【Python学习笔记】 第4章 介绍Python对象类型
在Python中,数据以对象的形式出现,包括内置对象和自己创建的对象。在这一章中,我们首先了解Python的内置对象。
Python知识结构
Python程序可以分为模块、语句、表达式以及对象:
- 程序由模块构成
- 模块包含语句
- 语句包含表达式
- 表达式创建并处理对象
为什么使用内置类型
- 内置对象使程序更容易编写
- 内置对象是可扩展的组件
- 内置对象往往比定制的数据结构更加有效率
- 内置对象是语言标准的一部分
Python核心数据类型
| 对象类型 | 字面量/构造示例 |
|---|---|
| 数字 | 1234, 3.1415, 3+4j, 0b111, Decimal(), Fraction() |
| 字符串 | 'spam', "Bob's", b'a\x01c', u'sp\xc4m' |
| 列表 | [1,[2,'three'],4.5], list(range(10)) |
| 字典 | {'food':'spam', 'taste':'yum'}, dict(hours=10) |
| 元组 | (1,'spam',4,'U'), tuple('spam'), namedtuple |
| 文件 | open('egg.txt'), open(r'C:\ham.bin', 'wb') |
| 集合 | set('abc'), {'a', 'b', 'c'} |
| 其他核心类型 | 类型、None、布尔型 |
| 程序单元类型 | 函数、模块、类 |
| Python实现相关类型 | 已编译代码、调用栈跟踪 |
把上述类型称为核心数据类型,是因为它们在Python语言内部高效创建。
一旦创建了对象,它就和操作绑定。比如:只能对字符串进行字符串相关的操作;只能对列表进行列表相关的操作。
数字
Python支持基本的数学运算:加号+代表加法,星号*代表乘法,双星号**代表幂。
>>> 123 + 222
345
>>> 1.5 * 4
6.0
>>> 2 ** 100
1267650600228229401496703205376
最后一个结果表明了,Python3可以支持很大的整数类型。
对于浮点数,存在两种打印它们的模式:全精度模式和用户友好模式。
除了表达式,我们可以使用Python安装后的内置数学模块。
>>> import math
>>> math.pi
3.141592653589793
>>> math.sqrt(85)
9.219544457292887
random模块作为随机数字的生成器和随机选择器(如:从列表中选择)。
>>> import random
>>> random.random()
0.7710488760534042
>>> random.random()
0.8677574676564624
>>> random.random()
0.9501398019386395
>>> random.choice([1,2,3,4])
4
>>> random.choice([1,2,3,4])
3
>>> random.choice([1,2,3,4])
1
字符串
序列操作
我们可以对字符串采取序列操作,比如取长度len()和索引操作:
>>> S = 'Spam'
>>> len(S)
4
>>> S[0]
'S'
>>> S[1]
'p'
索引从0开始,从左往右递增。
注意到,我们把字符串值赋值给了变量S,这样就创建了一个变量(不需要提前声明)。
我们可以对字符串反向索引。反向索引从-1开始,从右往左递减。
>>> S[-1]
'm'
>>> S[-2]
'a'
序列支持分片操作,即提取整个分片。
>>> S
'Spam'
>>> S[1:3]
'pa'
这种分片的语法是:X[I:J],表示“取出X的偏移量为I,直到但不包括偏移量为J的内容”。结果:返回一个新的对象。上述的分片操作创建新的字符串。
分片X[I:J]中,冒号左右两个参数都可以省略。如果左边的参数省略,那么切片从X[0]开始;如果右边的参数省略,那么切片一直到序列的末尾结束。
>>> S[1:] # 同S[1:len(S)]
'pam'
>>> S # S不变
'Spam'
>>> S[0:3]
'Spa'
>>> S[:3] # 同S[0:3]
'Spa'
>>> S[:-1]
'Spa'
>>> S[:] # 同S[0:len(S)]
序列也支持用加号拼接得到新字符串,或者通过数乘重复。
>>> S
'Spam'
>>> S + 'xyz'
'Spamxyz'
>>> S
'Spam'
>>> S * 8
'SpamSpamSpamSpamSpamSpamSpamSpam'
不可变性
不能通过索引修改字符串,但可以通过创建新字符串的方式修改:
