[apue] 进程控制那些事儿
进程标识
在介绍进程的创建、启动与终止之前,首先了解一下进程的唯一标识——进程 ID,它是一个非负整数,在系统范围内唯一,不过这种唯一是相对的,当一个进程消亡后,它的 ID 可能被重用。不过大多数 Unix 系统实现延迟重用算法,防止将新进程误认为是使用同一 ID 的某个已终止的进程,下面这个例子展示了这一点:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <time.h>
#include <set>
int main (int argc, char *argv[])
{
std::set<pid_t> pids;
pid_t pid = getpid();
time_t start = time(NULL);
pids.insert(pid);
while (true)
{
if ((pid = fork ()) < 0)
{
printf ("fork error\n");
return 1;
}
else if (pid == 0)
{
printf ("[%u] child running\n", getpid());
break;
}
else
{
printf ("fork and exec child %u\n", pid);
int status = 0;
pid = wait(&status);
printf ("wait child %u return %d\n", pid, status);
if (pids.find (pid) == pids.end())
{
pids.insert(pid);
}
else
{
time_t end = time(NULL);
printf ("duplicated pid find: %u, total %lu, elapse %lu\n", pid, pids.size(), end-start);
break;
}
}
}
exit (0);
}上面的程序制造了一个进程 ID 复用的场景:父进程不断创建子进程,将它的进程 ID 保存在 set 容器中,并将每次新创建的 pid 与容器中已有的进行对比,如果发现有重复的 pid,则打印一条消息退出循环,下面是程序输出日志:
> ./pid
fork and exec child 18687
[18687] child running
wait child 18687 return 0
fork and exec child 18688
[18688] child running
wait child 18688 return 0
fork and exec child 18689
...
wait child 18683 return 0
fork and exec child 18684
[18684] child running
wait child 18684 return 0
fork and exec child 18685
[18685] child running
wait child 18685 return 0
fork and exec child 18687
[18687] child running
wait child 18687 return 0
duplicated pid find: 18687, total 31930, elapse 8在大约创建了 3W 个进程后,进程 ID 终于复用了,整个耗时大约 8 秒左右,可见在频繁创建进程的场景中,进程 ID 被复用的间隔还是很快的,如果依赖进程 ID 的唯一性做一些记录的话,还是要小心,例如使用进程 ID 做为文件名,最好是加上时间戳等其它维度以确保唯一性。
另外一个有趣的现象是,进程 ID 重复时,刚好是第一个子进程的进程 ID,看起来这个进程 ID 分配是个周而复始的过程,在涨到一定数量后会回卷,追踪中间的日志,发现有以下输出:
...
[32765] child running
wait child 32765 return 0
fork and exec child 32766
[32766] child running
wait child 32766 return 0
fork and exec child 32767
[32767] child running
wait child 32767 return 0
fork and exec child 300
[300] child running
wait child 300 return 0
fork and exec child 313
[313] child running
wait child 313 return 0
fork and exec child 314
[314] child running
wait child 314 return 0
...看起来最大达到 32767 (SHORT_MAX) 后就开始回卷了,这比我想象的要早,毕竟 pid_t 类型为 4 字节整型:
sizeof (pid_t) = 4最大可以达到 2147483647,这也许是出于某种向后兼容考虑吧。在 macOS 上这个过程略长一些:
> ./pid
fork and exec child 12629
[12629] child running
wait child 12629 return 0
fork and exec child 12630
[12630] child running
wait child 12630 return 0
fork and exec child 12631
[12631] child running
wait child 12631 return 0
...
[12626] child running
wait child 12626 return 0
fork and exec child 12627
[12627] child running
wait child 12627 return 0
fork and exec child 12629
[12629] child running
wait child 12629 return 0
duplicated pid find: 12629, total 99420, elapse 69总共产生了不到 10W 个 pid,历时一分多钟,看起来要比 linux 做的好一点。查看中间日志,pid 也发生了回卷:
...
fork and exec child 99996
[99996] child running
wait child 99996 return 0
fork and exec child 99997
[99997] child running
wait child 99997 return 0
fork and exec child 99998
[99998] child running
wait child 99998 return 0
fork and exec child 100
[100] child running
wait child 100 return 0
fork and exec child 102
[102] child running
wait child 102 return 0
fork and exec child 103
[103] child running
wait child 103 return 0
...回卷点是 99999,emmmm 有意思,会不会是乔布斯定的,哈哈。
虽然进程 ID 的合法范围是 [0~INT_MAX],但实际上前几个进程 ID 会被系统占用:
- 0: swapper 进程 (调度)
- 1: init 进程 (用户态)
- …
其中 ID=0 的通常是调度进程,也称为交换进程,是内核的一部分,并不执行任何磁盘上的程序,因此也被称为系统进程;ID=1 的通常是 init 进程,在自举过程结束时由内核调用,该程序的程序文件在 UNIX 早期版本中是 /sbin/init,不过在我的测试机 CentOS 上是 /usr/lib/systemd/systemd:
> ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Oct24 ? 00:00:19 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0 0 Oct24 ? 00:00:00 [kthreadd]
root 4 2 0 Oct24 ? 00:00:00 [kworker/0:0H]
root 6 2 0 Oct24 ? 00:00:01 [ksoftirqd/0]
root 7 2 0 Oct24 ? 00:00:01 [migration/0]
root 8 2 0 Oct24 ? 00:00:00 [rcu_bh]
...查看文件系统:
> ls -lh /sbin/init
lrwxrwxrwx. 1 root root 22 Sep 7 2022 /sbin/init -> ../lib/systemd/systemd就是个软链接,其实是一回事。在 macOS 又略有不同,
> ps -ef
UID PID PPID C STIME TTY TIME CMD
0 1 0 0 3:34PM ?? 0:15.45 /sbin/launchd
0 74 1 0 3:34PM ?? 0:00.89 /usr/sbin/syslogd
0 75 1 0 3:34PM ?? 0:01.42 /usr/libexec/UserEventAgent (System)
...为 launched。这里将进程 ID=1 的统称为 init 进程,它通常读取与系统有关的初始化文件,并将系统引导到一个状态 (e.g. 多用户),且不会终止,虽然运行在用户态,但具有超级用户权限。在孤儿进程场景下,它负责做缺省的父进程,关于这一点可以参考后面 "进程终止" 一节。正因为进程 ID 0 永远不可能分配给用户进程,所以它可以用作接口的临界值,就如上面例子中 fork 所做的那样,关于 fork 的详细说明可以参考后面 "进程创建" 一节。
各种进程 ID 通过下面的接口返回:
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void); // process ID
pid_t getppid(void); // parent process ID
uid_t getuid(void); // user ID
uid_t geteuid(void); // effect user ID
gid_t getgid(void); // group ID
gid_t getegid(void); // effect group ID各个接口返回的 ID 已在注释中说明。进程是动态的程序文件、文件又由进程生成,而它们都受系统中用户和组的辖制,用户态进程必然属于某个用户和组,就像文件一样,关于这一点,可以参考这篇《[apue] linux 文件访问权限那些事儿 》。再说深入一点,用户 ID、组 ID 标识的是执行进程的用户;有效用户 ID、有效组 ID 则标识了进程程序文件通过 set-user-id、set-group-id 标识指定的用户,一般用作权限"后门";还有 saved-user-id、saved-group-id,则用来恢复更改 uid、gid 之前的身份。关于两组三种 ID 之间的关系、相互如何转换及这样做的目的,可以参考后面 "更改用户 ID 和组 ID" 一节。
进程创建
Unix 系统的进程主要依赖 fork 创建:
#include <unistd.h>
pid_t fork(void);fork 本意为分叉,像一条路突然分开变成两条一样,调用 fork 后会裂变出两个进程,新进程具有和原进程完全相同的环境,包括执行堆栈。即在调用 fork 处会产生两次返回,一次是在父进程,一次是在子进程。
但是父、子进程的返回值却大不相同,父进程返回的是成功创建的子进程 ID;子进程返回的是 0。通过上一节对进程 ID 的说明,0 是一个合法但不会分配给用户进程的 ID,这里作为区分父子进程的关键,从而执行不同的逻辑。父进程 fork 返回子进程的 pid 也是必要的,因为目前没有一种接口可以返回父进程所有的子进程 ID,通过 fork 返回值父进程就可以得到子进程的 ID;而反过来,子进程可以通过 get_ppid 轻松获取父进程 ID,所以不需要在 fork 处返回,且为了区别于父进程中的 fork 返回,这里有必要返回 0 来快速标识自己是子进程 (通过记录父进程 ID 等办法也可以标识,但是明显不如这种来得简洁)。
int pid = fork();
if (pid < 0)
{
// error
exit(1);
}
else if (pid == 0)
{
// child
printf ("%d spawn from %d\n", getpid(), getppid());
}
else
{
// parent
sleep (1);
printf ("%d create %d\n", getpid(), pid);
}新建的子进程具有和父进程完全相同的数据空间、堆、栈,但这不意味着与父进程共享,除代码段这种只读的区域,其他的都可以理解为父进程的副本:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int g_count = 1;
int main()
{
int v_count = 42;
static int s_count = 1024;
int* h_count = (int*)malloc (sizeof (int));
*h_count = 36;
int pid = fork();
if (pid < 0)
{
// error
exit(1);
}
else if (pid == 0)
{
// child
g_count ++;
v_count ++;
s_count ++;
(*h_count) ++;
printf ("%d spawn from %d\n", getpid(), getppid());
}
else
{
// parent
sleep (1);
printf ("%d create %d\n", getpid(), pid);
}
printf ("%d: global %d, local %d, static %d, heap %d\n", getpid(), g_count, v_count, s_count, *h_count);
return 0;
}这个例子就很说明问题,运行得到下面的输出:
$ ./forkit
18270 spawn from 18269
18270: global 2, local 43, static 1025, heap 37
18269 create 18270
18269: global 1, local 42, static 1024, heap 36子进程修改全局、局部、静态、堆变量对父进程不可见,父、子进程是相互隔离的,子进程一般会在 fork 之后调用函数族来将进程空间替换为新的程序文件。这就是 exec 函数族,它们会把当前进程内容替换为磁盘上的程序文件并执行新程序的代码段,和 fork 是一对好搭档。关于 exec 函数族的更多内容,请参考后面 "exec" 一节。
对于习惯在 Windows 上创建进程的用户来说,CreateProcess 还是更容易理解一些,它直接把 fork + exec 的工作都包揽了,完全不知道还有复制进程这种骚操作。那 Unix 为什么要绕这样一个大弯呢?这是由于如果想在执行新程序文件之前,对进程属性做一些设置,则必需在 fork 之后、exec 之前进行处理,例如 I/O 重定向、设置用户 ID 和组 ID、信号安排等等,而封装成一整个的 CretaeProcess 对此是无能为力的,只能将这些代码安排在新程序的开头才行,而有时新进程的代码是不受我们控制的,对此就无能为力了。
Unix 有没有类似 CreateProcess 这样的东西呢,也有,而且是在 POSIX 标准层面定义的:
#include <spawn.h>
int posix_spawn(pid_t *restrict pid, const char *restrict path,
const posix_spawn_file_actions_t *file_actions,
const posix_spawnattr_t *restrict attrp,
char *const argv[restrict], char *const envp[restrict]);
int posix_spawnp(pid_t *restrict pid, const char *restrict file,
const posix_spawn_file_actions_t *file_actions,
const posix_spawnattr_t *restrict attrp,
char *const argv[restrict], char * const envp[restrict]);这就是 posix_spawn 和 posix_spawnp,两者的参数完全相同,区别仅在于路径参数是绝对路径 (path) 还是带搜索能力的相对路径 (file)。不过这个接口无意取代 fork + exec,仅用来支持对存储管理缺少硬件支持的系统,这种系统通常难以有效的实现 fork。
有的人认为基于 fork+exec 的 posix_spawn 不如 CreateProcess 性能好,毕竟要复制父进程一大堆东西,而大部分对新进程又无用。实际上 Unix 采取了两个策略,导致 fork+exec 也不是那么低效,通常情况下都能媲美 CreateProcess。这些策略分别是写时复制 (COW:Copy-On-Write) 与 vfork。
COW
fork 之后并不执行一个父进程数据段、栈、堆的完全复制,作为替代,这些区域由父、子进程共享,并且内核将它们的访问权限标记为只读。如果父、子进程中的任一个试图修改这些区域,则内核只为修改区域的那块内存制作一个副本,通常是虚拟存储器系统中的一页。在更深入的说明这个技术之前,先来看看 Linux 是如何将虚拟地址转换为物理地址的:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdint.h>
unsigned long virtual2physical(void* ptr)
{
unsigned long vaddr = (unsigned long)ptr;
int pageSize = getpagesize();
unsigned long v_pageIndex = vaddr / pageSize;
unsigned long v_offset = v_pageIndex * sizeof(uint64_t);
unsigned long page_offset = vaddr % pageSize;
uint64_t item = 0;
int fd = open("/proc/self/pagemap", O_RDONLY);
if(fd == -1)
{
printf("open /proc/self/pagemap error\n");
return NULL;
}
if(lseek(fd, v_offset, SEEK_SET) == -1)
{
printf("sleek error\n");
return NULL;
}
if(read(fd, &item, sizeof(uint64_t)) != sizeof(uint64_t))
{
printf("read item error\n");
return NULL;
}
if((((uint64_t)1 << 63) & item) == 0)
{
printf("page present is 0\n");
return NULL;
}
uint64_t phy_pageIndex = (((uint64_t)1 << 55) - 1) & item;
return (unsigned long)((phy_pageIndex * pageSize) + page_offset);
}这段代码可以在用户空间将一个虚拟内存地址转换为一个物理地址,具体原理就不介绍了,感兴趣的请参考附录 2。用它做个小测试:
void test_ptr(void *ptr, char const* prompt)
{
uint64_t addr = virtual2physical(ptr);
printf ("%s: virtual: 0x%x, physical: 0x%x\n", prompt, ptr, addr);
}
int g_val1=0;
int g_val2=1;
int main(void) {
test_ptr(&g_val1, "global1");
test_ptr(&g_val2, "global2");
int l_val3=2;
int l_val4=3;
test_ptr(&l_val3, "local1");
test_ptr(&l_val4, "local2");
static int s_val5=4;
static int s_val6=5;
test_ptr(&s_val5, "static1");
test_ptr(&s_val6, "static2");
int *h_val7=(int*)malloc(sizeof(int));
int *h_val8=(int*)malloc(sizeof(int));
test_ptr(h_val7, "heap1");
test_ptr(h_val8, "heap2");
free(h_val7);
free(h_val8);
return 0;
};测试种类还是比较丰富的,有局部变量、静态变量、全局变量和堆上分配的变量。在 CentOS 上有以下输出:
> sudo ./memtrans
global1: virtual: 0x60107c, physical: 0x8652f07c
global2: virtual: 0x60106c, physical: 0x8652f06c
local1: virtual: 0x9950ff2c, physical: 0xfb1df2c
local2: virtual: 0x9950ff28, physical: 0xfb1df28
static1: virtual: 0x601070, physical: 0x8652f070
static2: virtual: 0x601074, physical: 0x8652f074
heap1: virtual: 0xc3e010, physical: 0xb7ebe010
heap2: virtual: 0xc3e030, physical: 0xb7ebe030发现以下几点:
- 同类型的变量虚拟、物理地址相差不大
- 静态和全局变量虚拟地址相近、物理地址也相近,很可能是分配在同一个页上了
- 局部、全局、堆上的变量虚拟地址相差较大、物理地址也相差较大,应该是分配在不同的页上了
必需使用超级用户权限执行这段程序,否则看起来不是那么正确:
> ./memtrans
global1: virtual: 0x60107c, physical: 0x7c
global2: virtual: 0x60106c, physical: 0x6c
local1: virtual: 0x6a433e2c, physical: 0xe2c
local2: virtual: 0x6a433e28, physical: 0xe28
static1: virtual: 0x601070, physical: 0x70
static2: virtual: 0x601074, physical: 0x74
heap1: virtual: 0x116b010, physical: 0x10
heap2: virtual: 0x116b030, physical: 0x30虽然 virtual2physical 没有报错,但是一眼看上去这个结果就是有问题的。能将虚拟地址转化为物理地址后,就可以拿它在 fork 的场景中做个验证:
int g_count = 1;
int main()
{
int v_count = 42;
static int s_count = 1024;
int* h_count = (int*)malloc (sizeof (int));
*h_count = 36;
printf ("%d: global ptr 0x%x:0x%x, local ptr 0x%x:0x%x, static ptr 0x%x:0x%x, heap ptr 0x%x:0x%x\n", getpid(),
&g_count, virtual2physical(&g_count),
&v_count, virtual2physical(&v_count),
&s_count, virtual2physical(&s_count),
h_count, virtual2physical(h_count));
int pid = fork();
if (pid < 0)
{
// error
exit(1);
}
else if (pid == 0)
{
// child
printf ("%d spawn from %d\n", getpid(), getppid());
#if 0
g_count ++;
v_count ++;
s_count ++;
(*h_count) ++;
#endif
}
else
{
// parent
sleep (1);
printf ("%d create %d\n", getpid(), pid);
}
printf ("%d: global %d, local %d, static %d, heap %d\n", getpid(), g_count, v_count, s_count, *h_count);
printf ("%d: global ptr 0x%x:0x%x, local ptr 0x%x:0x%x, static ptr 0x%x:0x%x, heap ptr 0x%x:0x%x\n", getpid(),
&g_count, virtual2physical(&g_count),
&v_count, virtual2physical(&v_count),
&s_count, virtual2physical(&s_count),
h_count, virtual2physical(h_count));
return 0;
}增加了对虚拟、物理地址的打印,并屏蔽了子进程对变量的修改,先看看父、子进程是否共享了内存页:
> sudo ./forkit
19216: global ptr 0x60208c:0x5769308c, local ptr 0x22c50040:0xf4fe2040, static ptr 0x602090:0x57693090, heap ptr 0x1e71010:0x89924010
19217 spawn from 19216
19217: global 1, local 42, static 1024, heap 36
19217: global ptr 0x60208c:0x5769308c, local ptr 0x22c50040:0xf4fe2040, static ptr 0x602090:0x57693090, heap ptr 0x1e71010:0x89924010
19216 create 19217
19216: global 1, local 42, static 1024, heap 36
19216: global ptr 0x60208c:0x412f308c, local ptr 0x22c50040:0xea994040, static ptr 0x602090:0x412f3090, heap ptr 0x1e71010:0x89924010发现以下现象:
- 所有变量虚拟地址不变
- 仅堆变量的物理地址不变
- 子进程所有变量的物理地址不变,父进程局部、静态、全局变量的物理地址发生了改变
从现象可以得到以下结论:
- COW 生效,否则堆变量的物理地址不可能不变
- 局部、静态、全局变量的物理地址发生改变很可能是因为该页上有其它数据发生了变更需要复制
- 率先复制的那一方物理地址会发生变更
下面再看下子进程修改变量的情况:
> sudo ./forkit
23182: global ptr 0x60208c:0x1037008c, local ptr 0x677e8540:0xe65b6540, static ptr 0x602090:0x10370090, heap ptr 0x252d010:0x9fb3d010
23183 spawn from 23182
23183: global 2, local 43, static 1025, heap 37
23183: global ptr 0x60208c:0x1037008c, local ptr 0x677e8540:0xe65b6540, static ptr 0x602090:0x10370090, heap ptr 0x252d010:0x6dafb010
23182 create 23183
23182: global 1, local 42, static 1024, heap 36
23182: global ptr 0x60208c:0xf045708c, local ptr 0x677e8540:0x5bc6f540, static ptr 0x602090:0xf0457090, heap ptr 0x252d010:0x9fb3d010这下所有变量的物理地址都改变了,进一步验证了 COW 的介入,特别是子进程堆变量物理地址改变 (0x6dafb010) 而父进程的没有改变 (0x9fb3d010),说明系统确实为修改页的一方分配了新的页。另一方面,子进程修改了局部、静态、全局变量而物理地址没有发生改变,则说明当页不再标记为共享后,子进程再修改这些页也不会为它重新分配页了。最后父进程没有修改局部、静态、全局变量而物理地址发生了变化,一定是这些变量所在页的其它部分被修改导致的,且这些修改发生在用户修改这些变量之前,即 fork 内部。
vfork
另外一种提高 fork 性能的方法是 vfork:
#include <unistd.h>
pid_t vfork(void);它的声明与 fork 完全一致,用法也差不多,但是却有以下根本不同:
- 父、子进程并不进行任何数据段、栈、堆的复制,连 COW 都没有,完全是共享同样的内存空间
- 父进程只有在子进程调用 exec 或 exit 之后才能继续运行
vfork 是面向 fork+exec 使用场景的优化,所以在 exec (或 exit) 之前,子进程就是在父进程的地址空间运行的。而为了避免父、子进程访问同一个内存页导致的竞争问题,父进程在此期间会被短暂挂起,预期子进程会立刻调用 exec,所以这个延迟还是可以接受的。修改上面的 forkit 代码:
#if 0
int pid = fork();
#else
int pid = vfork();
#endif使用 vfork 代替 fork,再来观察结果有何不同:
> sudo ./forkit
15421: global ptr 0x60208c:0x9f6d608c, local ptr 0x91d548c0:0xa98148c0, static ptr 0x602090:0x9f6d6090, heap ptr 0x1cc1010:0xf3a5c010
15422 spawn from 15421
15422: global 2, local 43, static 1025, heap 37
15422: global ptr 0x60208c:0x9f6d608c, local ptr 0x91d548c0:0xa98148c0, static ptr 0x602090:0x9f6d6090, heap ptr 0x1cc1010:0xf3a5c010
15421 create 15422
Segmentation fault子进程运行正常而父进程在 fork 返回后崩溃了,打开 gdb 挂上 coredmp 文件查看:
> sudo gdb ./forkit --core=core.15421
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-120.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /ext/code/apue/08.chapter/forkit...done.
