浅析网络库
1.C10K problem
最初的服务器都是基于进程/线程模型的,新到来一个TCP连接,就需要分配1个进程(或者线程),但当连接数来到10K时,就需要不停地买服务器了. Dan Kegel 在 1999 年提出了著名的世界难题:“c10k problem”。那时的服务器还只是 32 位系统,运行着 Linux 2.2 版本(后来又升级到了 2.4 和 2.6,而 2.6 才支持 x86_64),只配置了很少的内存(2GB)和千兆网卡。此时距离Redhat 发布POSIX Thread Library (NPTL)还有4年时间,内核调度实体都是进程,内核并没有真正支持线程,还不能创建成千上万的线程.此时Windows还在时不时蓝屏···虽然早在1983年Unix就搞出了select,但跟三年后的poll一样,面对C10K问题时原罪就是慢.
逸闻轶事 当年腾讯QQ也是有C10K问题的,他们是在udp上面封装了一下,模拟了一下tcp,解决了大并发的问题,之后因为做的很nb了,虽然epoll这种技术出现了,还是没有改回使用tcp了。后来的手机QQ,微信都采用TCP协议。[\[1\]](https://www.zhihu.com/question/20292749/answer/24557541)
在此背景下,微软率先开发了IOCP技术,并将其引入到Windows I/O 模型中,1994年9月21日在Windows NT3.5后开始支持, 据后续观测,该版本在全球范围内使用率极低。
2000 年7 月发布的FreeBSD 4.1 中首次引入了kqueue,随后也被NetBSD、OpenBSD、macOS 等操作系统支持。
2002年携带Linux核心的可擴展I/O事件通知機制epoll的Linux 2.5.44首度登场.
2.网络IO模型
2.1 IOCP模型
IOCP本质是一种线程池的模型,处理多个并发的异步I/O请求时,以往的模型都是在接收请求是创建一个线程来应答请求。这样就有很多的线程并行地运行在系统中。而这些线程都是可运行的,Windows内核花费大量的时间在进行线程的上下文切换,并没有多少时间花在线程运行上。再加上创建新线程的开销比较大,所以造成了效率的低下。 而IOCP模型是事先开好了N个线程,存储在线程池中,让他们hold。然后将所有用户的请求都投递到一个完成端口上,然后N个工作线程逐一地从完成端口中取得用户消息并加以处理。这样就避免了为每个用户开一个线程。既减少了线程资源,又提高了线程的利用率。 这个线程池的核心工作就是去调用IO操作完成时的回调函数.这也是IOCP名字的来由.它首先就被用来处理硬盘操作的输入输出,同时它也支持邮箱、管道、以及WinSock的网络输入输出.
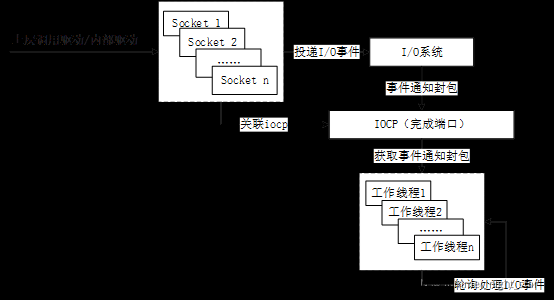
IOCP整体工作流程:

2.2 epoll 模型
epoll模型,网上的文章汗牛充栋,服务器的同学也比较熟悉.
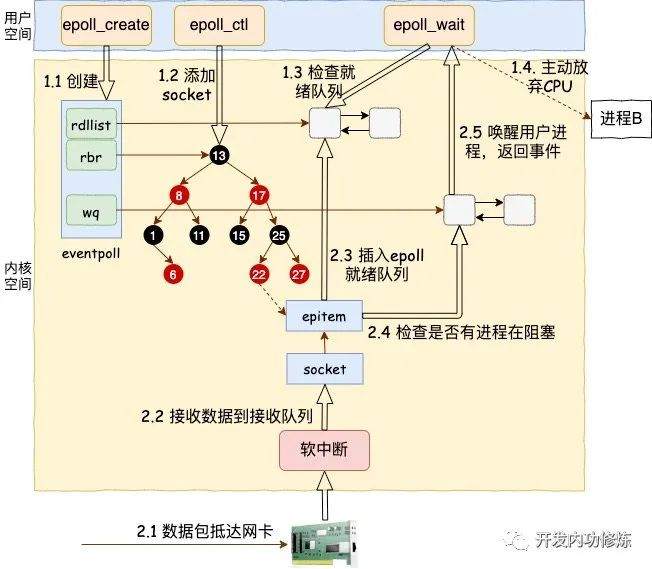
2.3 kqueue 模型
在kqueue的实现中,比较关键的是一个knote结构体,该结构体在内核空间对应于应用层的kevent结构体.knode将事件源(被监控节点的tcp/socket)是否有事件发生和knote所在的kqueue联系起来.另一个比较关键的数据结构是kqueue自己,其包含两个功能:1)
包含一个有事件发生需要通知应用层的knotes队列,也就是已完成事件队列. 2) 保存并跟踪应用层注册的的需要监听的事件和描述符.kqueue有三个子结构体来实现上面的功能:
--1. 一个队列,用来保存active的knotes节点
--2. 一个小hashtable 用来查找那些没有对应描述符的knotes节点
--3.一个线性的描述符array,这个array和进程打开的文件描述符表一致
上述的hashtable 和线性数组都是延迟分配的, 存放描述符array可以自动扩展, kqueue必须记录这些所有用户注册的knotes, 当kqueue被close,属于它的knotes都会被释放. 描述符array可以保证当用用户关闭一个描述符如(socket fd)时, kqueue对应的knotes 节点会别释放.