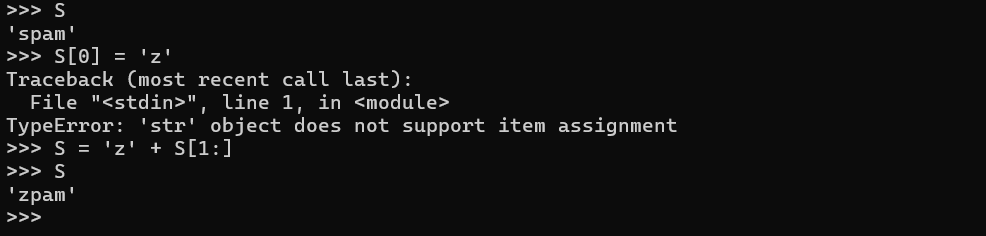
在核心类型中,数字、字符串和元组不可变,但列表、字典和集合可变。
如果我们要通过索引修改字符串,我们要把它扩展为列表,或者使用bytearray类型:
>>> S = 'shrubbery'
>>> L = list(S)
>>> L
['s', 'h', 'r', 'u', 'b', 'b', 'e', 'r', 'y']
>>> L[1] = 'c'
>>> ''.join(L)
'scrubbery'
>>> B = bytearray(b'spam')
>>> B.extend(b'eggs')
>>> B
bytearray(b'spameggs')
>>> B.decode()
'spameggs'
特定类型的方法
我们以及介绍了字符串类型中的列表操作,下面是对字符串特定的操作。
find方法是子字符串查找操作,返回子字符串第一个字符在字符串的位置,如果没找到则为-1。
>>> S = 'spam'
>>> S.find('pa')
1
replace方法对子字符串进行搜索并替换掉子字符串。
>>> S
'spam'
>>> S.replace('pa', 'XYZ')
'sXYZm'
>>> S
'spam'
这两种方法都不会改变原来的字符串。
以下也是字符串的操作。
通过分隔符将字符串拆分为子字符串:
>>> line = 'aaa,bbb,ccccc,dd'
>>> line.split(',')
['aaa', 'bbb', 'ccccc', 'dd']
大小写变换,测试字符串内容(是否为大写/小写/数字,这里检测是否为大写):
>>> S = 'spam'
>>> S.upper()
'SPAM'
>>> S.isalpha()
True
去掉字符串后的空字符(包括空格' '、换行'\n'、Tab'\t'等等)
>>> line = 'aaa,bbb,ccccc,dd'
>>> line.rstrip() # 这里书本错了,写成line = rstrip()
'aaa,bbb,ccccc,dd'
>>> line.rstrip().split(',')
['aaa', 'bbb', 'ccccc', 'dd']
字符串支持一个叫做格式化的高级替代操作(以下是格式化字符串的三个版本):
>>> '%s, eggs, and %s' % ('spam', 'SPAM!')
'spam, eggs, and SPAM!'
>>> '{0}, eggs, and {1}'.format('spam', 'SPAM!')
'spam, eggs, and SPAM!'
>>> '{}, eggs, and {}'.format('spam', 'SPAM!')
'spam, eggs, and SPAM!'
这部分内容会在后面的章节介绍。
寻求帮助
事实上,字符串类型还有许多方法。我们可以调用dir查看这些方法:
>>> dir(S)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'removeprefix', 'removesuffix', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
注意到像__add__这种带双下划线的方法,它是真正执行字符串拼接的函数(类似于操作符重载)。
>>> S + 'NI!'
'spamNI!'
>>> S.__add__('NI!')
'spamNI!'
我们可以通过help来查询某一个方法的作用是什么:
>>> help(S.replace)
Help on built-in function replace:
replace(old, new, count=-1, /) method of builtins.str instance
Return a copy with all occurrences of substring old replaced by new.
count
Maximum number of occurrences to replace.
-1 (the default value) means replace all occurrences.
If the optional argument count is given, only the first count occurrences are
replaced.
或者对整个类型进行查询(可能不可行):
>>> help(S)
No Python documentation found for 'spam'.
Use help() to get the interactive help utility.
Use help(str) for help on the str class.
