Prometheus监控部署以及问题解决
Prometheus作用:
Prometheus监控(Prometheus Monitoring)是一种开源的系统监控和警报工具。它最初由SoundCloud开发并于2012年发布,并在2016年加入了云原生计算基金会(CNCF)。Prometheus监控旨在收集、存储和查询各种指标数据,以帮助用户监视其应用程序和系统的性能和运行状态。
部署流程:
本文采用Prometheus来监控k8s集群资源状态,并解决alertmanager 9093端口连接拒绝的问题
1.根据k8s集群版本下载对应矩阵的Prometheus版本
# 我的k8s集群版本为1.26.9,所以我下载0.13版本
wget https://mirror.ghproxy.com/https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.13.0.zip
# 下载完成后解压即可使用
unzip v0.13.0.zip


2.进入解压出来的目录,自定义配置告警规则和邮件推送(看需求)
cd kube-prometheus-0.13.0/manifests/
# 该文件配置告警规则
vim prometheus-prometheusRule.yaml
# 该文件配置告警推送
vim alertmanager-secret.yaml
3.部署Prometheus监控和删除
kubectl apply --server-side -f manifests/setup -f manifests
# 移除Prometheus
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
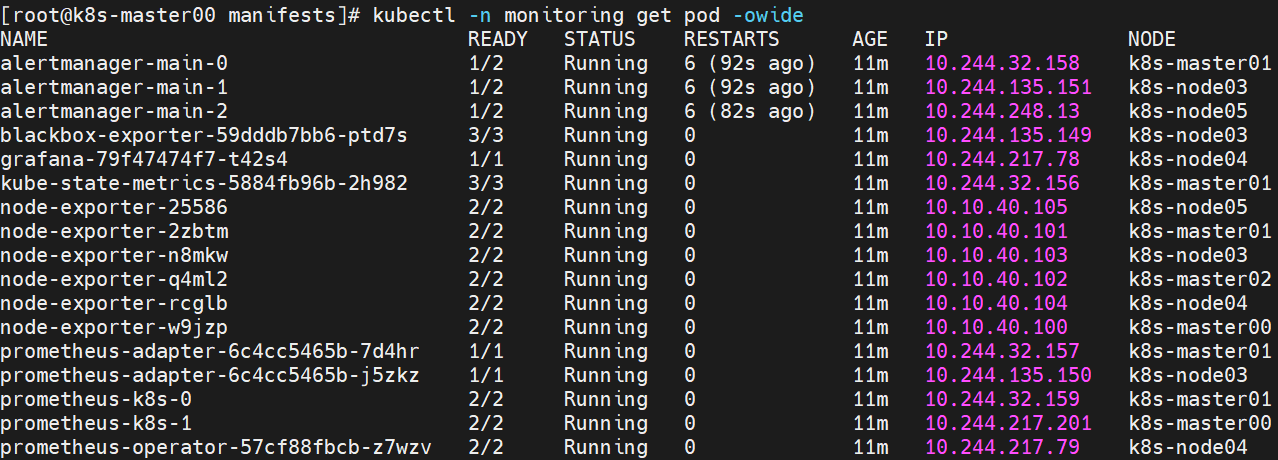
# 以下为部署完成后正常的资源状态

# 如果没有部署ingress则需要更改以下几个svc配置文件,将svc类型改为NodePort才能对外访问
kubectl -n monitoring edit svc alertmanager-main
kubectl -n monitoring edit svc prometheus-k8s
kubectl -n monitoring edit svc grafana
# 删除对应的网络策略,它默认限制了出口和入口流量,即便使用了 NodePort 类型的 svc 或者 ingress 也无法直接访问
kubectl -n monitoring delete networkpolicy --all


