[ML&DL] 线性回归的梯度下降
2023-04-26 16:25 由
feixianxing 发表于
#其他
前言
这篇笔记记录了线性回归的梯度下降相关公式的推导。
符号说明:
- \(h\) :假设函数,是学习算法对线性回归问题给出的一个解决方案。
- \(J\) :代价函数,是对 \(h\) 和实际数据集之间的误差的描述。
- \(m\) :数据集的大小。
- \(x^{(i)},y^{(i)}\): 第 \(i\) 个数据。(\(1\le i \le m\))
- \(\theta\) :\(h\)函数中各项的系数。
单变量线性回归
\(h(x)=\theta_0 + \theta_1x\)
\(J(\theta_0,\theta_1)=\frac{1}{2m} \Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2\)
在这个算法中需要找到最优的\(\theta_0\)和\(\theta_1\)使得代价函数\(J\)可以取得最小值。
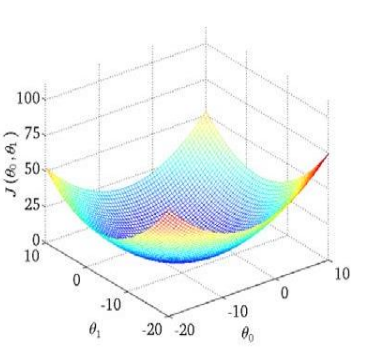
使用梯度下降可以计算得出局部最小值,由于线性回归中的代价函数\(J\)是凸函数,因此局部最小值即全局最小值。
批量梯度下降算法的公式如下:
repeat until convergence{
\(\theta_j:=\theta_j-\alpha \frac{\partial}{\partial \theta_j}J(\theta_0,\theta_1)\) \(for\quad (j=0 \quad and \quad j=1)\)
}
其中 \(\alpha\) 是学习率,表示梯度下降的步长。
\(\frac{\partial}{\partial \theta_j}J(\theta_0,\theta_1)\) 是梯度。
通过不断更新\(\theta\),向最低点逼近,最终使得\(J\)最小的\(\theta\)值,即对应一个最优的解决方案\(h\).
\[\theta_0:=\theta_0-\alpha\frac{\partial}{\partial \theta_0}J(\theta_0,\theta_1)
\]
其中
\[\begin{align*}
\frac{\partial}{\partial \theta_0}J(\theta_0,\theta_1)
&=\frac{\partial}{\partial\theta_0}(\frac{1}{2m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2)\\
&=\frac{\partial}{\partial\theta_0}(\frac{1}{2m}\Sigma^m_{i=1}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2)\\
&=\frac{1}{2m}\Sigma^m_{i=1}(\frac{\partial}{\partial\theta_0}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2)\\
&= \frac{1}{2m}\Sigma^m_{i=1}(2\times(\theta_0+\theta_1x^{(i)}-y^{(i)})\times1)\\
&= \frac{1}{m}\Sigma^m_{i=1}(\theta_0+\theta_1x^{(i)}-y^{(i)})\\
&=\frac{1}{m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})
\end{align*}
\]
\(\therefore\)
\[\theta_0:=\theta_0-\alpha\frac{1}{m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})
\]
类似地,
\[\theta_1:=\theta_1-\alpha\frac{\partial}{\partial \theta_1}J(\theta_0,\theta_1)
\]
其中
\[\begin{align*}
\frac{\partial}{\partial \theta_1}J(\theta_0,\theta_1)
&=\frac{\partial}{\partial\theta_1}(\frac{1}{2m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2)\\
&=\frac{\partial}{\partial\theta_1}(\frac{1}{2m}\Sigma^m_{i=1}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2)\\