字符串编程的其他方式
反斜杠转义序列代表特殊字符,也可以用于十六进制的ASCII码:
>>> S = 'A\nB\tC\x30\x31\x32'
>>> S
'A\nB\tC012'
通过ord查询字符对应的ASCII码:
>>> ord('\n')
10
Python允许字符串包括在单引号或双引号中,也允许多行字符串包含在三个引号中。如果用三个引号表示,那么会在末尾处加上'\n'。
>>> msg = """
... aaa
... bbb'''bbb
... ddd"ddd
... ccc
... """
>>> msg
'\naaa\nbbb\'\'\'bbb\nddd"ddd\nccc\n'
Unicode字符串
Python支持Unicode,以支持其他语言(包括中文)的文本。
在Python3中,基本的str字符串能够处理Unicode;在Python2中,str字符串处理8位的基于字符的字符串,并有一个独特的unicode字符串类型。
>>> 'sp\xc4m'
'spÄm'
一些Unicode码的一个字符大于一个字节。而bytearray类型是一种bytes字符串,相当于Python 2中的str类型。
>>> 'spam'.encode('utf8')
b'spam'
>>> 'spam'.encode('utf16')
b'\xff\xfes\x00p\x00a\x00m\x00'
Python还支持编码非ASCII字符,包括以\x开头、以\u开头的、以\U开头的。
>>> 'sp\xc4\u00c4\U000000c4m'
'spÄÄÄm'
这些值得意义及其使用方式在不同得文本字符串和字节字符串中是不同的:文本字符串包括3.X中的普通字符串和2.X中的unicode字符串;字节字符串包括3.X的bytearray和2.X中的普通字符串。
Python3禁止在没有显式转型的情况下,将普通字符串与字节串混合:
>>> u'x' + b'y'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "bytes") to str
>>> u'x' + 'y'
'xy'
>>> 'x' + b'y'.decode()
'xy'
>>> 'x'.encode() + b'y'
b'xy'
文本文件实现了特定的编码,接受、返回str,但二进制文件接受、返回bytearray。
模式匹配
模式匹配不在Python的内置语言的方法中,我们只能导入模块re:
>>> import re
>>> match = re.match('Hello[ \t]*(.*)world', 'Hello Python world')
>>> match.group(1)
'Python '
它表示,搜索子字符串,它以"Hello"为开始,后面跟着几个制表符或空格,接着任意字符并将其保存在匹配组中,以"world"结尾。
列表
列表是一个任意类型的对象的位置相关的有序集合,并且可变。
序列操作
我们以一个有三个元素的列表为例。
>>> L = [123, 'spam', 1.23]
取长度:
>>> len(L)
3
通过索引取列表中的元素:
>>> L[0]
123
切片:
>>> L[:-1]
[123, 'spam']
与序列相加:
>>> L + [4, 5, 6]
[123, 'spam', 1.23, 4, 5, 6]
数乘:
>>> L * 2
[123, 'spam', 1.23, 123, 'spam', 1.23]
以上操作都不会对列表产生变化。
>>> L
[123, 'spam', 1.23]
特定类型的操作
列表没有固定类型的操作,可以包含不同类型的任意对象。列表也没有固定大小,可以增加、删减元素:
>>> L.append('NI')
>>> L
[123, 'spam', 1.23, 'NI']
>>> L.pop(2)
1.23
>>> L
[123, 'spam', 'NI']
这里,append方法向列表尾部插入一项;pop方法移除给定位置(偏移量)的一项,让列表减小。类似的方法还有:按位置插入insert、按值移除remove、在尾部添加多个元素extend。
由于列表可变,大多数列表的操作都是改变原来的列表,而不是创建一个新列表:
比如,sort对列表元素排序,reverse翻转列表:
>>> M = ['aa', 'bb', 'cc']
>>> M.sort()
>>> M
['aa', 'bb', 'cc']
>>> M.reverse()
>>> M
['cc', 'bb', 'aa']
边界检查
超出列表末尾之外的索引会引发错误:
>>> L
[123, 'spam', 'NI']
>>> L[99]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
>>> L[99] = 1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list assignment index out of range
嵌套
Python的核心数据类型支持任意组合的嵌套,比如,下面是一个嵌套列表的列表:
>>> M = [[1, 2, 3],
... [4, 5, 6],
... [7, 8, 9]]
>>> M
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
我们可以通过多种方法获取元素:
>>> M[1]
[4, 5, 6]
>>> M[1][2]
6
推导
Python还有更高级的操作:列表推导表达式。比如,我们要提取上述嵌套列表的第二列:
>>> col2 = [row[1] for row in M]