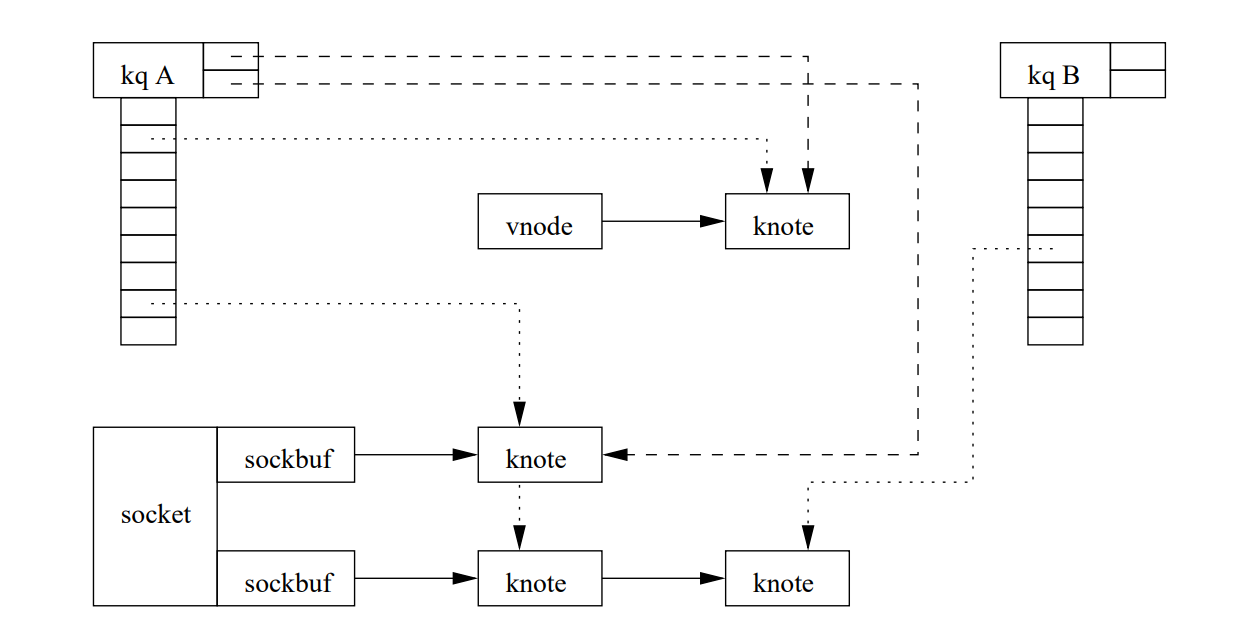
图中有两个 kqueue、它们的描述符数组和活动列表。请注意,kq A 在其活动列表中有两个排队的节点,而 kq B 则没有。 socket 为每个sockbuf 都有一个 klist,如图所示,一个 klist 上的节点可能属于不同的 kqueue。vnode 用于文件系统.
注册:
2.4 io_uring 模型
io_uring 是 2019 年 Linux 5.1 内核首次引入的高性能异步 I/O 框架,在设计上是真正的异步 I/O.
在 kernel 中会创建一块内存区域,该内存区域分为三个部分,分别是 SQ,CQ,SQEs.
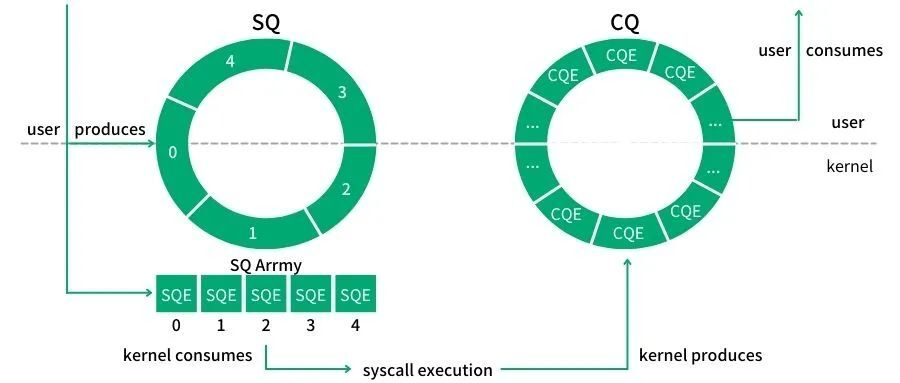
在 SQ,CQ 之间有一个叫做 SQEs 数组.实际的请求只保存在 SQEs 数组中。SQ 和 CQ 中每个节点保存的都是 SQEs 数组的索引,而不是实际的请求.
