百度飞桨(PaddlePaddle) - PP-OCRv3 文字检测识别系统 Paddle Inference 模型推理
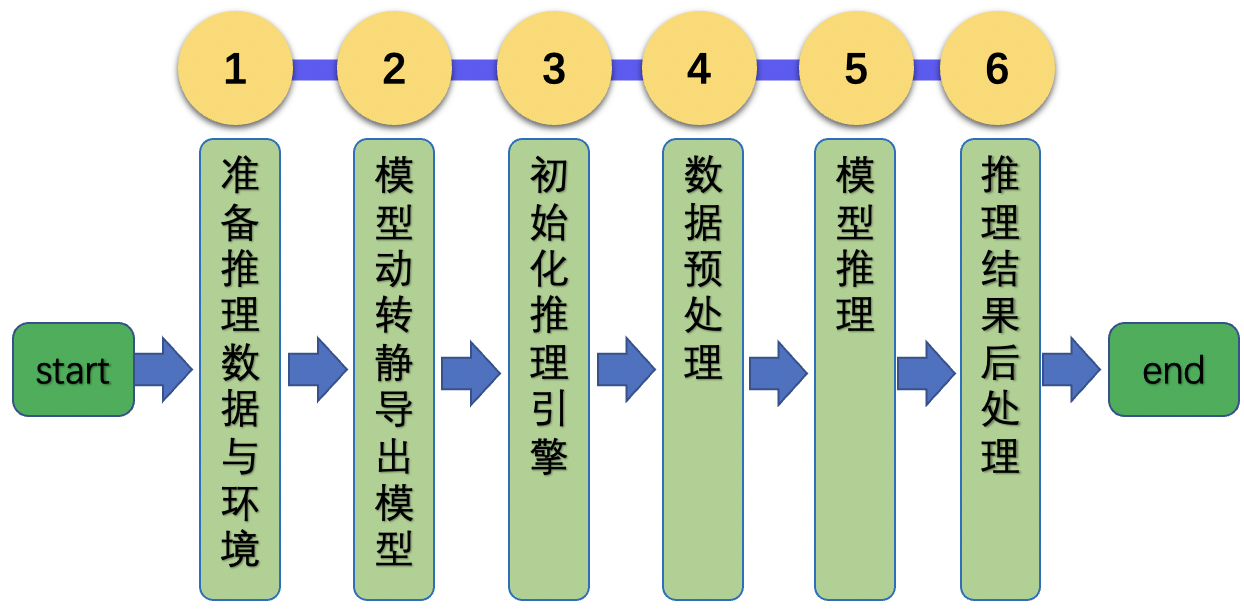
Paddle Inference 模型推理流程
分别介绍文字检测、方向分类器和文字识别3个模型,基于Paddle Inference的推理过程。
Paddle Inference 的 Python 离线推理
离线推理,即在特定机器上部署的代码只能在这台机器上使用,无法通过其他机器进行访问
使用whl包预测推理
“WHL”是“WHeeL”的英文缩写,意思是“车轮” ,whl 格式本质上是一个压缩包,里面包含了py文件,以及经过编译的pyd文件
为了更加方便快速体验OCR文本检测与识别模型,PaddleOCR提供了基于Paddle Inference预测引擎的whl包,方便您一键安装,体验PaddleOCR。
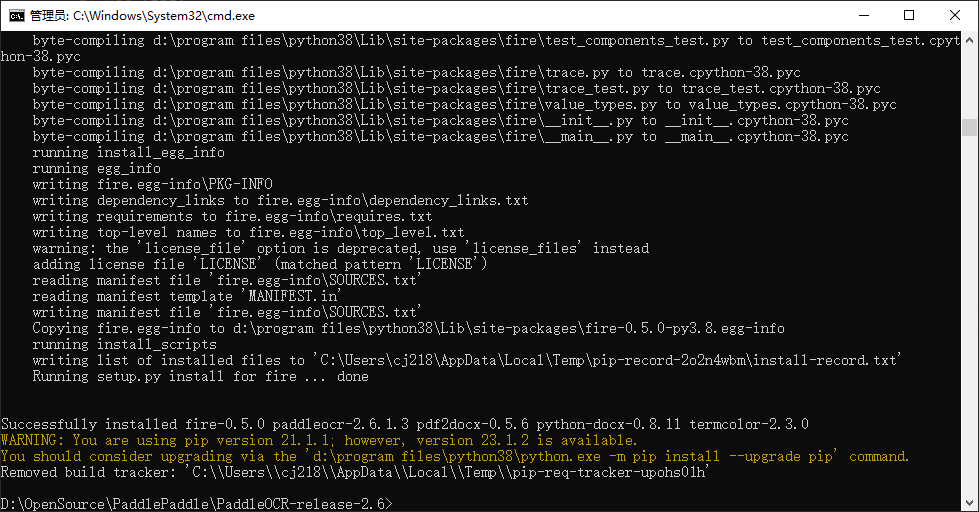
安装whl包
pip install paddleocr -i https://pypi.tuna.tsinghua.edu.cn/simple --verbose
使用whl包预测推理
paddleocr whl包会自动下载PP-OCRv2超轻量模型作为默认模型,也支持自定义模型路径、预测配置等参数,参数名称与基于Paddle Inference的python预测中参数相同。
单独执行检测
import cv2
import matplotlib.pyplot as plt
import numpy as np
import os
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(use_gpu=False) # need to run only once to download and load model into memory
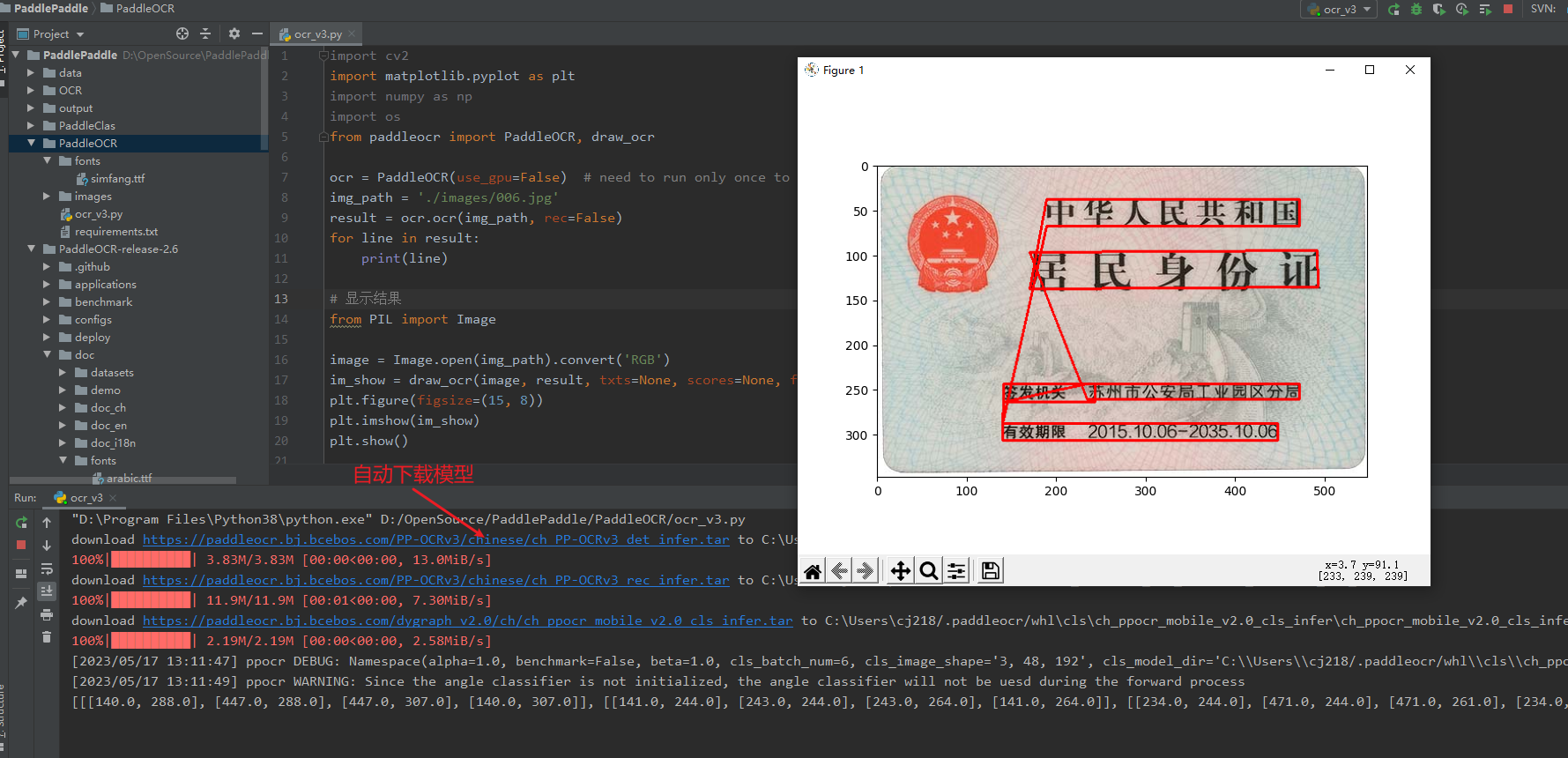