>>> col2
[2, 5, 8]
>>> M
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
它通过对序列中每一项运行一个表达式来创建一个新列表,每次一个,从左到右。列表推导编写在方括号中,并且使用了同一个变量名的表达式(这里是row)和循环结构(for ... in ...)组成。
这种列表推导可以更复杂,注意第二个列表推导包含了if,即筛选操作:
>>> [row[1] + 1 for row in M]
[3, 6, 9]
>>> [row[1] for row in M if row[1] % 2 == 0]
[2, 8]
列表能够在任何可迭代对象上进行迭代。
>>> diag = [M[i][i] for i in [0, 1, 2]]
>>> diag
[1, 5, 9]
>>> doubles = [c * 2 for c in 'spam']
>>> doubles
['ss', 'pp', 'aa', 'mm']
range可以生成整数数列,对应range(i, j, k)而言,i默认为0,k默认为1,表示从i开始,到j为止(不包括j)的从小到大整数序列,k为相邻两个整数的差。要将这些整数数列变为列表,需要用到list()方法。
>>> list(range(4))
[0, 1, 2, 3]
>>> list(range(-6, 7, 2))
[-6, -4, -2, 0, 2, 4, 6]
推导式不仅仅可以用在列表中,当推导式在圆括号中,它表示生成器。生成器会自我迭代,比如,对其应用next方法,它会从第一个元素开始,给出下一个项。内置的sum方法求列表中元素的和。
>>> G = (sum(row) for row in M)
>>> next(G)
6
>>> next(G)
15
>>> next(G)
24
内置的map方法也可以通过一个函数,对列表中的每个项生成新的列表。
>>> list(map(sum, M))
[6, 15, 24]
推导式也可以用在之后讲的集合、字典里。
字典
字典是一种映射,它通过键(key)而不是列表中的偏移存储对象。字典将键映射到相应的值上。
映射操作
字典编写在大括号中,包含一系列的键:值对:
>>> D = {'food': 'Spam', 'quantity': 4, 'color': 'pink'}
我们可以通过键作为索引访问、修改值。
>>> D['food']
'Spam'
>>> D['quantity'] += 1
>>> D
{'food': 'Spam', 'quantity': 5, 'color': 'pink'}
由于字典通过键访问元素,因此它没有禁止边界外的赋值(但禁止边界外的访问),而是为其添加一对键-值对。
>>> D = {}
>>> D['name'] = 'Bob'
>>> D['job'] = 'dev'
>>> D['age'] = 40
>>> D
{'name': 'Bob', 'job': 'dev', 'age': 40}
我们也可以通过dict函数传递键值参数对,dict中的参数可以是:key1=value1, key2=value2, ...,也可以是zip函数,其中后者的zip的参数是键的列表和值的列表。
>>> bob1 = dict(name='Bob', job='dev', age=40)
>>> bob1
{'name': 'Bob', 'job': 'dev', 'age': 40}
>>> bob2 = dict(zip(['name', 'job', 'age'], ['Bob', 'dev', 40]))
>>> bob2
{'name': 'Bob', 'job': 'dev', 'age': 40}
重访嵌套
有时候要记录的信息比较复杂,我们可以将所有内容编写进一个常量:
>>> rec = {'name': {'first': 'Bob', 'last': 'Smith'},
... 'job': ['dev', 'mgr'],
... 'age': 40.5}
像之前访问矩阵M一样,我们可以访问这个结构的组件,并对这些组件其进行修改:
>>> rec['name']
{'first': 'Bob', 'last': 'Smith'}
>>> rec['name']['last']
'Smith'
>>> rec['job'].append('janitor')
>>> rec
{'name': {'first': 'Bob', 'last': 'Smith'}, 'job': ['dev', 'mgr', 'janitor'], 'age': 40.5}
我们可以看出,Python允许轻松地建立复杂的数据结构,这是C/C++所不具备的。而且,在最后一次引用对象时,Python会自动地回收这个变量占有的空间(而不需要我们手动操作)。
不存在的键:if测试
Python不允许访问不存在的键。
>>> D = {'a': 1, 'b': 2, 'c': 3}
>>> D
{'a': 1, 'b': 2, 'c': 3}
>>> D['e'] = 99
>>> D
{'a': 1, 'b': 2, 'c': 3, 'e': 99}
>>> D['f']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'f'
我们可以在访问之前进行测试(直接写表达式,或者用if。在if语句中,如果后面表达式的值为真,则执行子句,否则不执行):
>>> 'f' in D
False
>>> if not 'f' in D:
... print('missing')
...