io_uring 实例可工作在三种模式:
- 中断驱动模式(interrupt driven)默认模式。可通过 io_uring_enter() 提交 I/O 请求,然后无需进入内核就能检查 CQ 状态判断是否完成。
2.轮询模式(polled)Busy-waiting for an I/O completion,而不是通过异步 IRQ(Interrupt Request)接收通知。这种模式需要文件系统(如果有)和块设备(block device)支持轮询功能。 相比中断驱动方式,这种方式延迟更低(连系统调用都省了), 但可能会消耗更多 CPU 资源。
3.内核轮询模式(kernel polled)这种模式中,会 创建一个内核线程(kernel thread)来执行 SQ 的轮询工作。使用这种模式的 io_uring 实例, 应用无需切到到内核态 就能触发I/O 操作。 通过 SQ 来提交 SQE,以及监控 CQ 的完成状态,应用无需任何系统调用,就能提交和收割 I/O(submit and reap I/Os)。
诸神之战
各个网络IO模型都声称自己的新接口对 select 有质的提升,是破解 c10k 问题的不二法宝,你用也得用,不用也得用. 为了让自己编写的网络程序能跨平台,程序员开始了对三大各自为阵的法宝的膜拜学习.除了需要应对多套互不兼容的 API , 异步本身也需要更高级的抽象,把程序员从编写异步代码的地狱模式里拯救出来程序员们急需一个上天入地无所不能的法宝的法宝,把这三家法宝给统御起来.
ACE
率先站出来的是 ACE, ACE 支持 IOCP/kqueu/epoll/select/ 各种接口,号曰没有不能跨的平台,支持多种模型.
但 ACE 过于复杂,甚至比它试图封装的对象更复杂 ,过度设计,以对象代替接口, 以虚函数代替回调,以继承代替组合,以虚类代替模板对象间关系错综复杂,牵一发而动全身。ACE 5.7 自身有 30 万行 C++ 代码.除了作者,已经无人能参与 ACE 的开发了.

libevent
Libevent 是一个用C语言编写的、基于reactor模式的轻量级开源高性能事件通知库,主要有以下几个亮点:事件驱动( event-driven),高性能;轻量级,专注于网络,不如 ACE 那么臃肿庞大;源代码相当精炼、易读;跨平台,支持 Windows、 Linux、 BSD 和 Mac Os;支持多种 I/O 多路复用技术, epoll、 poll、 dev/poll、 select 和 kqueue 等;支持 I/O,定时器和信号等事件;注册事件优先级。
Libevent 已经被广泛的应用,作为底层的网络库;比如 Google Chrome(Mac 和 Linux 版本), memcached、 Tor:洋葱头、Transmission: 一个开源的 BitTorrent (协议)客户端. ntpd: 网络时间协议 daemon、 tmux: 一个终端多路复用器 等。
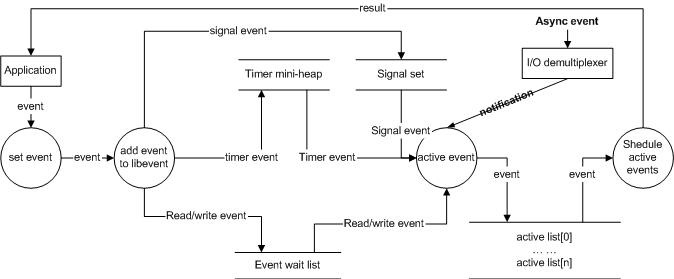
libevent 基本流程。
1) 首先应用程序准备并初始化event,设置好事件类型和回调函数;
2) 向libevent添加该事件event。对于定时事件,libevent使用一个小根堆管理,key为超时时间;对于Signal和I/O事件,libevent将其放入到等待链表(wait list)中,这是一个双向链表结构;
3) 程序调用event_base_dispatch()系列函数进入无限循环,等待事件,以select()函数为例;每次循环前libevent会检查定时事件的最小超时时间tv,根据tv设置select()的最大等待时间,以便于后面及时处理超时事件;
当select()返回后,首先检查超时事件,然后检查I/O事件;
Libevent将所有的就绪事件,放入到激活链表中;
然后对激活链表中的事件,调用事件的回调函数执行事件处理;
libevent 也存在着一些缺点:
全局变量的使用,让libevent很难在多线程环境中使用。watcher结构体很大,因为它们包含了I/O,定时器和信号处理器。额外的组件如HTTP和DNS服务器,因为拙劣的实现品质和安全问题而备受折磨。定时器不精确,而且无法很好地处理时间跳变。libev试图改进所有这些缺陷.