[New LWP 15421]
Core was generated by `./forkit'.
Program terminated with signal 11, Segmentation fault.
#0 0x0000000000400ace in main () at forkit.c:90
90 printf ("%d: global %d, local %d, static %d, heap %d\n", getpid(), g_count, v_count, s_count, *h_count);
Missing separate debuginfos, use: debuginfo-install glibc-2.17-326.el7_9.x86_64
(gdb) i lo
v_count = 43
s_count = 1025
h_count = 0x0
pid = 15422
(gdb)因为生成的 core 文件具有 root 权限,所以这里也使用 sudo 提权。打印本地变量查看,发现 h_count 指针为空了,导致 printf 崩溃。再看 vfork 的使用说明,发现有下面这么一段:
vfork() differs from fork(2) in that the calling thread is suspended until the child terminates (either normally, by calling
_exit(2), or abnormally, after delivery of a fatal signal), or it makes a call to execve(2). Until that point, the child shares all
memory with its parent, including the stack. The child must not return from the current function or call exit(3), but may call
_exit(2).大意是说因 vfork 后子进程甚至会共享父进程执行堆栈,所以子进程不能通过 return 和 exit 退出,只能通过 _exit。啧啧,一不小心就踩了坑,修改代码如下:
if (pid < 0)
{
// error
exit(1);
}
else if (pid == 0)
{
// child
printf ("%d spawn from %d\n", getpid(), getppid());
#if 1
g_count ++;
v_count ++;
s_count ++;
(*h_count) ++;
#endif
printf ("%d: global %d, local %d, static %d, heap %d\n", getpid(), g_count, v_count, s_count, *h_count);
printf ("%d: global ptr 0x%x:0x%x, local ptr 0x%x:0x%x, static ptr 0x%x:0x%x, heap ptr 0x%x:0x%x\n", getpid(),
&g_count, virtual2physical(&g_count),
&v_count, virtual2physical(&v_count),
&s_count, virtual2physical(&s_count),
h_count, virtual2physical(h_count));
_exit(0);
}
else
{
// parent
// sleep (1);
printf ("%d create %d\n", getpid(), pid);
}主要修改点如下:
- 打印语句复制一份到子进程
- 子进程通过 _exit 退出
- 父进程去除 sleep 调用
再次编译运行:
> sudo ./forkit
22831: global ptr 0x60208c:0xde9ee08c, local ptr 0x9c8a3ac0:0x2661dac0, static ptr 0x602090:0xde9ee090, heap ptr 0x1a90010:0x88797010
22832 spawn from 22831
22832: global 2, local 43, static 1025, heap 37
22832: global ptr 0x60208c:0xde9ee08c, local ptr 0x9c8a3ac0:0x2661dac0, static ptr 0x602090:0xde9ee090, heap ptr 0x1a90010:0x88797010
22831 create 22832
22831: global 2, local 43, static 1025, heap 37
22831: global ptr 0x60208c:0xde9ee08c, local ptr 0x9c8a3ac0:0x2661dac0, static ptr 0x602090:0xde9ee090, heap ptr 0x1a90010:0x88797010这回不崩溃了,而且可以看到以下有趣的现象:
- 父进程的所有变量都被子进程修改了
- 父、子进程的所有变量虚拟、物理地址完全一致
进一步印证了上面的结论。由于 vfork 根本不存在内存空间的复制,所以理论上它是性能最高的,毕竟 COW 在底层还是发生了很多内存页复制的。
vfork 这个接口是属于 SUS 标准的,目前流行的 Unix 都支持,只不过它被标识为了废弃,使用时需要小心,尤其是处理子进程的退出。
fork + fd
子进程会继承父进程以下属性:
- 打开文件描述符
- 实际用户 ID、实际组 ID、有效用户 ID、有效组 ID
- 附加组 ID
- 进程组 ID
- 会话 ID
- 控制终端
- 设置用户 ID 标志和设置组 ID 标志
- 当前工作目录
- 根目录
- 文件模式创建屏蔽字
- 信号屏蔽和安排
- 打开文件描述符的 close-on-exec 标志
- 环境变量
- 连接的共享存储段
- 存储映射
- 资源限制
- ……
以打开文件描述符为例,有如下测试程序:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main()
{
printf ("before fork\n");
int pid = fork();
if (pid < 0)
{
// error
exit(1);
}
else if (pid == 0)
{
// child
printf ("%d spawn from %d\n", getpid(), getppid());
}
else
{
// parent
sleep (1);
printf ("%d create %d\n", getpid(), pid);
}
printf ("after fork\n");
return 0;
}运行程序输出如下:
> ./forkfd
before fork
7204 spawn from 7203
after fork
7203 create 7204
after forkbefore fork 只在父进程输出一次,符合预期,如果在 main 函数第一行插入以下代码:
setvbuf (stdout, NULL, _IOFBF, 0);将标准输出设置为全缓冲模式,(关于标准 IO 的缓冲模式,可以参考这篇《[apue] 标准 I/O 库那些事儿 》),则输出会发生改变:
> ./forkfd
before fork
6955 spawn from 6954
after fork
before fork
6954 create 6955
after fork可以看到 before fork 这条语句输出了两次,分别在父、子进程各输出一次,这是由于 stdout 由行缓冲变更为全缓冲后,积累的内容并不随换行符 flush,从而就会被 fork 复制到子进程,并与子进程生成的信息一起 flush 到控制台,最终输出两次。如果仍保持行缓冲模式,还会导致多次输出吗?答案是有可能,只要将上面的换行符去掉就可以:
printf ("before fork ");新的输出如下:
> ./forkfd
before fork 17736 spawn from 17735
after fork
before fork 17735 create 17736
after fork原理是一样的。其实还存在另外的隐式修改标准输出缓冲方式的办法:文件重定向,仍以有换行符的版本为例:
> ./forkfd > output.txt
> cat output.txt
before fork
15505 spawn from 15504
after fork
before fork
15504 create 15505
after fork通过将标准输出重定向到 output.txt 文件,实现了行缓冲到全缓冲的变化,从而得到了与调用 setvbuf 相同的结果。使用不带缓冲的 write、或者在 fork 前主动 flush 缓冲,以避免上面的问题。
除了缓存复制,父、子进程共享打开文件描述符的另外一个问题是读写竞争,fork 后父、子进程共享文件句柄的情况如下图 (参考《[apue] 一图读懂 unix 文件句柄及文件共享过程 》):

父、子进程共享文件句柄特别像进程内 dup 的情况,此时对于共享的双方而言,任一进程更新文件偏移量对另一个进程都是可见的,保证了一个进程添加的数据会在另一个进程之后。但如果不做任何同步,它们的数据会相互混合,从而使输出变得混乱。一般遵循以下惯例来保证父、子进程不会在共享的文件句柄上产生读写竞争:
- 父进程等待子进程完成
- 父、子进程各自执行不同的程序段 (关闭各自不需要使用的文件描述符)
如果必需使用共享的文件句柄,则需要引入进程间同步机制来解决读写冲突,关于这一点,可以参考后续 "父子进程同步" 的文章。
在上一节介绍 vfork 时,了解到它是不复制进程空间的,子进程需要保证在退出时使用 _exit 来清理进程,避免 return 语句破坏栈指针。这里有个疑问,如果使用 exit 代替上例中的 _exit 会如何呢?修改上面的程序进行验证:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main()
{
setvbuf (stdout, NULL, _IOFBF, 0);
printf ("before fork\n");
int pid = vfork();
if (pid < 0)
{
// error
exit(1);
}
else if (pid == 0)
{
// child
printf ("%d spawn from %d\n", getpid(), getppid());
exit(0);
}
else
{
// parent
printf ("%d create %d\n", getpid(), pid);
}
printf ("after fork\n");
return 0;
}发现父进程可以正常终止:
> ./forkfd
before fork
25923 spawn from 25922
25922 create 25923
after fork_exit 是不会做任何清理工作的,所以是安全的;exit 至少会 flush 标准 IO,至于是否关闭它们则没有标准明确的要求这一点,由各个实现自行决定。如果 exit 关闭了标准 IO,那么父进程一定无法输出 after fork 这句,可见 CentOS 上的exit 没有关闭标准 IO。目前大多数系统的 exit 实现不在这方面给自己找麻烦,毕竟进程结束时系统会自动关闭进程打开的所有文件句柄,在库中关闭它们,只是增加了开销而不会带来任何益处。
apue 原文讲,即使 exit 关闭了标准 IO,STDOUT_FILENO 句柄还是可用的,通过 write 仍可以正常输出,子进程关闭自己的标准 IO 句柄并不影响父进程的那一份,对此进行验证:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main()
{
printf ("before fork\n");
char buf[128] = { 0 };
int pid = vfork();
if (pid < 0)
{
// error
exit(1);
}
else if (pid == 0)
{
// child
printf ("%d spawn from %d\n", getpid(), getppid());
fclose (stdin);
fclose (stdout);
fclose (stderr);
exit(0);
}
else
{
// parent
sprintf (buf, "%d create %d\n", getpid(), pid);
write (STDOUT_FILENO, buf, strlen(buf));
}
sprintf (buf, "after fork\n");
write (STDOUT_FILENO, buf, strlen(buf));
return 0;
}主要修改点有三处:
- 去除标准输出重定向
- 在 child exit 前主动关闭标准 IO 库
- 在 parent vfork 返回后,使用 write 代替 printf 打印日志
新的输出如下:
> ./forkfd
before fork
20910 spawn from 20909
20909 create 20910
after fork和书上说的一致,看来关闭标准 IO 库只影响父进程的 printf 调用,不影响 write 调用。再试试直接关闭文件句柄:
close (STDIN_FILENO);
close (STDOUT_FILENO);
close (STDERR_FILENO);新的输出如下:
> ./forkfd
before fork
17462 spawn from 17461
17461 create 17462
after fork仍然没有影响!看起来 vfork 子进程虽然没有复制任何父进程空间的内容,但句柄仍是做了 dup 的,所以关闭子进程的任何句柄,对父进程没有影响。
标准 IO (stdin/stdout/stderr) 还和文件句柄不同,它们带有一些额外信息例如缓存等是存储在堆或栈上的,如果 vfork 后子进程的 exit 关闭了它们,父进程是会受到影响的,这进一步反证了 exit 不会关闭标准 IO。
关于子进程继承父进程的其它属性,这里就不一一验证了,有兴趣的读者可以自行构造 demo。最后补充一下 fork 后子进程与父进程不同的属性:
- fork 返回值
- 进程 ID
- 父进程 ID
- 子进程的 CPU 时间 (tms_utime / tms_stime / tms_cutime / tms_ustime 均置为 0)
- 文件锁不会继承
- 未处理的闹钟 (alarm) 将被清除
- 未处理的信号集将设置为空
- ……
clone
在 fork 的全复制和 vfork 全不复制之间,有没有一个接口可以自由定制进程哪些信息需要复制?答案是 clone,不过这个是 Linux 特有的:
#include <sched.h>
int clone(int (*fn)(void *), void *child_stack,int flags, void *arg, .../* pid_t *ptid, void *newtls, pid_t *ctid */ );与 fork 不同,clone 子进程启动时将运行用户提供的 fn(arg) ,并且需要用户提前开辟好栈空间 (child_stack),而控制各种信息共享就是通过 flags 参数了,下面列一些主要的控制参数:
- CLONE_FILES:是否共享文件句柄
- CLONE_FS:是否共享文件系统相关信息,这些信息由 chroot、chdir、umask 指定
- CLONE_NEWIPC:是否共享 IPC 命名空间
- CLONE_PID:是否共享 PID
- CLONE_SIGHAND:是否共享信号处理
- CLONE_THREAD:是否共享相同的线程组
- CLONE_VFORK:是否在子进程 exit 或 execve 之前挂起父进程
- CLONE_VM:是否共享同一地址空间
- ……
其实 glibc clone 底层依赖的 clone 系统调用 (sys_clone) 接口更接近于 fork 系统调用,glibc 仅仅是在 sys_clone 的子进程返回中调用用户提供的 fn(arg) 而已。它将 fork 中的各种进程信息是否共享的决定权交给了用户,所以有更大的灵活性,甚至可以基于 clone 实现用户态线程库。上一节中说 vfork 后子进程在退出时可以关闭 STDOUT_FILENO 而不影响父进程,这是因为标准 IO 句柄是经过 vfork dup 的,如果使用 clone 并指定共享父进程的文件句柄 (CLONE_FILES) 会如何?下面写个例子进行验证:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
int child_func(void *arg)
{
// child
printf ("%d spawned from %d\n", getpid(), getppid());
return 1;
}
int main()
{
printf ("before fork\n");
size_t stack_size = 1024 * 1024;
char *stack = (char *)malloc (stack_size);
int pid = clone(child_func, stack+stack_size, CLONE_VM | CLONE_VFORK | SIGCHLD, 0);
if (pid < 0)
{
// error
exit(1);
}
// parent
printf ("[1] %d create %d\n", getpid(), pid);
char buf[128] = { 0 };
sprintf (buf, "[2] %d create %d\n", getpid(), pid);
write (STDOUT_FILENO, buf, strlen(buf));
return 0;
}先演示下不加 CLONE_FILES 的效果:
> ./clonefd
before fork
1271 spawned from 1270
[1] 1270 create 1271
[2] 1270 create 1271这个和 vfork 效果相同。这里为了验证标准 IO 库被关闭的情况,父进程最后一句日志使用两种方法打印,能输出两行就证明标准 IO 和底层句柄都没有被关闭,不同的方法使用前缀数字进行区别。
clone 在这个场景的使用有几点需要注意:
- 至少需要为 clone 指定 CLONE_VM 选项,用于父、子进程共享内存地址空间
- 指定的 stack 地址是开辟内存地址的末尾,因为栈是向上增长的,刚开始 child 进程一启动就挂掉,就是这里没设置对
- 指定 CLONE_VFORK 标记,这样父进程会在子进程退出后才继续运行,避免了多余的 sleep
在子进程关闭标准 IO 库尝试:
> ./clonefd
before fork
5433 spawned from 5432
[2] 5432 create 5433父进程的 printf 不工作但 write 可以工作,符合预期。在子进程关闭 STDOUT_FILENO 尝试:
> ./clonefd
before fork
11688 spawned from 11687
[1] 11687 create 11688
[2] 11687 create 11688两个都能打印,证实了 fd 是经过 dup 的,与之前 vfork 的结果完全一致。下面为 clone 增加一个共享文件描述表的设置:
int pid = clone(child_func, stack+stack_size, CLONE_VM | CLONE_VFORK | CLONE_FILES | SIGCHLD, 0);再运行上面两个用例:
> ./clonefd
before fork
8676 spawned from 8675两个场景父进程的 printf 与 write 都不输出了,但是原理稍有差别,前者是因为关闭标准 IO 对象后底层的句柄也被关闭了;后者是虽然标准 IO 对象虽然还打开着,但底层的句柄已经失效了,所以也无法输出信息。
clone 虽然强大但不具备可移植性,唯一与它类似的是 FreeBSD 上的 rfork。
fork + pthread
fork 并不复制进程的线程信息,请看下例:
#include "../apue.h"
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <fcntl.h>
#include <pthread.h>
#include <errno.h>
static void* thread_start (void *arg)
{
printf ("thread start %lu\n", pthread_self ());
sleep (2);
printf ("thread exit %lu\n", pthread_self ());
return 0;
}
int main (int argc, char *argv[])
{
int ret = 0;
pthread_t tid = 0;
ret = pthread_create (&tid, NULL, &thread_start, NULL);
if (ret != 0)
err_sys ("pthread_create");
pid_t pid = 0;
if ((pid = fork ()) < 0)
err_sys ("fork error");
else if (pid == 0)
{
printf ("[%u] child running, thread %lu\n", getpid(), pthread_self());
sleep (3);
}
else
{
printf ("fork and exec child %u in thread %lu\n", pid, pthread_self());
sleep (4);
}
exit (0);
}做个简单说明:
- 父进程启动一个线程 (thread_start)
- 线程启动后休眠 2 秒
- 父进程启动一个子进程,子进程启动后休眠 3 秒后退出
- 父进程休眠 4 秒后退出
执行程序有如下输出:
> ./fork_pthread
fork and exec child 9825 in thread 140542546036544
thread start 140542537676544
[9825] child running, thread 140542546036544
thread exit 140542537676544
> ./fork_pthread
fork and exec child 28362 in thread 139956664842048
[28362] child running, thread 139956664842048
thread start 139956656482048
thread exit 139956656482048注意这个 threadid,长长的一串首尾相同,容易让人误认为是同一个 thread,实际上两个是不同的,体现在中间的差异,以第二次执行的输出为例,一个是 6484,另一个是 5648,猛的一眼看上去不容易看出来,坑爹~
两次运行线程的启动和子进程的启动顺序有别,但结果都是一样的,子进程没有观察到线程的退出日志,从而可以断定没有复制父进程的线程信息。对上面的例子稍加改造,看看在线程中 fork 子进程会如何:
#include "../apue.h"
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <fcntl.h>
#include <pthread.h>
#include <errno.h>
static void* thread_start (void *arg)
{
printf ("thread start %lu\n", pthread_self ());
pid_t pid = 0;
if ((pid = fork ()) < 0)
err_sys ("fork error");
else if (pid == 0)
{
printf ("[%u] child running, thread %lu\n", getpid(), pthread_self());
sleep (3);
}
else
{
printf ("fork and exec child %u in thread %lu\n", pid, pthread_self());
sleep (2);
}
printf ("thread exit %lu\n", pthread_self ());
return 0;
}
int main (int argc, char *argv[])
{
int ret = 0;
pthread_t tid = 0;
ret = pthread_create (&tid, NULL, &thread_start, NULL);
if (ret != 0)
err_sys ("pthread_create");
sleep (4);
printf ("main thread exit %lu\n", pthread_self());
exit (0);
}重新执行:
> ./fork_pthread
thread start 139848844396288
fork and exec child 17141 in thread 139848844396288
[17141] child running, thread 139848844396288
thread exit 139848844396288
thread exit 139848844396288
main thread exit 139848852756288发现这次只复制了新线程 (4439),没有复制主线程 (5275),仍然是不完整的。不过 POSIX 语义本来如此:只复制 fork 所在的线程,如果想复制进程的所有线程信息,目前仅有 Solaris 系统能做到,而且只对 Solaris 线程有效,POSIX 线程仍保持只复制一个的语义。而为了和 POSIX 语义一致 (即只复制一个 Solaris 线程),它特意推出了 fork1 接口干这件事,看来复制全部线程反而是个小众需求。
exec
exec 函数族并不创建新的进程,只是用一个全新的程序替换了当前进程的正文、数据、堆和栈段,所以调用前后进程 ID 并不改变。函数族共包含六个原型:
#include <unistd.h>
extern char **environ;
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *file, char *const argv[], char *const envp[]);不同的后缀有不同的含义:
- l:使用可变参数列表传递新程序参数 (list),一般需要配合 va_arg / va_start / va_end 来提取参数
- v:与 l 参数相反,使用参数数组传递新程序参数 (vector)
- p:传递程序文件名而非路径,如果 file 参数不包含 / 字符,则在 PATH 环境变量中搜索可执行文件
- e:指定环境变量数组 envp 参数而不是默认的 environ 变量作为新程序的环境变量
书上有个图很好的解释了它们的之间的关系:
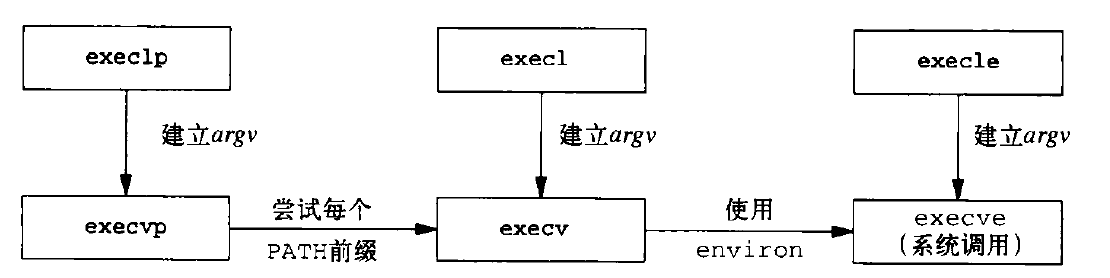
做个简单说明:
- 所有 l 后缀的接口,将参数列表提取为数组后调用 v 后缀的接口
- execvp 在 PATH 环境变量中查找可执行文件,确认新程序路径后调用 execv
- execv 使用 environ 全局变量作为 envp 参数调用 execve
百川入海,execve 就是最终被调用的那个,实际上它是一个系统调用,而其它 5 个都是库函数。上面就是 exec 函数族的主要关系,还有一些细节需要注意,下面分别说明。
路径搜索
带 p 后缀的函数在搜索 PATH 环境变量时,会依据分号(:)分隔多个路径字段,例如
> echo $PATH
/bin:/usr/bin:/usr/local/bin:.包含了四个路径,按顺序分别是
- /bin
- /usr/bin
- /usr/local/bin
- 当前目录
其中当前目录的表示方式有多种,除了显示指定点号外,还可以
- 放置在最前
PATH=:/bin:/usr/bin:/usr/local/bin - 放置在最后
PATH=/bin:/usr/bin:/usr/local/bin: - 放置在中间
PATH=/bin::/usr/bin:/usr/local/bin
当然了,不同的位置搜索优先级也不同,并且也不建议将当前路径放置在 PATH 环境变量中。
参数列表
带 l 后缀的函数,以空指针作为参数列表的结尾,像下面这个例子
if (execlp("echoall", "echoall", "test", (char *)0) < 0)
err_sys ("execlp error"); 如果使用常数 0,必需使用 char* 进行强制转换,否则它将被解释为整型参数,在整型长度与指针长度不同的平台上, exec 函数的实际参数将会出错。
带 v 后缀的函数,也需要保证数组以空指针结尾,无论是 argv 还是 envp,最终都会被新程序的 main 函数接收,所以要求与 main 函数参数相同 (参考《[apue] 进程环境那些事儿》),它们的 man 手册页中也有明确说明:
The execv(), execvp(), and execvpe() functions provide an array of pointers to null-terminated
strings that represent the argument list available to the new program. The first argument, by con‐
vention, should point to the filename associated with the file being executed. The array of pointers
must be terminated by a NULL pointer.配合 execve 的 man 内容阅读:
argv is an array of argument strings passed to the new program. By convention, the first of these
strings should contain the filename associated with the file being executed. envp is an array of
strings, conventionally of the form key=value, which are passed as environment to the new program.
