DeepMind详解AI打《星际争霸2》:靠战略水平 而非手速
导语:
北京时间今日凌晨,谷歌母公司Alphabet旗下人工智能公司DeepMind与暴雪联合直播最新AI程序“AlphaStar”与《星际争霸2》职业选手比赛实况录像,并让AlphaStar和人类选手现场进行一盘比赛。AlphaStar在实况录像中的10场均获胜,而在与人类选手现场比赛时不敌人类,因此最终总成绩定格在10-1。

AlphaStar与《星际争霸2》比赛直播
在直播开始之际,DeepMind在官方博客上详细解释了打造AlphaStar的全过程。DeepMind团队认为,尽管《星际争霸》只是一款游戏,但不失为一款较为复杂的游戏。AlphaStar背后的技术可以用来解决其他的问题。在天气预报、气候建模、语言理解等等领域,以及研究开发安全稳定的人工智能方面,都会有很大帮助。
以下为DeepMind文章主要内容:
在过去几十年里,人类一直用游戏测试评估AI系统。随着技术的进步,科学界寻找复杂的游戏,深入研究智力的方方面面,看看如何才能解决科学问题和现实问题。许多人认为,《星际争霸》是最有挑战的RTS(实时战略)游戏之一,也是有史以来电子竞技领域最古老的游戏之一,它是AI研究的“大挑战”。
现在我们推出一个可以操作《星际争霸2》游戏的程序,名叫AlphaStar,它是一个AI系统,成功打败了世界顶级职业玩家。12月19日,我们举行了测试比赛,AlphaStar打败了Team Liquid战队的Grzegorz "MaNa" Komincz,他是世界最强的职业玩家之一,以5比0获胜,之前AlphaStar已经打败同队的Dario “TLO” Wünsch。比赛是按照职业标准进行的,使用天梯地图,没有任何游戏限制。
在游戏领域,我们已经取得一系列成功,比如Atari、Mario、《雷神之锤3:竞技场》多人夺旗、Dota 2。但是AI技术还是无法应付复杂的《星际争霸》。想拿到好结果,要么是对游戏系统进行重大调整,对游戏规则进行限制,赋予系统超人一般的能力,或者让它玩一些简单地图。即使做了修改,也没有系统可以与职业玩家一较高下。AlphaStar不一样,它玩的是完整版《星际争霸2》,用深度神经网络操作,网络已经用原始游戏数据训练过,通过监督式学习和强化式学习来训练。
《星际争霸》游戏的挑战
《星际争霸2》由暴雪娱乐制作,是一款单位众多的多层次宇宙科幻游戏,在设计上非常挑战人工智能。与前作一样,《星际争霸2》也是游戏史上最宏大和成功的游戏,已有20余年的电竞联赛历史。
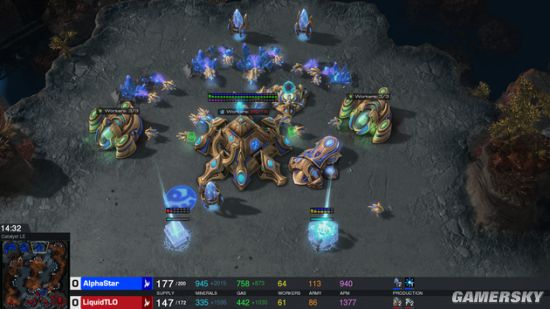
该游戏玩法众多,但电竞中最常见的是1对1对战,五局三胜制。开始时,玩家从人类、星灵和异虫三个种族中人选一个进行操作,每个种族都有独特的特点、能力(机关专业选手会专注于一个种族)。开局时,每个玩家都有一些“农民”来采集资源和建造建筑,解锁新科技。这也让玩家可以收集新的资源,建造更复杂的基地和建筑,研发新科技以胜过对手。要取得胜利,玩家必须仔细平衡宏观经济管理,即宏观经济,和每个单位的控制,即微操。
这就需要平衡短期和长期目标,还要应对意外情况,整个系统因而经常变得脆弱僵硬。处理这些问题需要在下列若干人工智能领域解决挑战,取得突破:
- 游戏理论:《星际争霸》是个游戏,就想剪刀石头布一样,没有单一最佳战略。因此人工智能训练过程中需不断探索和扩展最战略知识前沿。
- 瑕疵信息:不同于国际象棋或围棋那种一览无余的状态,星际玩家无法直接观察到重要信息,必须积极探索“探路”。
- 长期规划:和许多现实世界中的问题并非是从“因”立即生“果”一样,游戏是可以从任何一个地方开始,需要1个小时时间出结果,这意味着在游戏开始时的行动可能在很长一段时间不会有收效。
- 即时性:不像传统桌面游戏,玩家轮流行动,星际玩家必须在游戏时间内持续排兵布阵。
- 庞大的行动空间:要同时控制上百个单位及建筑,这就导致了大量的可能性,行动是分级别的,可以被修改和扩张。我们将游戏参数化后,每个时间步骤平均约有10到26个合理行为。
由于上述的大量挑战,《星际争霸》成为了人工智能研究中的“大挑战”。自从2009年《母巢之战》应用参数界面问世后,围绕《星际争霸》和《星际争霸2》开展了众多人工智能竞赛。