libev
在设计理念上,创建libev是为了改进libevent中的一些架构决策。
例如:全局变量的使用使得在多线程环境中很难安全地使用libevent。
观察器结构很大,因为它们将输入/输出、时间和信号处理程序合二为一。
额外的组件(如http和dns服务器)的实现质量参差不齐。
计时器不精确,不能很好地处理时间跳跃。
Libev的解决方案是:
不使用全局变量,而是每个函数都有一个循环上下文。
对每种事件类型使用小的观察器(一个I/O观察器在x86_64机器上使用56字节,而用libevent的话使用136字节)。
没有http库等组件。libev的功能非常少。
允许更多事件类型,例如基于wall clock或者单调时间的定时器、线程间中断等等。
更简单地说,libev的设计遵循UNIX工具箱的哲学,尽可能好地只做一件事。
但 libev 的缺陷也很明显:不支持IOCP.于是 libuv 就出来给 libev 擦屁股了。
node.js曾经嵌入了libev,现在更换为了libuv.
github最新最近更新时间是2015年,官网也打不开了.
libuv
Libuv 是一个跨平台的的基于事件驱动的异步 io 库。但是他提供的功能不仅仅是 io,包括进程、线程、信号、定时器、进程间通信等.libuv构成:
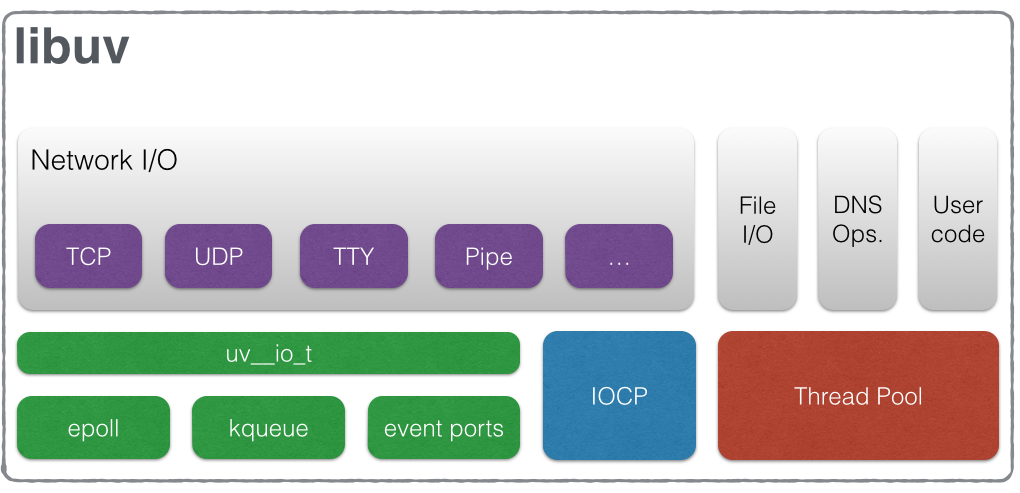
I/O 循环
下面的图表显示了一次循环迭代的所有阶段:

1.更新 now.
2.运行适当的计时器。 所有在循环概念 now 之前到期的活动的计时器的回调函数被调用。
3.待处理的回调函数被调用。 大多数情况下,在I/O轮询之后所有的I/O回调函数会被调用。 然而有些情况下,这些回调推延到下一次迭代中。 如果前一次的迭代推延了任何的I/O回调函数的调用,回调函数将在此刻运行。
4.空转句柄的回调函数被调用。 虽有不恰当的名字,当其活动时空转句柄在每次循环迭代时都会运行。
5.准备句柄的回调函数被调用。 在循环将为I/O阻塞前,准备句柄的回调函数被调用。
6.循环为I/O阻塞。
7.检查句柄的回调函数被调用。 在循环为I/O阻塞之后,检查句柄的回调函数被调用。 检查句柄基本上与准备句柄相辅相成。
8.关闭 回调函数被调用。 如果一个句柄通过调用 uv_close() 被关闭, 它的回调函数将被调用。
ASIO
Boost.Asio在2003被开发出来,然后于2005年的12月引入到Boost 1.35版本中.ASIO 放入 Boost 锻炼,经过 Boost 十余的锻炼,有望加入到C++23. ASIO的作者Christopher M. Kohlhoff研究了ACE 6个模型后提出Proactor 模型乃最优模型.
