AtCoder Beginner Contest 353
A - Buildings (abc353 A)
题目大意
给定\(n\)个数字,输出第一个大于第一个数的下标。
解题思路
依次与第一个数比较,大于则输出。
神奇的代码
n = input()
a = list(map(int, input().split()))
b = [i > a[0] for i in a]
if True not in b:
print(-1)
else:
print(b.index(True) + 1)
B - AtCoder Amusement Park (abc353 B)
题目大意
\(n\)组,每组若干个人,坐云霄飞车。
每个飞车只有 \(k\)个座位。依次给这\(n\)组人安排飞车,若该组人可以坐进飞车,则坐。否则另开一个新的飞车给他们坐。
问最后用了多少个飞车。
解题思路
按照题意模拟,维护当前飞车剩余座位数量,然后判断是否新开一个飞车。
神奇的代码
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
int main(void) {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int n, k;
cin >> n >> k;
int ans = 0;
int cur = k;
for (int i = 0; i < n; i++) {
int x;
cin >> x;
if (cur < x) {
++ans;
cur = k;
}
cur -= x;
}
cout << ans + 1 << endl;
return 0;
}
C - Sigma Problem (abc353 C)
题目大意
给定\(n\)个数\(a_i\),求 \(\sum_{i=1}^{n-1} \sum_{j=i+1}^{n} (a_i + a_j) \mod 10^8\)
解题思路
注意不是总的求和对\(mo = 10^8\)取模。 \(a \% mo + b \% mo \neq (a + b) \% mo\)
朴素做法是\(O(n^2)\),会超时,优化方向一般是枚举一个数,考虑\(\sum\)能否快速算出来。
由于是加法,所以\((a+b) \% mo\)的结果只有两种:
- \((a+b) \% mo = a+b, a+b < mo\)
- \((a+b) \% mo = a+b - mo, a+b \geq mo\)
于是我们可以把取模操作拆分成两种情况的加法:\(a+b\)或 \(a+(b - mo)\)。
因此我们先对这\(n\)个数排序,然后枚举当前数\(a_j\),计算\(\sum_{i=1}^{j-1} (a_i + a_j) \% mo\)
由前面的分析,可以将\(a_i\)就分成两部分:
- 第一部分的 \(a_i + a_j < mo\),因此 \(\sum (a_i + a_j) \% mo = \sum_1 a_i + cnt_1 \times a_j\)
- 第二部分的 \(a_i + a_j \geq mo\),因此 \(\sum (a_i + a_j) \% mo = \sum_2 a_i + cnt_2 \times (a_j - mo)\)
由于\(a_i\)是递增的,所以可以通过二分找到第一部分第二部分的分界点 \(a_k\)(这里认为是最后一个的第一部份的),由此 \(i \leq k\)的都是满足第一部分的 \(a_i\), \(k < i < j\)的是满足第二部分的 \(a_i\)。
因此\(\sum_1 a_i = presum[k], cnt = k\),\(\sum_2 a_i = presum[j - 1] - presum[k], cnt_2 = j - 1 - k\),其中\(presum[i] = \sum_{i=1}^{k} a_i\)是一个预处理的前缀和数组。
两部分加起来,就是\(\sum_{i=1}^{j-1} (a_i + a_j) \% mo\)。对所有的\(a_j\)求和,即为答案。
上述也可以理解成,对于一个\(a_j\),它与所有的 \(a_i\)相加取模,看要 \(- mo\)的数量。
总的时间复杂度是 \(O(n\log n)\)。将取模换成 绝对值之类的,做法其实是一样的,分类讨论来去掉绝对值后,分别求和。
代码里下标是从\(0\)开始的,分界点是第二部分的第一个,与上述的解释有点出入。
神奇的代码
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
int main(void) {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int n;
cin >> n;
int mo = 1e8;
vector<LL> a(n);
for (auto& x : a)
cin >> x;
sort(a.begin(), a.end());