img_path = './images/006.jpg'
result = ocr.ocr(img_path, rec=False)
for line in result:
print(line)
# 显示结果
from PIL import Image
image = Image.open(img_path).convert('RGB')
im_show = draw_ocr(image, result, txts=None, scores=None, font_path='./fonts/simfang.ttf')
plt.figure(figsize=(15, 8))
plt.imshow(im_show)
plt.show()
单独执行识别
可以指定det=False,仅运行单独的识别模块。
import matplotlib.pyplot as plt
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(use_gpu=False) # need to run only once to download and load model into memory
img_path = './images/006.jpg'
result = ocr.ocr(img_path, det=False)
for line in result:
print(line)
单独执行方向分类器
可以指定det=False, rec=False, cls=True,仅运行方向分类器。
import cv2
import matplotlib.pyplot as plt
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False) # need to run only once to download and load model into memory
img_path = './images/006.jpg'
result = ocr.ocr(img_path, det=False, rec=False, cls=True)
for line in result:
print(line)
img = cv2.imread(img_path)
plt.imshow(img[...,::-1])
plt.show()
全流程体验(检测+方向分类器+识别)
import cv2
import os
import matplotlib.pyplot as plt
from paddleocr import PaddleOCR, draw_ocr
# PaddleOCR目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch", use_gpu=False) # need to run only once to download and load model into memory
save_results = []
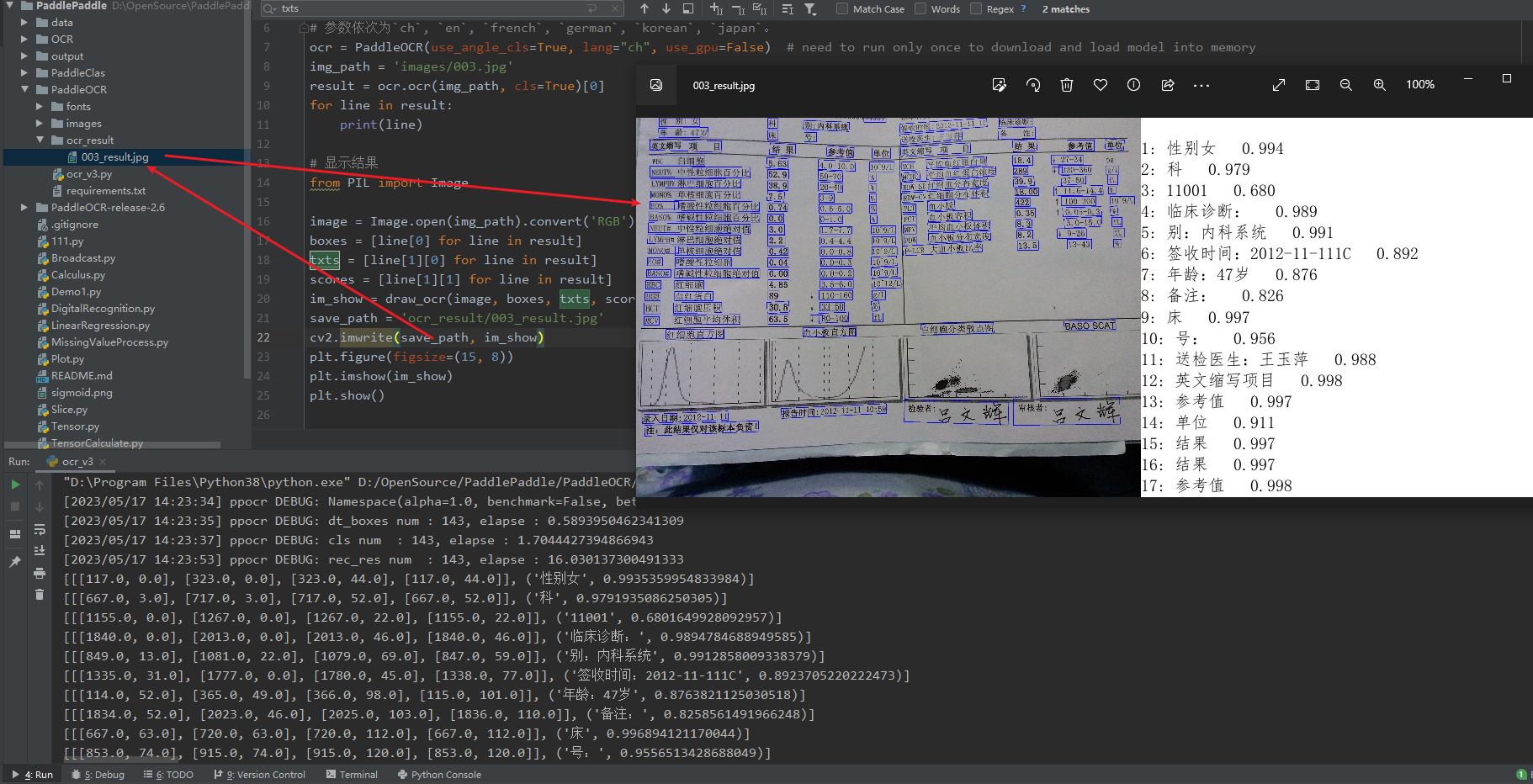
img_path = 'images/003.jpg'
save_dir = 'ocr_result'
result = ocr.ocr(img_path, cls=True)[0]
# 将结果写入文件
with open(
os.path.join(save_dir, "003_result.txt"),
'w',
encoding='utf-8') as f:
for line in result:
f.writelines(str(line)+'\n')
print(line)
# 显示结果
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
cv2.imwrite(os.path.join(save_dir, "003_result.jpg"), im_show)
plt.figure(figsize=(15, 8))
plt.imshow(im_show)
plt.show()
使用源码推理
下载源码,并解压:https://gitee.com/paddlepaddle/PaddleOCR/tree/release/2.6
