bash shell 无法使用 perl 正则

哈喽大家好,我是咸鱼。今天跟大家分享一个关于正则表达式的案例,希望能够对你有所帮助
案例现象
前几天有一个小伙伴在群里求助,说他这个 shell 脚本有问题,让大家帮忙看看


可以看到,这个脚本首先将目标文本文件的名字当作该脚本的第一个参数($1)传递进去,然后查看这个文本文件的内容(cat $1),并将内容赋值给 firstLine 变量
接着对文本内容的每一行进行遍历然后正则匹配,并将匹配到的内容绿色高亮输出出来,不匹配的内容红色高亮输出,并显示提示信息
其中,正则匹配表达式^\[(\d+)+\].+$ 匹配一组方括号 [ ] ,方括号后还有内容且方括号之间由数字组成:
-
第一部分:
^\[(\d+)+\]-
^\[ 表示以 [ 开头,\ 为转义字符
-
(\d+) +表示匹配多个数字,\ 为转义字符
-
\] 表示匹配右方括号,\ 为转义字符
-
-
第二部分:
.+$-
.+ 表示匹配任意字符
-
$ 表示结尾
-
因此上面的正则表达式可以匹配:[123] this is a test line 这样的内容
我们来执行一下这个脚本,首先看下目标文件内容


由脚本的执行结果得知,文本文件中的内容均没有匹配到
奇怪,正则表达式写的没有问题,为啥脚本里面的正则不匹配呢
定位问题
在解决这个问题之前,我们先来了解一下正则表达式(Regular Expression)
什么是正则表达式
正则表达式是一种通用的文本匹配工具
它允许你使用特定的语法来描述和匹配文本中的模式,可以说是描述文本内容组成规律的表示方式
正则表达式的发展史
正则表达式的起源,可以追溯到早期神经系统如何工作的研究
在 20 世纪 40 年代,有两位神经生理学家(Warren McCulloch 和 Walter Pitts),研究出了一种用数学方式来描述神经网络的方法
1956 年,一位数学家(Stephen Kleene)发表了一篇标题为《神经网络事件表示法和有穷自动机》的论文。这篇论文描述了一种叫做「正则集合(Regular Sets)」的符号
随后,大名鼎鼎的 Unix 之父 Ken Thompson 于1968年发表了文章《正则表达式搜索算法》,并且将正则引入了自己开发的编辑器 qed,以及之后的编辑器 ed 中,然后又移植到了大名鼎鼎的文本搜索工具 grep 中
自此,正则表达式被广泛应用到 Unix 系统或类 Unix 系统 (如 macOS、Linux) 的各种工具中,但是百家争鸣的场面使得各种语言和工具中的正则虽然功能大致类似,但仍然有不少细微差别
正则表达式两种流派之 POSIX 流派
上个世纪八十年代,POSIX (Portable Operating System Interface) 标准公诸于世,它制定了不同的操作系统都需要遵守的一套规则
其中就包括正则表达式的规则,遵循 POSIX 标准的正则表达式,称为 POSIX 派系正则表达式
POSIX 规范定义了正则表达式的两种标准
-
基本正则表达式 BRE(Basic Regular Expression)
-
不支持量词问号和加号,也不支持多选分支结构管道符
-
-
扩展正则表达式 ERE(Extended Regular Expression)
-
BRE 在使用花括号,圆括号时要转义才能表示特殊含义。由于BRE 功能不够强大,导致了 ERE 扩展标准的诞生
-
像 Unix 系统或类 Unix 系统上的大部分工具,如 grep 、sed 、awk 等都属于 POSIX 派系
BRE 标准和 ERE 标准
早期 BRE 与 ERE 标准的区别主要在于,BRE 标准不支持量词问号和加号,也不支持多选分支结构管道符
BRE 标准在使用花括号,圆括号时要转义才能表示特殊含义。BRE 标准用起来这么不爽,于是有了 ERE 标准,在使用花括号,圆括号时不需要转义了,还支持了问号、加号和多选分支
我们现在使用的 Linux 发行版,大多都集成了 GNU 套件。GNU 在实现 POSIX 标准时,做了一定的扩展,主要有以下三点扩展
-
GNU BRE 支持了
+、?,但转义了才表示特殊含义,即需要用\+、\?表示 -
GNU BRE 支持管道符多选分支结构,同样需要转义,即用
\|表示 -
GNU ERE 也支持使用反引用,和 BRE 一样,使用
\1、\2…\9表示

