract class NodeHandler {
/**
* 处理校验订单以及创建订单信息
* @param requestVO 订单创建入参
* @return 订单DO实体类
*/
public abstract OrderDO handleOrder(OrderCreateRequestVO requestVO);
/**
* 执行业务处理链路
* @param requestVO 订单创建入参
* @param nodeComponentList 业务处理节点
* @return
*/
protected OrderDO executeChain(OrderCreateRequestVO requestVO, List<? extends INodeComponent> nodeComponentList){
final OrderParam orderParam = this.buildOrderParam(requestVO);
final OrderContext orderContext = OrderContext.builder().build();
for (INodeComponent nodeComponent : nodeComponentList){
// 此处进行业务处理节点的调用
nodeComponent.handleData(orderContext, orderParam);
}
log.info("执行的链路:{}", String.join(",", Optional.ofNullable(orderContext.getExecuteRuleList()).orElse(new ArrayList<>())));
return this.buildOrderDO(orderContext);
}
我们的超类对外提供统一的业务处理接口方法,同时对业务处理节点的调用进行处理的管理,对于规则处理者来说,他只需要实现handlerOrder的方法。以下是规则处理器的实现代码:
@Slf4j
@Component("ruleA")
public class RuleAHandler extends NodeHandler {
@RuleA
@Autowired
private List<? extends INodeComponent> nodeComponents;
/**
* 处理校验订单以及创建订单信息
*
* @param requestVO 订单创建入参
* @return 订单DO实体类
*/
@Override
public OrderDO handleOrder(OrderCreateRequestVO requestVO) {
return super.executeChain(requestVO, nodeComponents);
}
}
@Slf4j
@Component("ruleB")
public class RuleBHandler extends NodeHandler {
@RuleB
@Autowired
private List<? extends INodeComponent> nodeComponents;
/**
* 处理校验订单以及创建订单信息
*
* @param requestVO 订单创建入参
* @return 订单DO实体类
*/
@Override
public OrderDO handleOrder(OrderCreateRequestVO requestVO) {
return super.executeChain(requestVO, nodeComponents);
}
}
订单处理器
最后我们在创建一个订单处理器,为业务代码中提供服务接口。
先创建一个订单类型的枚举,枚举中定义使用哪个规则处理器。
@AllArgsConstructor
public enum OrderHandlerEnum {
TO_C(1,"ruleA"),
TO_B(2, "ruleB");
public final Integer orderType;
public final String ruleHandler;
public static String getRuleHandler(Integer orderType){
return Arrays.stream(OrderHandlerEnum.values()).filter(e -> Objects.equals(e.orderType, orderType)).findFirst()
.orElse(OrderHandlerEnum.TO_C).ruleHandler;
} `
}
然后我们就可以定义一个订单处理器了,处理中决定调用那个规则处理器去执行规则。
@Slf4j
@Component
public class OrderFactory {
@Autowired
private Map<String, NodeHandler> nodeHandlerMap;
/**
* 创建订单
* @param requestVO 订单参数
* @return 订单实体DO
*/
public OrderDO createOrder(OrderCreateRequestVO requestVO){
final Integer orderType = requestVO.getOrderType();
// 获取node规则执行器名称
final String ruleHandler = OrderHandlerEnum.getRuleHandler(orderType);
// 获取node规则执行器
final NodeHandler nodeHandler = nodeHandlerMap.get(ruleHandler);
if (nodeHandler == null){
// 异常
throw new RuntimeException();
}
return nodeHandler.handleOrder(requestVO);
}
}
测试
我们编写测试类看一下效果:
@SpringBootTest
public class SpringbootCodeApplicationTests {
@Autowired
private OrderFactory orderFactory;
@Test
void testOrderCreate() {
final OrderCreateRequestVO requestVO = new OrderCreateRequestVO();
requestVO.setOrderNo("11111");
requestVO.setOrderType(OrderHandlerEnum.TO_C.orderType);
requestVO.setUserId("coderacademy");
requestVO.setUserName("码农Academy");
final OrderDO orderDO = orderFactory.createOrder(requestVO);
System.out.println(orderDO.getOrderId());
}
}
执行结果日志如下:

执行结果是我们想要的。
通过采用责任链模式结合Spring Boot的优化方案,我们实现了一种高度解耦的业务逻辑处理方式。其中的主要优势在于,我们成功地将各个业务节点的处理逻辑进行解耦,使得每个节点能够独立演进,降低了代码的耦合性。
其中的最大优势体现在替换或新增业务节点处理规则时的灵活性。若需替换某一节点的处理规则,只需实现新的INodeComponent并标记相应的规则注解,系统将自动将其纳入责任链中。这意味着我们能够以最小的改动实现业务逻辑的变更,而无需涉及其他节点。
进一步地,若新增一条处理规则,只需定义新的规则注解(如@RuleC),并实现相应的INodeComponent接口,定义规则C下各节点的处理逻辑。然后,创建对应的规则C处理器即可,系统将自动将其整合到责任链中。这种设计允许我们以一种清晰、简便的方式进行代码扩展,同时使得代码接口清晰易懂,为后续维护和升级提供了便利。这种设计理念在面对日益变化的业务规则时,具有显著的适应性和可维护性。
上述示例中我们也使用了表驱动,策略模式+工厂模式,以及枚举等方式,具体请参考我另一篇的文章:代码整洁之道(一)之优化if-else的8种方案
总结
通过使用责任链模式,我们可以更优雅地组织和扩展业务逻辑。在Spring Boot中,结合自定义注解和@Qualifier注解,以及构造函数注入,可以实现更清晰、可读性更强的代码。通过控制处理者的顺序,我们可以确保责任链的执行顺序符合业务需求。
责任链模式的优雅实践使得我们的代码更具可维护性,更容易应对业务的变化。在设计和实现中,要根据实际业务场景的需要进行灵活调整,以达到最佳的解耦和可扩展性。
有的小伙伴可能也会发现我们的类定义为NodeComponent,很熟悉,是的,此类名参考一个规则引擎开源项目LiteFlow,我们下一期将会使用LiteFolw改造这个案例,由此打开学习LiteFlow的篇章,需要了解的小伙伴们注意点关注哦。。。。
本文已收录于我的个人博客:码农Academy的博客,专注分享Java技术干货,包括Java基础、Spring Boot、Spring Cloud、Mysql、Redis、Elasticsearch、中间件、架构设计、面试题、程序员攻略等