AlphaStar与MaNa的第二场比赛可视化动图。人工智能的视角,原始观测输入神经网络,神经网络内部活动,一些人工智能考虑可采取的行动,如单击哪里或在哪里建造,以及预测结果。MaNa的视角也在其中,但人工智能看不见他的视角。
AlphaStar如何观察游戏以及玩游戏的
职业玩家TLO和MaNa的APM可以达到数百,现有机器人高出很多,它们可以独立控制每一个单位,持续维持几千甚至几万的APM。
对决TLO和MaNa时,AlphaStar的平均APM约为280,比职业玩家低,但它的动作更精准一些。为什么APM会低一些?主要是因为AlphaStar是用录像训练的,因此它会模拟人类玩法。还有,AlphaStar在观察和行动之间平均会有350ms的延迟。

AlphaStar在APM和延迟方面与人类玩家的比较
对决时,AlphaStar借助原始界面与《星际争霸》游戏引擎交流,也就是说,它可以直接观察地图上的我方单位和敌方可见单位,不需要移动摄像头。如果是人类玩家,注意力有限,必须调整摄像头,让它瞄准应该关注的地方。分析AlphaStar游戏能发现,它有一个隐藏的注意力焦点。平均来说,游戏代理每分钟会切换环境约30次,和MaNa、TLO的频率差不多。
比赛之后,我们开发了第二版AlphaStar。和人类玩家一样,这个版本的AlphaStar需要确定何时移动摄像头,应该瞄准哪里,对于屏幕信息,AI的感知受到限制,动作位置也受到可视区域的限制。

AlphaStar在使用原始界面和控制摄像头时,其MMR数据比较
我们训练了两个代理,一个使用原始界面,一个学着控制摄像头。两个代理最开始时都用人类数据进行监督式和增强式训练。使用摄像头界面的AlphaStar几乎和使用原始界面的AlphaStar一样强大,在内部排行榜上达到7000 MMR(天梯积分)。在演示比赛中,MaNa用摄像头界面打败了原型版AlphaStar,但它只训练了7天。我们希望能在近期内评估精炼的摄像头界面AlphaStar。
事实证明,AlphaStar与MaNa和TLO对决时之所以占据上风,主要是因为它的宏观战略、微观战略决策能力更强,靠的不是超级点击率、超快响应时间、原始界面。
AlphaStar与职业玩家的较量
《星际争霸》这款游戏包含三大外星种族:人类、星灵和异虫。玩家可以从中选择一个族类开始游戏。目前,我们仅针对星灵一族对AlphaStar进行了训练,以减少训练时间和差异。值得一提的是,相同的训练模式可以也应用到其他两个种族的训练上。经过训练的代理可以在《星际争霸2》(v4.6.2)的CatalystLE天梯地图中,实现星灵族与星灵族的较量。
为评估AlphaStar的表现,团队最初测试了代理对弈玩家TLO(一位顶级职业异虫玩家和大师级星灵玩家)的表现。AlphaStar以5:0的战绩获胜,对弈过程中AlphaStar灵活使用了大量单位和建造命令。
“代理的强大水平令我惊讶,”TLO表示,“AlphaStar将众所周知的策略融会贯通。代理运用的策略,也是我之前从未想到过的。也就是说对于这个游戏,我们或许还有很多玩法没有探索出来。”
对我们的代理继续训练了一周之后,我们让代理与另一名玩家MaNa进行较量。MaNa不仅是世界顶级的《星际争霸2》玩家,也是排名前十的最擅长使用星灵族的玩家之一。AlphaStar再次以5:0的战绩获胜,体现了强大的微观和宏观策略技能。
“AlphaStar在每局游戏中采用的操作和不同策略十分令人印象深刻,近乎人类选手般的游戏策略出乎我的意料,”MaNa说,“我这才意识到,自己之前的策略过分依赖失误和人类反应力,因此这场比赛让我对游戏有了全新的认识。我们很期待未来的无限可能。”
AlphaStar和其他复杂问题

打造AlphaStar的团队
尽管《星际争霸》只是一款游戏,但不失为一款较为复杂的游戏。我们认为,AlphaStar背后的技术可以用来解决其他的问题。比如,它的神经网络架构可以基于不完美的信息,对长时间序列中的可能行为进行建模——因为一局游戏通常长达1个多小时且涉及成千上万次动作。《星际争霸》的每一帧都是输入的一个动作,神经网络在每一帧动作之后都会对接下来的游戏发展进行预测。根据较长的数据序列进行复杂的预测,是很多现实世界挑战中的基本问题,比如天气预报、气候建模、语言理解等等。AlphaStar项目的学习和发展对帮助这些领域取得显著进展的可能性,值得期待。
我们还认为,团队的一些训练方法或可有助于研究开发安全稳定的人工智能。人工智能的一大挑战是,系统出错的方式各种各样。先前,《星际争霸》的职业玩家可以通过各种新颖方式诱导代理失误,轻易击败AI系统。AlphaStar采用的基于league模式的创新训练方式,可以找到最可靠、最不容易出错的方式。这一创新方式对改进整体AI系统(尤其是在诸如能源等安全至上、且解决复杂边缘案例十分关键的领域)的安全性和稳定性的前景亦值得期待。
实现最高水平的《星际争霸》对弈代表了人工智能在有史以来最复杂电子游戏中取得的重大突破。我们相信,这些进展,以及AlphaZero和AlphaFold等项目的其他进展,代表着我们在创建人工智能系统之路上的又一大前进。未来终有一日,智能系统将帮助人类解锁解决世界上一些最重要、最基本之科学问题的创新方式。
热门相关:大王饶命 房产大亨 都市之无敌仙帝 蜜爱甜妻:老公,请亲亲! 房产大亨