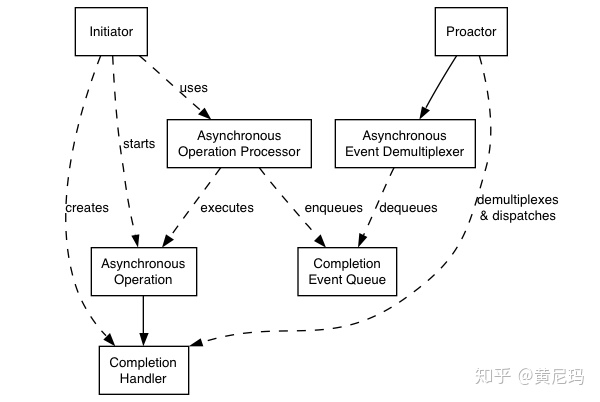
Initiator:初始化器,用来提供初始的异步操作。
Asynchronous Operation:异步操作,调用后直接返回,不阻塞;
Asynchronous Operation Processor:异步操作执行单元,用来执行异步操作,异步操作执行完成之后将对应的完成事件放入完成事件队列
Completion Event Queue:存储完成事件的队列Asynchronous Event Demultiplexer:异步事件多路复用单元,等待
Completion Event Queue出现完成事件,然后返回一个完成事件
Proactor:调用异步事件多路复用单元来获得一个完成事件,然后分发这个完成事件所关联的完成操作句柄(回调函数)到具体的执行单元中
在windows上,这个模型很容易的就可以映射到IOCP之上:
asynchrounous Operation Processor:这个是系统自己处理,我们直接将异步操作映射到操作系统自带的异步api即可委托给操作系统执行;
completion Event Queue: 这个完成事件队列也是由windows自己管理好了,我们只需要用GetQueuedCompletionStatus即可获得一个完成事件;
Asynchronous Event Demultiplexer: 这部分是由Asio调用GetQueuedCompletionStatus来获得完成事件以及相应的完成操作句柄。
而在Linux/Unix上情况则不同了,因为这两个平台系统所提供的操作是同步的,其模型是Reactor模型,只能通知IO操作是否可以开始进行,而不能通知IO操作的完成。所以,Asio需要进行如下处理:Asynchronous Operation Processor: 当通过select/epoll/kqueue实现的reactorr通知某项IO操作可以进行时,这个processor执行这个异步操作,然后将完成事件和完成操作挂在到完成事件队列上;
Completion Event Queue : 一个以链表形式存在的完成操作句柄队列;
Asynchronous Event DemultiPlexer:这个是由Asio实现的一个等待机制,主要是通过条件变量来进行等待
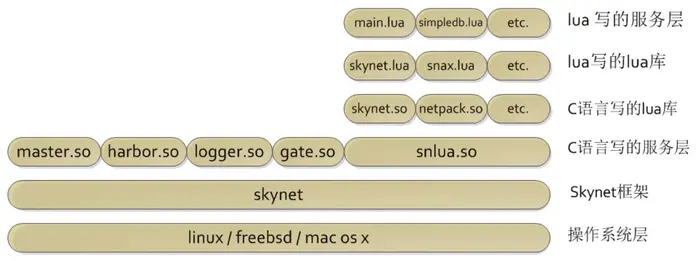
skynet
skynet 各层的表现:
网络及线程示意图:

a.简化的数据结构:每个模块会创建一个context,里面有一个消息队列 message_queue.
b.处理消息:其他模块和在网络端的模块想与某个模块通信,就向其 message_queue 中 push 消息.有了消息后就会被挂在 global context list 中. 而线程池就是不断从 global context list 中取出context,然后用回调函数处理 message_queue 中的消息.
