自动化混沌工程 ChaosMeta V0.6 版本发布
混沌工程 ChaosMeta 的全新版本 V0.6.0 现已正式发布!该版本包含了许多新特性和增强功能,在编排界面提供了包括流量注入、度量等各类节点的支持,可视化支撑演练全流程。解决混沌工程原则中“持续自动化运行实验”的最后一公里问题。
简介
ChaosMeta 是一款面向自动化演练而设计的云原生混沌工程平台。提供了可视化编排调度、数据隔离、多云管理等平台功能,以及丰富的故障注入能力,覆盖演练全生命周期。凝聚了蚂蚁集团在公司级大规模红蓝攻防演练实践中多年积累的方法论、技术能力以及产品能力。
新版本特性
新版本中,新增了DNS异常、日志注入等故障能力,并且在可视化编排界面中提供了对流量注入、度量等各类节点的支持,提供自动化混沌工程的支撑能力。
▌无损注入
日志注入是一个简单的故障能力,本质上就是对文件追加文本内容。但是由此延伸的无损注入思想是比较重要的。
顾名思义,无损注入就是希望能在不真正影响业务的情况下进行演练,挖掘出应用的监控告警、止血、自愈等应急流程的不足,是一种风险最小化、非常适合在生产环境进行的演练方式。
无损注入的实现方案一般有两种:
- 如果某个应用的监控指标是依赖日志内容而来的,那么通过对应用的日志文件注入相应内容,即可无损验证目标应用的相关应急流程的完善与否;
- 直接篡改目标监控项的监控数据(比如CPU使用率),验证后续应急流程是否完善。
下面是两个日志注入的演练场景:
(1)Common Error
平时我们会监控日志文件中的"Error"、"Exception"等组合关键词的数量,以此来判断一个应用状态是否有异常,如果发生了突增,大概率说明应用出现了故障。因此,可以使用日志注入(文件追加)的能力模拟这类故障

(2)接口请求耗时
出于对监控采集上报的性能影响考虑,有些应用使用的是异步采集的方案,RPC框架把每个接口的请求耗时、返回码输出到日志中,然后由采集Agent从日志文件中异步采集数据上报。
下面是一个消息推送接口的耗时监控采集样例,从日志文件中收集每次接口的耗时数据上报到监控平台:


在这种情况下也可以使用日志注入(文件追加)的故障能力模拟请求耗时过大的故障场景,而不用真正对应用注入网络故障。
无损注入在一些只需要快速验证大量应用的监控告警、定位、预案等标准化应急能力的场景上非常高效。
▌自动化运行实验
业界的混沌工程原则为:
- 建立一个围绕稳定状态行为的假说
- 多样化真实世界的事件
- 在生产环境中运行实验
- 最小化爆炸半径
- 持续自动化运行实验
而其中前四条在行业中都总有办法实现,但是最后这个“持续自动化运行实验”却始终没有较好的落地方案。
当然很多出名的混沌工程项目都有尝试解决,大部分都提供了定时调度执行的产品能力,但是这个定时执行能力是否敢在生产环境中真正大规模使用起来是存疑的。
原因一方面是故障注入是个高危动作,没有足够的前置准入等检查操作,就没有足够的安全感去自动触发;另一方面是一次演练并不仅仅只有“故障注入”,我们往往还需要做很多的“人工分析”的其他工作,比如注入故障前检查目标应用状态、当前环境等是否符合预设条件、流量是否满足,注入故障后,发现定位恢复耗时多少、分析应急效率等。
ChaosMeta 将这类“人工分析”的工作拆解成了不同类型的原子执行任务,分为“故障注入”、“度量执行”、“流量注入”、“等待”等多种类型的节点,然后根据灵活的编排能力组合成各种业务语义的自动化演练场景,下面展示几个简单的样例:
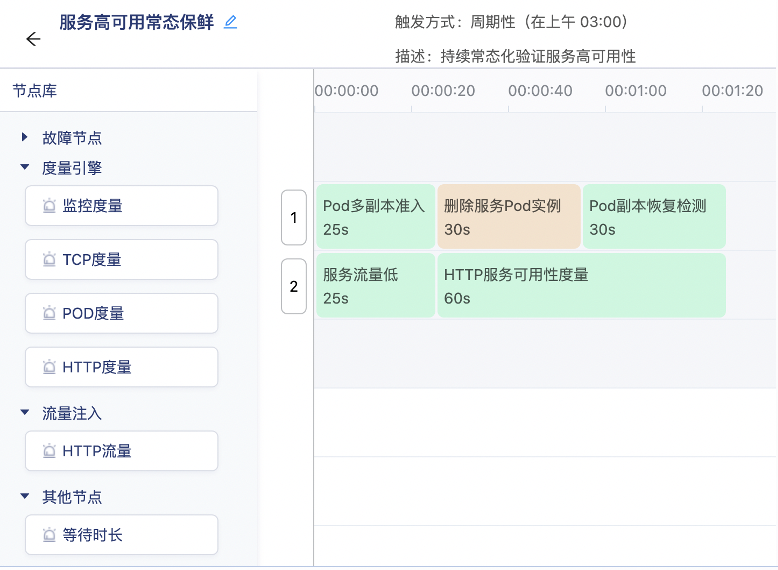
服务高可用常态保鲜
我们对线上应用都有服务高可用的要求,比如要求具备多副本+服务自动负载均衡的能力,定时进行常态演练就是高可用能力持续保鲜的一种保障方式
由于是生产环境,那么我们就不能随随便便就直接自动发起,因为你无法保证某个应用是不是时时刻刻都是多副本可用状态,比如在演练前刚好只有一个副本可用,并且有大量用户流量访问的情况下,你配置的演练自动发起了,那么就会酿成不可估量的后果。
那么这个例子中,就有几个操作,可以增加你自动化演练的信心:确认应用多副本、服务用户流量在可接受范围内、演练后应用能回复到多副本状态
而我们这次演练的目的就是要校验服务的高可用性,所以对应的服务可用性度量也是必须的。
那么只要把所有担忧的因素都配置到编排中了,只要运行结果是成功的,这次演练就是一次符合预期的演练。反之执行失败了再通过告警通知相关负责人介入。就能大大解放在演练中的人力投入
红蓝攻防自动化
在进行红蓝攻防演练的时候,蓝军一般负责设计场景进行演练,并且最后对红军的应急效率(人员、平台)做出一个尽量客观的评测,以此来牵引红军的防御能力建设方向。

评判标准常见的一种方式是,判断一场故障中,红军应急的发现、定位、恢复耗时是否分别满足1、5、10分钟内的要求,否则就扣分。既然涉及到“耗时”,那么必然需要一个准确的起始时间点(故障生效)和目标时间点(发现、定位、恢复时刻)。
起始时间点就是达到红军认为形成了故障标准的时刻,而这并不一定是传统意义上故障注入的时刻,比如目标服务承诺保障服务延迟3000ms以下,那么只有网络延时在3000ms以上才会被认为是故障,红军才应该去应急,业务恢复目标同理也是3000ms以下。而如果直接以故障注入操作时刻来算,就会造成很大的误差,甚至这个“故障注入”未必就能真正造成红军认为的故障,所以故障生效度量也是非常必要的一个环节。

蓝军为了对每次故障的红军应急效率进行评价,需要收集各个应急平台(监控平台、定位平台、自愈平台等)的数据,人工收集分析是一项十分繁重的工作。而在传统的混沌工程平台上只有故障模拟能力,同样一个演练场景,这些“人工操作”的工作都要一次次重复的执行。而 ChaosMeta 正是希望能把这些“人工操作”都配置到平台中,提升演练效率。
网络故障攻防演练
这是一个简单的红蓝攻防演练样例,针对应用在网络延迟过大的场景
既然涉及到网络流量类监控,那么服务流量是一个必要条件,没有服务流量,注入了网络延迟,也不会触发服务延迟过高的告警,因此需要配置一个Mock流量的节点;
而准入检测,度量当前流量水位是否满足预期也是需要的,否则接下来的流程都大概率是不被红军认可的;
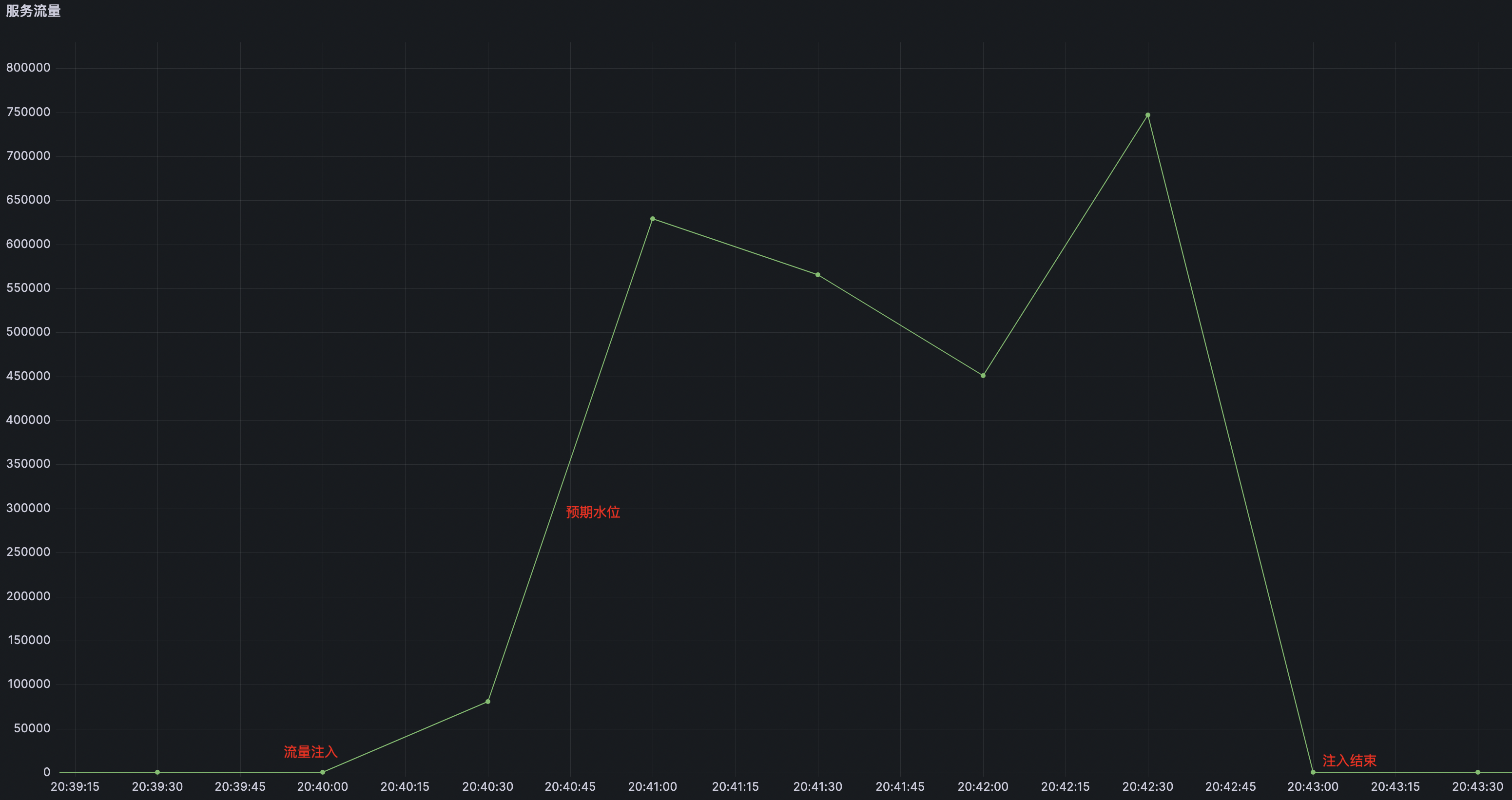
然后剩下的就是度量故障生效点以及业务恢复时间点的了,用来收集数据以便分析应急效率

未来方向
接下来我们会继续完善各方面的能力
- 支持多云、非云管理,即管理跨集群的pod/node以及非k8s机器/裸容器;
- 完善度量能力的数据分析能力,当前只能度量出故障生效、定位、恢复等单一时刻,还不具备联合多节点的时刻进行分析(比如:恢复时刻-生效时刻 < 目标耗时);
- 支持更多各类节点的原子能力,比如支持mysql、oceanbase、redis等主流开源项目的业务级别故障能力;
- 支持一些跟大模型训练稳定性以及推理架构风险相关的故障能力以及度量能力,比如GPU高负载注入。
加入我们
作为一个开放的项目,我们认可开源的研发模式,并致力于将 ChaosMeta 社区打造成一个开放和有创造力的社区。后续,所有的研发、讨论等相关工都会在社区透明运行。
我们欢迎任何形式的参与,包括且不限于提问、代码贡献、技术讨论、需求建议等。期待收到社区想法和反馈,以推动项目往前进一步发展。
如果对我们的项目或者设计理念感兴趣,请 star 我们的项目给予支持。
项目 GitHub 地址:https://github.com/traas-stack/chaosmeta
官方文档:https://chaosmeta.gitbook.io/chaosmeta-cn
微信群:请添加负责人(微信号:KingsonKai)邀请入1群,或者扫码入2群


钉钉群:21765030887

公众号:ChaosMeta混沌工程