vector<LL> presum(n);
partial_sum(a.begin(), a.end(), presum.begin());
LL ans = 0;
LL sum = 0;
for (int i = 0; i < n; ++i) {
LL bu = mo - a[i];
if (a[i] < bu) {
ans += a[i] * i + sum;
} else {
auto pos = lower_bound(a.begin(), a.begin() + i, bu) - a.begin();
LL p = pos > 0 ? presum[pos - 1] : 0;
ans += a[i] * pos + p;
LL suf = sum - p;
ans += suf - bu * (i - pos);
}
sum += a[i];
}
cout << ans << '\n';
return 0;
}
D - Another Sigma Problem (abc353 D)
题目大意
给定\(n\)个数\(a_i\),求 \(\sum_{i=1}^{n-1} \sum_{j=i+1}^{n} f(a_i, a_j) \mod 998244353\)
其中\(f(a,b) = ab\),即拼接起来(不是相乘)。最后的结果取模。
解题思路
朴素做法是\(O(n^2)\),会超时,优化方向一般是枚举一个数,考虑\(\sum\)能否快速算出来。
从左到右枚举\(a_i\),考虑 \(\sum_{j=i+1}^{n} f(a_i, a_j)\)的值,容易发现有两部分:
- 第一部分显然是 \(\sum_{j=i+1}^{n} a_j\)。一个后缀和。
- 第二部分是关于\(a_i\)的,由于 \(f(a,b) = ab\),\(b\)就是第一部分, \(a\) 则相当于\(a \times 10^{g(b)}\) ,其中\(g(b)\)表示 \(b\)的位数。 即 \(a_i \sum_{j=i+1}^{n} 10^{g(a_j)}\),一个关于 \(10^{g(a_j)}\)的后缀和。
从右往左枚举的话,就可以顺便维护后缀和。
代码里是考虑每个数对答案的贡献,对于每个 \(a_k\),分别计算作为 \(a_j\)和 \(a_i\)的贡献,即 作为低位时的贡献和作为高位时的贡献。
神奇的代码
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
const int mo = 998244353;
int main(void) {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int n;
cin >> n;
vector<int> a(n);
for (auto& x : a)
cin >> x;
LL sum = 0;
LL ten = 0;
auto calc_ten = [&](int x) {
int cnt = 0;
while (x) {
++cnt;
x /= 10;
}
LL val = 1;
while (cnt--)
val *= 10;
return val;
};
for (int i = n - 1; i >= 0; --i) {
sum += 1ll * a[i] * i % mo;
sum += 1ll * a[i] * ten % mo;
sum %= mo;
LL val = calc_ten(a[i]);
ten += val;
ten %= mo;
}
cout << sum << '\n';
return 0;
}
E - Yet Another Sigma Problem (abc353 E)
题目大意
给定\(n\)个字符串,求 \(\sum_{i=1}^{n-1} \sum_{j=i+1}^{n} lcp(s_i, s_j)\)
\(lcp(a,b)\)表示串 \(a,b\)的最长公共前缀。
解题思路
之前有道abc287e与这个类似,是求\(\max\)。那个有一些特别的性质,但这里要求和。
字符串前缀这种东西,一般会和字典树\(Trie\)相关,因为它正巧把拥有相同前缀的字符串合并了。
将这\(n\)个字符串都插入到字典树里,考虑如何计算答案。一个可能的想法是,比如我遍历到最深的节点,字符串个数可能只有一个,然后看其父亲,有分叉点,然后有若干个,这个时候可以组合数一下,得到 \(lcp\)是对应深度的个数,然后再考虑父亲节点之类的。这样做是是可以,但得认真考虑组合数的计算,避免算重。
一个简便的计算方法,则是将 \(lcp\)看成 \(1+1+1+...\),这里虽然都是数字 \(1\),但是有意义的: \(lcp = 4 = 1 + 1 + 1 + 1 =\)前一位字母相同 + 前二位字母相同 + 前三位字母相同 + 前四位字母相同 。比如两个字符串的\(lcp\)是 \(4\),则它分别对 前一位字母相同、前两位字母相同、前三位字母相同、前四位字母相同分别有\(1\)的贡献。而这四个相同情况的和就是 \(\sum \sum lcp\),我们只要分别求出,前一位字母相同、前二位字母相同......有多少贡献即可,即字符串对数,满足前一位字母相同,前二位相同...。注意这里与\(lcp\)的区别, \(lcp\)是最长的,而这里只需要前 \(i\)位。
