渲染路径 - Deferred Texturing
Deferred Texturing
forward rendering 将获取 material 相关属性的计算和 lighting 计算都放在光栅化 pass 的 pixel shader 中;deferred rendering 则将 lighting 计算从 pixel shader 抽离开来并延迟到后面的一个 compute shader。
Deferred Texturing 则主要把获取 material 相关属性的计算从 pixel shader 中抽离,并延迟到后面的某个 compute shader。
| 常见渲染路径 | material | lighting |
|---|---|---|
| Forward Rendering | PS | PS |
| Deferred Rendering | PS | CS |
| Deferred Texturing | CS | CS |
为什么需要 Deferred Texturing?
光栅化的 Helper Lane 开销
PS(Pixel Shader)很容易出现 overdraw 问题,虽然一个额外的 z-prepass 能够避免这个问题,但是其实 PS 还有另一个性能浪费的点,下面就详细阐述一下。
现代硬件光栅化往往经历两个阶段:
- Coarse Raster : 以 8x8 像素为一块;将三角形光栅化,输出若干个块(即相当于在 \(\frac{1}{8}*\frac{1}{8}\) 分辨率的 framebuffer 上进行光栅化),并进行一次 z cull。
z cull:利用低分辨率的 z-buffer 来剔除 8x8 像素的块。
- Fine Raster :以 2x2 像素为一个 quad;在经过 coarse raster 阶段且通过 Z Cull 后剩下的块内,再次将三角形光栅化,输出若干个 pixel quad,并且对 quad 里的 4 个像素执行 PS 和 z test。
因为采样贴图时需要计算 lod 层级,就需要知道相邻像素的 uv 并计算它们之间的差分,因此光栅化硬件在 fine raster 阶段采用 2x2 pixels 的并行单位而非 1 pixel 的并行单位。
然而在三角形的边缘情况下,fine raster 很容易出现浪费:实际上只需要 3 个 pixels 执行 PS,由于光栅化硬件的设计,实际上执行了 4 个 pixels 的 PS,这造成了浪费。

这种性能浪费尤其体现在细长三角形或者小三角形的情况下:

与此同时随着游戏模型的日益精细,三角面数越来越多,一个三角面覆盖的 pixels 数量也越来越少,这也就越来越造成更大的性能浪费。
例如在线段的 case 中,fine raster 的开销差不多是两倍:
常见渲染路径 material 开销 lighting 开销 forward rendering 2x 2x deferred rendering 2x 1x deferred texturing 1x 1x
为此,我们希望尽可能减少 PS 的工作量,从而尽可能减少性能的浪费,这也是 deferred texturing 为什么会将获取 material 相关属性的计算从 PS 中抽离走。
Draw Call 更容易合批
将 material 计算从 PS 抽离出来后,material 不同的不透明物体都能共用少数几个 pixel shader( PS 里的代码与 material 大部分属性都无相关了,除了背面剔除,alpha测试等属性),这可以大大减少光栅化的 PSO 切换。
利用 V-Buffer 可以做更多事情
V-Buffer 的各种 ID 可以用于实现更多的算法,例如本文后续介绍的 upsampling、AA 和 software VRS,用于 temporal filtering 避免产生鬼影的 id detection,基于 visibility id 的 surfel GI 方案等。随着 deferred texturing 渲染路径的普及,也会产生越来越多利用 V-Buffer 的新算法。
即便是传统的延迟渲染路径,也可以在 base pass 额外渲染多一个轻量级的 V-Buffer(也算是 G-Buffer 多一张 texture),来支持很多算法。
Visibility Buffer
那 deferred texturing 如何抽离 material 计算呢?
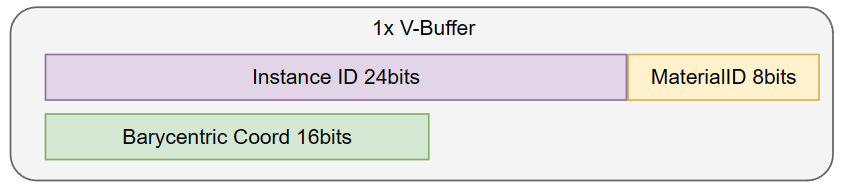
首先它要把光栅化 pass 的 Render Target 从 G-Buffer 换成了 V-Buffer(Visibility Buffer),并往 V-Buffer 里面每个 pixel 填充以下内容:
- InstanceID(16~24 bits):表示当前 pixel 属于哪个 instance(也包含了属于哪个 mesh 的信息)
- PrimitiveID(8~16 bits):表示当前 pixel 属于 instance 的哪个三角形
- Barycentric Coord(16 bits):代表当前 pixel 位于三角形内的位置,用重心坐标表示
- MaterialID(8~16 bits):表示当前 pixel 属于哪个材质
这些属性并不需要从各种贴图中计算而得,而是能直接从 VS 传给 PS 的三角形属性获得。