4.接下来说一下我之前遇到的问题
# 在我部署Prometheus监控服务的时候,我的alertmanager一直无法正常启动,查看状态发现了报错信息
kubectl -n monitoring describe pod alertmanager-main-1
# dial tcp 10.244.135.151:9093 connection refused
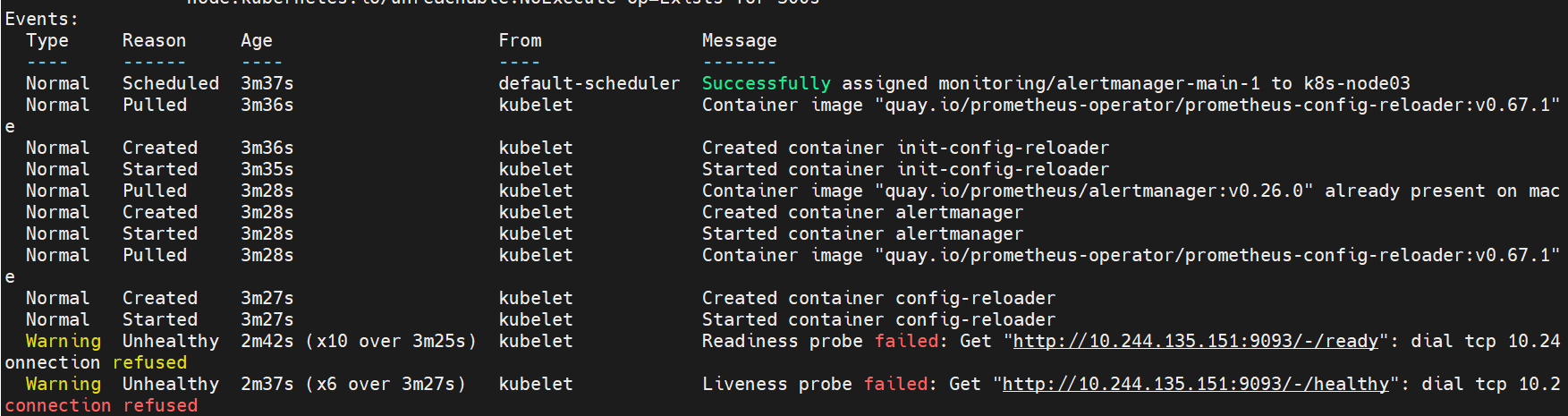
# 最开始在github官网查看issue时,发现有人遇到了相同的问题,并且也有人给出了解决办法,我试着按照他的方法解决,没成功。他要修改sts里的文件内容,你改了就会发现不管你怎么改,它都不会生效,并且你还删不掉它的sts,该sts是由(crd)自定义资源alertmanager main所控制的,你只有修改这个或者删除这个资源才能停掉sts
kubectl -n monitoring edit alertmanager main
kubectl -n monitoring delete alertmanager main
# 起初想着可能是探针超时时间太短了导致它一直无法通过检测,就修改了alertmanager main的文件,更改超时时间为300s,但还是有问题。后面把探针给它注释掉,不让它检测发现还是有问题。最后是直接把容器的端口给注释掉了,让它通过域名查找,发现了真正的问题
kubectl -n monitoring get alertmanager main -o yaml >
dump-modify.yaml
vim dump-modify.yaml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
creationTimestamp: "2024-08-19T08:12:24Z"
generation: 1
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.26.0
name: main
namespace: monitoring
resourceVersion: "510527"
uid: ee407f56-bffa-4191-baa7-e458e7a1b9ff
spec:
image: quay.io/prometheus/alertmanager:v0.26.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.26.0
portName: web
replicas: 3
logLevel: debug
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 4m
memory: 100Mi
retention: 120h
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: alertmanager-main
version: 0.26.0
containers:
- args:
- --config.file=/etc/alertmanager/config_out/alertmanager.env.yaml
- --storage.path=/alertmanager
- --data.retention=120h
- --cluster.listen-address=[$(POD_IP)]:9094
- --web.listen-address=:9093
- --web.route-prefix=/
- --cluster.peer=alertmanager-main-0.alertmanager-operated:9094
- --cluster.peer=alertmanager-main-1.alertmanager-operated:9094
- --cluster.peer=alertmanager-main-2.alertmanager-operated:9094
- --cluster.reconnect-timeout=5m
- --web.config.file=/etc/alertmanager/web_config/web-config.yaml
env:
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
image: quay.io/prometheus/alertmanager:v0.26.0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 10
httpGet:
path: /
port: 443
scheme: HTTPS
host: example.com
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
name: alertmanager