&=\frac{1}{2m}\Sigma^m_{i=1}(\frac{\partial}{\partial\theta_1}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2)\\
&= \frac{1}{2m}\Sigma^m_{i=1}(2\times(\theta_0+\theta_1x^{(i)}-y^{(i)})\times x^{(i)})\\
&= \frac{1}{m}\Sigma^m_{i=1}((\theta_0+\theta_1x^{(i)}-y^{(i)})\cdot x^{(i)})\\
&=\frac{1}{m}\Sigma^m_{i=1}((h_\theta(x^{(i)})-y^{(i)})\cdot x^{(i)})
\end{align*}
\]
\(\therefore\)
\[\theta_1:=\theta_1-\alpha\frac{1}{m}\Sigma^m_{i=1}((h_\theta(x^{(i)})-y^{(i)})\cdot x^{(i)})
\]
多元线性回归
基本概念
多元线性回归中的假设函数 \(h\) 包含多个特征:
\[h_\theta(x) = \theta_0 + \theta_1x_1+...+\theta_nx_n
\]
如果假设 \(x_0=1\),那么上式可以改写为:
\[h_\theta(x) =\theta_0x_0 + \theta_1x_1+...+\theta_nx_n
\]
此时,若将 \(\theta\) 和 \(x\) 视为向量(默认为列向量),则:
\[h_\theta(x) = \theta^Tx
\]
代价函数为:
\[J(\theta) = \frac{1}{2m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2
\]
梯度下降
对于梯度下降算法的每一次迭代, \(\theta\) 按一下规则更新:
Repeat {
\(\theta_j := \theta_j - \alpha\frac{\partial}{\partial \theta_j}J(\theta_0,...,\theta_n)\)
} \(for\ \ every\ \ j=0,...,n\)
上述公式中的偏导数计算:
\[\begin{align*}
\frac{\partial}{\partial \theta_j}J(\theta)
&=\frac{\partial}{\partial\theta_j}(\frac{1}{2m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2)\\
&=\frac{\partial}{\partial\theta_j}(\frac{1}{2m}\Sigma^m_{i=1}(\theta^Tx^{(i)}-y^{(i)})^2)\\
&=\frac{1}{2m}\Sigma^m_{i=1}(\frac{\partial}{\partial\theta_j}(\theta^Tx^{(i)}-y^{(i)})^2)\\
&= \frac{1}{2m}\Sigma^m_{i=1}(2\times(\theta^Tx^{(i)}-y^{(i)})\times x_j^{(i)})\\
&= \frac{1}{m}\Sigma^m_{i=1}((\theta^Tx^{(i)}-y^{(i)})\cdot x_j^{(i)})\\
&=\frac{1}{m}\Sigma^m_{i=1}((h_\theta(x^{(i)})-y^{(i)})\cdot x_j^{(i)})
\end{align*}
\]
上述推导过程中的 \(x\) 是向量, \(x_j\)是向量中的第 \(j\) 个元素。
\(\therefore\)
\[\theta_j:=\theta_j - \alpha\frac{1}{m}\Sigma^m_{i=1}((h_\theta(x^{(i)})-y^{(i)})\cdot x_j^{(i)})
\]
特征缩放
当不同特征的取值范围相差过大时, \(\theta\) 的取值可能不断波动,需要花费较长时间才能收敛到全局最小值点。
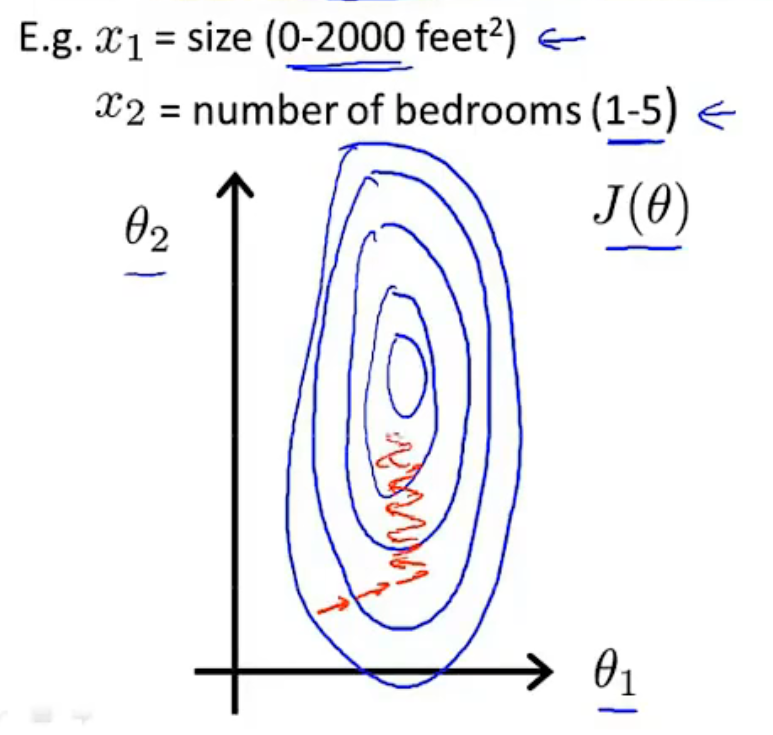
此时可以考虑缩放,
\[x_i = \frac{x_i}{max-min}
\]
均值归一化
对于除了 \(x_0\) 以外的特征(因为\(x_0=1\)),
\[\begin{align*}
x_i = \frac{x_i-average(x)}{max} \\
x_i = \frac{x_i-average(x)}{max-min}
\end{align*}
\]
在分母中, 可以使用样本的\(max\)或者\(max-min\),根据需求而定。
特征缩放和均值归一化的作用都是为了减小样本数据的波动使得梯度下降能够更快速的寻找到一条捷径,从而到达全局最小值。
热门相关:地球第一剑 刺客之王 无限杀路 学霸女神超给力 战神