由此,\(\sum \sum lcp = \sum_{lcp=i} i \times\) 数量 \(= \sum_{i}\)前\(i\)位字母相同 \(\times\) 对数。我们的视角从求每个 \(lcp\)的数量转成求前\(i\)位字母相同的对数。
而前 \(i\)位字母相同的字符串对数,即为字典树中深度是 \(i\)的节点下字符串数量\(m\)的 \(C_m^2\)。
因此遍历下所有节点,对\(C_m^2\) 求和即为答案。总的时间复杂度是\(O(n)\)。
更进一步观察上面提到的两个方法,可以感觉出来,假想在一个全是\(1\)的二维格子,一种是对每一列求和,另一种是求每一行求和。
神奇的代码
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
const int SZ = 26;
template <typename T, typename K> struct Trie {
struct node {
K value;
bool is_terminal;
int vis_count;
array<int, SZ> children;
node(K val) : value(val) {
is_terminal = false;
children.fill(0);
vis_count = 0;
}
};
int cast(K val) {
int ret = val - 'a';
assert(ret < SZ and ret >= 0);
return ret;
}
vector<node> tree;
Trie(K val) { tree.push_back(node(val)); }
void insert(const T& sequence) {
int cur = 0;
for (int i = 0; i < (int)sequence.size(); i++) {
K value = sequence[i];
if (tree[cur].children[cast(value)] == 0) {
tree[cur].children[cast(value)] = (int)tree.size();
tree.emplace_back(value);
}
cur = tree[cur].children[cast(value)];
tree[cur].vis_count += 1;
}
tree[cur].is_terminal = true;
}
LL dfs(int cur) {
LL sum = 0;
for (int i = 0; i < SZ; i++) {
if (tree[cur].children[i] == 0)
continue;
int child_node = tree[cur].children[i];
sum += dfs(child_node);
}
sum += 1ll * tree[cur].vis_count * (tree[cur].vis_count - 1) / 2;
return sum;
}
};
int main(void) {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int n;
cin >> n;
Trie<string, char> tree('a');
for (int i = 0; i < n; i++) {
string s;
cin >> s;
tree.insert(s);
}
LL ans = tree.dfs(0);
cout << ans << '\n';
return 0;
}
F - Tile Distance (abc353 F)
题目大意
给定一个\(k\),其定义了一种网格。
比如\(k=3\)定义了如下网格: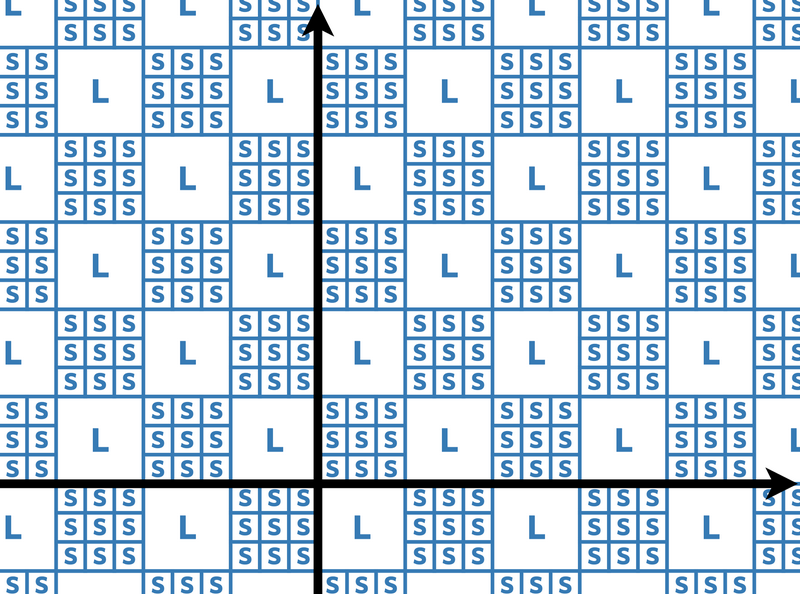
感性理解下,详细定义可去原问题。
从格子走到另一个格子代价是 \(1\)。
现在给定起点终点,问从起点到终点的最小代价。
解题思路
感觉就是一个大力分类讨论
神奇的代码
G - Merchant Takahashi (abc353 G)
题目大意
\(n\)个城市,给定 \(c\),定义了从城市 \(i \to j\)的花费为 \(c|i-j|\)。
有 \(m\)个活动依次举行,第 \(i\)个活动 在第\(t_i\)个城市举行,参加则获得 \(p_i\)收益。
初始在第 \(1\)个城市,问如何选择参加活动,使得收益最大化。
解题思路
我选择参加活动,则需要计算出城市间转移的代价,而该代价取决于我之前在哪个城市,因此状态信息里只需要保留该信息就可以转移了。