Both argv and envp must be terminated by a NULL pointer. The argument vector and environment can be
accessed by the called program's main function, when it is defined as:
int main(int argc, char *argv[], char *envp[])像附录 8 那样没有给 argv 参数以空指针结尾带来的问题就很好理解了。
参数列表中的第一个参数一般指定为程序文件名,但这只是一种惯例,并无任何强制校验。每个系统对命令行参数和环境变量参数的总长度都有一个限制,通过sysconf(ARG_MAX)可获取:
> getconf ARG_MAX
2097152POSIX 规定此值不得小于 4096,当使用 shell 的文件名扩充功能 (*) 产生一个文件列表时,可能会超过这个限制从而被截断,为避免产生这种问题,可借助 xargs 命令将长参数拆分成几部分传递,书上给了一个查找 man 手册中所有的 getrlimit 的例子:
查看代码
> zgrep getrlimit /usr/share/man/*/*.gz
/usr/share/man/man0p/sys_resource.h.0p.gz:for the \fIresource\fP argument of \fIgetrlimit\fP() and \fIsetrlimit\fP():
/usr/share/man/man0p/sys_resource.h.0p.gz:int getrlimit(int, struct rlimit *);
/usr/share/man/man0p/sys_resource.h.0p.gz:\fIgetrlimit\fP()
/usr/share/man/man1/g++.1.gz:\&\s-1RAM \s0>= 1GB. If \f(CW\*(C`getrlimit\*(C'\fR is available, the notion of \*(L"\s-1RAM\*(R"\s0 is
/usr/share/man/man1/gcc.1.gz:\&\s-1RAM \s0>= 1GB. If \f(CW\*(C`getrlimit\*(C'\fR is available, the notion of \*(L"\s-1RAM\*(R"\s0 is
/usr/share/man/man1/perl561delta.1.gz:offers the getrlimit/setrlimit interface that can be used to adjust
/usr/share/man/man1/perl56delta.1.gz:offers the getrlimit/setrlimit interface that can be used to adjust
/usr/share/man/man1/perlhpux.1.gz: truncate, getrlimit, setrlimit
/usr/share/man/man2/brk.2.gz:.BR getrlimit (2),
/usr/share/man/man2/execve.2.gz:.BR getrlimit (2))
/usr/share/man/man2/fcntl.2.gz:.BR getrlimit (2)
/usr/share/man/man2/getpriority.2.gz:.BR getrlimit (2)
/usr/share/man/man2/getrlimit.2.gz:.\" 2004-11-16 -- mtk: the getrlimit.2 page, which formally included
/usr/share/man/man2/getrlimit.2.gz:getrlimit, setrlimit, prlimit \- get/set resource limits
/usr/share/man/man2/getrlimit.2.gz:.BI "int getrlimit(int " resource ", struct rlimit *" rlim );
/usr/share/man/man2/getrlimit.2.gz:.BR getrlimit ()
/usr/share/man/man2/getrlimit.2.gz:.BR getrlimit ()
/usr/share/man/man2/getrlimit.2.gz:.BR getrlimit ().
/usr/share/man/man2/getrlimit.2.gz:.BR getrlimit ().
/usr/share/man/man2/getrlimit.2.gz:.BR getrlimit (),
/usr/share/man/man2/getrlimit.2.gz:.\" getrlimit() and setrlimit() that use prlimit() to work around
/usr/share/man/man2/getrusage.2.gz:.\" 2004-11-16 -- mtk: the getrlimit.2 page, which formerly included
/usr/share/man/man2/getrusage.2.gz:.\" history, etc., see getrlimit.2
/usr/share/man/man2/getrusage.2.gz:.BR getrlimit (2),
/usr/share/man/man2/madvise.2.gz:.BR getrlimit (2),
/usr/share/man/man2/mremap.2.gz:.BR getrlimit (2),
/usr/share/man/man2/prlimit.2.gz:.so man2/getrlimit.2
/usr/share/man/man2/quotactl.2.gz:.BR getrlimit (2),
/usr/share/man/man2/sched_setscheduler.2.gz:.BR getrlimit (2))
/usr/share/man/man2/sched_setscheduler.2.gz:.BR getrlimit (2)).
/usr/share/man/man2/sched_setscheduler.2.gz:.BR getrlimit (2)
/usr/share/man/man2/sched_setscheduler.2.gz:.BR getrlimit (2).
/usr/share/man/man2/setrlimit.2.gz:.so man2/getrlimit.2
/usr/share/man/man2/syscalls.2.gz:\fBgetrlimit\fP(2) 1.0
/usr/share/man/man2/syscalls.2.gz:\fBugetrlimit\fP(2) 2.4
/usr/share/man/man2/syscalls.2.gz:.BR getrlimit (2)
/usr/share/man/man2/syscalls.2.gz:.IR sys_old_getrlimit ()
/usr/share/man/man2/syscalls.2.gz:.IR __NR_getrlimit )
/usr/share/man/man2/syscalls.2.gz:.IR sys_getrlimit ()
/usr/share/man/man2/syscalls.2.gz:.IR __NR_ugetrlimit ).
/usr/share/man/man2/ugetrlimit.2.gz:.so man2/getrlimit.2
/usr/share/man/man3/getdtablesize.3.gz:.BR getrlimit (2);
/usr/share/man/man3/getdtablesize.3.gz:.BR getrlimit (2)
/usr/share/man/man3/getdtablesize.3.gz:.BR getrlimit (2),
/usr/share/man/man3/malloc.3.gz:.BR getrlimit (2)).
/usr/share/man/man3/pcrestack.3.gz: getrlimit(RLIMIT_STACK, &rlim);
/usr/share/man/man3/pcrestack.3.gz:This reads the current limits (soft and hard) using \fBgetrlimit()\fP, then
/usr/share/man/man3p/exec.3p.gz:\fIgetenv\fP(), \fIgetitimer\fP(), \fIgetrlimit\fP(), \fImmap\fP(),
/usr/share/man/man3p/fclose.3p.gz:\fIclose\fP(), \fIfopen\fP(), \fIgetrlimit\fP(), \fIulimit\fP(),
/usr/share/man/man3p/fflush.3p.gz:\fIgetrlimit\fP(), \fIulimit\fP(), the Base Definitions volume of
/usr/share/man/man3p/fputc.3p.gz:\fIferror\fP(), \fIfopen\fP(), \fIgetrlimit\fP(), \fIputc\fP(),
/usr/share/man/man3p/fseek.3p.gz:\fIgetrlimit\fP(), \fIlseek\fP(), \fIrewind\fP(), \fIulimit\fP(),
/usr/share/man/man3p/getrlimit.3p.gz:.\" getrlimit
/usr/share/man/man3p/getrlimit.3p.gz:getrlimit, setrlimit \- control maximum resource consumption
/usr/share/man/man3p/getrlimit.3p.gz:int getrlimit(int\fP \fIresource\fP\fB, struct rlimit *\fP\fIrlp\fP\fB);
/usr/share/man/man3p/getrlimit.3p.gz:The \fIgetrlimit\fP() function shall get, and the \fIsetrlimit\fP()
/usr/share/man/man3p/getrlimit.3p.gz:Each call to either \fIgetrlimit\fP() or \fIsetrlimit\fP() identifies
/usr/share/man/man3p/getrlimit.3p.gz:considered to be larger than any other limit value. If a call to \fIgetrlimit\fP()
/usr/share/man/man3p/getrlimit.3p.gz:When using the \fIgetrlimit\fP() function, if a resource limit can
/usr/share/man/man3p/getrlimit.3p.gz:is unspecified unless a previous call to \fIgetrlimit\fP()
/usr/share/man/man3p/getrlimit.3p.gz:Upon successful completion, \fIgetrlimit\fP() and \fIsetrlimit\fP()
/usr/share/man/man3p/getrlimit.3p.gz:The \fIgetrlimit\fP() and \fIsetrlimit\fP() functions shall fail if:
/usr/share/man/man3p/setrlimit.3p.gz:.so man3p/getrlimit.3p
/usr/share/man/man3/pthread_attr_setstacksize.3.gz:.BR getrlimit (2),
/usr/share/man/man3/pthread_create.3.gz:.BR getrlimit (2),
/usr/share/man/man3/pthread_getattr_np.3.gz:.BR getrlimit (2),
/usr/share/man/man3/pthread_setschedparam.3.gz:.BR getrlimit (2),
/usr/share/man/man3/pthread_setschedprio.3.gz:.BR getrlimit (2),
/usr/share/man/man3p/ulimit.3p.gz:\fIgetrlimit\fP(), \fIsetrlimit\fP(), \fIwrite\fP(), the Base Definitions
/usr/share/man/man3p/write.3p.gz:\fIchmod\fP(), \fIcreat\fP(), \fIdup\fP(), \fIfcntl\fP(), \fIgetrlimit\fP(),
/usr/share/man/man3/ulimit.3.gz:.BR getrlimit (2),
/usr/share/man/man3/ulimit.3.gz:.BR getrlimit (2),
/usr/share/man/man3/vlimit.3.gz:.so man2/getrlimit.2
/usr/share/man/man3/vlimit.3.gz:.\" getrlimit(2) briefly discusses vlimit(3), so point the user there.
/usr/share/man/man5/core.5.gz:.BR getrlimit (2)
/usr/share/man/man5/core.5.gz:.BR getrlimit (2)
/usr/share/man/man5/core.5.gz:.BR getrlimit (2),
/usr/share/man/man5/limits.conf.5.gz:\fBgetrlimit\fR(2)\fBgetrlimit\fR(3p)
/usr/share/man/man5/proc.5.gz:.BR getrlimit (2)).
/usr/share/man/man5/proc.5.gz:.BR getrlimit (2).
/usr/share/man/man5/proc.5.gz:.BR getrlimit (2)).
/usr/share/man/man5/proc.5.gz:.BR getrlimit (2))
/usr/share/man/man7/credentials.7.gz:.BR getrlimit (2);
/usr/share/man/man7/daemon.7.gz:\fBgetrlimit()\fR
/usr/share/man/man7/mq_overview.7.gz:.BR getrlimit (2).