同时,我们还需要维护一个全局的 vertex buffer 和材质贴图表,表中存储了当前帧所有几何体的顶点数据,以及材质参数和贴图。不过全局材质贴图表会增加引擎设计的复杂度和降低材质系统的灵活度,并且往往还需要硬件支持如下特性之一: Bindless Texture/Sparse Texture/Texture Array,亦或者软件实现 Virtual Texture 特性。
这样利用总共 **8~12 Bytes/Pixel **的 V-Buffer,就可以在后续的某个阶段进行 material 计算:
- 通过 InstanceID 和 PrimitiveID 从全局的 vertex buffer 中索引到相关三角形的信息。
- 对 vertex buffer 内的顶点信息(UV,tangent space等)进行重心坐标插值得到插值后的 pixel 信息。
- 根据 MaterialID 去全局的材质贴图表索引到相关的材质信息,并执行贴图采样等操作得到 material 信息。
Material Culling
但是 deferred texturing 的一个问题是:由于实际 materials 是多种多样的,不同的 material id 获取对应 material 属性的逻辑都是不同的。
- 要是这些逻辑全部都塞到一个 full-screen 的着色 shader,那么这个 uber shader 将会产生众多分支,导致众多 gpu 线程空转,是非常不好的。
- 要是针对每个 material 分别做一次 full-screen 的着色,那么又会产生大量的带宽和计算浪费,因为实际上绝大部分 material 不会覆盖整个屏幕的 pixels。
- 要是针对每个 material 分别记录一个所覆盖的 pixels 列表,这样看似每个 material 在着色时只对有效覆盖的 pixels 进行着色,实际上读写 pixels 列表(pixels 数量太多了)的开销比上面做法远远要大。
一个折衷的做法是,使用基于 tile 的 material culling:针对每个 material 分别记录一个 material 所覆盖的 tiles 列表。然后在后续的 material 计算阶段时,就可以让每个 material 单独开一个 CS,并将对应的 tiles(一个 thread-group 对应一个 tile) 里的 pixels(一个 thread 对应一个 pixel) 进行 material 计算。
当然,如果 thread 判断出对应的 pixel 不属于当前 material,则不用进行 material 计算并直接退出函数。
因为实际上相同 material 的 pixels 往往是聚集在局部区域,而非随机散落在各个地方;同时 tiles 列表本身也不是很大(相比 pixels 远远要少得多),又能很好的避免覆盖太多无关的 pixels。
而在工业界里,针对基于 tile 的 material culling ,还可以一些变种的方式:
- UE5 Nanite 利用了 R32G32 的 material id range texture(存放了 tile 内 material 的最大值最小值)来粗略地表示 tile 包含了最大最小值范围内的 materials。
- 在后续的 material 计算中,使用了光栅化而非 CS,1 个 draw call 对应 1 个 material。
- 通过 VS 来采样 material id range texture 来判断当前材质是否在该 tile(4个 vertexs 对应一个 tile)的 id range 内,若不在则将 vertex 位置设置为 NaN,那么后续 vertex 所在的这个三角形就会被剔除,从而不会进入 PS。
- PS 里执行 material 计算。
这种方式的缺点在于:range 的表示方式可能会包含一些实际并不存在的 materials,从而让一些无关 material 的 VS 通过剔除测试并进入 PS 里;虽然 PS 内还会有根据 material 判断来决定是否 discard,但这种表示方式仍然会造成一定的性能浪费。