安装依赖包
https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/requirements.txt
将文件 requirements.txt 保存到运行目录下如 D:\OpenSource\PaddlePaddle\PaddleOCR-release-2.6
shapely
scikit-image
imgaug
pyclipper
lmdb
tqdm
numpy
visualdl
rapidfuzz
opencv-python==4.6.0.66
opencv-contrib-python==4.6.0.66
cython
lxml
premailer
openpyxl
attrdict
Polygon3
lanms-neo==1.0.2
PyMuPDF<1.21.0
安装运行所需要的包
D:\OpenSource\PaddlePaddle\PaddleOCR-release-2.6>pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --verbose
D:\OpenSource\PaddlePaddle\PaddleOCR-release-2.6>pip install paddlenlp -i https://pypi.tuna.tsinghua.edu.cn/simple --verbose
文字检测
PaddleOCR中,在基于文字检测模型进行推理时,需要通过参数image_dir指定单张图像或者图像集合的路径、参数det_model_dir, 指定检测的 inference 模型路径。
百度OCR源码中提供了样例图片:https://gitee.com/paddlepaddle/PaddleOCR/tree/release/2.6/doc/imgs
准备数据和环境
import cv2
import matplotlib.pyplot as plt
import numpy as np
import os
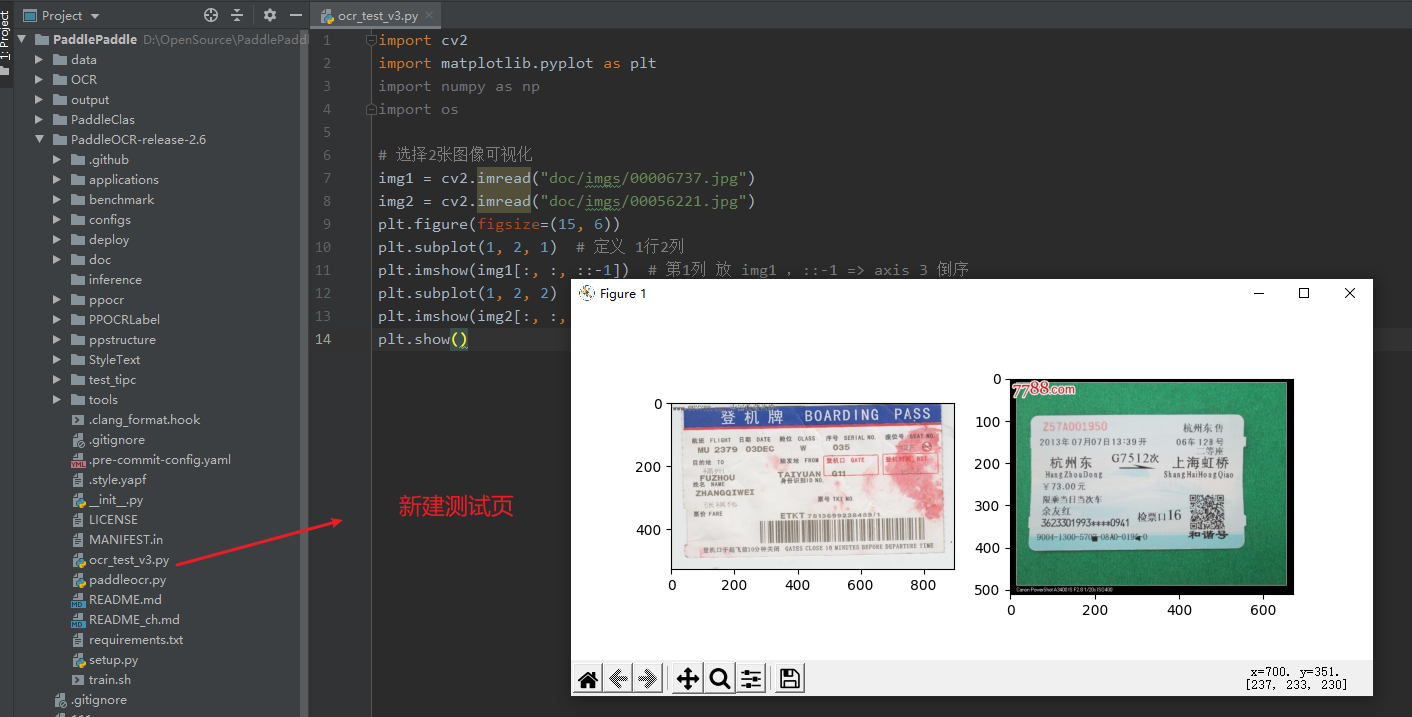
# 选择2张图像可视化
img1 = cv2.imread("doc/imgs/00006737.jpg")
img2 = cv2.imread("doc/imgs/00056221.jpg")
plt.figure(figsize=(15, 6))
plt.subplot(1, 2, 1) # 定义 1行2列
plt.imshow(img1[:, :, ::-1]) # 第1列 放 img1 ,::-1 => axis 3 倒序
plt.subplot(1, 2, 2) # 定义 1行2列
plt.imshow(img2[:, :, ::-1]) # 第2列 放 img1
plt.show()
准备推理模型
下载模型:https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv3_det_infer.tar
解压放至:inference 目录
如果您希望导出自己训练得到的模型,使用Paddle Inference部署,那么可以使用下面的命令将预训练模型使用动转静的方法,转化为推理模型。
# 参考代码
# https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.4/tools/export_model.py
# 下载预训练模型(V2)
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar && tar -xf ch_PP-OCRv2_det_distill_train.tar && rm ch_PP-OCRv2_det_distill_train.tar
# 导出推理模型(V2)
python tools/export_model.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml \
-o Global.pretrained_model="ch_PP-OCRv2_det_distill_train/best_accuracy" \
Global.save_inference_dir="./my_model"
文字检测模型推理
CMD 进到代码目录如图
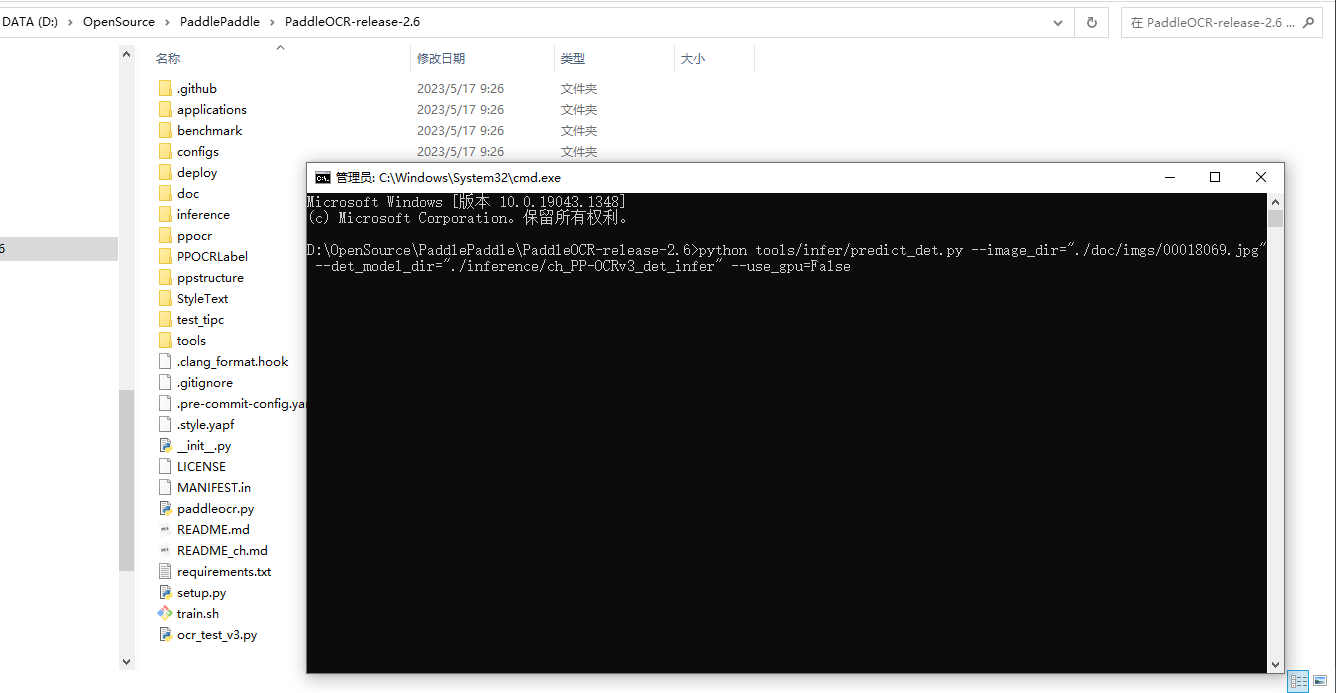
使用V3模型预测
# 预测
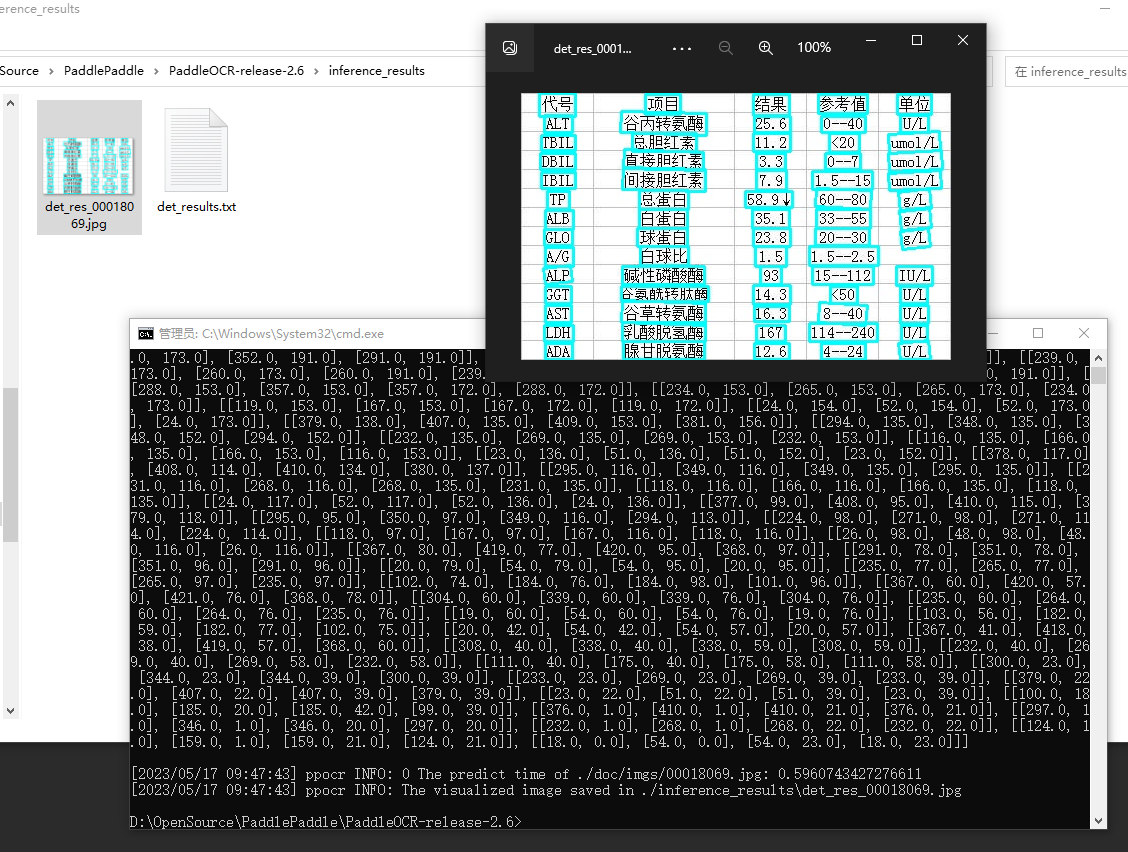
python tools/infer/predict_det.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./inference/ch_PP-OCRv3_det_infer" --use_gpu=False
输出
- 定义参数设置
PaddleOCR-release-2.6\tools\infer\utility.py
更多参数说明:doc\doc_ch\inference_args.md - 文字检测
PaddleOCR-release-2.6\tools\infer\predict_det.py
部分代码说明:https://aistudio.baidu.com/aistudio/projectdetail/6180758
方向分类器模型推理
//TODO 现在还不知道这玩意具体是用来干嘛的。
将角度不正确的文字处理成正常方向的
https://www.paddlepaddle.org.cn/modelsDetail?modelId=17
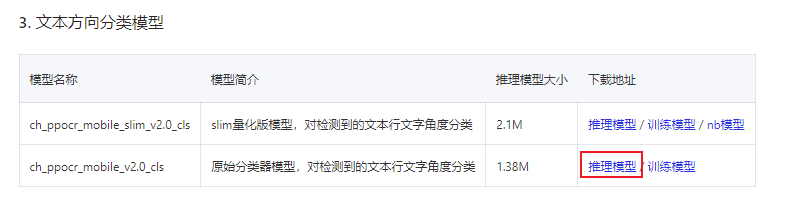
下载模型:https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
解压放至:inference 目录
# 预测
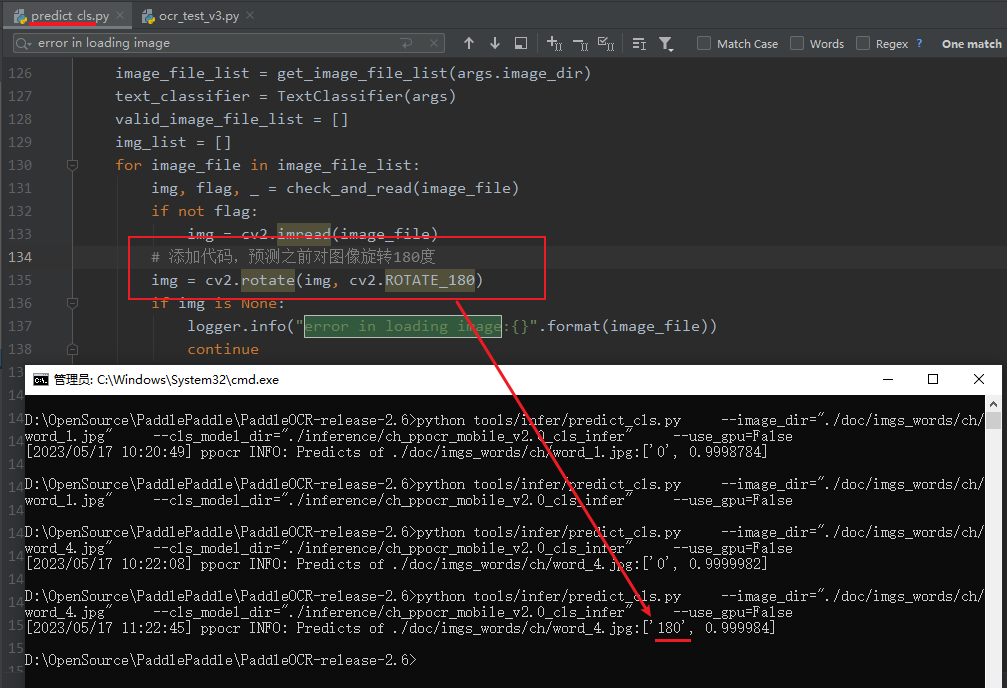
python tools/infer/predict_cls.py \
--image_dir="./doc/imgs_words/ch/word_1.jpg" \
--cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer" \
--use_gpu=False
方向分类器的具体实现代码: PaddleOCR-release-2.6\tools\infer\predict_cls.py
文字识别
https://www.paddlepaddle.org.cn/modelsDetail?modelId=17
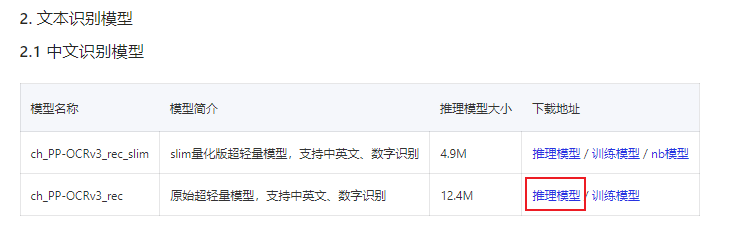
下载模型:https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
解压放至:inference 目录
# 预测
python tools/infer/predict_rec.py \
--image_dir="./doc/imgs_words/ch/word_4.jpg" \
--rec_model_dir="./inference/ch_PP-OCRv3_rec_infer" \
--use_gpu=False
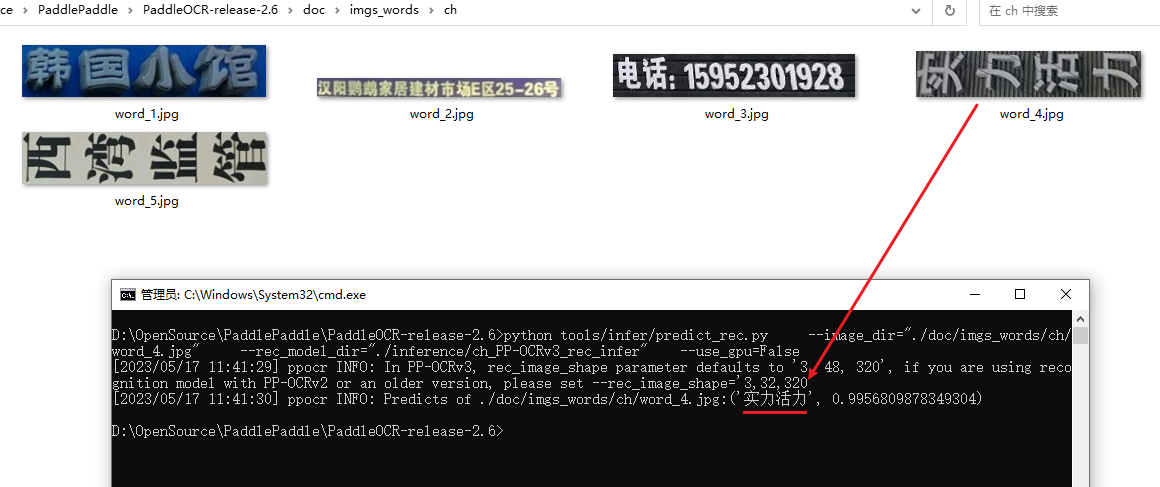
文字识别的具体代码:PaddleOCR-release-2.6\tools\infer\predict_rec.py
系统串联预测推理
在执行PP-OCR的系统推理时,需要通过参数image_dir指定单张图像或者图像集合的路径、参数det_model_dir, cls_model_dir 和 rec_model_dir 分别指定检测、方向分类和识别的 inference 模型路径。参数 use_angle_cls 用于控制是否启用方向分类模型。use_mp 表示是否使用多进程。total_process_num 表示在使用多进程时的进程数。
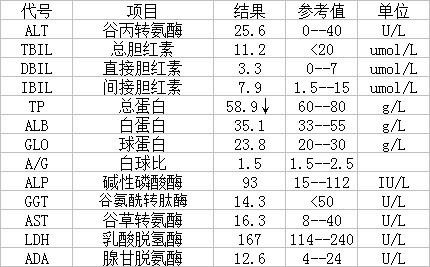
以图像文件 ./doc/imgs/00018069.jpg 为例,预测的原始图像如下。