/usr/share/man/man7/mq_overview.7.gz:.BR getrlimit (2),
/usr/share/man/man7/signal.7.gz:.BR getrlimit (2),
/usr/share/man/man7/time.7.gz:.BR getrlimit (2),我做了两点改进:
- 使用 zgrep 代替 grep 或 bzgrep 搜索 gz 压缩文件中的内容
- 使用 /usr/share/man/*/*.gz 代替 */* 过滤子目录
实测没有报错,看起来是因为数据量还不够大:
$ find /usr/share/man/ -type f -name "*.gz" | wc
9509 9509 361540总字节大小为 361540 仍小于限制值 2097152。不过还是改成下面的形式更安全:
> find /usr/share/man -type f -name "*.gz" | xargs zgrep getrlimitxargs 会自动切分参数,确保它们不超过限制,分批“喂”给 zgrep,从而实现参数长度限制的突破,不过这样做的前提是作业可被切分为多个进程,如果必需由单个进程完成,就不能这样搞了。
最后,exec 的环境变量与命令行参数有类似的地方:
- 必需以空指针结尾
- 有总长度限制
也有不同之处,那就是不指定 envp 参数时,也可以通过修改当前进程的环境变量,来影响子进程中的环境变量,这主要是通过 setenv、putenv 接口,关于这点请参考《[apue] 进程环境那些事儿》中环境变量一节的说明。
解释器文件
如果为带 p 后缀的 exec 指定的文件不是一个由链接器产生的可执行文件,则将该文件当作一个脚本文件处理,此时将尝试调用脚本首行中记录的解释器,格式如下:
#! pathname [ optional-argument ]对这种文件的识别是由内核作为 exec 系统调用处理的一部分来完成的,pathname 通常是路径名 (绝对 & 相对),并不对它进行路径搜索。内核使调用 exec 函数的进程实际执行的并不是 file 参数本身,而是脚本第一行中 pathname 所指定的解释器,例如最常见的:
#!/bin/sh相当于调用 /bin/sh path/to/script,其中 #! 之后的空格是可选的;如果没有首行标记,则默认是 shell 脚本;若解释器需要选项才能支持脚本文件,则需要带上相应的选项 (optional-argument),例如:
#! /bin/awk -f最终相当于调用 /bin/awk -f path/to/script。书上有个不错的例子拿来做个测试:
#! /bin/awk -f
BEGIN {
for (i =0; i<ARGC; i++)
printf "argv[%d]: %s\n", i, ARGV[i]
exit
}用于打印所有传递到 awk 脚本中的命令行参数,执行之:
> ./echoall.awk file1 FILENAME2 f3
argv[0]: awk
argv[1]: file1
argv[2]: FILENAME2
argv[3]: f3有以下发现:
- 第一个参数是 awk 而不是 echoall.awk
- 没有参数 -f
和书上讲的不同,怀疑是 awk 做了处理 (-f 明显没有传递到内部的必要),改为自己写 C 程序版 echoall 验证:
#include <stdio.h>
int main (int argc, char *argv[])
{
int i;
for (i=0; i<argc; ++ i)
printf ("argv[%d]: %s\n", i, argv[i]);
exit (0);
}脚本也需要稍微改进一下:
#! ./echoall -f因为程序已经做了所有工作,这里脚本内容反而只有首行解释器定义,再次执行:
> ./echoall.sh file1 FILENAME2 f3
argv[0]: ./echoall
argv[1]: -f
argv[2]: ./echoall.sh
argv[3]: file1
argv[4]: FILENAME2
argv[5]: f3这回有了 -f 选项,并且它会被编排到 exec 函数中 argv 参数列表之前。书上的例子是直接使用 execl 来模拟内核处理解释器文件的:
#include "../apue.h"
#include <sys/wait.h>
#include <limits.h>
int main (int argc, char *argv[])
{
pid_t pid;
char *exename = "echoall.sh";
char pwd[PATH_MAX] = { 0 };
getcwd(pwd, PATH_MAX);
if (argc > 1)
exename = argv[1];
strcat (pwd, "/");
strcat (pwd, exename);
if ((pid = fork ()) < 0)
err_sys ("fork error");
else if (pid == 0)
{
if (execl (pwd, exename, "file1", "FILENAME2", "f3", (char *)0) < 0)
err_sys ("execl error");
}
if (waitpid (pid, NULL, 0) < 0)
err_sys ("wait error");
exit (0);
}输出与上例完全一致:
> ./exec
argv[0]: ./echoall
argv[1]: -f
argv[2]: /ext/code/apue/08.chapter/echoall.sh
argv[3]: file1
argv[4]: FILENAME2
argv[5]: f3有趣的是 optional-argument (-f) 之后的第一个参数 (argv[2]),execl 使用的是 path 参数 (pwd),而不是参数列表中的第一个参数 (exename):这是因为 path 参数包含了比第一个参数更多的信息,或者说第一个参数是人为指定的,可以传入任意值,存在较大的随意性,远不如 path 参数可靠。
再考查一下多个 optional-argument 的场景:
#! ./echoall -f test foo bar新的输出看起来把他们当作了一个:
> ./echoall.sh
argv[0]: ./echoall
argv[1]: -f test foo bar
argv[2]: ./echoall.sh最多只有一个解释器参数,这就意味着除了 -f,不能为 awk 指定更多的额外参数,例如 -F 指定分隔符,这一点需要注意。
解释器首行也有最大长度限制,而且与命令行参数长度限制不是一回事,以上面的脚本为例,设置一个 128 长度的参数:
#! ./echoall aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa实际输出不到 128:
> ./echoall.sh
argv[0]: ./echoall
argv[1]: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
argv[2]: ./echoall.sh经查只有 115,算上前面的 #! ./echoall 才刚好 128,可见该限制是施加在整个首行上的,且就是 128 (CentOS)。
最后,解释器文件只是一种优化而非必需,因为任何系统命令或程序,都可以放在 shell 里执行,使用解释器文件只是简化了这一过程、提高了创建进程的效率,如果解释器因种种原因不可用 (例如一个 optional-argument 不够用),还可以回退到 shell 脚本的“老路”上来~
close-on-exec
之前说过,exec 后进程 ID 不会改变,除此之外,执行新程序的进程还保持了原进程的以下特征:
- 进程 ID 和父进程 ID
- 实际用户 ID、实际组 ID
- 附加组 ID
- 进程组 ID
- 会话 ID
- 控制终端
- 闹钟剩余时间
- 当前工作目录
- 根目录
- 文件模式创建屏蔽字
- 文件锁
- 信号屏蔽和安排
- 未处理信号
- 资源限制
- tms_utime & time_stime & tms_cutime & tms_cstime (参考进程时间一节)
- ……
一般不会改变的还有打开文件描述符,说一般是因为当设置某些标志位后,描述符将被 exec 关闭,这个标志位就是 close-on-exec (FD_CLOEXEC)。如果设置了该标志,新进程中的 fd 将被关闭,否则保持不变,默认不设置该标志。下面是典型的通过 fcntl 获取和设置该标志的代码:
flag = fcntl (fd, F_GETFD);
printf ("fd(%d) flag: 0x%x, CLOSE_ON_EXEC: %d\n", fd, flag, flag & FD_CLOEXEC);
// set CLOSE_ON_EXEC
fcntl (fd, F_SETFD, flag & ~FD_CLOEXEC);POSIX.1 明确要求在执行 exec 后关闭打开的目录流,这通常是由 opendir 在内部实现的,它会为对应的描述符设置 close-on-exec 标志。下面这个程序验证了这一点,并想方设法让目录流可以跨 exec 传递:
#include "../apue.h"
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#include <dirent.h>
char *str = 0;
int main (int argc, char *argv[])
{
int fd = 0;
DIR *dir = 0;
int flag = 0;
if (argc > 1)
{
// child mode
// get file descriptor from args
fd = atol(argv[1]);
char *s = argv[2];
flag = fcntl (fd, F_GETFD);
printf ("dir fd(%d) flag: 0x%x, CLOSE_ON_EXEC: %d\n", fd, flag, flag & FD_CLOEXEC);
dir = fdopendir(fd);
printf ("recv dir %d, str %s (total %d)\n", fd, s, argc);
flag = fcntl (fd, F_GETFD);
printf ("dir fd(%d) flag: 0x%x, CLOSE_ON_EXEC: %d\n", fd, flag, flag & FD_CLOEXEC);
rewinddir(dir);
struct dirent *ent = readdir (dir);
printf ("read %p, %s\n", ent, ent ? ent->d_name : 0);
closedir (dir);
}
else
{
str = strdup ("hello world");
dir = opendir (".");
if (dir == NULL)
err_sys ("open .");
else
printf ("open . return %p\n", dir);
fd = dirfd (dir);
flag = fcntl (fd, F_GETFD);
printf ("dir fd(%d) flag: 0x%x, CLOSE_ON_EXEC: %d\n", fd, flag, flag & FD_CLOEXEC);
// restore CLOSE_ON_EXEC
fcntl (fd, F_SETFD, flag & ~FD_CLOEXEC);
flag = fcntl (fd, F_GETFD);
printf ("dir fd(%d) flag: 0x%x, CLOSE_ON_EXEC: %d\n", fd, flag, flag & FD_CLOEXEC);
pid_t pid = 0;
if ((pid = fork ()) < 0)
err_sys ("fork error");
else if (pid == 0)
{
char tmp[32] = { 0 };
sprintf (tmp, "%lu", (long)fd);
execlp ("./exec_open_dir", "./exec_open_dir"/*argv[0]*/, tmp, str, NULL);
err_sys ("execlp error");
}
else
{
printf ("fork and exec child %u\n", pid);
struct dirent *ent = readdir (dir);
printf ("read %p, %s\n", ent, ent ? ent->d_name : 0);
// closedir (dir);
}
}
exit (0);
}做个简单说明:
- 程序编译为 exec_open_dir,它有两种模式:
- 无参数时打开当前目录流,展示并清除它的 close-on-exec 标志,启动子进程,exec 替换进程为自身 (exec_open_dir) 并传递这个目录流的底层 fd 作为参数;父进程遍历目录流第一个文件并退出
- 有参数时直接打开传递的文件句柄为目录流,在 fd 转换为目录流前后分别打印它的 close-on-exec 标志,rewind 至开始并遍历第一个文件,关闭目录流退出
- 不带任何参数启动时进入 else 条件启动子进程,带参数启动时进入 if 条件;父进程进入 else 条件,子进程进入 if 条件
下面看下这个程序的运行结果:
> ./exec_open_dir
open . return 0x1c60030
dir fd(3) flag: 0x1, CLOSE_ON_EXEC: 1
dir fd(3) flag: 0x0, CLOSE_ON_EXEC: 0
fork and exec child 13085
read 0x1c60060, exec.c
dir fd(3) flag: 0x0, CLOSE_ON_EXEC: 0
recv dir 3, str hello world (total 3)
dir fd(3) flag: 0x1, CLOSE_ON_EXEC: 1
read 0x1a7c040, exec.c做个简单说明:
- 1-5:为父进程输出,opendir 后自带 close-on-exec,手动清除了这个标志,能正常遍历并打印第一个文件名
- 6-9:为子进程输出,接收到的 fd 不带 close-on-exec,fdopendir 后设置了这个标志,rewind 后能正常遍历并打印第一个文件名
这里印证了两点:
- opendir & fdopendir 自动添加 close-on-exec 标志来保证目录流跨 exec 的关闭
- 手动清除目录流底层 fd 上的 close-on-exec 可以保证目录的跨 exec 传递
不过需要注意的是,重新打开的目录流必需 rewind 才可以遍历,否则什么也不输出,即使父进程没有遍历到目录结尾。注意这里不能直接传递 DIR 指针,因为 exec 后整个进程的堆、栈会被替换,前程序的指针变量引用的内容会失效。
最后,对比下 exec 和 fork 前后保留的进程信息:
| 进程信息 | fork | exec |
| 进程 ID 和父进程 ID | 变 | 不变 |
| 实际用户 ID 和实际组 ID | 不变 | 不变 |
| 有效用户 ID 和有效组 ID | 不变 | 可变 (set-uid/set-gid) |
| 附加组 ID | 不变 | 不变 |
| 进程组 ID | 不变 | 不变 |
| 会话 ID | 不变 | 不变 |
| 控制终端 | 不变 | 不变 |
| 闹钟 | 清除未处理的 | 保持剩余时间 |
| 当前工作目录 | 不变 | 不变 |
| 根目录 | 不变 | 不变 |
| 文件模式创建屏蔽字 | 不变 | 不变 |
| 文件锁 | 清除 | 不变 |
| 信号屏蔽和安排 | 不变 | 不变 |
| 未处理信号 | 清除 | 不变 |
| 资源限制 | 不变 | 不变 |
| 新进程时间 (tms_xxtime) | 清除 | 不变 |
| 环境 | 不变 | 可变 |
| 连接的共享存储段 | 不变 | 清除 |
| 存储映射 | 不变 | 清除 |
| 文件描述符 | 不变 | 关闭 (close-on-exec) |
| ... |
更改进程用户 ID 和组 ID
Unix 系统中,特权是基于用户和用户组的,如果需要揽权操作,一般是通过切换启动进程的用户身份来实现的,例如 su 或 sudo。
然而一些需要访问特权文件的程序又需要对普通用户开放使用权限,例如 passwd,它修改的是普通用户的账户密码,但需要修改的文件 /etc/passwd 却只有 root 才有写权限,为此引入了 set-uid、set-gid 权限位标识。当普通启动具有 root 身份的 passwd 命令时,新进程将借用命令所有者的身份 (root) 而不是启动用户的身份 (普通用户),从而让 passwd 命令可以写 /etc/passwd 文件,实现让普通用户绕开权限检查的目的。
能这样做的前提是 passwd 这个程序功能单一,内部会对用户身份进行校验,确保不会修改其它用户的密码,也不会做修改密码以外的事情。Unix 系统对此有专门的保护机制,当 set-uid 或 set-gid 程序文件内容发生变更时,会自动去除其 set-uid 和 set-gid 标志位,确保程序没有被黑客篡改来做一些非法的事情。除 passwd 外,类似的程序还有 crontab、at 等等,通过下面的命令可以查看系统中所有 set-uid 程序:
> find / -perm -u+s 2>/dev/null | xargs ls -lhd关于用户权限更详细的内容,可参考《[apue] linux 文件访问权限那些事儿》。
在解释 set-uid、set-gid 机制之前先了解几个术语,进程真实的用户 ID 和用户组 ID 称为 RUID 和 RGID (real),这个一般是不变的;而权限检查针对的是进程的有效用户 ID 与有效用户组 ID,称为 EUID 和 EGID (effect),默认情况下 EUID = RUID、EGID = RGID,当指定 set-uid 或 set-gid 标志位时,exec 会自动将 EUID 或 EGID 设置为文件所属的用户 ID 与用户组 ID,从而实现揽权的目的。这也是将本节安排在 exec 函数族之后的原因。
单有 set-uid、set-gid 标志位还是不够,考查一种命令的使用场景,它既要访问特权文件,还要启动子进程,如果以特权身份启动子进程,则存在权限滥用的问题。为此,Unix 允许进程自己控制 EUID、EGID 的变更,当访问特权文件时,使用特权身份访问;当启动子进程时,使用普通用户身份启动,从而满足“最小化使用特权”的原则。
当然了,EUID 与 EGID 不能随意变更,否则会形成更大的安全漏洞,一般也就是在 RUID、RGID 与 set-uid、set-gid 指定的用户身份之间切换,后面这组 ID 在切换后会丢失,需要将它们保存起来,为此引入了新的术语:saved-set-uid & saved-set-gid,简称为 SUID 和 SGID,用来保存特权用户身份,方便之后从这里恢复。
在早期 POSIX.1 标准中 SUID & SGID 是可选的,到 2001 版中才变为必需,因此一些较老的系统可能不支持,程序中可以下面的代码做编译期测试:
#ifdef _POSIX_SAVED_IDS
printf ("support SUID & SGID!\n")
#else
printf ("NOT support SUID & SGID!\n")
#if或通过下面的代码在运行期进行验证:
if (sysconf (_SC_SAVED_IDS) == 1)
printf ("support SUID & SGID!\n");
else
printf ("NOT support SUID & SGID\n"); 甚至支持命令行:
> getconf SAVED_IDS
1
> getconf _POSIX_SAVED_IDS
1目前流行的大多数系统均支持这一特性。
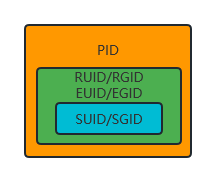
上图展示了到目前为止进程内部与权限相关的各种 ID,其中 SUID & SGID 没有接口可以直接获取,标识为单独的颜色。Linux 中有额外的扩展接口可以获取 SUID & SGID,所以可以通过 ps 命令展示它们:
$ ps -efo ruid,euid,suid,rgid,egid,sgid,pid,ppid,cmd
RUID EUID SUID RGID EGID SGID PID PPID CMD
383278 383278 383278 100000 100000 100000 24537 24536 bash -c /usr/bin/baas login
383278 383278 383278 100000 100000 100000 24610 24537 \_ /bin/bash -l XDG_SESSION_ID=393387 TERM=xterm SHELL=/bin/bash
383278 383278 383278 100000 100000 100000 19001 24610 \_ ps -efo ruid,euid,suid,rgid,egid,sgid,pid,ppid,cmd 有了这个基础,可以将之前所说的复杂权限控制场景通过下图直观展示出来:

重点看下进程的各个 ID 是如何变更的:
- 进程 100 以用户身份 foo 通过 fork + exec 启动了一个 set-uid 程序,设置的用户身份是 bar
- 启动后的进程为 101,它的 EUID 为 bar 所以可以直接访问具有 bar 权限的文件
- 进程 101 通过 fork 启动了一个子进程 102,它的用户身份完全与 101 一致
- 进程 102 在 exec 之前调整自己的用户身份为 foo
- 进程 102 在 exec 之后,完全丢失了 bar 的身份信息,没有机会再转换身份为 bar,从而达成了解除特权身份的目标
一番操作猛如虎,具有特权身份的进程 (101) 创建了一个普通身份的子进程 (102),它是完完全全的普通身份,不像其父进程一样可以自由地在特权与普通身份之间切换,如同被阉割了一般。能这样做其实隐藏了一条非常重要的规则:SUID & SGID 在 exec 时,仅从 EUID & EGID 复制,如果 EUID & EGID 是由 exec 从 set-uid & set-gid 设置的,那么复制发生在它们被设置之后。这一点保证了,102 进程在 exec 之前 SUID 为 bar,exec 之后它被同步为 foo;也是进程 101 从 set-uid 程序创建时能记录特权身份 (SUID 为 bar) 的关键。不得不说这里的设计确实巧妙。创建子进程只是一个例子,实际上可以是任意需要普通用户权限的场景,因此这个图还可以继续扩展,进程 102 可以不断在的特权用户 (bar) 和启动用户 (foo) 身份之间切换。
有了上面的铺垫,再来看 Unix 提供的接口:
// user ID
uid_t getuid(void);
uid_t geteuid(void);
int setuid(uid_t uid);
int seteuid(uid_t euid);
int setreuid(uid_t ruid, uid_t euid);
// groupd ID
gid_t getgid(void);
gid_t getegid(void);
int setgid(gid_t gid);
int setegid(gid_t egid);
int setregid(gid_t rgid, gid_t egid);4 个 get 接口就不多解释了,剩下的 6 个 set 接口中,仅对 3 个设置 uid 的接口做个说明。另外 3 个设置 gid 的接口情况类似,需要注意的是它们对进程附加组 ID 没有任何影响,关于后者,参考《[apue] linux 文件访问权限那些事儿》。
setuid
- root 进程:RUID/EUID/SUID = uid
- 普通进程
- uid == RUID:EUID = uid
- uid == SUID:EUID = uid
- 否则出错返回 -1,errno 设置为 EPERM
注意当进程本身为超级用户进程时 (root),才可以更改 RUID,在系统中,通常由 login 程序在用户登录时调用 setuid 设置新进程为当前登录用户,而 login 确实就是一个超级用户进程。
非 root 进程仅能将 EUID 设置为自己的 RUID 或 SUID,当进程不是 set-uid 进程时 (RUID = EUID = SUID),实际上调用这个接口没有意义,因为不能将 EUID 更改为其它值。
seteuid
- root 进程:EUID = uid
- 普通进程
- uid == RUID:EUID = uid
- uid == SUID:EUID = uid
- 否则出错返回 -1,errno 设置为 EPERM
这个接口对于普通进程而言,与 setuid 无异;对于超级用户进程而言,唯一的区别是只设置 EUID,保持 RUID 与 SUID 不变。
setreuid
- root 进程:RUID = ruid;EUID = euid
- 普通进程
- ruid
- -1:RUID 不变
- ruid == EUID:RUID = ruid
- ruid == SUID:RUID = ruid
- 否则出错返回 -1,errno 设置为 EPERM
- euid
- -1:EUID 不变
- euid == RUID:EUID = euid
- euid == SUID:EUID = euid
- 否则出错返回 -1,errno 设置为 EPERM
- ruid
这个接口来源于 SUS 标准,最早是 BSD 4.3 引入的,由于当时没有 saved-set-uid 机制,只能通过交换 RUID 与 EUID 的方法来实现特权与普通用户身份的切换。随着与 saved-set-uid 机制的整合,相应的判断条件也增加了一个 (item III):可以把 RUID 或 EUID 设置为 SUID。setreuid (-1, uid) 等价于 seteuid,另外 setreuid 还能实现普通进程 RUID 的变更,这是之前接口没有的能力。
demo
下面的程序用来验证:
#include "../apue.h"
#include <sys/types.h>
#include <sys/file.h>
#include <sys/stat.h>
#include <unistd.h>
void print_ids ()
{
uid_t ruid = 0;
uid_t euid = 0;
uid_t suid = 0;
int ret = getresuid (&ruid, &euid, &suid);
if (ret == 0)
printf ("%d: ruid %d, euid %d, suid %d\n", getpid(), ruid, euid, suid);
else
err_sys ("getresuid");
}
int main (int argc, char *argv[])
{
if (argc == 2)
{
char* uid=argv[1];
int ret = setuid(atol(uid));
if (ret != 0)
err_sys ("setuid");
print_ids();
}
else if (argc == 3)
{
char* ruid=argv[1];
char* euid=argv[2];
int ret = setreuid(atol(ruid), atol(euid));
if (ret != 0)
err_sys ("setreuid");
print_ids();
}
else if (argc > 1)
{
char* uid=argv[1];
int ret = seteuid(atol(uid));
if (ret != 0)
err_sys ("seteuid");
print_ids();
}
else
{
print_ids();
}
return 0;
}对 demo 的参数做个简单说明:
- 1 个参数:调用 setuid,argv[1] 为 uid,整型
- 2 个参数:调用 setreuid,argv[1] 为 ruid,argv[2] 为 euid,整型
- >2 个参数:调用 seteuid,argv[1] 为 euid,整型,其它随意,仅用于占位
- 无参数:打印当前进程 RUID / EUID / SUID
变更后也会打印当前进程 RUID / EUID / SUID。这里为了直观起见,使用了 Linux 上独有的 getresuid 接口,缺点是牺牲了可移植性。下面是驱动脚本:
#!/bin/sh
groupadd test
echo "create group ok"
useradd -g test foo
useradd -g test bar
foo_uid=$(id -u foo)
bar_uid=$(id -u bar)
echo "create user ok"
echo " foo: ${foo_uid}"
echo " bar: ${bar_uid}"
cd /tmp
chown bar:test ./setuid
echo "test foo"
su foo -c ./setuid
chmod u+s ./setuid
echo "test set-uid bar"
su foo -c ./setuid
echo "test setuid(foo)"
su foo -c "./setuid ${foo_uid}"
echo "test seteuid(foo)"
su foo -c "./setuid ${foo_uid} noop noop"
echo "test setreuid(bar, foo)"
su foo -c "./setuid ${bar_uid} ${foo_uid}"
echo "test setreuid(-1, foo)"
su foo -c "./setuid -1 ${foo_uid}"
echo "test setreuid(bar, -1)"
su foo -c "./setuid ${bar_uid} -1"
userdel bar
userdel foo
echo "remove user ok"
rm -rf /home/bar
rm -rf /home/foo
echo "remove user home ok"
groupdel test
echo "delete group ok"这个脚本制造了不同的条件来调用上面的 setuid 程序,前提是将 demo 事先放置在 /tmp 目录。运行后产生下面的输出:
> sudo sh setuid.sh
create group ok
create user ok
foo: 1003
bar: 1004
test foo
4549: ruid 1003, euid 1003, suid 1003
test set-uid bar
4562: ruid 1003, euid 1004, suid 1004
test setuid(foo)
4574: ruid 1003, euid 1003, suid 1004
test seteuid(foo)
4586: ruid 1003, euid 1003, suid 1004
test setreuid(bar, foo)
4598: ruid 1004, euid 1003, suid 1003
test setreuid(-1, foo)
4617: ruid 1003, euid 1003, suid 1004
test setreuid(bar, -1)
4629: ruid 1004, euid 1004, suid 1004
remove user ok
remove user home ok
delete group ok脚本构造了测试所需的所有账户,包括一个用户组 test,两个测试账号 foo(1003) 与 bar(1004),测试结束后又自动清理了这些账户。分别验证了以下场景:
- 未 set-uid:RUID (foo),EUID (foo),SUID (foo)
- set-uid bar
- 空参数:RUID (foo),EUID (bar),SUID (bar)
- setuid (foo):RUID (foo),EUID (foo),SUID (bar)
- seteuid (foo):RUID (foo),EUID (foo),SUID (bar)
- setreuid (bar, foo):RUID (bar),EUID (foo),SUID (bar)
- setreuid (-1,foo):RUID (foo),EUID (foo),SUID (bar)
- setreuid (bar, -1):RUID (bar),EUID (bar),SUID (bar)
都是以 foo 身份启动的,主要看 set-uid 为 bar 的场景:
- setuid、seteuid 与
setreuid(-1,foo)在这个场景等价 - setreuid 可以改变 RUID 的值,setreuid (bar,-1) 甚至允许用户永久抛弃普通用户身份,"理直气壮"的作个特权进程
对于上面最后一个用例,三个 ID 都变更为了 bar,有人可能会问了,此时进程还能恢复 foo 的身份吗?在 print_ids 中增加一小段代码做个验证:
int ret = getresuid (&ruid, &euid, &suid);
if (ret == 0)
{
if (ouid != -1)
{
printf ("%d: ruid %d, euid %d, suid %d, ouid %d\n", getpid(), ruid, euid, suid, ouid);
if (ruid == euid && euid == suid && suid != ouid)
{
printf ("all uid same %d, change back to old %d\n", ruid, ouid);
ret = seteuid (ouid);
if (ret != 0)
err_sys ("seteuid");
else
print_ids (0);
}
}
else
printf ("%d: ruid %d, euid %d, suid %d\n", getpid(), ruid, euid, suid);
}
else
err_sys ("getresuid");主要逻辑就是:判断三个 ID 相等后,尝试 change back 到之前的普通用户身份,原来的身份由 ouid 记录并经外层传入,这里是在调用 setreuid 之前使用 getuid 备份了之前的值:
else if (argc == 3)
{
char* ruid=argv[1];
char* euid=argv[1];
uid_t ouid = getuid();
int ret = setreuid(atol(ruid), atol(euid));
if (ret != 0)
err_sys ("setreuid");
// to test if ruid/euid/suid changed to same
// can we change back again?