missing
我们也可以通过get方法和if-else语句获取不存在的键。if-else的语法是:<A> if <B> else <C>,表示如果表达式<B>为真,则取值<A>,否则取值<C>。
>>> value = D.get('x', 0)
>>> value
0
>>> value = D['x'] if 'x' in D else 0
>>> value
0
键的排序:for循环
我们可以看到,键的排序与我们初始化字典的排序可能不一样。我们可以通过keys方法收集一个键的列表,并使用sort对其进行排序,这样我们可以按照键的顺序访问值。
>>> D = {'d': 1, 'a': 2, 'c': 3, 'e': 4, 'b': 5}
>>> Ks = list(D.keys())
>>> Ks
['d', 'a', 'c', 'e', 'b']
>>> Ks.sort()
>>> Ks
['a', 'b', 'c', 'd', 'e']
>>> for Key in Ks:
... print(Key, '=>', D[Key])
...
a => 2
b => 5
c => 3
d => 1
e => 4
也可以通过sorted对字典的键排序:
>>> for key in sorted(D):
... print(key, '=>', D[key])
...
a => 2
b => 5
c => 3
d => 1
e => 4
在这里,for用于遍历序列(包括字符串、列表)中的所有元素,并对每个元素进行一些操作。
类似的循环语句为while,当while后面的表达式为真,则执行,否则跳过。这两个循环结构后面会说到。
迭代与优化
事实上,for可以作用于遵守迭代协议的任意可迭代对象(如列表、字符串、range)。可迭代对象是在内存中物理存储/“虚拟”的序列。它们的共同特点是:相应next之前先用一个对象对iter内置函数做出相应,在结束时触发异常。
生成器推导表达式就是这样的:它的值通过迭代工具在被请求时生成。迭代协议会在后面中提到。
总之,任何一个从左到右扫描的Python工具(如for)都使用迭代协议。
使用不同的方法对列表实行同样的操作,会使运行时间不同。
元组
元组可以看作是不可修改的序列,它编写在圆括号中。
>>> T = (1, 2)
>>> T
(1, 2)
由于元组也是序列,因此他也智齿序列操作:取长度、加号拼接、数乘、索引、切片等等。
为什么用到元组
元组的不可变性提供约束。
文件
文件是Python代码调用在电脑中文件的接口,用于读取/写入任意形式的文件。要创建文件对象,就要使用open函数,open的第一个参数是外部文件的文件名,第二个参数是处理方式(如'w'为写文件)。
>>> f = open('data.txt', 'w')
>>> f.write('Hello\n')
6
>>> f.write('world\n')
6
>>> f.close()
这样就在当前文件夹下创建文件并用write写入文本。
要读出文件,可以用'r'读取,并用read方法将文件内容读到一个字符串。
>>> f.close()
>>> f = open('data.txt')
>>> text = f.read()
>>> text
'Hello\nworld\n'
文件类型还有许多方法,比如readline(每次读取一行)。
以下是文件方法的列表:
>>> dir(f)
['_CHUNK_SIZE', '__class__', '__del__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_checkClosed', '_checkReadable', '_checkSeekable', '_checkWritable', '_finalizing', 'buffer', 'close', 'closed', 'detach', 'encoding', 'errors', 'fileno', 'flush', 'isatty', 'line_buffering', 'mode', 'name', 'newlines', 'read', 'readable', 'readline', 'readlines', 'reconfigure', 'seek', 'seekable', 'tell', 'truncate', 'writable', 'write', 'write_through', 'writelines']
二进制字节文件
在Python3.X中,文本文件把内容显示为正常的str字符串,在写入/读取时自动执行Unicode解码和编码;二进制文件把内容显示为一个特定的字节字符串(bytearray)。
二进制文件有许多应用,比如,我们可以将自定义的结构类型(Python中,用到struct模块)打包到二进制文件中,也可以从二进制文件中解码。
将struct打包到二进制文件中:
>>> import struct
>>> packed = struct.pack('>i4sh', 7, b'spam', 8)
>>> packed
b'\x00\x00\x00\x07spam\x00\x08'
>>>
>>> file = open('data.bin', 'wb')
>>> file.write(packed)
10
>>> file.close()
对二进制文件的解码过程,实际上和上述过程相互对称:
>>> data = open('data.bin', 'rb').read()
>>> data
b'\x00\x00\x00\x07spam\x00\x08'
>>> list(data)