c.发送消息:发送消息的目标模块如果在本地,就直接将消息 push 进其 message_queue.如果消息在网络远端,则将消息发给 habor 模块,由habor模块发送给网络线程发送出去.
d.定时器 有单独的线程运行定时器.逻辑线程生成一个协程发送消息给定时器线程,定时器触发后发送 message 到对应 context 的 message_queue 里面
skynet的Actor模型是什么:
消息除了在网络线程和逻辑线程之间传递外,也在逻辑线程之间传递.实现方法就是将消息直接塞到目标队列里面,供其处理.[skynet_send]
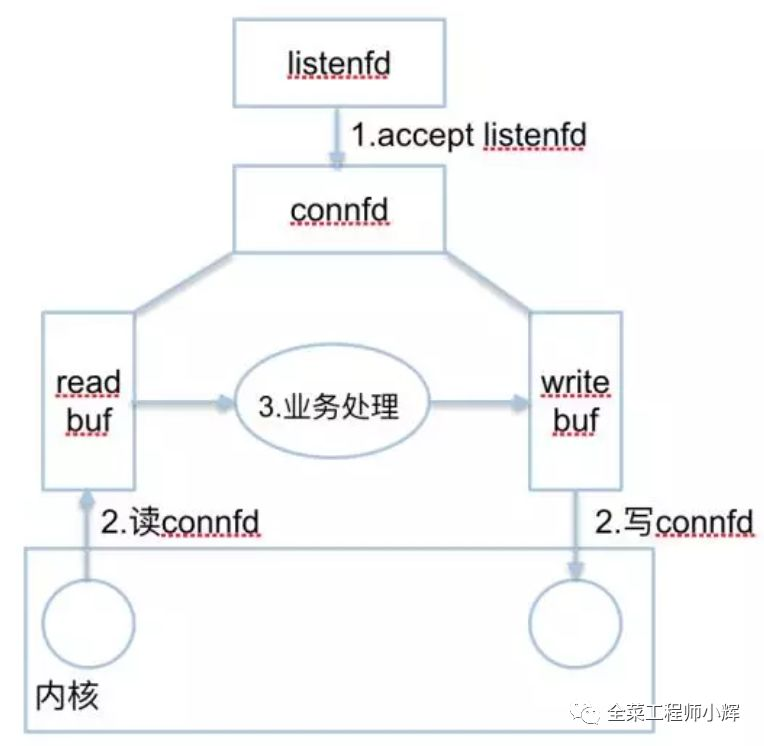
2种fd:
listenfd:一般情况,只有一个。用来监听一个特定的端口(如80)。
connfd:每个连接都有一个connfd。用来收发数据。
3种事件:
listenfd进行accept阻塞监听,创建一个connfd
用户态/内核态copy数据。每个connfd对应着2个应用缓冲区:readbuf和writebuf。
处理connfd发来的数据。业务逻辑处理,准备response到writebuf。
Reactor模型
Reactor模型基于事件驱动,特别适合处理海量的I/O事件。Reactor模型中定义的三种角色:
Reactor:负责监听和分配事件,将I/O事件分派给对应的Handler。新的事件包含连接建立就绪、读就绪、写就绪等。
Acceptor:处理客户端新连接,并分派请求到处理器链中。
Handler:将自身与事件绑定,执行非阻塞读/写任务,完成channel的读入,完成处理业务逻辑后,负责将结果写出channel。可用资源池来管理。
根据 Reactor 的数量和处理资源池线程的数量不同,有 3 种典型的实现:
1)单 Reactor 单线程;
2)单 Reactor 多线程;
3)主从 Reactor 多线程。
单 Reactor 单线程
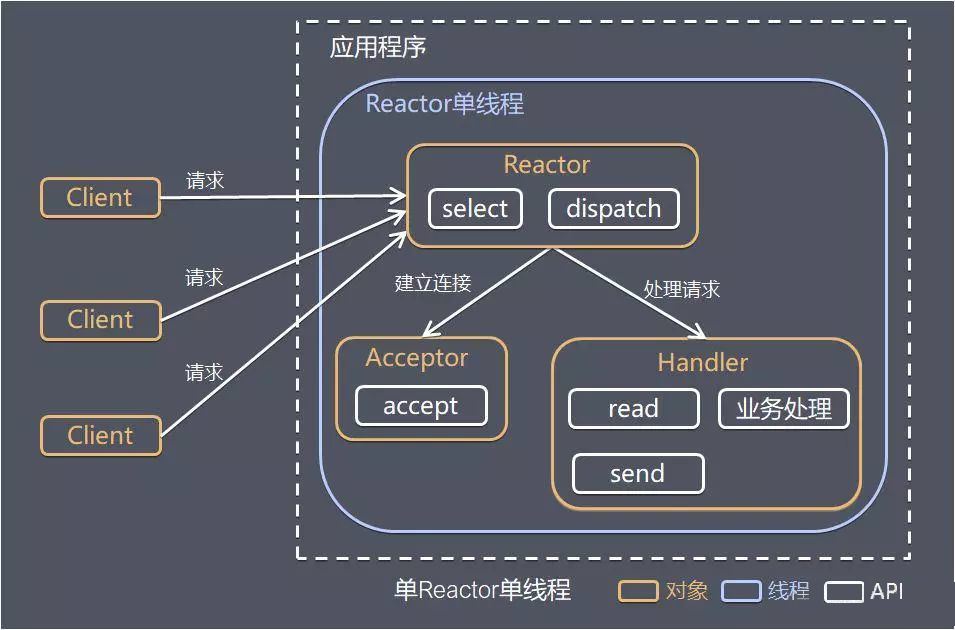
方案说明:
1)Reactor 对象通过 Select 监控客户端请求事件,收到事件后通过 Dispatch 进行分发;
2)如果是建立连接请求事件,则由 Acceptor 通过 Accept 处理连接请求,然后创建一个 Handler 对象处理连接完成后的后续业务处理;
3)如果不是建立连接事件,则 Reactor 会分发调用连接对应的 Handler 来响应;
4)Handler 会完成 Read→业务处理→Send 的完整业务流程。
优点:模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成。
缺点:性能问题,只有一个线程,无法完全发挥多核 CPU 的性能。Handler 在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈。