print_ids(ouid);
}其他场景直接传 -1 即可。重新运行上面的脚本:
> sudo sh setuid.sh
create group ok
create user ok
foo: 1003
bar: 1004
test foo
4549: ruid 1003, euid 1003, suid 1003
test set-uid bar
4562: ruid 1003, euid 1004, suid 1004
test setuid(foo)
4574: ruid 1003, euid 1003, suid 1004
test seteuid(foo)
4586: ruid 1003, euid 1003, suid 1004
test setreuid(bar, foo)
4598: ruid 1004, euid 1003, suid 1003, ouid 1003
test setreuid(-1, foo)
4617: ruid 1003, euid 1003, suid 1004, ouid 1003
test setreuid(bar, -1)
4629: ruid 1004, euid 1004, suid 1004, ouid 1003
all uid same 1004, change back to old 1003
seteuid: Operation not permitted
remove user ok
remove user home ok
delete group ok果然失败了 (EPERM),这从另一个角度验证了之前的约束:seteuid 只能将 EUID 更新为 RUID 或 SUID 之一。在 setreuid(-1,foo) 的场景中,RUID = EUID = foo,仅 SUID = bar,此时切换到 bar 应该可行,感兴趣的读者可以一试。
root demo1
demo 中的 bar 并不是超级用户,而 set-uid 的大多数场景是超级用户,将 bar 切换为 root 会有什么不同?将原始脚本中的 bar 都改为 root (且去掉创建、删除 root 账户的代码) 再试:
> sudo sh setuid-setroot.sh
create group ok
create user ok
foo: 1003
root: 0
test foo
16370: ruid 1003, euid 1003, suid 1003
test set-uid root
16383: ruid 1003, euid 0, suid 0
test setuid(foo)
16395: ruid 1003, euid 1003, suid 1003
test seteuid(foo)
16408: ruid 1003, euid 1003, suid 0
test setreuid(root, foo)
16420: ruid 0, euid 1003, suid 1003
test setreuid(-1, foo)
16432: ruid 1003, euid 1003, suid 0
test setreuid(root, -1)
16445: ruid 0, euid 0, suid 0
remove user ok
remove user home ok
delete group ok除了以下不同外外,其它没区别:
- setuid 会将 3 个 ID 设置为一样
- setreuid 后 SUID 也将会被变更为新的 EUID
后一条在 man 中找到了解释:
If the real user ID is set or the effective user ID is set to a value not equal to the previous real user ID, the saved set-user-ID will be set to the new effective user ID.意思是无论 EUID 还是 RUID,只要与之前的 RUID 不同,SUID 都会随之变更。关于 SUID 的变更,可以参考下一小节的例子,现在接着上一个例子的热度,再验证下 ID 一样的情况下是否还有 change back 的能力:
> sudo sh setuid-setroot.sh
create group ok
create user ok
foo: 1003
root: 0
test foo
5842: ruid 1003, euid 1003, suid 1003
test set-uid root
5855: ruid 1003, euid 0, suid 0
test setuid(foo)
5873: ruid 1003, euid 1003, suid 1003, ouid 0
all uid same 1003, change back to old 0
seteuid: Operation not permitted
test seteuid(foo)
5885: ruid 1003, euid 1003, suid 0
test setreuid(root, foo)
5897: ruid 0, euid 1003, suid 1003, ouid 1003
test setreuid(-1, foo)
5909: ruid 1003, euid 1003, suid 0, ouid 1003
test setreuid(root, -1)
5921: ruid 0, euid 0, suid 0, ouid 1003
all uid same 0, change back to old 1003
5921: ruid 0, euid 1003, suid 0
remove user ok
remove user home ok
delete group ok如果已变身为普通用户,不能 change back;如果是超级用户,可以。
root demo2
上个例子中,超级用户进程在变更 EUID 时 SUID 会随之变更,然而 man 中说 RUID 变更时 SUID 才会随之变更,为了看的更清楚些,写了一个 setreuid 的测试脚本:
#!/bin/sh
groupadd test
echo "create group ok"
useradd -g test foo
useradd -g test bar
foo_uid=$(id -u foo)
bar_uid=$(id -u bar)
echo "create user ok"
echo " foo: ${foo_uid}"
echo " bar: ${bar_uid}"
cd /tmp
#chown bar:test ./setuid
echo "test foo"
./setuid
#chmod u+s ./setuid
#echo "test set-uid bar"
#su foo -c ./setuid
echo "test setreuid(bar, foo)"
./setuid ${bar_uid} ${foo_uid}
echo "test setreuid(foo, bar)"
./setuid ${foo_uid} ${bar_uid}
echo "test setreuid(-1, foo)"
./setuid -1 ${foo_uid}
echo "test setreuid(bar, -1)"
./setuid ${bar_uid} -1
echo "test setreuid(bar, bar)"
./setuid ${bar_uid} ${bar_uid}
echo "test setreuid(foo, foo)"
./setuid ${foo_uid} ${foo_uid}
userdel bar
userdel foo
echo "remove user ok"
rm -rf /home/bar
rm -rf /home/foo
echo "remove user home ok"
groupdel test
echo "delete group ok"仍然创建 foo、bar 账户,不同的是直接使用超级用户身份启动 setuid,并传递不同的 foo、bar 参数给 setreuid 进行测试:
> sudo sh setreuid.sh
create group ok
create user ok
foo: 1003
bar: 1004
test foo
27253: ruid 0, euid 0, suid 0
test setreuid(bar, foo)
27254: ruid 1004, euid 1003, suid 1003
test setreuid(foo, bar)
27255: ruid 1003, euid 1004, suid 1004
test setreuid(-1, foo)
27256: ruid 0, euid 1003, suid 1003
test setreuid(bar, -1)
27257: ruid 1004, euid 0, suid 0
test setreuid(bar, bar)
27258: ruid 1004, euid 1004, suid 1004
test setreuid(foo, foo)
27259: ruid 1003, euid 1003, suid 1003
remove user ok
remove user home ok测试了 6 个场景,这下看清楚了,SUID 变更基本与 EUID 是同步的,而 RUID 的变更对 SUID 反而没有什么影响。
需要注意的是,与 demo2 的 setreuid(-1,foo) 场景不同,demo1 的 SUID 仍保持 0 而不是变更为 1003,这里有点说不通,两个例子唯一的区别仅是获取的超级用户权限的途径,demo1 通过 set-uid root;demo2 通过启动用户本身是 root。为 demo1 增加 setreuid(foo,bar) 与 setreuid(bar,foo) 两个场景做对比,新的输出如下:
> sudo sh setuid-setroot.sh
create group ok
create user ok
foo: 1003
root: 0
test foo
7475: ruid 1003, euid 1003, suid 1003
test set-uid root
7488: ruid 1003, euid 0, suid 0
test setuid(foo)
7500: ruid 1003, euid 1003, suid 1003
test seteuid(foo)
7512: ruid 1003, euid 1003, suid 0
test setreuid(root, foo)
7524: ruid 0, euid 1003, suid 1003
test setreuid(-1, foo)
7536: ruid 1003, euid 1003, suid 0
test setreuid(root, -1)
7548: ruid 0, euid 0, suid 0
test setreuid(foo, bar)
7560: ruid 1003, euid 1003, suid 1003
test setreuid(bar, foo)
7572: ruid 1003, euid 1003, suid 1003
remove user ok
remove user home ok
delete group ok神奇的事情发生了,虽然理论上现在进程拥有特权,然而却不能设置 foo & root 之外的用户身份,这两个用例最终都变成了 foo,看起来借用的特权和原生的还是有很大差别。
好奇 setuid 和 seteuid 的表现如何,添加下面的用例:
echo "test setuid(foo)"
su foo -c "./setuid ${foo_uid}"
echo "test setuid(bar)"
su foo -c "./setuid ${bar_uid}"
echo "test seteuid(foo)"
su foo -c "./setuid ${foo_uid} noop noop"
echo "test seteuid(bar)"
su foo -c "./setuid ${bar_uid} noop noop"主要验证 setuid(bar) & seteuid(bar) 的情况:
test setuid(foo)
27292: ruid 1003, euid 1003, suid 1003
test setuid(bar)
27304: ruid 1003, euid 0, suid 0
test seteuid(foo)
27316: ruid 1003, euid 1003, suid 0
test seteuid(bar)
27328: ruid 0, euid 0, suid 0更离谱的情况出现了,setuid(bar) 不生效也不报错;seteuid(bar) 更是直接回退到了 root。感觉 set-uid root 的进程逻辑有点混乱。
虽然不清楚 Linux 底层是如何处理的,但是大胆假设一下,这里的逻辑应该和 RUID 相关:当以 root 身份启动时,RUID = EUID = 0;而以 set-uid root 身份启动时,RUID != 0。然而可以人为将 set-uid root 的 RUID 修改为 0 (通过 setreuid(root, -1) 实现),此时它满足 RUID = EUID = 0 的条件,再执行 setreuid(foo,bar) 还能成功吗?修改 setuid.c 程序进行验证:
uid_t ruid = 0;
uid_t euid = 0;
uid_t suid = 0;
int ret = getresuid (&ruid, &euid, &suid);
if (ret == 0)
{
printf ("%d: ruid %d, euid %d, suid %d\n", getpid(), ruid, euid, suid);
if (ruid == 0 && euid == 0)
{
// in root, try setreuid(foo, bar)
int ret = setreuid(1003, 1004);
if (ret != 0)
err_sys ("setreuid");
else
print_ids (-1);
}
}
else
err_sys ("getresuid");当检测到全 root ID 时,在 print_ids 中再调用一次 setreuid,这里为方便直接写死了 foo、bar 的用户 ID (1003/1004)。重新运行上面的脚本:
> sudo sh setuid-setroot.sh
create group ok
create user ok
foo: 1003
root: 0
test foo
3767: ruid 1003, euid 1003, suid 1003
test set-uid root
3780: ruid 1003, euid 0, suid 0
test setuid(foo)
3792: ruid 1003, euid 1003, suid 1003
test setuid(bar)
3804: ruid 1003, euid 0, suid 0
test seteuid(foo)
3817: ruid 1003, euid 1003, suid 0
test seteuid(bar)
3829: ruid 0, euid 0, suid 0
3829: ruid 1003, euid 1004, suid 1004
test setreuid(root, foo)
3841: ruid 0, euid 1003, suid 1003
test setreuid(-1, foo)
3853: ruid 1003, euid 1003, suid 0
test setreuid(root, -1)
3865: ruid 0, euid 0, suid 0
3865: ruid 1003, euid 1004, suid 1004
test setreuid(foo, bar)
3878: ruid 1003, euid 1003, suid 1003
test setreuid(bar, foo)
3890: ruid 1003, euid 1003, suid 1003
remove user ok
remove user home ok
delete group ok重点看 test setreuid(root,-1) 之后的输出,全 root ID 后是可以正确设置 RUID = foo、EUID = bar 身份的,看来就是 RUID 与 EUID 不一致捣的鬼!
总结一下,如果 EUID = 0 为超级用户权限,那么在是否能随意设置其它用户身份这个问题上,还要看 RUID 的值,如果 RUID = 0,可以;否则,有限制。而对于这个进程是通过 root 身份获取的全 0 ID,还是通过 set-uid root 再 setreuid 获取的全 0 ID,系统并不 care。至于 Linux 源码是不是这样写的,这个存疑,留待以后查看源码再做结论。
root demo3
来看一个冷门但存在的场景:set-uid bar 但以超级用户身份启动进程。需要将原始脚本中 foo 替换为 root、所有 su foo -c 去掉 (且去掉创建、删除账户的代码) :
> sudo sh setuid-root.sh
create group ok
create user ok
root: 0
bar: 1003
test root
14996: ruid 0, euid 0, suid 0
test set-uid bar
14998: ruid 0, euid 1003, suid 1003
test setuid(root)
14999: ruid 0, euid 0, suid 1003
test seteuid(root)
15000: ruid 0, euid 0, suid 1003
test setreuid(bar, root)
15001: ruid 1003, euid 0, suid 0
test setreuid(-1, root)
15002: ruid 0, euid 0, suid 1003
test setreuid(bar, -1)
15003: ruid 1003, euid 1003, suid 1003
remove user ok
remove user home ok
delete group ok这个反向 set-uid 能实现特权"降级"效果,其中较有有趣的是 setuid (root) 的场景,它仅设置 EUID 为 0,进一步验证了进程的特权是从 EUID 而来 (老 EUID 为 bar 非特权用户,虽然 RUID 为 0)。
mac demo
好奇 mac 上的表现是否一致?将原始程序移植到 mac 上 (去掉 SUID 的获取和展示),直接启动脚本发现创建用户和组的命令会报错,在 mac 上缺少 groupadd、useradd 等命令,必需手动创建它们:

将原始脚本中创建、删除账户的代码移除,直接基于上面创建好的用户和组进行测试:
> sudo sh setuid.sh
create user ok
foo: 501
bar: 502
test foo
30106: ruid 501, euid 501
test set-uid bar
30109: ruid 501, euid 502
test setuid(foo)
30111: ruid 501, euid 501
test seteuid(foo)
30113: ruid 501, euid 501
test setreuid(bar, foo)
30115: ruid 502, euid 501
test setreuid(-1, foo)
30117: ruid 501, euid 501
test setreuid(bar, -1)
30119: ruid 502, euid 502虽然无法看到 SUID,表现却和 Linux 一致。如法炮制,继续验证 root demo1:
> sudo sh setuid-setroot.sh
create user ok
foo: 501
root: 0
test foo
2987: ruid 501, euid 501
test set-uid root
2990: ruid 501, euid 0
test setuid(foo)
2992: ruid 501, euid 501
test setuid(bar)
2994: ruid 501, euid 0
test seteuid(foo)
2996: ruid 501, euid 501
test seteuid(bar)
2998: ruid 0, euid 0
test setreuid(root, foo)
3000: ruid 0, euid 501
test setreuid(-1, foo)
3002: ruid 501, euid 501
test setreuid(root, -1)
3004: ruid 0, euid 0
test setreuid(foo, bar)
3006: ruid 501, euid 501
test setreuid(bar, foo)
3008: ruid 501, euid 501验证 set-uid 为 root 的场景,并且融合了部分 root demo2 的场景,即在 set-uid root 获取超级用户权限的情况下,能否设置其它用户身份,结果与 Linux 一致:不能。接下来验证 root demo2:
> sudo sh setreuid.sh
create user ok
foo: 501
bar: 502
test foo
3410: ruid 0, euid 0
test setreuid(bar, foo)
3411: ruid 502, euid 501
test setreuid(foo, bar)
3412: ruid 501, euid 502
test setreuid(-1, foo)
3413: ruid 0, euid 501
test setreuid(bar, -1)
3414: ruid 502, euid 0
test setreuid(bar, bar)
3415: ruid 502, euid 502
test setreuid(foo, foo)
3416: ruid 501, euid 501以超级用户启动进程的情况下 setreuid 设置任意用户的能力,与 Linux 也是一致的:能。最后验证 root demo3:
> sudo sh setuid-root.sh
create user ok
root: 0
bar: 502
test root
3679: ruid 0, euid 0
test set-uid bar
3681: ruid 0, euid 502
test setuid(root)
3682: ruid 0, euid 0
test seteuid(root)
3683: ruid 0, euid 0
test setreuid(bar, root)
3684: ruid 502, euid 0
test setreuid(-1, root)
3685: ruid 0, euid 0
test setreuid(bar, -1)
3686: ruid 502, euid 502以超级用户身份启动 set-uid 普通用户身份的进程,结果也是与 Linux 一致的。
最终结论,mac 上的 setuid 函数族表现与 linux 完全一致,特别是在 set-uid root 获取的超级用户权限时的一些表现,可以明确的一点就是这些异常 case 并不是 Linux 独有的,而是广泛分布于 Unix 系统。当然由于在 mac 上看不到 SUID,关于 SUID 的部分不在本节讨论范围内。
总结
结合之前对 exec 的说明,setuid 函数族对权限 ID 的影响可以归纳为一个表格:
| 启动身份 | set-uid 身份 | 接口 | RUID | EUID | SUID |
| foo | n/a | n/a | foo | foo | foo |
| root | n/a | foo | 0 | 0 | |
| setuid (foo) | foo | foo | foo | ||
| setuid (bar) | foo | 0 | 0 | ||
| seteuid (foo) | foo | foo | 0 | ||
| seteuid (bar) | 0 | 0 | 0 | ||
| setreuid (root, foo) | 0 | foo | 0 | ||
| setreuid (root, -1) | 0 | 0 | 0 | ||
| setreuid (-1, foo) | foo | foo | 0 | ||
| bar | n/a | foo | bar | bar | |
| setuid (foo) | foo | foo | bar | ||
| seteuid (foo) | foo | foo | bar | ||
| setreuid (bar, foo) | bar | foo | bar | ||
| root | n/a | n/a | 0 | 0 | 0 |
| setuid (foo) | foo | foo | foo | ||
| seteuid (foo) | 0 | foo | 0 | ||
| setreuid (foo, bar) | foo | bar | bar | ||