# ports:
# - containerPort: 9093
# name: web
# protocol: TCP
# - containerPort: 9094
# name: mesh-tcp
# protocol: TCP
# - containerPort: 9094
# name: mesh-udp
# protocol: UDP
readinessProbe:
failureThreshold: 10
httpGet:
path: /
port: 443
scheme: HTTPS
host: example.com
initialDelaySeconds: 3
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 3
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 4m
memory: 100Mi
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: FallbackToLogsOnError
volumeMounts:
- mountPath: /etc/alertmanager/config
name: config-volume
- mountPath: /etc/alertmanager/config_out
name: config-out
readOnly: true
- mountPath: /etc/alertmanager/certs
name: tls-assets
readOnly: true
- mountPath: /alertmanager
name: alertmanager-main-db
- mountPath: /etc/alertmanager/web_config/web-config.yaml
name: web-config
readOnly: true
subPath: web-config.yaml
# status:
# availableReplicas: 0
# conditions:
# - lastTransitionTime: "2024-08-19T08:12:28Z"
# message: |-
# pod alertmanager-main-1: containers with incomplete status: [init-config-reloader]
# pod alertmanager-main-2: containers with incomplete status: [init-config-reloader]
# observedGeneration: 1
# reason: NoPodReady
# status: "False"
# type: Available
# - lastTransitionTime: "2024-08-19T08:12:28Z"
# observedGeneration: 1
# status: "True"
# type: Reconciled
# paused: false
# replicas: 3
# unavailableReplicas: 3
# updatedReplicas: 3
# 删除已有的main资源
kubectl -n monitoring delete alertmanager main
# 重新创建main资源
kubectl -n monitoring apply -f dump-modify.yaml
# 查看sts的日志发现报错信息提示说dns解析有问题,于是就去查看k8s组件coredns的信息,发现了问题所在,我的k8s集群采用的高可用部署方案,网络插件为calico,集群地址为10.10.40.100-105,service网段为10.96.0.0/16,pod网段为10.244.0.0/16,而这个coredns网段却是10.88.0.0/16网段的
kubectl -n monitoring logs sts alertmanager
kubectl get pod -A -o wide
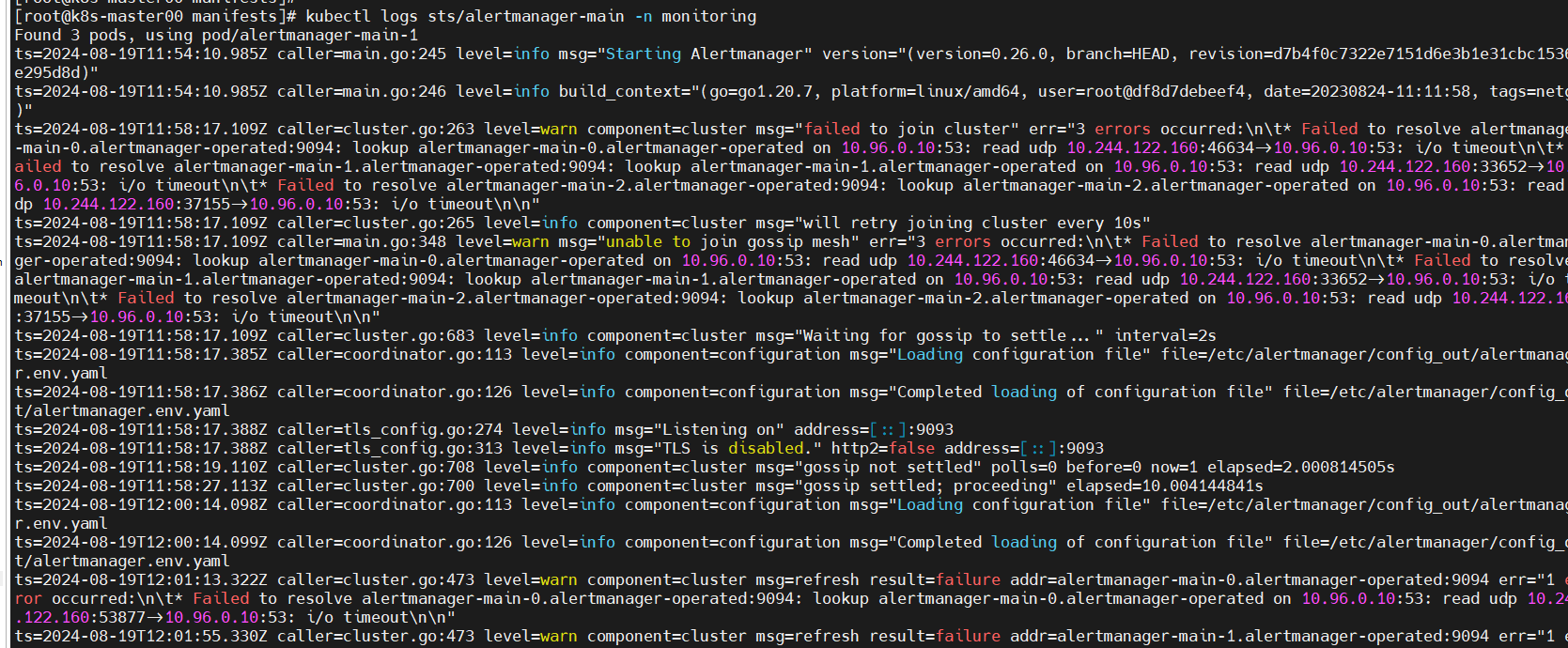

# 于是查看cni网络组件信息,看到所有节点都有这个cni0的网卡,这个网卡是安装了flannel网络组件才会提供的,问题就出在这里,calico网络组件提供的网卡是calic741a2df36d@if2的网卡名称,所以将原本的coredns删除掉后,网络就恢复正常了
# 此时再将整个Prometheus服务删除重新部署就恢复正常了
ls -l /etc/cni/net.d/
# 两个都要删
kubectl -n kube-system delete pod coredns-5bbd96d687-gtl9r
kubectl -n kube-system get pod -o wide


总结
# 不管部署一套什么服务,pod能跑起来,跨节点pod和pod之间能互相访问就不是网络问题,像这种个别pod有问题的,就查看报错,只要发现是端口拒绝之类的优先检查k8s组件coredns的问题,有奇效,当然还是得根据实际情况而论。
# 如果部署集群有问题的时候,给它改成单节点测试也是很好的排错方式。