POSIX 字符组
POSIX 流派还有一个特殊的地方,就是有自己的字符组,叫 POSIX 字符组

正则表达式两种流派之 PCRE 流派
除了 POSIX 标准外,还有一个 Perl 分支,随着 Perl 语言的发展,Perl 语言中的正则表达式功能越来越强悍,为了把 Perl 语言中正则的功能移植到其他语言中,我们熟知的 PCRE 就诞生了
PCRE 是一个兼容 Perl 语言正则表达式的解析引擎,是由 Philip Hazel 开发的,为很多现代语言和工具所普遍使用
除了 Unix 上的工具遵循 POSIX 标准,PCRE 现已成为其他大部分语言和工具隐然遵循的标准
目前大部分常用编程语言都是源于 PCRE 标准,这个流派显著特征是有 \d、\w、\s 这类字符组简记方式
在 UNIX/LINUX 系统里 PCRE 流派与 POSIX 流派的对比,可以参考下表

在 Linux 中使用正则
在遵循 POSIX 规范的 UNIX/Linux 系统上,按照 BRE 标准 实现的有 grep、sed 和 vi/vim 等
而按照 ERE 标准 实现的有 egrep、awk 等
但是在 Linux 的 bash 中,原生的正则表达式语法是基于 POSIX 标准的(支持 ERE 标准和 BRE 标准),不直接支持 PCRE 标准
脚本中的正则表达式出现了 \d ,而 \d 是属于 PCRE 标准,而 Linux Bash (基于 POSIX 标准)不支持 PCRE 标准,所以匹配不到
3.解决问题
知道了 Linux Bash 不支持 PCRE 标准,我们将脚本中的正则表达式由 PCRE 标准改成 ERE 标准即可
-
改成 ERE 标准

- 修改脚本:在脚本里面使用 grep 进行正则匹配过滤
-
-P 参数表示支持 PCRE 正则
-
-v 参数表示取反操作
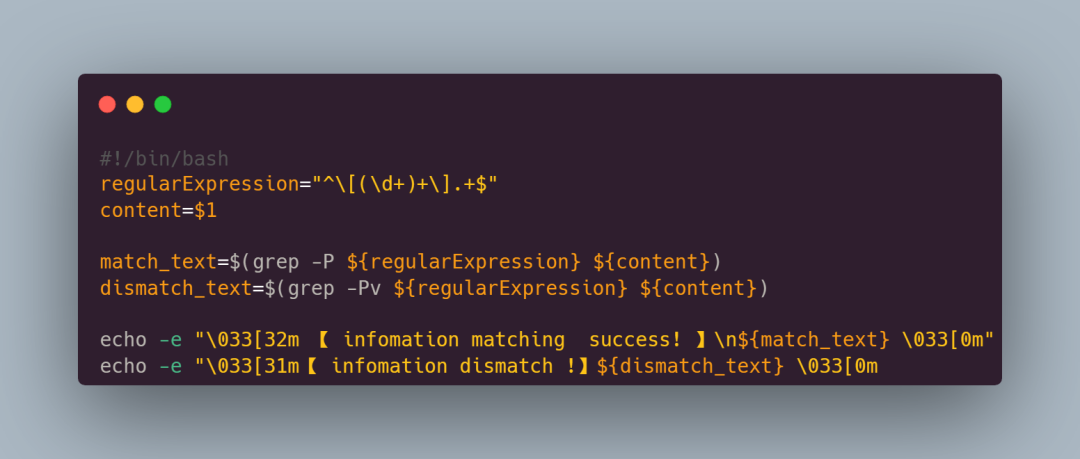
看下执行结果

参考链接:
-
https://zq99299.github.io/note-book/regular/03/03.html#正则表达式简史
-
https://askubuntu.com/questions/1143710/regex-with-d-doesn-t-work-in-if-else-statement-with