| setreuid (bar, foo) | bar | foo | foo | ||
| bar | n/a | 0 | bar | bar | |
| setuid (root) | 0 | 0 | bar | ||
| seteuid (root) | 0 | 0 | bar | ||
| setreuid (bar, root) | bar | 0 | bar |
其中 foo 和 bar 都是普通用户,表中验证了之前讨论的几种场景:
- foo/no-set-uid:普通用户启动普通进程,只能访问自己的文件
- foo/set-uid root:普通用户启动超级用户进程 (setuid 主要场景)
- foo/set-uid bar:普通用户启动普通进程,能访问另一个普通用户的文件 (冷门场景但存在)
- root/no-set-uid:超级用户启动超级用户进程
- root/set-uid bar:超级用户启动普通进程 (冷门场景几乎不存在)
把这个表弄懂,Unix 上进程权限变化就了然于胸了。
回顾
本节开头那个复杂的进程特权控制的例子:
在切换 EUID 时,理论上使用上面三个接口都可以,但经过实测:
- setuid 在 root 场景下会同时修改 3 个 ID
- setreuid 场景复杂
- 对 SUID 有说不清楚的影响
- set-uid root 场景下可设置其它用户身份而不报错,但结果不符合预期
- 仅交换 RUID & EUID 并不能实现子进程的特权回收,因为子进程可以通过继续调用 setreuid 恢复特权,如果将 ruid 参数设置为 -1,则退化为 seteuid 的场景
seteuid 语义明确、副作用更少,是最合适的接口,实际上它们的历史的演进也是如此:setuid -> setreuid -> seteuid。下面的程序演示了基于 seteuid 做上图中复杂的进程特权控制的过程:
#include "../apue.h"
#include <sys/types.h>
#include <sys/file.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
void print_ids (char const* prompt)
{
uid_t ruid = 0;
uid_t euid = 0;
uid_t suid = 0;
int ret = getresuid (&ruid, &euid, &suid);
if (ret == 0)
printf ("%s %d: ruid %d, euid %d, suid %d\n", prompt, getpid(), ruid, euid, suid);
else
err_sys ("getresuid");
}
int main (int argc, char *argv[])
{
uid_t ruid = getuid();
uid_t euid = geteuid();
if (ruid == euid)
{
printf ("ruid %d != euid %d, please set me set-uid before run this test !\n");
exit (1);
}
print_ids ("init");
int pid = fork ();
if (pid < 0)
err_sys ("fork");
else if (pid == 0)
{
// children
print_ids ("after fork");
int ret = seteuid (ruid);
if (ret == -1)
err_sys ("seteuid");
print_ids ("before exec");
execlp ("./setuid", "setuid", NULL);
err_sys ("execlp");
}
else
printf ("create child %u\n", pid);
wait(NULL);
print_ids("exit");
return 0;
}做个简单说明:
- 这个程序本身会被 set-uid,相当于图中的 101 进程
- 它会 fork 一个子进程,并在其中 exec 程序 (./setuid),相当于图中的 102 进程
- 将 seteuid 放置于 fork 之后 exec 之前,这样做的好处是对父进程没有影响 (考虑父进程多线程的场景)
- 被启动的 setuid 进程不带额外参数,只会打印子进程的 3 个ID 值,用于验证 SUID 值没有从父进程复制
下面是驱动脚本:
#!/bin/sh
groupadd test
echo "create group ok"
useradd -g test foo
useradd -g test bar
foo_uid=$(id -u foo)
bar_uid=$(id -u bar)
echo "create user ok"
echo " foo: ${foo_uid}"
echo " bar: ${bar_uid}"
cd /tmp
chown bar:test ./fork_setuid
chmod u+s ./fork_setuid
su foo -c ./fork_setuid
userdel bar
userdel foo
echo "remove user ok"
rm -rf /home/bar
rm -rf /home/foo
echo "remove user home ok"
groupdel test
echo "delete group ok"以 foo 用户启动了一个 set-uid 为 bar 的程序 (fork_setuid)。下面是脚本和程序的输出:
> sudo sh fork_setuid.sh
create group ok
create user ok
foo: 1003
bar: 1004
init 29958: ruid 1003, euid 1004, suid 1004
create child 29959
after fork 29959: ruid 1003, euid 1004, suid 1004
before exec 29959: ruid 1003, euid 1003, suid 1004
29959: ruid 1003, euid 1003, suid 1003
exit 29958: ruid 1003, euid 1004, suid 1004
remove user ok
remove user home ok
delete group ok做个简单说明:
- 由于 set-uid,程序启动后 RUID = foo,EUID = SUID = bar
- fork 后父、子进程以上值均没有变化
- 子进程 exec 前 seteuid 后,RUID = EUID = foo,SUID = bar
- 子进程 exec 后,RUID = EUID = SUID = foo,彻彻底底失去了变身 bar 的机会
完全符合预期。做为对比,去掉程序中的 seteuid 调用,再次运行:
> sudo sh fork_setuid.sh
create group ok
create user ok
foo: 1003
bar: 1004
init 14567: ruid 1003, euid 1004, suid 1004
create child 14568
after fork 14568: ruid 1003, euid 1004, suid 1004
14568: ruid 1003, euid 1004, suid 1004
exit 14567: ruid 1003, euid 1004, suid 1004
remove user ok
remove user home ok
delete group ok这次子进程 exec 后保留了 bar 身份。更进一步,在原 demo 的基础上为 ./setuid 设置 3 个参数来调用内部的 seteuid,看它还能否恢复 bar (1004) 的身份:
char tmp[128] = { 0 };
sprintf (tmp, "%u", euid);
execlp ("./setuid", "setuid", tmp, "noop", "noop", NULL);新的程序输出如下:
> sudo sh fork_setuid.sh
create group ok
create user ok
foo: 1003
bar: 1004
init 1646: ruid 1003, euid 1004, suid 1004
create child 1647
after fork 1647: ruid 1003, euid 1004, suid 1004
before exec 1647: ruid 1003, euid 1003, suid 1004
seteuid: Operation not permitted
exit 1646: ruid 1003, euid 1004, suid 1004
remove user ok
remove user home ok
delete group ok的确不行。
最后需要补充一点的是,set-uid 标志位对脚本文件不生效,原因其实已经在“解释器文件”一节中有过说明:脚本文件只是解释器的输入,真正被启动的进程是解释器,只有将 set-uid 标志加在解释器上才能有效果,不过解释器一般是一种通用的命令,具体要执行的操作由脚本指定,如果将它指定为 set-uid root 的话,无疑会造成特权滥用。只有在封闭受控的系统中、没有其它替代方法万不得已时才可出此下策。关于这方面更多的信息,可参考附录 10。
进程终止
关于进程的终止,这篇《[apue] 进程环境那些事儿》有过梳理,主要分 5 种正常终止与 3 种异常终止场景:
正常终止:
- 从 main 返回 (无论是否有返回值)
- 调用 exit
- 调用 _exit 或 _Exit
- 最后一个线程从其启动例程返回
- 最后一个线程调用 pthread_exit
异常终止:
- 调用 abort
- 接到一个信号并终止
- 最后一个线程对取消请求做出响应
首先看正常终止场景下后两个场景,它们都与线程相关。如果最后一个线程不是 main,那么当 main 返回或调用 exit 后进程就终止了,不存在其它线程还能继续跑的场景,所以 main 一定是进程的最后一个线程,所谓它"从启动例程返回或调用 pthread_exit" 这句话没有任何意义,因为 main 线程不是 pthread 库创建的,也就是说最后两个场景在现实中并不存在,反正我是没有试出来。
这样进程正常退出只要聚焦前三个场景就可以了,apue 上有一个图非常经典:
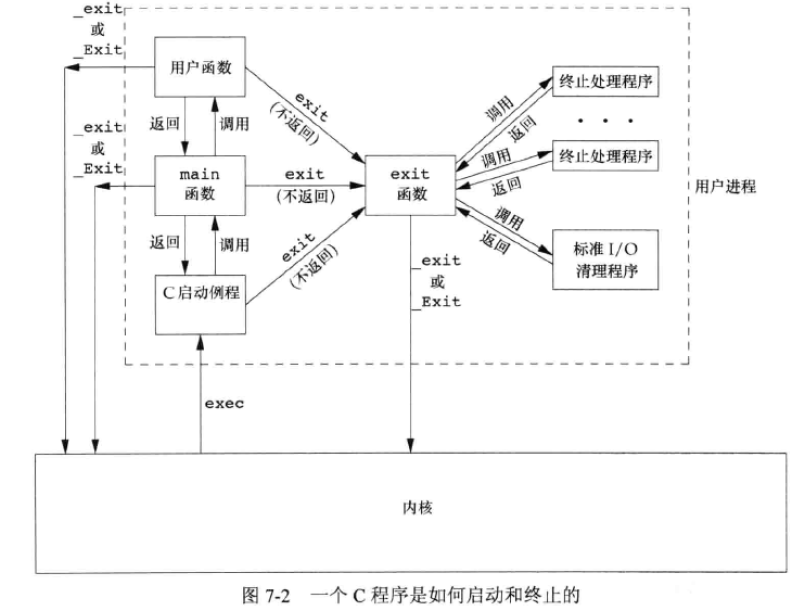
很好的描述了 exit 与 _exit、用户进程与内核的关系。进程异常终止虽然不走 exit,但在内核有与正常终止相同的清理逻辑,估且称之为 sys_exit,它的主要工作是关闭进程所有打开文件、释放使用的存储器 (memory) 等。
进程终止状态
进程退出后并不是什么信息也没有留下,考虑一种场景,父进程需要得知子进程的退出码 (exit(status)),系统为此保留了一部分进程信息:
- 进程 ID
- 终止状态
- 使用的 CPU 时间总量
- ……
这里的终止状态既包含了正常终止时的退出码,也包含了异常终止时的信号等信息。
当通过 waitxxx 系统调用返回时,终止状态 (status) 一般作为整型返回,通过下面的宏可以提取退出码、异常信号等信息:
- WIFEXITED (status):进程正常终止为 true
- WEXITSTATUS (status):进程正常终止的退出码,为 exit 或 _exit 的低 8 位,关于 main 函数 return 值与进程 exit 参数的关系,参考《[apue] 进程环境那些事儿》
- WIFSIGNALED (status):进程异常终止为 true
- WTERMSIG (status):导致进程异常终止的信号编号
- WCOREDUMP (status):产生 core 文件为 true (非 SUS 标准)
- WIFSTOPPED (status):进程被挂起为 true
- WSTOPSIG (status):导致进程被挂起的信号编号
- WIFCONTINUED (status):进程继续运行为 true
注意 wait 函数还可以获取正在运行的子进程的状态,例如挂起或继续运行,但此时子进程并未"终止",多用于 shell 这样带作业控制的终端程序。关于终止状态的更多信息将在讨论 wait 函数族时进一步介绍。
僵尸进程与孤儿进程
前文说到,进程退出后仍有一部分信息保留在系统中,这些信息虽然尺寸不大,但在未被 wait 之前会一直占据一个进程表项,而系统的进程表项是有限的 (ulimit -u),如果这种僵尸进程 (zombie) 太多,就会导致新进程创建失败。下面是基于 forkit 自制的一个例子:
$ ps -exjf
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
....
41707 41955 41707 41707 ? -1 S 1000 0:00 sshd: yunhai01@pts/1
41955 41957 41957 41957 pts/1 28035 Ss 1000 0:00 \_ bash -c /usr/bin/baas pass_bils_identity --baas_cred=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
41957 41982 41982 41957 pts/1 28035 S 1000 0:00 \_ /bin/bash -l XDG_SESSION_ID=39466 ANDROID_HOME=/ext/tools/android-sdk-linux TERM=xterm-256color SHELL=/bin/bash HISTSIZE=1000 SSH_CL
41982 28035 28035 41957 pts/1 28035 S+ 1000 0:00 \_ ./forkit XDG_SESSION_ID=39466 HOSTNAME=goodcitizen.bcc-gzhxy.baidu.com ANDROID_HOME=/ext/tools/android-sdk-linux SHELL=/bin/bash
28035 28036 28035 41957 pts/1 28035 Z+ 1000 0:00 \_ [forkit] <defunct>
....其中 28035 是父进程,28036 是子进程,子进程退出后父进程没有 wait 前,ps 查看它的状态就是 Z (defunct)。僵尸进程的产生是子进程先于父进程退出,如果父进程先于子进程退出呢?这就是孤儿进程了 (orphan)。孤儿进程将被过继给 init 进程 (进程 ID = 1),无论父进程是否为僵尸进程,这是因为僵尸进程无法 wait 回收任何子进程。对上面的 forkit 稍加改造制作了 fork_zombie 程序:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main()
{
int pid = fork();
if (pid < 0)
{
// error
exit(1);
}
else if (pid == 0)
{
// child
printf ("%d spawn from %d\n", getpid(), getppid());
pid = fork();
if (pid < 0)
{
// error
exit(1);
}
else if (pid == 0)
{
// child
printf ("%d spawn from %d\n", getpid(), getppid());
sleep (10);
}
else
{
printf ("%d create %d\n", getpid(), pid);
}
}
else
{
printf ("%d create %d\n", getpid(), pid);
sleep (10);
}
printf ("after fork\n");
return 0;
}在子进程中继续 fork 子进程,这个孙子进程会存活比子进程更长的时间 (sleep 10),从而成为孤儿进程:
$ ps -exjf
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
41707 41955 41707 41707 ? -1 S 1000 0:00 sshd: yunhai01@pts/1
41955 41957 41957 41957 pts/1 13744 Ss 1000 0:00 \_ bash -c /usr/bin/baas pass_bils_identity --baas_cred=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
41957 41982 41982 41957 pts/1 13744 S 1000 0:00 \_ /bin/bash -l XDG_SESSION_ID=39466 ANDROID_HOME=/ext/tools/android-sdk-linux TERM=xterm-256color SHELL=/bin/bash HISTSIZE=1000 SSH_CL
41982 13744 13744 41957 pts/1 13744 S+ 1000 0:00 \_ ./fork_zombie XDG_SESSION_ID=39466 HOSTNAME=goodcitizen.bcc-gzhxy.baidu.com ANDROID_HOME=/ext/tools/android-sdk-linux SHELL=/bin
13744 13745 13744 41957 pts/1 13744 Z+ 1000 0:00 \_ [fork_zombie] <defunct>
1 13746 13744 41957 pts/1 13744 S+ 1000 0:00 ./fork_zombie XDG_SESSION_ID=39466 HOSTNAME=goodcitizen.bcc-gzhxy.baidu.com ANDROID_HOME=/ext/tools/android-sdk-linux SHELL=/bin/bash TERM=x其中 13744 是父进程;13745 是子进程,会成为僵尸进程;13746 是孙子进程,会成为孤儿进程。可以看到孤儿进程直接过继给 init 进程了。init 进程会保证回收所有退出的子进程,从而避免僵尸进程数量太多的问题。
上面无意间已经揭示了一种避免僵尸进程的方法:double fork,目前有共三种方法:
- wait 函数族
- SIGCHLD 信号 (处理或忽略)
- double fork
前两种方法在敝人的拙著《[apue] 等待子进程的那些事儿》中都有记录,欢迎大家翻阅~
需要注意的是第三种方法 double fork 只能避免孙子进程不是僵尸进程,子进程还需要使用前两种方法来避免成为僵尸进程,这里用 wait 函数族多一些。
wait 函数族
在介绍 wait 函数族之前,先简单说一下 SIGCHLD 信号,当子进程退出时,父进程会接收到该信号,面对 SIGCHLD 父进程有三种选择:
- 默认:系统忽略
- 处理:增加信号处理函数,在其中使用 wait 函数族回收子进程 (可期望不被被阻塞)
- 忽略:SIG_IGN 显示忽略信号,子进程会被自动回收,对 wait 函数族的影响后面介绍
有了这个铺垫,再看 wait 接口定义:
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, int options);
int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options);
pid_t wait3(int *status, int options, struct rusage *rusage);
pid_t wait4(pid_t pid, int *status, int options, struct rusage *rusage);wait
最基础的获取子进程终止状态的接口,顾名思义,当子进程还在运行时,它还有同步等待子进程退出的能力,以下是它在不同场景的表现:
- 无任何子进程:返回 -1,errno 设置为 ECHILD
- 子进程全部在运行:阻塞等待
- 有子进程退出:获取其中任意一个退出的子进程状态并返回其进程 ID
为了避免阻塞,可期望在 SIGCHLD 信号处理器中调用 wait。如果 SIGCHLD 已通过 SIG_IGN 显示忽略,则一直阻塞直到所有子进程退出,此时返回 -1,errno 设置为 ECHILD,同场景 1。
waitpid
相对 wait 有三方面改进:
- 可指定等待的子进程
- 可查询子进程状态
- 可不阻塞试探
pid 参数比较灵活,既可指定进程 ID 也可指定进程组 ID:
- -1:任意子进程,等价于 wait
- > 0:指定进程 ID
- < -1:绝对值指定进程组 ID
- 0:进程组 ID 等于调用进程的任意子进程
注意第二个场景,虽然这里的 pid 可以任意指定,但如果不是调用进程的子进程,依然还是会出错 (ECHILD)。
status 参数返回进程终止状态,成功返回时,可用之前介绍过的 WIFXXX 进行进程状态判断;若不关心,可设置为 NULL。
options 参数可以指定以下值:
- WNOHANG:不阻塞,若无合适条件的子进程则立即返回,返回值为 0
- WCONTINUED:用于作业控制,若已挂起的子进程在继续运行后未报告状态,则返回其状态
- WUNTRACED:用于作业控制,若已挂起的子进程还未报告其状态,则返回其状态
- WNOWAIT:不破坏子进程终止状态,后续仍可以被 wait (仅 Solaris 支持)
中间两个选项用于作业控制,可用来获取子进程当前的状态,成功返回时,可用 WIFSTOPPED & WIFCONTINUED 去判断进程状态,一般为终端程序所用。
WNOHANG 在有合适条件的子进程时,会返回子进程的 PID 与终止状态,它提供了一种试探的能力。
waittid
是 waitpid 的一个变形,允许以更直观的方式提供进程 ID,它的 idtype 参数指定了 id 参数的含义:
- P_ALL:忽略 id,等待任一进程
- P_PID:id 表示一个特定进程,等待该进程
- P_PGID:id 表示一个特定进程组,等待该进程组中任意一个进程
从组合上讲与 waitpid 功能一致,但实用性上不如 waitpid,waitpid 指定 0 就可以等待同进程组的子进程,waittid 还要明确指定一个进程组,不方便。优点是后者代码看起来会更清晰一些。
options 参数与 waitpid 大同小异:
- WNOHANG:同上
- WNOWAIT:同上,所有平台都支持
- WCONTINUED:同上
- WSTOPPED: 同 WUNTRACED
- WEXITED:等待正常退出的进程
信号相关的信息存放在 infop 参数中,相比之前只能拿到一个信号编号要丰富多了。
wait3 & wait4
并非标准的一部分,但大部分 Unix 平台均提供了,主要增加了被等待进程 (及其所有子进程) 使用的资源汇总 (rusage),除去这部分,wait3 等价于:
waitpid(-1, status, options);wait4 等价于:
waitpid(pid, status, options);资源汇总主要统计以下内容:
struct rusage {
struct timeval ru_utime; /* user CPU time used */
struct timeval ru_stime; /* system CPU time used */
long ru_maxrss; /* maximum resident set size */
long ru_ixrss; /* integral shared memory size */
long ru_idrss; /* integral unshared data size */
long ru_isrss; /* integral unshared stack size */
long ru_minflt; /* page reclaims (soft page faults) */
long ru_majflt; /* page faults (hard page faults) */
long ru_nswap; /* swaps */
long ru_inblock; /* block input operations */
long ru_oublock; /* block output operations */
long ru_msgsnd; /* IPC messages sent */
long ru_msgrcv; /* IPC messages received */
long ru_nsignals; /* signals received */
long ru_nvcsw; /* voluntary context switches */
long ru_nivcsw; /* involuntary context switches */
};就是一些 CPU 时间、内存占用、页错误、信号接收次数等信息,有兴趣的可以 man getrusage 查看。
进程时间