[0, 0, 0, 7, 115, 112, 97, 109, 0, 8]
>>> struct.unpack('>i4sh', data)
(7, b'spam', 8)
Unicode文本文件
为了访问非ASCII编码的Unicode文本,我们直接传入一个编码名参数。此时Python文件对象采用指定的编码/解码方式。
>>> S = 'sp\xc4m'
>>> file = open('unidata.txt', 'w', encoding = 'utf-8')
>>> file.write(S)
4
>>> file.close()
>>> text = open('unidata.txt', encoding = 'utf-8').read()
>>> text
'spÄm'
>>> len(text)
4
我们也可以查看文件内容的二进制形式:
>>> raw = open('unidata.txt', 'rb').read()
>>> raw
b'sp\xc3\x84m'
>>> len(raw)
5
只要提供了正确的编码方式名称,文件中不同类型的字节可以被解码成相同的字符串。
>>> text.encode('latin-1')
b'sp\xc4m'
>>> text.encode('utf-16')
b'\xff\xfes\x00p\x00\xc4\x00m\x00'
>>> len(text.encode('latin-1'))
4
>>> len(text.encode('utf-16'))
10
>>> b'\xff\xfes\x00p\x00\xc4\x00m\x00'.decode('utf-16')
'spÄm'
在Python2.X中,Unicode字符串被编码成一个以u开头的形式。
其他类文件工具
管道、先进先出序列、套接字、按键值访问的文件等等。
其他核心类型
集合
集合不是序列,它是无序的,可以在通过set创建,也可以在大括号中列出元素来创建。
>>> X = set('spam')
>>> Y = {'h', 'a', 'm'}
>>> X
{'p', 's', 'a', 'm'}
>>> Y
{'m', 'h', 'a'}
集合的操作:|并集,&交集,-差集,>是否包含。
>>> X & Y
{'m', 'a'}
>>> X | Y
{'m', 'a', 'h', 'p', 's'}
>>> X - Y
{'p', 's'}
>>> X > Y
False
集合的性质:元素不重复,因此我们可以过滤重复对象、分离差异、进行非顺序等价判断。
>>> list(set([1, 2, 1, 2, 3]))
[1, 2, 3]
>>> set('spam') - set('ham')
{'p', 's'}
>>> set('spam') == set('asmp')
True
新的数值类型
十进制数(固定精度浮点数)
>>> import decimal
>>> d = decimal.Decimal('3.141')
>>> d + 1
Decimal('4.141')
>>> decimal.getcontext().prec = 2
>>> decimal.Decimal('1.00') / decimal.Decimal('3.00')
Decimal('0.33')
分数
>>> from fractions import Fraction
>>> f = Fraction(2, 3)
>>> f + 1
Fraction(5, 3)
>>> f + Fraction(1, 2)
Fraction(7, 6)
布尔值、None
>>> 1 > 2
False
>>> 2 > 1
True
>>> X = None
>>> X
>>>
如何破坏代码的灵活性
内置函数type返回的type对象是一个能够告知其他对象类型的对象。在Python3.X中,该对象和class合并。
>>> type(L)
<class 'list'>
>>> type(type(L))
<class 'type'>
应用:检查对象类型。
>>> type(L) == type([])
True
>>> type(L) == list
True
>>> isinstance(L, list)
True
检验特定的类型,实际上破坏了Python的灵活性。
用户定义的类
我们可以定义Python核心数据类型中的类。比方说,我们定义一个“员工”类型,它有两个属性:name和pay,以及两个方法lastName和giveRaise。
>>> class Worker:
def __init__(self, name, pay):
self.name = name
self.pay = pay
def lastName(self):
return self.name.split()[-1]
def giveRaise(self, percent):
self.pay *= (1.0 + percent)
...
然后我们可以创建新类的实例,调用类方法,获取被处理的实例。
>>> bob = Worker('Bob Smith', 50000)
>>> sue = Worker('Sue Smith', 60000)
>>> bob.lastName()
'Smith'
>>> sue.pay()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not callable
>>> sue.pay
60000
剩余的内容
本章没有介绍的类型:与程序执行相关的对象(函数、模块等),偏应用的对象(文本模式、网络连接等)。