# 预测
python tools/infer/predict_system.py \
--image_dir="./doc/imgs/00018069.jpg" \
--det_model_dir="./inference/ch_PP-OCRv3_det_infer/" \
--cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" \
--rec_model_dir="./inference/ch_PP-OCRv3_rec_infer/" \
--use_angle_cls=True
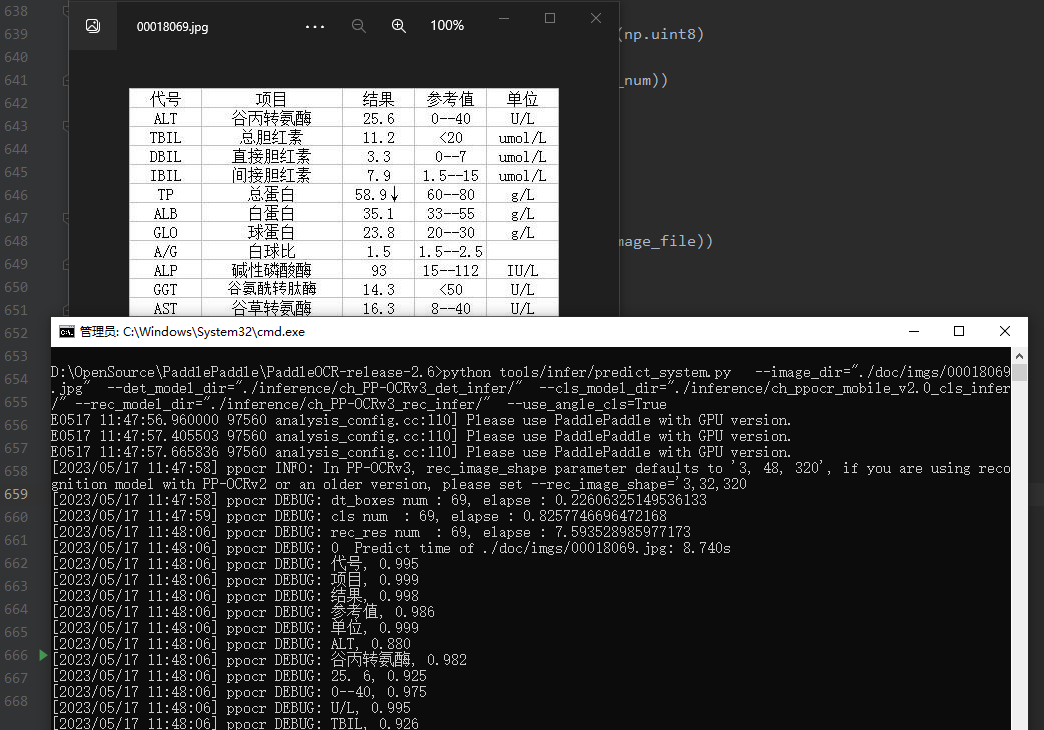
可视化识别结果默认保存到 ./inference_results 文件夹里面。
在图象中可视化出了检测框和识别结果,在上面的notebook中也打印出了具体的识别文件以及文件读取路径信息。
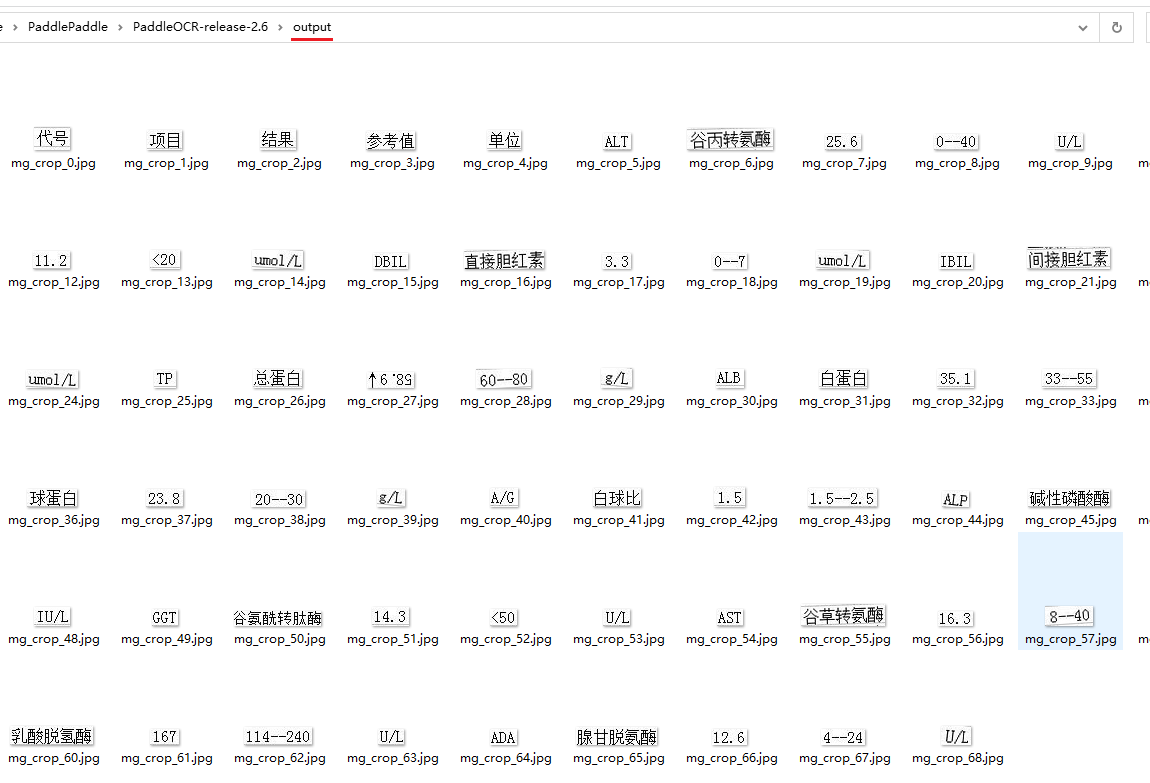
如果希望保存裁剪后的识别结果,可以将save_crop_res参数设置为True,最终结果保存在output目录下,其中部分裁剪后图像如下所示。保存的结果可以用于后续的识别模型标注与训练。
python tools/infer/predict_system.py \
--image_dir="./doc/imgs/00018069.jpg" \
--det_model_dir="./inference/ch_PP-OCRv3_det_infer/" \
--cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" \
--rec_model_dir="./inference/ch_PP-OCRv3_rec_infer/" \
--use_angle_cls=True \
--save_crop_res=True
参考引用
PP-OCRv3文字检测识别系统
PaddleOCR Github
PP-OCRv2预测部署实战 代码中 v2 改 v3