司空见惯的 time 命令,是基于 wait3 实现时间统计的:
$ time sleep 3
real 0m3.001s
user 0m0.000s
sys 0m0.001s其中
- real 为经历时间 (elapse)
- user 为用户 CPU 时间
- sys 为系统 CPU 时间
与 rusage 结构中字段的对应关系为:
- user:ru_utime
- sys: ru_stime
具体可参考附录 7。
除了通过 wait3 / wait4 获取被等待进程 CPU 时间外,通过 times 接口还能获取任意时间段的进程 CPU 时间:
#include <sys/times.h>
struct tms {
clock_t tms_utime; /* user time */
clock_t tms_stime; /* system time */
clock_t tms_cutime; /* user time of children */
clock_t tms_cstime; /* system time of children */
};
clock_t times(struct tms *buf);time 命令中 real、user、sys 三种时间与 times 的对应关系如下:
- real:两次 times 返回值的差值
- user:tms_utime 差值 + tms_cutime 差值
- sys:tms_stime 差值 + tms_cstime 差值
不过上述参数均以 clock_t 为单位,是时钟滴答数 (tick),还需将它转换为时间:sec = tick / sysconf(_SC_CLK_TK),后者表示每秒的 tick 数:
> getconf CLK_TCK
100times 与 wait3 / wait4 另外一个差别是可以区分父、子进程的时间消耗,不过要统计子进程的 CPU 消耗,需要满足以下两个条件:
- 子进程在 times 统计的时间段内终止
- 终止时被父进程 wait 到了
apue 中有一个绝好的例子,演示了 times 的使用方法,这里稍作修改验证上面的说法:
#include "../apue.h"
#include <sys/types.h>
#include <sys/times.h>
#include <sys/wait.h>
static void pr_times (clock_t, struct tms *, struct tms *);
static void do_cmd (char *);
int main (int argc, char *argv[])
{
int i;
int status;
pid_t pid;
struct tms start, stop;
clock_t begin, end;
for (i=1; i<argc; i++)
do_cmd (argv[i]);
if ((begin = times (&start)) == -1)
err_sys ("times error");
while (1)
{
pid = wait (&status);
if (pid < 0)
{
printf ("wait all children\n");
break;
}
printf ("wait child %d\n", pid);
pr_exit (status);
if ((end = times (&stop)) == -1)
err_sys ("times error");
pr_times (end-begin, &start, &stop);
printf ("---------------------------------\n");
}
exit (0);
}
static void do_cmd (char *cmd)
{
int status;
pid_t pid = fork ();
if (pid < 0)
err_sys ("fork error");
else if (pid == 0)
{
// children
fprintf (stderr, "\ncommand: %s\n", cmd);
if ((status = system (cmd)) < 0)
err_sys ("system () error");
pr_exit (status);
exit (status);
}
else
printf ("fork child %d\n", pid);
}
static void pr_times (clock_t real, struct tms *start, struct tms *stop)
{
static long clktck = 0;
if (clktck == 0)
if ((clktck = sysconf (_SC_CLK_TCK)) < 0)
err_sys ("sysconf error");
clock_t diff = 0;
fprintf (stderr, " real: %7.2f\n", real / (double)clktck);
diff = (stop->tms_utime - start->tms_utime);
fprintf (stderr, " user: %7.2f (%ld)\n", diff/(double) clktck, diff);
diff = (stop->tms_stime - start->tms_stime);
fprintf (stderr, " sys: %7.2f (%ld)\n", diff/(double)clktck, diff);
diff = (stop->tms_cutime - start->tms_cutime);
fprintf (stderr, " child user: %7.2f (%ld)\n", diff/(double)clktck, diff);
diff = (stop->tms_cstime - start->tms_cstime);
fprintf (stderr, " child sys: %7.2f (%ld)\n", diff/(double)clktck, diff);
}主要做了如下改动:
- 将传入的命令放在子进程中执行 (do_cmd)
- 时间统计放在 while 循环中不断 wait 子进程后,直接没有子进程运行后才退出
为了使例子更具真实性,传递进来的两个命令都执行 dd 文件拷贝操作,只不过第二个命令拷贝的数据量是第一个的 2 倍:
> ./childtime "dd if=/dev/urandom of=./out1 bs=1M count=512" "dd if=/dev/urandom of=./out2 bs=1M count=1024"
fork child 3837
command: dd if=/dev/urandom of=./out1 bs=1M count=512
fork child 3838
command: dd if=/dev/urandom of=./out2 bs=1M count=1024
512+0 records in
512+0 records out
536870912 bytes (537 MB) copied, 7.2026 s, 74.5 MB/s
normal termination, exit status = 0
wait child 3837
normal termination, exit status = 0
real: 7.21
user: 0.00 (0)
sys: 0.00 (0)
child user: 0.00 (0)
child sys: 7.03 (703)
---------------------------------
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 10.5758 s, 102 MB/s
normal termination, exit status = 0
wait child 3838
normal termination, exit status = 0
real: 10.58
user: 0.00 (0)
sys: 0.00 (0)
child user: 0.00 (0)
child sys: 17.45 (1745)
---------------------------------
wait all children有以下发现:
- dd1 结束时,real 时间与 dd1 自己统计的接近 (7.21 => 7.2026)
- dd1 的 CPU 主要消耗在 sys 上,且与 real 时间接近 (7.03 => 7.21)
- dd2 结束时,real 时间与 dd2 自己统计的接近 (10.58 => 10.5758)
- dd2 的 CPU 也消耗在 sys 上,但远远大于自己的 real 时间 (10.58 => 17.45),这是因为它包含的是两个子进程的 sys 时间,需要减去 dd1 的 sys 时间 (17.45 - 7.03 = 10.45),此时与自己的 real 时间接近
- 对比两次 dd 的 sys CPU 消耗,会发现 dd2 小于 2 倍 dd1 的消耗 (7.03 => 10.45),这与 dd2 平均速度大于 dd1 的结果吻合 (74.5 => 102),速度快了,耗时相应的就降了;而速度提升,很可能与 dd1 退出不再抢占系统资源有关
- 总 CPU 时间 17.45,而总耗时只有 10.58,并行执行任务有效的降低了等待时间
对程序稍加修改,每次等待到子进程后更新 start 与 begin:
while (1)
{
pid = wait (&status);
if (pid < 0)
{
printf ("wait all children\n");
break;
}
printf ("wait child %d\n", pid);
pr_exit (status);
if ((end = times (&stop)) == -1)
err_sys ("times error");
pr_times (end-begin, &start, &stop);
begin = end;
start = stop;
printf ("---------------------------------\n");
}再次运行上面的程序:
> ./childtime "dd if=/dev/urandom of=./out1 bs=1M count=512" "dd if=/dev/urandom of=./out2 bs=1M count=1024"
fork child 7928
command: dd if=/dev/urandom of=./out2 bs=1M count=1024
512+0 records in
512+0 records out
536870912 bytes (537 MB) copied, 9.92325 s, 54.1 MB/s
normal termination, exit status = 0
wait child 7927
normal termination, exit status = 0
real: 9.93
user: 0.00 (0)
sys: 0.00 (0)
child user: 0.00 (0)
child sys: 6.93 (693)
---------------------------------
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 13.499 s, 79.5 MB/s
normal termination, exit status = 0
wait child 7928
normal termination, exit status = 0
real: 3.57
user: 0.00 (0)
sys: 0.00 (0)
child user: 0.00 (0)
child sys: 10.34 (1034)
---------------------------------
wait all children与之前相比,子进程的 CPU 时间能真实的反映自己的情况了,其它的差别不大。通过这两个例子,验证了 times 统计子进程时间的第一个特点:子进程不结束时,times 无法获取它的进程时间数据;关于第二个特点,感兴趣的读者,可以尝试使用 sleep 代替 wait 子进程,看看是否还能得到正确的统计。
关于子进程时间统计的实现,下面是我的一些个人想法:当有子进程结束且被父进程 wait 后,它的进程时间数据就会被累加到父进程的子进程时间中 (tms_cutime & tms_cstime),从而供 times 获取;若用户使用的是 wait3 / wait4,则这份子进程时间数据会和父进程时间数据相加后再返回给用户;若子进程也 wait 了它的子进程,那么这个数据还有"递归"效果,只不过在被累计至父进程时,孙子进程的时间就和子进程区分不开了,统统计入子进程一栏。
当然了,这个机制是"君子协定",如果哪个子进程没有遵守规定,不给自己的子进程"善后",那么最终统计出的时间就不准确,不过总的来说实际时间是只大不小,可以换个名称如"至少进程时间",就更贴切了。
system
glibc 基于 fork+exec+wait 玩了很多花样,典型的如 system、popen & pclose:
#include <stdlib.h>
int system(const char *command);
#include <stdio.h>
FILE *popen(const char *command, const char *type);
int pclose(FILE *stream);system 可以接收任何 shell 能接受的命令,典型的如 date > log.txt 这种带 shell 重定向功能的命令,甚至是一段 shell 脚本:for file in "*.c"; do echo $file; done,当参数为 NULL 时,system 返回值表示 shell 是否可用,目前大多数系统中,都返回 1。真实 system 源码比较复杂,书上模拟了一个 system 的实现:
#include <unistd.h>
#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <errno.h>
int my_system (const char *cmdstring)
{
pid_t pid;
int status;
if (cmdstring == NULL)
return 1;
if ((pid = fork ()) < 0)
{
status = -1;
}
else if (pid == 0)
{
printf ("before calling shell: %s\n", cmdstring);
execl ("/bin/sh", "sh", "-c", cmdstring, (char *)0);
_exit (127);
}
else
{
while (waitpid (pid, &status, 0) < 0)
{
if (errno != EINTR)
{
printf ("wait cmd failed, errno = %d\n", errno);
status = -1;
break;
}
}
printf ("wait cmd, status = %d\n", status);
}
return (status);
}通过 fork 子进程后 execl 调用 sh 进程,并将 cmdstring 通过 shell 的 -c 选项传入,最后在父进程 waitpid 等待子进程终结,中间考虑了信号中断的场景。下面这个程序演示了 my_system 的调用:
#include "../apue.h"
extern int my_system (const char *cmdstring);
int main (int argc, char *argv[])
{
int status;
if (argc < 2)
err_quit ("command-line argument required");
if ((status = my_system (argv[1])) < 0)
err_sys ("system () error");
pr_exit (status);
exit (0);
}通过命令行传递任何想要测试的内容:
> ./tsys "date > log.txt"
normal termination, exit status = 0
> cat log.txt
Fri Mar 15 16:44:35 CST 2024这样做也有缺点:所有传递给 system 接口的参数必需和命令放在一个参数中,假如想要执行如下命令:ps -exjf,不能写成:./tsys ps -exjf,必需写成:./tsys "ps -exjf"。不放在一起也可以,需要将调用 execl 改为 execv,并根据 main 的 argv 参数构造新的参数数组 (假设为 argv_new) 传递给新命令,而 argv_new 前两个参数是固定的,分别是 sh 和 -c,最后以 NULL 结尾。
此外也可以不依赖 shell 直接基于 exec 函数族去做,将 cmdstring 中的命令名与参数传递给 exec 即可,仍以 ps 命令为例,最终执行的是下面的代码:
execlp (argv[1], argv[1] /*ps*/, argv[2] /*-exjf*/, (char *)0);这里需要有两个改变:
- 使用 execlp 或 execvp 以便在用户只给命令名时,可在 PATH 环境变量中查找命令所在位置
- 用户将需要执行的命令和参数单独罗列而不是写成一行,否则还需要解析 cmdstring 中的各个字段
结合以上分析,这里最合适的接口还是 execvp,直接传递 &argv[1] 就可以了。
不过这种直接调用 exec 的方式也有缺点,就是不能享受 shell 提供的能力了,譬如:重定向、shell 脚本甚至 shell 元字符,所以目前大部分 glibc 的实现还是通过调用 shell 的。
关于 system 接口还有一个需要说明的用例是 set-uid 程序,这主要表现在两方面:
- 普通用户使过 system 调用 set-uid 为 root 的程序,新命令将具有特权
- 通过 set-uid 为 root 获取特权的进程使用 system 调用普通程序,新命令将不具有特权
第一点比较好理解,主要是 exec 的工作;第二点比较依赖 shell,bash 2.0 之后的版本会检查 RUID 与 EUID,如果不一致,会将 EUID 设置为 RUID,从而避免安全漏洞。如果直接使用 exec 启动新命令的话,特权是会被保留的。下面基于 setuid 程序和 tsys 做一个测试:
> ls -lh tsys setuid
-rwxr-xr-x 1 yunhai01 DOORGOD 53K Mar 15 15:54 setuid
-rwxr-xr-x 1 yunhai01 DOORGOD 52K Mar 15 15:54 tsys
> ./tsys ./setuid
29059: ruid 383278, euid 383278, suid 383278
normal termination, exit status = 0
> su
Password:
$ ./tsys ./setuid
29358: ruid 0, euid 0, suid 0
normal termination, exit status = 0
$ chown root:root tsys
$ chmod u+s tsys
$ suspend
[4]+ Stopped su
> ls -lh tsys setuid
-rwxr-xr-x 1 yunhai01 DOORGOD 53K Mar 15 15:54 setuid
-rwsr-xr-x 1 root root 52K Mar 15 15:54 tsys
> ./tsys ./setuid
29754: ruid 383278, euid 383278, suid 383278
normal termination, exit status = 0
> fg
su
$ chown yunhai01:DOORGOD tsys
$ exit
exit
> ls -lh tsys setuid
-rwxr-xr-x 1 yunhai01 DOORGOD 53K Mar 15 15:54 setuid
-rwxr-xr-x 1 yunhai01 DOORGOD 52K Mar 15 15:54 tsys使用的 bash 版本 4.2.46。第三次 tsys 设置为 set-uid root 后,它启动的 ./setuid 的输出来看,与预期一致,bash 拦截了不安全的特权继承。
进程核算
ps 命令可以查看系统当前运行的进程,类似地,lastcomm 可以查看已经终止的进程,不过需要手动开启进程核算 (accounting,也称为进程会计)。
accton
不同平台都是通过 accton 命令开启进程核算的,但用法略有不同:
| 平台 | 默认开启 | 带文件开启 | 关闭 | 默认 acct 文件 |
| Linux | sudo accton on | sudo accton /path/to/acctfiles | sudo accton off | /var/account/pacct |
| macOS/FreeBSD | n/a | sudo accton /path/to/acctfiles | sudo accton | /var/account/acct |
| Solaris | n/a | sudo accton /path/to/acctfiles | sudo accton | /var/adm/pacct |
做个简单说明:
- Linux 上如果不指定 acct 文件路径,则必需指定 on 或 off 参数,不指定路径时使用默认 acct 文件
- macOS 上不能指定 on 或 off 参数,要开启进程核算必需指定 acct 文件路径,指定的路径不存在时会出错,需要手动创建。不带路径时表示关闭核算
acct & struct acct
它们底层都是调用 acct 接口完成核算的开启和关闭:
#include <unistd.h>
int acct(const char *filename);开启进程核算后,内核会在进程终止时记录一条信息到 acct 文件中,它在 C 语言中就是一个结构体 struct acct。由于进程核算并不是 POSIX 标准的一部分,各个平台在这里的实现差异比较大,在 Linux 上:
#define ACCT_COMM 16
typedef u_int16_t comp_t;
struct acct {
char ac_flag; /* Accounting flags */
u_int16_t ac_uid; /* Accounting user ID */
u_int16_t ac_gid; /* Accounting group ID */
u_int16_t ac_tty; /* Controlling terminal */
u_int32_t ac_btime; /* Process creation time
(seconds since the Epoch) */
comp_t ac_utime; /* User CPU time */
comp_t ac_stime; /* System CPU time */
comp_t ac_etime; /* Elapsed time */
comp_t ac_mem; /* Average memory usage (kB) */
comp_t ac_io; /* Characters transferred (unused) */
comp_t ac_rw; /* Blocks read or written (unused) */
comp_t ac_minflt; /* Minor page faults */
comp_t ac_majflt; /* Major page faults */
comp_t ac_swaps; /* Number of swaps (unused) */
u_int32_t ac_exitcode; /* Process termination status
(see wait(2)) */
char ac_comm[ACCT_COMM+1];
/* Command name (basename of last
executed command; null-terminated) */
char ac_pad[X]; /* padding bytes */
};
enum { /* Bits that may be set in ac_flag field */
AFORK = 0x01, /* Has executed fork, but no exec */
ASU = 0x02, /* Used superuser privileges */
ACORE = 0x08, /* Dumped core */
AXSIG = 0x10 /* Killed by a signal */
};在 macOS 上:
/*
* Accounting structures; these use a comp_t type which is a 3 bits base 8
* exponent, 13 bit fraction ``floating point'' number. Units are 1/AHZ
* seconds.