一个朴素的\(dp\)即为 \(dp[i][j]\)表示考虑前 \(m\)个活动后,我最终在城市 \(j\)的最大收益。转移则为\(dp[i][t_i] = \max_{1 \leq j \leq n}(dp[i - 1][j] - c|t_i - j|) + p_i\),每次转移其实只有\(dp[.][t_i]\)这一个值会发生变化,复用其他的值,时间复杂度是\(O(nm)\)。(复用的意思即为\(dp[t_i] = \max_{1 \leq j \leq n}(dp[j] - c|t_i - j|) + p_i\))
考虑优化转移,转移即为一个区间取最大值,但棘手在绝对值,解决办法就是通过分类讨论,将绝对值去掉。
\(dp[t_i] = \max( \max_{1 \leq j \leq t_i}(dp[j] + cj) - ct_i, \max_{t_i \leq j \leq n}(dp[j] - cj) + ct_i)\)
将绝对值拆掉后,转移式就变成了两个关于\(dp[j] + cj\)和 \(dp[j] - cj\)的区间最大值问题,用两个线段树维护这两类值即可。
时间复杂度是 \(O(m \log n)\)
神奇的代码
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
const int N = 2e5 + 8;
const LL inf = 1e18;
class segment {
#define lson (root << 1)
#define rson (root << 1 | 1)
public:
LL maxx[N << 2];
void build(int root, int l, int r, vector<LL>& a) {
if (l == r) {
maxx[root] = a[l - 1];
return;
}
int mid = (l + r) >> 1;
build(lson, l, mid, a);
build(rson, mid + 1, r, a);
maxx[root] = max(maxx[lson], maxx[rson]);
}
void update(int root, int l, int r, int pos, LL val) {
if (l == r) {
maxx[root] = max(maxx[root], val);
return;
}
int mid = (l + r) >> 1;
if (pos <= mid)
update(lson, l, mid, pos, val);
else
update(rson, mid + 1, r, pos, val);
maxx[root] = max(maxx[lson], maxx[rson]);
}
LL query(int root, int l, int r, int L, int R) {
if (L <= l && r <= R) {
return maxx[root];
}
int mid = (l + r) >> 1;
LL resl = -inf, resr = -inf;
if (L <= mid)
resl = query(lson, l, mid, L, R);
if (R > mid)
resr = query(rson, mid + 1, r, L, R);
return max(resl, resr);
}
} lsg, rsg;
int main(void) {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int n, c;
cin >> n >> c;
vector<LL> a(n);
for (int i = 0; i < n; ++i)
a[i] = -inf;
a[0] = 0;
rsg.build(1, 1, n, a);
lsg.build(1, 1, n, a);
int m;
cin >> m;
LL ans = 0;
for (int i = 0; i < m; ++i) {
int t;
LL p;
cin >> t >> p;
int id = t;
--t;
LL dp1 = lsg.query(1, 1, n, 1, id) - 1ll * c * t;
LL dp2 = rsg.query(1, 1, n, id, n) + 1ll * c * t;
LL dp = max(dp1, dp2) + p;
ans = max(ans, dp);
lsg.update(1, 1, n, id, dp + 1ll * c * t);
rsg.update(1, 1, n, id, dp - 1ll * c * t);
}
cout << ans << '\n';
return 0;
}
热门相关:冲破死亡游戏 我是狼之火龙山大冒险 追鱼 极度诱惑之屌丝逆袭 泥人哥连出世记