- 《Uncharted 4》利用了 R8 的 features bitmask texture 来表示 tile 包含了哪些 shader features(不同的 material 实际上就是使用了不同的 features 组合,如果仅考虑有哪些 features 被用到过,就可以从 12-bits 表示的 material id 压缩至 8-bits 表示的 features bitmask)。
- 每个 features bitmask 都有对应一个 shader,从而可以让一个 tile 内的 pixels 都调用同一个 shader。只不过该 shader 将包含不少的 feature 分支判断 tiles 内可能存在不同的 material id,它们会根据 material id 来决定是否进入某个 feature 分支。
- 如果能确定 tile 内就只有一种 features 组合,则可以调用 branch-less(无分支)的 shader,来减少分支开销。实际上,大部分游戏画面中的 tiles 也确实是只包含了单一的 features 组合。
这种方式的缺点在于:一是 shader 的分支判断可能会带来一定的额外性能开销(即使有 branch-less 的优化);二是可能会产生大量 shader,因为需要针对每种 features 组合来产生对应的 shader,8 bits 的 bitmask 就已经有 256 种 shader(虽然这种数量级是能接受的),如果考虑 branch-less 优化,那么 shader 数量还得再翻倍,假设引擎需要支持更多 features,16 bits 的 bitmask 将会产生 65,536 种 shader。

是否抛弃 G-Buffer?

传统 deferred rendering 管线的 G-Buffer 往往需要占据大量带宽,甚至随着材质复杂度的提升和精确度的要求,G-Buffer 大小还在变得越来越庞大。
像 UE5.1 中的延迟渲染管线就已经占了 16 Bytes/Pixel:

甚至在 2016 年的 《Uncharted 4》中,G-Buffer 更是达到了惊人的 32 bytes/pixel:

抛弃 G-Buffer 的 Deferred Texturing
deferred texturing 的原始流程可以将 material 计算和 lighting 计算合在一个 pass 里,利用计算出 material 属性后立即进行 lighting 计算,从而无需庞大的 G-Buffer 传递材质和几何数据。