单 Reactor 多线程
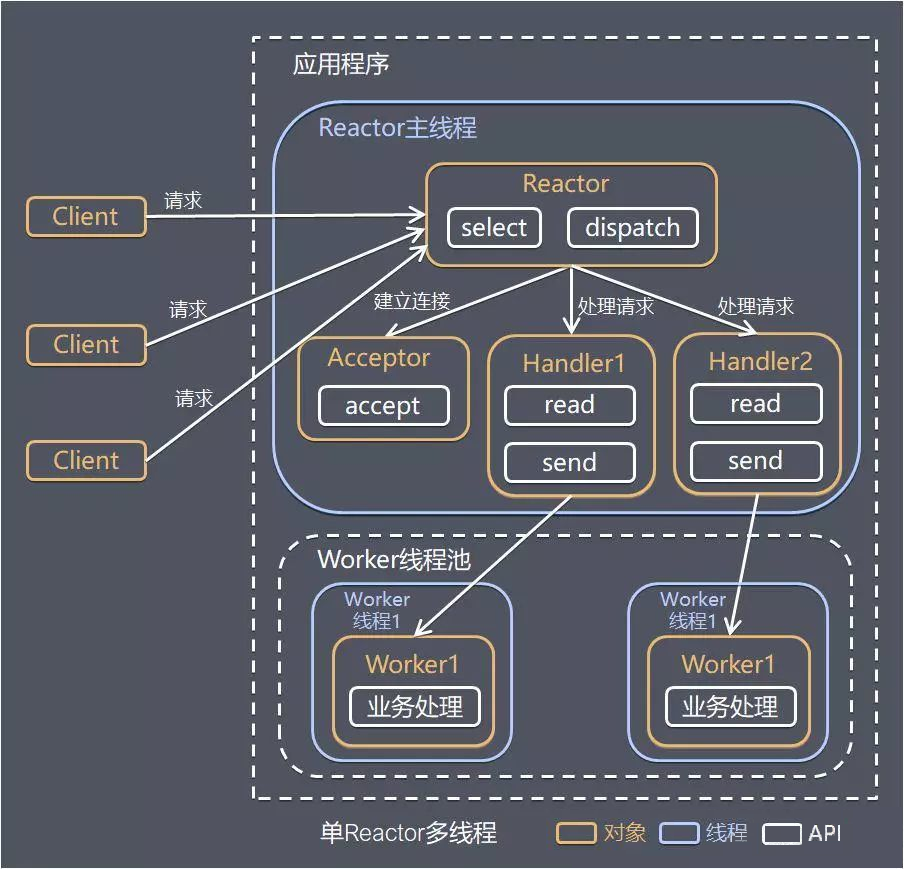
方案说明:
1)Reactor 对象通过 Select 监控客户端请求事件,收到事件后通过 Dispatch 进行分发;
2)如果是建立连接请求事件,则由 Acceptor 通过 Accept 处理连接请求,然后创建一个 Handler 对象处理连接完成后续的各种事件;
3)如果不是建立连接事件,则 Reactor 会分发调用连接对应的 Handler 来响应;
4)Handler 只负责响应事件,不做具体业务处理,通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理;
5)Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理;
6)Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
优点:可以充分利用多核 CPU 的处理能力。
缺点:多线程数据共享和访问比较复杂;Reactor 承担所有事件的监听和响应,在单线程中运行,高并发场景下容易成为性能瓶颈。
主从 Reactor 多线程
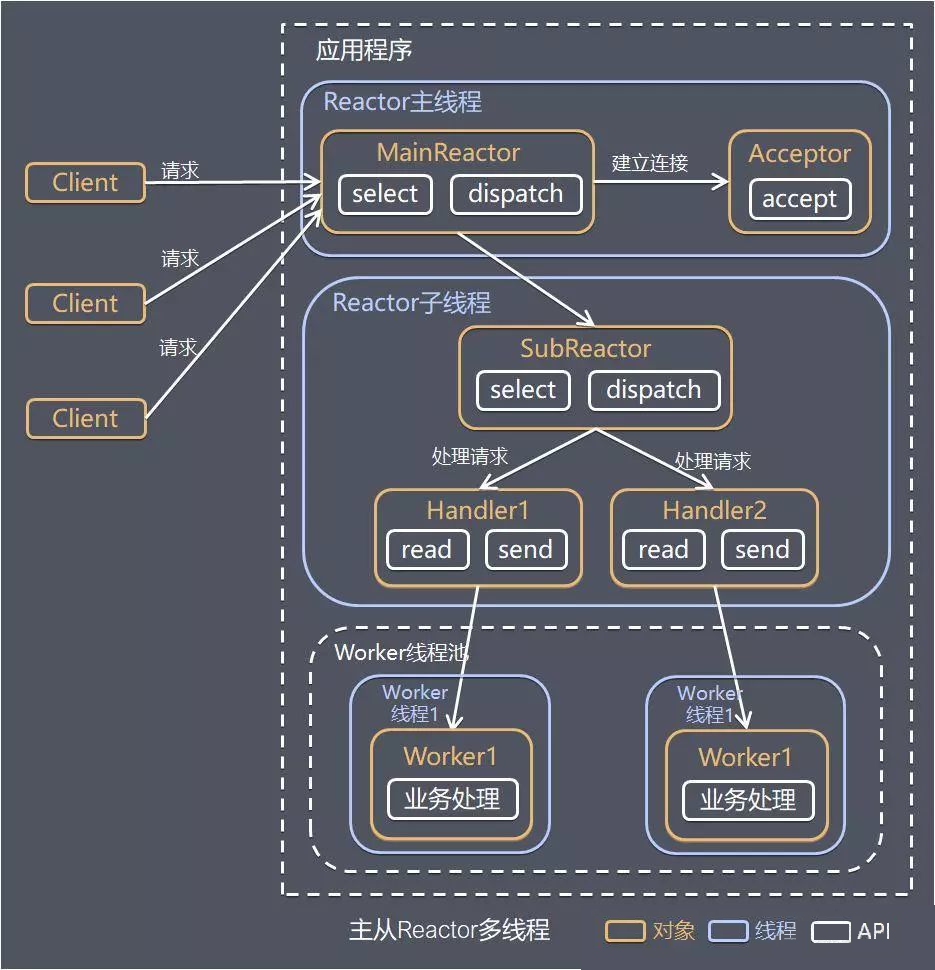
针对单 Reactor 多线程模型中,Reactor 在单线程中运行,高并发场景下容易成为性能瓶颈,可以让 Reactor 在多线程中运行。
方案说明:
1)Reactor 主线程 MainReactor 对象通过 Select 监控建立连接事件,收到事件后通过 Acceptor 接收,处理建立连接事件;
2)Acceptor 处理建立连接事件后,MainReactor 将连接分配 Reactor 子线程给 SubReactor 进行处理;
3)SubReactor 将连接加入连接队列进行监听,并创建一个 Handler 用于处理各种连接事件;
4)当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应;
5)Handler 通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理;
6)Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理;
7)Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
优点:父线程与子线程的数据交互简单职责明确,父线程只需要接收新连接,子线程完成后续的业务处理。父线程与子线程的数据交互简单,Reactor 主线程只需要把新连接传给子线程,子线程无需返回数据。这种模型在许多项目中广泛使用,包括 Nginx 主从 Reactor 多进程模型,Memcached 主从多线程,Netty 主从多线程模型的支持。