*/
typedef u_short comp_t;
struct acct {
char ac_comm[10]; /* name of command */
comp_t ac_utime; /* user time */
comp_t ac_stime; /* system time */
comp_t ac_etime; /* elapsed time */
time_t ac_btime; /* starting time */
uid_t ac_uid; /* user id */
gid_t ac_gid; /* group id */
short ac_mem; /* memory usage average */
comp_t ac_io; /* count of IO blocks */
dev_t ac_tty; /* controlling tty */
#define AFORK 0x01 /* forked but not execed */
#define ASU 0x02 /* used super-user permissions */
#define ACOMPAT 0x04 /* used compatibility mode */
#define ACORE 0x08 /* dumped core */
#define AXSIG 0x10 /* killed by a signal */
char ac_flag; /* accounting flags */
};在 Solaris 上:
typedef ushort comp_t; /* pseudo "floating point" representation */
/* 3 bit base-8 exponent in the high */
/* order bits, and a 13-bit fraction */
/* in the low order bits. */
struct acct
{
char ac_flag; /* Accounting flag */
char ac_stat; /* Exit status */
uid_t ac_uid; /* Accounting user ID */
gid_t ac_gid; /* Accounting group ID */
dev_t ac_tty; /* control tty */
time_t ac_btime; /* Beginning time */
comp_t ac_utime; /* accounting user time in clock */
/* ticks */
comp_t ac_stime; /* accounting system time in clock */
/* ticks */
comp_t ac_etime; /* accounting total elapsed time in clock */
/* ticks */
comp_t ac_mem; /* memory usage in clicks (pages) */
comp_t ac_io; /* chars transferred by read/write */
comp_t ac_rw; /* number of block reads/writes */
char ac_comm[8]; /* command name */
};
/*
* Accounting Flags
*/
#define AFORK 01 /* has executed fork, but no exec */
#define ASU 02 /* used super-user privileges */
#define ACCTF 0300 /* record type */
#define AEXPND 040 /* Expanded Record Type - default */下面这个表总结了各个平台上 struct acct 的差异:
| acct 字段 | Linux | macOS | FreeBSD | Solaris | |
| ac_flag | AFORK (仅 fork 不 exec) | * | * | * | * |
| ASU (超级用户进程) | * | * | * | ||
| ACOMPAT | * | ||||
| ACORE (发生 coredump) | * | * | * | ||
| AXSIG (被信号杀死) | * | * | * | ||
| AEXPND | * | ||||
| ac_stat (signal & core flag) | * | ||||
| ac_exitcode | * | ||||
| ac_uid / ac_gid / ac_tty | * | * | * | * | |
| ac_btime / ac_utime / ac_stime / ac_etime | * | * | * | * | |
| ac_mem | * (kB/?) | * (?) | * (?) | * (page/click) | |
| ac_io | * (unused) | * (block) | * (block) | * (bytes) | |
| ac_rw | * (unused) | * (block) | |||
| ac_comm | * (17) | * (10) | * (16) | * (8) | |
做个简单说明:
- 对于异常退出的场景,Linux & macOS & FreeBSD 是通过 ac_flag 来记录;Solaris 则通过单独的 ac_stat 来记录
- 对于正常退出的场景,只有 Linux 的 ac_exitcode 可以记录进程退出状态,其它平台都没有这个能力
- 对于进程时间
- ac_btime 开始时间为 epoch 时间,单位为秒
- ac_utime 为用户 CPU 时间,单位为 ticks,含义同 rusage.ru_utime 或 tms.tms_utime
- ac_stime 为系统 CPU 时间,单位为 ticks,含义同 rusage.ru_stime 或 tms.tms_stime
- ac_etime 为实际经历时间,单位为 ticks,含义同 time 命令中的 real 时间
- 对于进程 IO 统计
- macOS & FreeBSD 倾向于使用块作为单位,然而当块大小发生变更后,这个统计实际上会失真
- Solaris 做的好一些,使用的是字节,它也有基于块为单位的统计,即 ac_rw
- Linux 则根本不具备统计进程 IO 的能力,这两个字段虽然存在却总为 0
- 对于进程名,各个平台均支持,但长度不一致。最长为 Linux 17 字节,最短为 Solaris 8 字节,即使是最长的 Linux,在目前看来也不够用,不过考虑到记录数太过庞大,这点可以原谅
进程核算所需的各种数据都由内核保存在进程表中,并在一个新进程被创建时置初值 (通常是 fork 之后的子进程),每次进程终止时都会追加一条结算记录,这意味着 acct 文件中记录的顺序对应于进程终止顺序而不是启动顺序。配合上面的数据结构会导致一个问题——无法确定进程的启动顺序:
- 想推导进程的启动顺序时,通常想到的方法是读取全部结算记录,按 ac_btime 进行排序,但因日历时间的精度是秒,在一秒内可能启动了多个进程,所以这种排序结果是不准确的
- ac_etime 的单位是时钟滴答 (ticks),每秒 ticks 通常在 60~128 之间,这个精度是够了,但由于没有记录进程的准确结束时间,所以也无法反推它的准确启动时间
第二种方案通过记录进程的准确结束时间来反推进程准确启动时间,还不如就在一开始记录准确启动时间。例如增加一个字段记录启动毫秒数,那 Unix 为何不这样做?我能想到的一个答案——最小化存储空间占用。增加一个毫秒字段至少需要 2 字节,而一个短整型最大可以表达 65535,对于毫秒而言,数值 1000 以上的空间都无法使用,考虑到庞大记录数,这是一笔可观的存储浪费。再看看 ac_utime / ac_stime / ac_etime 的设计,通过 2 字节类型 (comp_t) 实现了 10ms 的时间精度,反过来看前者的设计,在早期存储空间寸土寸金的时代,简直就是一种无法容忍的挥霍行为。
由于进程核算的起始锚定 fork 而非 exec、且只在进程终止时记录一条信息,这导致另外一个问题——多次 exec 的进程只记录最后进程的信息,前面 exec 过的进程像“隐身”一样消失了,就如同它从来没在系统中存在过一样,所以 acct 文件也不可全信,即某些进程不在 acct 文件中不代表它不存在。最简单的做法,一个黑客可以在恶意程序的最后 exec 一个普通命令,来达到抹去 acct 记录的目的。
exec loop
为了验证多次 exec 的场景,先写一个可以循环 exec 的测试程序:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main (int argc, char *argv[])
{
char const* exename=0;
if (argc > 1)
exename = argv[1];
else
exename = "date";
sleep (1);
printf ("%d, start exec: %s\n", getpid(), exename);
if (argc > 1)
execvp (exename, &argv[1]);
else
execlp (exename, exename, (char *)0);
printf ("should not reach here, exec failed?\n");
abort();
}这个程序会将参数列表作为一个新程序执行,其中 argv[1] 是新程序名,后面是它的参数,如果参数不足 2,则使用默认的 date 命令。如此就可以通过下面的调用执行一个多次 exec 的进程:
> ./exec_loop ./exec_loop ./exec_loop ./exec_loop ps -exjf
32166, start exec: ./exec_loop
32166, start exec: ./exec_loop
32166, start exec: ./exec_loop
32166, start exec: ps
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
11332 11364 11332 11332 ? -1 S 383278 0:00 sshd: yunhai01@pts/0
11364 11370 11370 11370 pts/0 32166 Ss 383278 0:00 \_ bash -c /usr/bin/baas login --baas_user=yunhai01 --baas_role=baas_all_pri
11370 11442 11442 11370 pts/0 32166 S 383278 0:00 \_ /bin/bash -l XDG_SESSION_ID=398726 TERM=xterm SHELL=/bin/bash SSH_CLI
11442 32166 32166 11370 pts/0 32166 R+ 383278 0:00 \_ ps -exjf XDG_SESSION_ID=398726 HOSTNAME=yunhai.bcc-bdbl.baidu.com上面的过程开启 accton 录制,通过书上的解读 acct 文件的程序 (vacct) 解析后,得到下面的记录:
> sudo ./vacct
clock tick: 100
sizeof (acct) = 64
...
ps e = 401.00, chars = 0, stat = 0:
...系统中同时运行的命令太多,通过 grep 过滤,发现没有任何 exec_loop 记录;ps 记录的 elapse 时间为 401 ticks,约 4 秒,和测试程序每 exec 一个命令 sleep 1 秒吻合。看起来确实只记录了最后的一个进程。
通过给 exec_loop 一个无法执行的命令,看看会有何改变:
> ./exec_loop ./exec_loop ./exec_loop ./exec_loop this_cmd_not_exist
20313, start exec: ./exec_loop
20313, start exec: ./exec_loop
20313, start exec: ./exec_loop
20313, start exec: this_cmd_not_exist
should not reach here, exec failed?
Aborted (core dumped)
...
$ sudo ./vacct | grep exec_loop
exec_loop e = 403.00, chars = 0, stat = 134: D X最终记录的是上一个执行成功的 exec_loop (elapse 4 秒),并且它的终止状态为接受信号后 (X) coredump (D),其中 stat 134 的高位 (第 8 位) 表示 coredump (128),低 7 位为 6 表示接受的信号 (SIGABRT)。
对于 abort,Linux 的表现与书上 Solaris 例子不同,书上不会有 D & X 两个标志位。关于这一点,通过重跑书上的那个多次 fork 的例子 (oacct) 也可以看清楚:
> ./vacct | grep -E 'oacct|dd|accton'
accton e = 0.00 , chars = 0, stat = 0: S
dd e = 0.00 , chars = 0, stat = 0:
oacct e = 200.00, chars = 0, stat = 0:
oacct e = 402.00, chars = 0, stat = 134: D X F
oacct e = 600.00, chars = 0, stat = 9: X F
oacct e = 800.00, chars = 0, stat = 0: F
accton e = 0.00 , chars = 0, stat = 0: S
accton e = 0.00 , chars = 0, stat = 0:这个例子通过 fork 生成了 4 个子进程,除其中一个调用 exec 执行 dd 外其它的均没有 exec,下面对各个 oacct 记录做个说明:
- 父进程,sleep 2;exit 2
- 第一个子进程,sleep 4;abort
- 第四个子进程,sleep 6;kill
- 第三个子进程,sleep 8;exit 0
- dd 为第二个子进程,未 sleep 所以结束最快
各项 ac_flag 值都能正确展示,其中 F 是首次出现,表示只 fork 未 exec 的进程,后面会看到,作者使用的 ac_flag 助词符与系统命令完全一致。
lastcomm
如果不需要查看 ac_etime,使用 lastcomm 命令也不错,以上面三个场景为例,分别输出如下:
> sudo lastcomm yunhai01 -f /var/accout/pacct.old
ps yunhai01 pts/0 0.01 secs Mon Mar 25 11:55
> sudo lastcomm yunhai01
exec_loop DX yunhai01 pts/0 0.00 secs Mon Mar 25 12:10
$ sudo lastcomm yunhai01 -f /var/account/pacct-20240322
oacct F yunhai01 pts/0 0.00 secs Thu Mar 21 15:02
oacct F X yunhai01 pts/0 0.00 secs Thu Mar 21 15:02
oacct F DX yunhai01 pts/0 0.00 secs Thu Mar 21 15:02
oacct yunhai01 pts/0 0.00 secs Thu Mar 21 15:02
dd yunhai01 pts/0 0.00 secs Thu Mar 21 15:02因为访问的 acct 文件具有超级用户权限,所以这里也需要 sudo 提权。关于 lastcomm 输出的各个字段,man 手册页有一段说明:
For each entry the following information is printed:
+ command name of the process
+ flags, as recorded by the system accounting routines:
S -- command executed by super-user
F -- command executed after a fork but without a following exec
C -- command run in PDP-11 compatibility mode (VAX only)
D -- command terminated with the generation of a core file
X -- command was terminated with the signal SIGTERM
+ the name of the user who ran the process
+ time the process started分别是:命令名、标志位、用户、终端、进程启动时间等,标志位与 ac_flag 有如下对应关系:
- S:ASU
- F:AFORK
- C:ACOMPAT
- D:ACORE
- X:AXSIG
另外除了启动时间,还打印了 xxx secs 的信息,经过对比应该不是 ac_etime,怀疑是 ac_utime、ac_stime 之一或之和。
通过 -f 可指定不同于默认路径的 acct 文件;通过参数可以筛选命令、用户、终端,关键字的顺序不重要,lastcomm 将用它们在全域进行匹配,只要有任一匹配成功,就会输出记录,相当于是 OR 的关系。例如用户想筛选名为 foo 的用户,会将名为 foo 的命令也给筛选出来,为了减少这种乌龙事件,lastcomm 也支持指定域匹配:
> lastcomm --strict-match --command ps --user yunhai01 --tty pts/0这种情况下,各个条件之间是 AND 的关系,只有匹配所有条件的记录才会输出。
dump-acct
如果仅在 Linux 上使用,dump-acct 可以输出比 lastcomm 更丰富的信息:
> dump-acct /var/account/pacct-20240322 | grep 383278
dd |v3| 0.00| 0.00| 0.00|383278|100000|108096.00| 0.00| 25047 25046|Thu Mar 21 15:02:35 2024
oacct |v3| 0.00| 0.00| 200.00|383278|100000| 4236.00| 0.00| 25045 19543|Thu Mar 21 15:02:35 2024
oacct |v3| 0.00| 0.00| 402.00|383278|100000| 4236.00| 0.00| 25046 1|Thu Mar 21 15:02:35 2024
oacct |v3| 0.00| 0.00| 600.00|383278|100000| 4236.00| 0.00| 25049 25048|Thu Mar 21 15:02:35 2024
oacct |v3| 0.00| 0.00| 800.00|383278|100000| 4236.00| 0.00| 25048 1|Thu Mar 21 15:02:35 2024记录比较多,通过 grep 过滤了用户 ID。各列含义如下:
- 命令名:ac_comm
- 版本号,关于 v3 请参考 Linux 扩展:acct_v3
- 用户 CPU 时间:ac_utime
- 系统 CPU 时间:ac_stime
- 经历时间:ac_etime
- 用户 ID:v3 扩展
- 组 ID:v3 扩展
- 内存使用:ac_mem
- IO:ac_io
- 进程 ID:v3 扩展
- 父进程 ID:v3 扩展
- 启动时间:ac_btime
信息比 lastcomm 丰富,但是缺少对 ac_flag 的展示,这方面还得借助书上的实用工具 (vacct)。
比较有趣的是上例中父进程 ID 的打印,从进程号可以直观的发现进程启动顺序:
- 25045:oacct 为父进程,sleep 2;exit 2
- 25046:oacct 为第一个子进程,sleep 4;abort。父进程为 1 应当是进程终止时父进程 25045 已结束被过继给 init 进程
- 25047:dd 为第二个子进程,未 sleep 所以结束最快。父进程为 25046 是第一个子进程,正常
- 25048:oacct 为第三个子进程,sleep 8;exit 0。父进程为 1 应当是进程终止时父进程 25047 已结束被过继给 init 进程
- 25049:oacct 为第四个子进程,sleep 6,kill 9。父进程 2504 是第三个子进程,正常
acct_v3 版本确实强大,通过父子进程 ID 复习了进程关系中的孤儿进程概念。
对于上节中 lastcomm xxx secs 打印的是 ac_utime 还是 ac_stime,这节可以给出答案:
sudo dump-acct /var/account/pacct.old | grep 383278
ps |v3| 0.00| 1.00| 401.00|383278|100000|153344.00| 0.00| 858 11442|Mon Mar 25 11:55:33 2024对比之前 lastcomm 的输出,ps 命令的 secs 字段为 0.1,对应的是 1 ticks,也就是这里的 ac_stime,可见肯定不是 ac_utime,但到底是系统 CPU 时间还是两者之和,由于这条记录的 ac_utime 为 0,没有办法确认了,需要再找一条记录看看:
> sudo lastcomm -f /var/account/pacct.old | grep argus_process_s
argus_process_s root __ 0.13 secs Mon Mar 25 11:55
> sudo dump-acct /var/account/pacct.old | grep argus_process_s
argus_process_s |v3| 12.00| 1.00| 36.00| 0| 0| 41160.00| 0.00| 908 20078|Mon Mar 25 11:55:36 2024这条记录看得更清楚了,0.13 s = 13 ticks = ac_utime (12) + ac_stime (1),所以最终的结论是:lastcomm 中 xxx secs 输出的是进程 CPU 总耗时 (ac_utime + ac_stime)。
sa
lastcomm & dump-acct 是针对单个记录的,如果想统计多个记录的信息,例如 CPU 总耗时、磁盘 IO 总次数、命令启动次数等,就需要使用 sa 命令了,针对 lastcomm 中的 oacct 的例子使用 sa 统计,得到如下输出:
> sa /var/account/pacct-20240322
314 2.77re 0.01cp 0avio 19357k
3 0.02re 0.01cp 0avio 10295k argus_process_s
13 0.04re 0.00cp 0avio 32597k ***other*
3 0.01re 0.00cp 0avio 188160k top
2 0.00re 0.00cp 0avio 234880k sudo
51 2.40re 0.00cp 0avio 1091k sleep
46 0.00re 0.00cp 0avio 3309k killall
28 0.00re 0.00cp 0avio 2454k monitor_webdir_*
21 0.00re 0.00cp 0avio 1093k wc
17 0.00re 0.00cp 0avio 2482k awk
17 0.00re 0.00cp 0avio 1099k date
14 0.00re 0.00cp 0avio 4888k ls
14 0.00re 0.00cp 0avio 2558k monitor_baas_ag*
14 0.00re 0.00cp 0avio 1627k hostname
13 0.00re 0.00cp 0avio 1096k cat
9 0.00re 0.00cp 0avio 2274k grep
8 0.00re 0.00cp 0avio 422528k noah-client*
6 0.00re 0.00cp 0avio 3310k bc
5 0.00re 0.00cp 0avio 2392k sh
4 0.00re 0.00cp 0avio 1091k getconf
3 0.30re 0.00cp 0avio 1059k oacct*
3 0.00re 0.00cp 0avio 181760k bscpserver
3 0.00re 0.00cp 0avio 1097k tr
3 0.00re 0.00cp 0avio 28848k gpu.sh
3 0.00re 0.00cp 0avio 2552k supervise.bscps*
3 0.00re 0.00cp 0avio 703k accton
3 0.00re 0.00cp 0avio 94k migstat
3 0.00re 0.00cp 0avio 91k gpustat
2 0.00re 0.00cp 0avio 1100k tail各列含义如下:命令出现次数、总经历时间、总 CPU 时间、平均 IO 次数、CPU 利用率、命令名。
与一般命令不同的是,sa 并不输出一个标题行,而是将各列的含义追加在数值后面,man 中对此有详细说明:
The output fields are labeled as follows:
cpu
sum of system and user time in cpu minutes
re
"elapsed time" in minutes
k
cpu-time averaged core usage, in 1k units
avio
average number of I/O operations per execution
tio
total number of I/O operations
k*sec
cpu storage integral (kilo-core seconds)
u
user cpu time in cpu seconds
s
system time in cpu seconds各个列与 struct acct 的对应关系是:
- u:ac_utime
- s:ac_stime
- cpu:ac_stime + ac_utime
- re:ac_etime,单位为 min
- avio/tio:ac_io
- k/k*sec:?
注意上面的输出中没有 dd 命令,原来为了简洁,小于 2 次的命令都会被折叠到 other 一栏中,需要使用 -a 选项展示它们:
> sa /var/account/pacct-20240322 -a
314 2.77re 0.01cp 0avio 19357k
3 0.02re 0.01cp 0avio 10295k argus_process_s
1 0.00re 0.00cp 0avio 57104k abrt-action-sav
3 0.01re 0.00cp 0avio 188160k top
2 0.00re 0.00cp 0avio 234880k sudo
1 0.00re 0.00cp 0avio 57088k abrt-server
1 0.00re 0.00cp 0avio 31120k abrt-hook-ccpp
1 0.00re 0.00cp 0avio 56576k abrt-handle-eve
51 2.40re 0.00cp 0avio 1091k sleep
46 0.00re 0.00cp 0avio 3309k killall
28 0.00re 0.00cp 0avio 2454k monitor_webdir_*
21 0.00re 0.00cp 0avio 1093k wc
17 0.00re 0.00cp 0avio 2482k awk
17 0.00re 0.00cp 0avio 1099k date
14 0.00re 0.00cp 0avio 4888k ls
14 0.00re 0.00cp 0avio 2558k monitor_baas_ag*
14 0.00re 0.00cp 0avio 1627k hostname
13 0.00re 0.00cp 0avio 1096k cat
9 0.00re 0.00cp 0avio 2274k grep
8 0.00re 0.00cp 0avio 422528k noah-client*
6 0.00re 0.00cp 0avio 3310k bc
5 0.00re 0.00cp 0avio 2392k sh
4 0.00re 0.00cp 0avio 1091k getconf
3 0.30re 0.00cp 0avio 1059k oacct*
3 0.00re 0.00cp 0avio 181760k bscpserver
3 0.00re 0.00cp 0avio 1097k tr
3 0.00re 0.00cp 0avio 28848k gpu.sh
3 0.00re 0.00cp 0avio 2552k supervise.bscps*
3 0.00re 0.00cp 0avio 703k accton
3 0.00re 0.00cp 0avio 94k migstat
3 0.00re 0.00cp 0avio 91k gpustat
2 0.00re 0.00cp 0avio 1100k tail
1 0.03re 0.00cp 0avio 1059k oacct
1 0.00re 0.00cp 0avio 164096k bcm-agent*
1 0.00re 0.00cp 0avio 27024k dd
1 0.00re 0.00cp 0avio 18752k ssh
1 0.00re 0.00cp 0avio 4066k iptables
1 0.00re 0.00cp 0avio 3280k lsmod
1 0.00re 0.00cp 0avio 2394k sh*
1 0.00re 0.00cp 0avio 1115k dmidecode
1 0.00re 0.00cp 0avio 90k gpu-int这次在倒数第 7 行有 dd 了。默认是按 cpu 倒序排列的,sa 也提供了大量选项来按其它字段排序,感兴趣的可自行 man 查看。
命令名后面的星号表示 AFORK 标志,例如上面的输出中,有两条 oacct 记录,1 个不带星号的是父进程,3 个带星号的是 fork 未 exec 的子进程,另外 1 个子进程就是 dd。
指定 -m 选项可以按用户级别查看统计信息:
> sa /var/account/pacct-20240322 -m
314 2.77re 0.01cp 0avio 19357k
root 309 2.44re 0.01cp 0avio 19569k
yunhai01 5 0.33re 0.00cp 0avio 6252k除了第一列增加了用户名,最后一列删除了命令名外,其余各列与之前相同。
总结一下,dump-acct、lastcomm、sa 命令之于 acct 文件的关系,与 w、who、last、lastb、ac 命令之于 utmp、wtmp、btmp 文件的关系类似,关于后者,可以参考《[apue] Unix 系统数据文件那些事儿》。
参考
[1]. Linux/Unix分配进程ID的方法以及源代码实现
[2]. Linux下如何在进程中获取虚拟地址对应的物理地址
[4]. Linux Clone函数
[5]. 浅谈linux下进程最大数、最大线程数、进程打开的文件数
[6]. 在 Linux 上以树状查看文件和进程
[7]. time命令busybox源码
[8]. 对argv可能的误解
[9]. 解释器、解释器文件
[10]. 如何使腳本的set-user-id位起作用
[11]. Linux setuid使用
[12]. acct——accounting utilities 统计工具
本文来自博客园,作者:goodcitizen,转载请注明原文链接:https://www.cnblogs.com/goodcitizen/p/things_about_process_control.html