相比于延迟渲染管线将几何属性和材质属性压进有限大小的 G-Buffer,deferred texturing 的做法显然要更精确且带宽开销低。尤其是在分辨率较高(如 MSAA 较大)的情况下,带宽开销将大大降低。
保留 G-Buffer 的 Deferred Texturing
将 material 计算和 lighting 计算放在同一个 pass 可以避免引入 G-Buffer 及其带来的带宽开销,听上去很理想,但在实际工作流中,可能会有以下问题:
- G-Buffer 是很重要的部件,盲目移除它可能会导致很多效果都无法实现(如屏幕后处理效果)
- material 是多种多样的,lighting 也可能包含多种变体,如果组合起来可能将导致巨量的 shader 文件,非常不灵活。尤其是在 TA 需要设计各种各样的 materials 时。
因此,个人觉得要想推广 deferred texturing 这种全新的渲染路径,最好是兼容过去的工作流,即包含 G-Buffer 的流程。
Deferred Texturing with G-Buffer 流程
Z Pre-pass
基于 PS,绘制场景中所有的不透明几何体,老生常谈的优化 overdraw 手段。不过这个步骤是可以和 visbility passes 步骤合并的,因为 V-Buffer 并不是特别大,减少光栅化批次带来的优化效果可能大于 V-Buffer 带来的额外 overdraw 开销。
Visibility Passes
基于 PS,绘制场景中所有的不透明几何体,将每个 fragment 的 instance id、primitive id、barycentric coord、material id 写入到 V-Buffer 中去。
Worklist Build Pass
基于 CS ,将屏幕划分成若干个 tiles,每个 tile 就是一个 thread group,每个 pixel 就是一个 thread。pixel 根据自身使用到的 material id,以 tile-material pair(8字节) 的形式记录到全局的 record list 里。
Worklist Sort Pass
基于 CS,对 record list 进行排序去重,并将去重后的 tile-material pair 中的 tile id 添加到 material 对应的 list 中。
worklist sort pass 应当充分利用 group shared memory 来做局部排序去重,而非做全局排序去重。
Material Passes
对每个 material 分别进行一个 pass(可 PS 也可 CS),并根据 material id 获取 worklist 里面的 tiles,对这些 tiles 进行着色:
- 如果 pixel 的 material id 不是当前 material,则不着色。
- 如果 pixel 的 material id 正好是当前 material,则进行 material 计算,输出到 G-Buffer。
Lighting Pass
进行一个 full-screen 的 pass(可 PS 也可 CS),根据 G-Buffer 对 pixel 进行 lighting 计算,输出到最终颜色图像。
Upsampling based on DVM
DVM
Decoupled Visibility Multisampling (DVM) 是一种基于高分辨率 visibility buffer 的多重采样方法,可用于 upsampling(升采样)或 AA(anti-alias,抗锯齿),其目标是想达成 N 倍频率的采样效果,但是却不用进行 N 次 shading,甚至不需要进行 N 倍分辨率的 G-Buffer(这就会造巨量带宽开销),而只需要 N 倍分辨率的 V-Buffer。
填充 Pore Pixels [第一种填充算法]
DVM upsampling 的核心在于:我们有低分辨率的 G-Buffer 并且通过计算输出了低分辨率的颜色图像,然后利用高分辨率的 V-Buffer来指导,从而对 color pixel(颜色像素)间的 pore pixel(空隙像素)填充颜色。
例如,下图我们有 4*4 分辨率的颜色图像,希望 upsampling 成 8*8 分辨率的图像。于是在高分辨率的图像上,我们让每个 pore pixel 获取周围 4 个 color pixels ,并根据它们 visibility id 和 uv 距离来混合出一个新的颜色并填入 pore pixel:
- visibility id 不同的 pixel 权重为 0,visibility id 相同的 pixel 权重为 1。
- 最坏情况:若 4 个 color pixels 的 visibility id 均与目标像素的 visibility id 不同,则直接根据 uv 距离来混合这四个 pixels(即正常的双线性插值)。

一个性能问题是,每个 pore pixel 都需要获取附近 4 个 color pixels,会导致 4 倍的 G-Buffer 读和 4 倍的 V-Buffer 读。为了节省带宽,DVM 4x upsampling 的处理单位不是 pixel 而是 2x2 pixels 组成的 quad:
- 每个 quad 内的 pore pixels 必定访问相同的 4 个 color pixels,因此可以避免 4 倍的重复读。

AA based on DVM
DVM AA 的思路与 DVM upsampling 差不多,只不过 upsampling 中的 pore pixel 变成了 AA 中的 subsample;此外,DVM AA 还额外利用了 sample switching 来增强 AA 效果。
和一般 AA 算法不同,DVM AA 的处理单位不是 pixel 而是 2x2 pixels 组成的 quad,如果我们想要做 8x 的效果,就相当于一个 quad 要包含 32 个 subsamples,但是我们只对其中 4 个做 shading(可以称这 4 个为 color sample)。

注意:每个 pixel 的 subsamples 位置分布是一致的,这样每帧给 pixel 选择某一个 subsample 成为 color sample时,另外三个 pixels 也应选择相对位置一样的 subsamples 成为 color samples,从而让 color samples 之间的间距 = pixel 的边长。

将 4 个 color samples 的着色结果算出来后,根据它们对应的 visibility id,首先给同一 pixel 内相同 visibility id 的 subsamples 赋予相同的着色结果:

接着,同一 pixel 内不同 visibility id 的 subsamples 则通过访问其它 pixels 的 color sample 来获得对应的着色结果:

接着就可以根据单个 pixel 内 subsamples 的 color 混合后得到该 pixel 经过抗锯齿处理后的 color 值 。
Sample Switching
一种 bad case 可能出现在 4 个 color sample 不能覆盖所有的 subsamples 的情况。
如下图 4 个 color samples 没有一个是位于左上角的三角形的,也就是说左上角共 9 个 subsamples 丢失了 color 信息:

这时候只要随机选 1 个 color sample 来切换(switch)到丢失 color 信息的 subsamples 中的随机一个,从而补充多一个 color 信息。这里不选择 1 个最近邻的 color sample 进行切换,而是选择随机 1 个 color sample,这样做是为了让每个 color sample 都有相同的概率被选中,以免对最终图像产生偏差。

解决这种 bad case 的方法除了 sample switching,还有更直接的增加额外样本的方法:只不过增加额外样本的方法会引入额外的复杂度以及 shading 开销,往往不推荐这么做。
此外,最糟糕的情况出现在 subsamples 所需的 color 信息大于 4 个的时候,无论怎么 switch sample 也无济于事,因为要彻底解决这个问题就必须得增加额外的 color samples。DVM AA 为了不引入额外的着色,选择忽视丢失 color 信息的 subsamples(即不参与颜色混合)。

但是,实际上很少会出现 4 个 pixels 占据五个及更多的 triangles。即使有,现有的 DVM 算法也足以呈现还可以的抗锯齿效果(因为最多已经包含了四种 color 的信息,大部分 subsamples 都能被覆盖到)。
更进一步地,DVM 每帧都会抖动一下 color sample 的基准位置,结合上 TAA 时序上复用的思路,其实也能实现近似全 subsamples 覆盖的抗锯齿效果。
4x DVM AA 流程 [TODO]
Z Pre-pass with V-Buffer
首先,我们需要通过 PS 生成 4x 分辨率的 V-Buffer,因此也必须得伴随着生成 4x 分辨率的 z-buffer。
但 DVM 实际上需要的 ID 是 primitive id 和 draw call id,并非需要完整的 V-Buffer,因此我们可以只生成 4x 分辨率的 primitive id texture 和 draw call id texture。而为了避免多开一轮 visibility passes,这里选择了和 z pre-pass 合并,让 z pre-pass 顺便去生成 primitive id(16 bits) 和 draw call id(16 bits)。

更进一步的,在 DVM 流程中,primitive id 和 draw call id 组成的 visibility id 仅仅只是用于比较是否相同的,因此可以不必完整的 visibility id 表示,而是可以用占用空间更小的 hash id 表示。
不过注意,相邻三角形的 primitive id 几乎是非常接近的,因此不宜用它的低位进行做太多 hash 变化,因此可以直接让 draw call id 的比特顺序翻转并异或到 primitive id 上(这样 draw call id 频繁变化的低位就能并入到 primitive id 的高位了),合成一个 hash id。
uint16 hashid = primitiveid ^ BitReversal(drawcallid);
Coverage Pass
首先,每个 pixel 先根据 temporal pattern 基准位置生成 1 个 color sample,并且计算出该 color sample 在 pixel 内覆盖的 subsamples,并以 16 bits coverage mask 记录。
这个时候其实只用到了 mask 中的 4 bits,因为一个 pixel 就 4 个 subsamples。
然后,每个 pixel 可以通过 coverage mask 知道有哪些本 pixel 内没有被覆盖到的 subsamples,对这些 subsamples 进行遍历,每次遍历尝试与另外三个 color sample 的 visibility id 进行比较:
- 若相同,则让该 color sample 的 coverage mask 对应的 bit 赋为 1,并结束本次遍历。
- 若三个均不同,则意味着该 subsample 丢失了 color 信息,将该 subsample 的 location(相当于说是在 bitmask 中的第几个 bit)添加到一个 subsample list to switch。
接着,4个 pixel 将它们的 color sample visibility id 按随机先后次序,和 test = 0 进行合并测试(检查位与运算的结果是否为 0):
- 若合并测试通过,则再用位或运算合并到 test 变量,并记录该 color sample 的 location, 以 4 bits subsample location 记录。
- 若合并测试不通过,意味着已经存在有重复的 visibility id 了,则当前 color sample 去 subsample list to switch 挑一个 subsample,并 switch 过去, 以 4 bits subsample location 记录;此外,switch sample 后重新计算其覆盖的 subsamples,以 32 bits coverage mask 记录。

Visibility Passes
其它 Passes
包含了 worklist 相关 passes,material 相关 passes 和 lighting pass。
DVM Pass
float3 myMin = MinOfNeighborsWithSameDrawCallId();
float3 myMax = MaxOfNeighborsWithSameDrawCallId();
float3 sumMin = 0;
float3 sumMax = 0;
sumMin += float(numMarked0) * myMin;
sumMax += float(numMarked0) * myMax;
sumMin += float(numMarked1) * QuadReadAcrossX(myMin);
sumMax += float(numMarked1) * QuadReadAcrossX(myMax);
sumMin += float(numMarked2) * QuadReadAcrossY(myMin);
sumMax += float(numMarked2) * QuadReadAcrossY(myMax);
sumMin += float(numMarked3) * QuadReadAcrossDiagonal(myMin);
sumMax += float(numMarked3) * QuadReadAcrossDiagonal(myMax);
float3 avgMin = sumMin * rcp(float(totalMarked));
float3 avgMax = sumMax * rcp(float(totalMarked))
float3 myColor = TexFetch();
uint myMask = MaskFetch();
float3 sumColor = 0;
uint numMarked0 = countbits(myMask & baseMask);
sumColor += float(numMarked0) * myColor;
uint numMarked1 = countbits(QuadReadAcrossX(myMask) & baseMask);
sumColor += float(numMarked1) * QuadReadAcrossX(myColor);
uint numMarked2 = countbits(QuadReadAcrossY(myMask) & baseMask);
sumColor += float(numMarked2) * QuadReadAcrossY(myColor);
uint numMarked3 = countbits(QuadReadAcrossDiagonal(myMask) & baseMask);
sumColor += float(numMarked3) * QuadReadAcrossDiagonal(myColor);
uint totalMarked = numMarked0 + numMarked1 + numMarked2 + numMarked3;
float3 avgColor = sumColor * rcp(float(totalMarked));
VRS based on V-Buffer
Hardware VRS & Software VRS
可变速率着色(Variable Rate Shading,VRS) 是一个用在光栅化上的硬件技术,通过控制在不同屏幕区域的光栅化分辨率从而来控制 pixel 的着色频率,在游戏中的应用往往是对一些不那么重要的屏幕区域(例如VR应用的非注视区域,赛车游戏中飞驰而过的风景,被 UI 遮挡的地方等)采用低着色频率。

虽然硬件 VRS 可以通过降低不重要区域的着色频率来提升相当的性能,但仍然有以下缺点:
- 标记的屏幕区域只能以 tile 为单位,而不能以 pixel 为单位。
- 由于与光栅化捆绑在一起,VRS 也避不开 helper lane 的额外开销。
- 由于与光栅化捆绑在一起,deferred rendering 仅渲染 G-Buffer 时可启用 VRS,而后基于 CS 的 shading pass 则无法启用 VRS。
不采用 VRS 时,光栅化的单位为 pixel(灰色为 pixel 的 helper lane);而采用 2x2 VRS 时,光栅化的单位为 2x2 pixels 组成的 quad(蓝色+灰色为 quad 的 helper lane):

再例如,一个小三角形本来只占据 1 个 pixel,在 2x2 VRS 下占据 1 个 quad(期望着色频率为 4 pixels 调用 1 次 PS),但由于 helper lane 机制,却不得不计算 4 个 quad 的着色(即运行 4 次 PS),填充完所占据的 quad 颜色后发现到头来着色频率还是 1 pixel 调用 1 次 PS。
如果 n 个小三角形挤在同一个区域,在它们光栅化后,可能会发现这个区域的着色频率甚至可能达到了 1 pixel 调用 n 次 PS。所以硬件 VRS 更多的是指光栅化出来的 fragments 的着色频率,并且还会带额外的 helper lane 开销。在大三角形的情形下,这些额外开销几乎不怎么影响,但在小三角形的情形时就会造成大量性能浪费。

我们理想中的着色频率,应当是屏幕区域的 pixels 着色频率,例如下图即使有 n 个小三角形挤在同一个区域,仍然期望该区域 16 pixels 只调用 4 次着色:

而如果借助 V-Buffer ,我们可以实现一种 software VRS,它不需要与光栅化捆绑,并且真正做到了 n 个 screen pixels(非 fragments) 进行 1 次着色,并且还能支持标记区域以 pixel 为单位,这就能带来很大的灵活度。
判断 Pixel 重要性
判断 pixel 是否重要有很多方法,可以选择性挑选,包括但不限于:
- 每隔 n × n 个 pixels 的位置【必须】:这些位置将在后续提供插值的参考,因此本身需要进行着色,即为 important。
- 自定义区域:例如 UI 遮挡区域上的 pixels 应该为 unimportant。
- velocity texture:移动较快的 pixels 应该为 unimportant。
- 可参考的邻域 pixels:目标 pixel 的 visibility id 与附近 pixels 的 visibility id 均不同,意味着缺少可参考的邻域 pixels,这时候目标 pixel 应该视为 important。
- ...
当然,这样的作法可能会导致性能波动,我们还可以给每个 pixel 赋予一个优先级,然后把所有 pixels 归入一个直方图,并设定一个阈值,然后就可以确定有固定数量的 pixels 被允许着色。
通过一个 pass 判断完重要性后,应当输出一张 mask texture 来表示哪些 pixels 是 important 的(应当着色),哪些 pixels 是 unimportant 的(应当插值)。
填充 Pore Pixels [第二种填充算法]
通过重要性判断后,我们只对 mask texture 上为 important 的 pixels 进行着色(shading pass)。然后开始再开始若干个 fill passes(1个 pass 对应 1 轮填充),它们负责对 pore pixels 进行填充(与 upsampling 类似):
- 访问 pore pixel 附近 4 个已经着色了的 pixels,若 visibility id 相同则参与基于 uv 距离的混合。
- 若 4 个 pixels visibility id 均与本 pore pixel 的不同,则直接使用双线性混合。

Convergence
前面说到,每隔 n × n 个 pixels 的位置都应该为 important 的,因为它们着色后需要被用于插值出别的 pixels,但是这个位置如果一直固定便可能不能收敛到非 VRS 图像(一些屏幕 pixels 有可能一直只会靠插值插出来而非着色出来)。
为了避免这种现象,我们可以每帧整体移动一下着色位置,使其在若干帧内的着色位置的并集能填满整个屏幕:

整齐划分的 pattern 可能会导致锯齿状 artifact,我们还可以使用抖动的 pattern 去避免这种问题:

有了每帧不同的 pattern,再搭配上 TAA,软件 VRS 产生的图像过几帧就能基本收敛到非 VRS 图像。而硬件 VRS 搭配 TAA 是不能收敛到非 VRS 图像,而只能一直呈现模糊的图像。
测试结果表明:
- 2x2 硬件 VRS 一直都是呈现模糊的图形,无法收敛。
- 2x2 VRS(对应0.25)第一帧可能会模糊,但是很快几帧后就能收敛。

总结 [TODO]
参考
- UE5渲染技术简介:Nanite篇 - 知乎 (zhihu.com)
- The Visibility Buffer: A Cache-Friendly Approach to Deferred Shading [2013]
- [Visibility Buffer Rendering with Material Graphs – Filmic Worlds](http://filmicworlds.com/blog/visibility-buffer-rendering-with-material-graphs/#:~:text=The UE5 visibility rasterizer is a Nanite-only rasterizer%2C,always fetch it directly from the vertex parameters.)
- Decoupled Visibility Multisampling – Filmic Worlds
- Visibility TAA and Upsampling with Subsample History – Filmic Worlds
- Software VRS with Visibility Buffer Rendering – Filmic Worlds
- Siggraph 2018 - Variable Rate Shading (VRS)
- Deferred Adaptive Compute Shading (geometrian.com)
- Decoupled Deferred Shading for Hardware Rasterization [2012]