Reactor 模式具有如下的优点:
1)响应快,不必为单个同步时间所阻塞,虽然 Reactor 本身依然是同步的;
2)编程相对简单,可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程/进程的切换开销;
3)可扩展性,可以方便的通过增加 Reactor 实例个数来充分利用 CPU 资源;
4)可复用性,Reactor 模型本身与具体事件处理逻辑无关,具有很高的复用性。
Proactor模型
在 Reactor 模式中,Reactor 等待某个事件或者可应用或者操作的状态发生(比如文件描述符可读写,或者是 Socket 可读写)。然后把这个事件传给事先注册的 Handler(事件处理函数或者回调函数),由后者来做实际的读写操作。其中的读写操作都需要应用程序同步操作,所以 Reactor 是非阻塞同步网络模型。如果把 I/O 操作改为异步,即交给操作系统来完成就能进一步提升性能,这就是异步网络模型 Proactor。
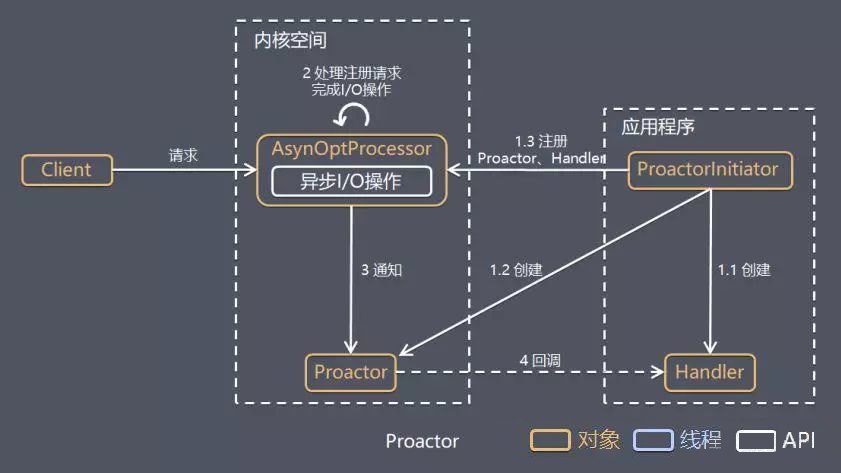
Proactor 是和异步 I/O 相关的,详细方案如下:
1)Proactor Initiator 创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过 AsyOptProcessor(Asynchronous Operation Processor)注册到内核;
2)AsyOptProcessor 处理注册请求,并处理 I/O 操作;
3)AsyOptProcessor 完成 I/O 操作后通知 Proactor;
4)Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理;
5)Handler 完成业务处理。
可以看出 Proactor 和 Reactor 的区别:
1)Reactor 是在事件发生时就通知事先注册的事件(读写在应用程序线程中处理完成);
2)Proactor 是在事件发生时基于异步 I/O 完成读写操作(由内核完成),待 I/O 操作完成后才回调应用程序的处理器来进行业务处理。
理论上 Proactor 比 Reactor 效率更高,异步 I/O 更加充分发挥 DMA(Direct Memory Access,直接内存存取)的优势。
但是Proactor有如下缺点:
1)编程复杂性,由于异步操作流程的事件的初始化和事件完成在时间和空间上都是相互分离的,因此开发异步应用程序更加复杂。应用程序还可能因为反向的流控而变得更加难以 Debug;
2)内存使用,缓冲区在读或写操作的时间段内必须保持住,可能造成持续的不确定性,并且每个并发操作都要求有独立的缓存,相比 Reactor 模式,在 Socket 已经准备好读或写前,是不要求开辟缓存的;
自己动手写网络库
https://github.com/liyakai/toolbox
参考资料: