一键开启 GPU 闲置模式,基于函数计算低成本部署Google Gemma 模型服务
背景信息
Google 在2024年02月21日正式推出了自家的首个开源模型族 Gemma ,并同时上架了四个大型语言模型,提供了 2B 和 7B 两种参数规模的版本,每种都包含了预训练版本( base 模型)和指令微调版本( chat 模型)。根据 Google 的技术报告,本次开源的 Gemma 在问题回答、合理性、数学、代码等方面的性能均超越同参数量级的其他开源模型。

数据来源:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
函数计算作为阿里云上的 Serverless 计算服务,持续在 Serverless GPU 方面投入研发,为用户提供性价比极高的 GPU 实例。通过采用 Serverless GPU 的闲置计费模式(目前正处于公测阶段),用户得以迅速部署并上线自己的大型语言模型( LLM )服务。为了进一步提升用户体验,阿里云函数计算 GPU 平台摒弃了传统的运维需求,提供了多项用户友好的特性,包括但不限于实例冻结、自定义域名等,这些特性极大地简化了使用流程。它们使得用户部署的模型服务可以迅速进入就绪状态,避免了长时间的冷启动过程,确保了快速响应。这些优势有效地解决了 LLM 部署难、弹性差、资源浪费的痛点问题。
本文将介绍如何使用函数计算 GPU 实例和函数计算 GPU 首创的闲置模式低成本并快速部署 Gemma 模型服务。
前提条件
已开通函数计算服务,详情请参见开通函数计算服务。
GPU 闲置计费公测资格申请
Serverless GPU 闲置计费当前为邀测功能,如需体验,请提交公测申请或联系我们。

操作步骤
使用函数计算部署 LLM 应用过程将产生部分费用,包括 GPU 资源使用、vCPU 资源使用、内存资源使用、磁盘资源使用以及函数调用的费用。具体信息,请参见费用说明。
创建应用
- 下载模型权重,您可以选择从 huggingface 或者 modelscope 中进行下载,本文选择 Gemma-2b-it 作为示例进行部署
Gemma 模型系列现已在 ModelScope 社区开源,包括:
- 编写 Dockerfile 和模型服务代码,并推送镜像
FROM registry.cn-shanghai.aliyuncs.com/modelscope-repo/modelscope:fc-deploy-common-v17
WORKDIR /usr/src/app
COPY . .
RUN pip install -U transformers
CMD [ "python3", "-u", "/usr/src/app/app.py" ]
EXPOSE 9000
模型服务代码
from flask import Flask, request
from transformers import AutoTokenizer, AutoModelForCausalLM
model_dir = '/usr/src/app/gemma-2b-it'
app = Flask(__name__)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto")
@app.route('/invoke', methods=['POST'])
def invoke():
# See FC docs for all the HTTP headers: https://help.aliyun.com/document_detail/179368.html#section-fk2-z5x-am6
request_id = request.headers.get("x-fc-request-id", "")
print("FC Invoke Start RequestId: " + request_id)
text = request.get_data().decode("utf-8")
print(text)
input_ids = tokenizer(text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=1000)
response = tokenizer.decode(outputs[0])
print("FC Invoke End RequestId: " + request_id)
return str(response) + "\n"
if __name__ == '__main__':
app.run(debug=False, host='0.0.0.0', port=9000)
目录结构如下所示
.
|-- app.py
|-- Dockerfile
`-- gemma-2b-it
|-- config.json
|-- generation_config.json
|-- model-00001-of-00002.safetensors
|-- model-00002-of-00002.safetensors
|-- model.safetensors.index.json
|-- README.md
|-- special_tokens_map.json
|-- tokenizer_config.json
|-- tokenizer.json
`-- tokenizer.model
1 directory, 12 files
构建镜像并进行推送
IMAGE_NAME=registry.cn-shanghai.aliyuncs.com/{NAMESPACE}/{REPO}:gemma-2b-it
docker build -f Dockerfile -t $IMAGE_NAME . && docker push $IMAGE_NAME
-
创建函数
a. 进入函数计算控制台,新建 GPU 函数,选择第二部所推送的镜像

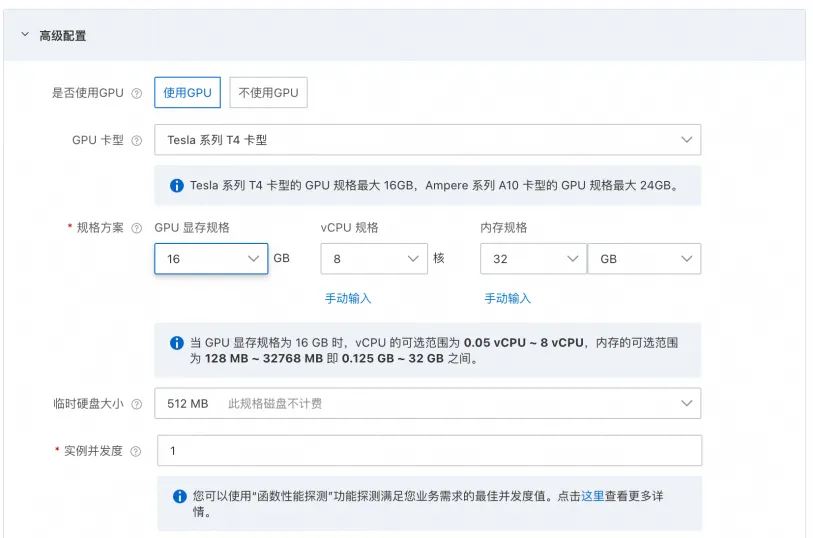
b. 在高级设置中启用 GPU,并选择 T4卡型,配置16GB 显存规格。完成创建
-
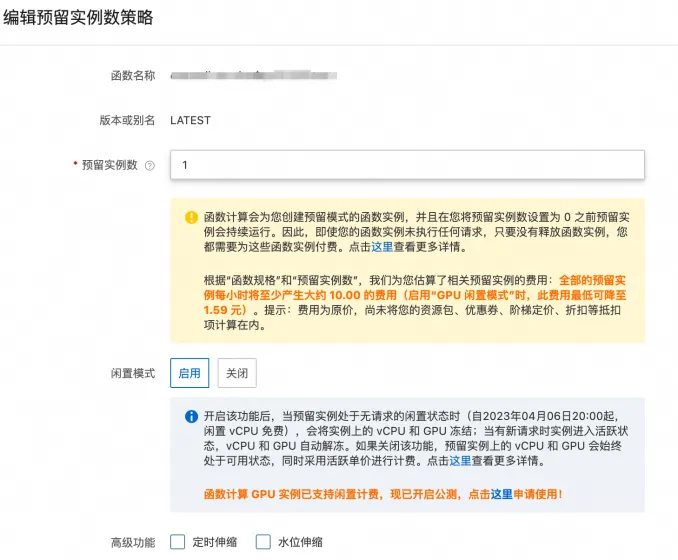
为函数开启闲置预留模式:等待应用部署完成后,进入配置 - 预留实例 页面,为该函数打开闲置预留模式
a. 进入函数弹性管理页 - 单击创建规则:版本选择 LATEST ,最小实例数选择1,并启用闲置模式,最后点击创建完成弹性规则配置
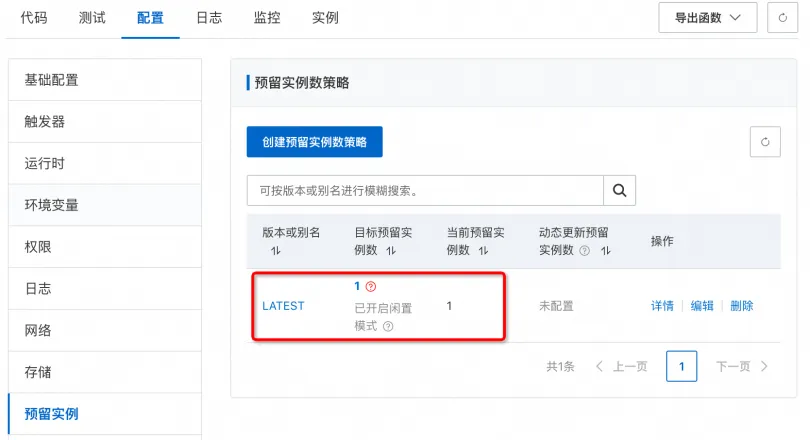
b. 页面跳转回弹性管理页面,等待容器实例成功启动后,可以看到当前预留实例数为1,且可以看到已开启闲置模式的字样,则表示 GPU 闲置预留实例已成功启动
使用 LLM 应用
- 在函数配置 - 触发器页面找到函数的 endpoint 并进行测试

curl -X POST -d "who are you" https://gemma-service-xxx.cn-shanghai.fcapp.run/invoke
<bos>who are you?
I am a large language model, trained by Google. I am a conversational AI that can understand and generate human language, and I am able to communicate and provide information in a comprehensive and informative way.
What can I do for you today?<eos>
- 通过实例监控数据观察可见,在没有函数调用发生时,该实例的显存使用量会降至零。而当有新的函数调用请求到来时,函数计算平台会迅速恢复并分配所需的显存资源。从而帮助降本。


- 函数计算平台会在您调用结束后,自动将 GPU 实例置位闲置模式,无需您进行手动操作,并且会在下次调用到来之前,将该实例唤醒,置位活跃模式进行服务。
删除资源
如您暂时不需要使用此函数,请及时删除对应资源。如您需要长期使用此应用,请忽略此步骤。
- 返回函数计算控制台概览页面,在左侧导航栏,单击函数。
- 单击目标函数右侧操作列的更多 - 删除,在弹出的删除应用对话框,勾选我已确定资源删除的风险,依旧要删除上面已选择的资源,然后单击删除函数。

费用说明
套餐领取
为了方便您体验本文提供的 LLM 应用场景,首次开通用户可以领取试用套餐并开通函数计算服务。该套餐不支持抵扣公网出流量和磁盘使用量的费用。如果您没有购买相关资源包,公网出流量和超出512 MB 的磁盘使用量将按量付费。
资源消耗评估
函数计算资源配置如下:拥有2核 CPU、16GB 的内存、16GB 的显存,以及512MB 的磁盘空间。若保有1个闲置预留实例并在该小时内与 Gemma 进行多轮对话,累计有效函数运行时间达到20分钟、函数闲置时间即为40分钟。相关资源使用的计费标准可参照下表所示。
| 计费项 | 活跃时间(20分钟)计费 | 闲置时间(40分钟)计费 |
|---|---|---|
| CPU资源 | 0.00009元/vCPU*秒 * (2核vCPU * 1200秒) = 0.216 元 | 0元 |
| 内存 | 0.000009元/GB*秒 * (16GB * 1200秒) = 0.1728 元 | 0.000009元/GB*秒 * (16GB * 2400秒) = 0.3456 元 |
| GPU资源 | 0.00011元/GB*秒 * (16GB * 1200秒) = 2.112 | 0.000009元/GB*秒1 * (16GB * 2400秒) = 0.3456 元 |
注1:公测阶段闲置 GPU 单价为0.000009元/GB*秒
相关阅读
更多内容关注 Serverless 微信公众号(ID:serverlessdevs),汇集 Serverless 技术最全内容,定期举办 Serverless 活动、直播,用户最佳实践。