探索 Kubernetes 持久化存储之 Rook Ceph 初窥门径
在 Kubernetes 生态系统中,持久化存储是支撑业务应用稳定运行的基石,对于维护整个系统的健壮性至关重要。对于选择自主搭建 Kubernetes 集群的运维架构师来说,挑选合适的后端持久化存储解决方案是关键的选型决策。目前,Ceph、GlusterFS、NFS、Longhorn 和 openEBS 等解决方案已在业界得到广泛应用。
为了丰富技术栈,并为容器云平台的持久化存储设计提供更广泛的灵活性和选择性,今天,我将带领大家一起探索,如何将 Ceph 集成到由 KubeSphere 管理的 Kubernetes 集群中。
集成 Ceph 至 Kubernetes 集群主要有两种方案:
- 利用 Rook Ceph 直接在 Kubernetes 集群上部署 Ceph 集群,这种方式更贴近云原生的应用特性。
- 手动部署独立的 Ceph 集群,并配置 Kubernetes 集群与之对接,实现存储服务的集成。
本文将重点实战演示使用 Rook Ceph 在 Kubernetes 集群上直接部署 Ceph 集群的方法,让您体验到云原生环境下 Ceph 部署的便捷与强大。
实战服务器配置(架构 1:1 复刻小规模生产环境,配置略有不同)
| 主机名 | IP | CPU | 内存 | 系统盘 | 数据盘 | 用途 |
|---|---|---|---|---|---|---|
| ksp-registry | 192.168.9.90 | 4 | 8 | 40 | 200 | Harbor 镜像仓库 |
| ksp-control-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-worker-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-worker/CI |
| ksp-worker-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s-worker |
| ksp-worker-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s-worker |
| ksp-storage-1 | 192.168.9.97 | 4 | 8 | 40 | 400+ | Containerd、OpenEBS、ElasticSearch/Longhorn/Ceph/NFS |
| ksp-storage-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | Containerd、OpenEBS、ElasticSearch/Longhorn/Ceph |
| ksp-storage-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | Containerd、OpenEBS、ElasticSearch/Longhorn/Ceph |
| ksp-gpu-worker-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-worker-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA Tesla P100 16G) |
| ksp-gateway-1 | 192.168.9.103 | 2 | 4 | 40 | 自建应用服务代理网关/VIP:192.168.9.100 | |
| ksp-gateway-2 | 192.168.9.104 | 2 | 4 | 40 | 自建应用服务代理网关/VIP:192.168.9.100 | |
| ksp-mid | 192.168.9.105 | 4 | 8 | 40 | 100 | 部署在 k8s 集群之外的服务节点(Gitlab 等) |
| 合计 | 15 | 56 | 152 | 600 | 2100+ |
实战环境涉及软件版本信息
- 操作系统:openEuler 22.03 LTS SP3 x86_64
- KubeSphere:v3.4.1
- Kubernetes:v1.28.8
- KubeKey: v3.1.1
- Containerd:1.7.13
- Rook:v1.14.9
- Ceph: v18.2.4
1. Rook 部署规划
为了更好地满足生产环境的实际需求,在规划和部署存储基础设施时,我增加了以下策略:
- 节点扩展:向 Kubernetes 集群中新增三个专用节点,这些节点将专门承载 Ceph 存储服务,确保存储操作的高效性和稳定性。
- 组件隔离:所有 Rook 和 Ceph 组件以及数据卷将被部署在这些专属节点上,实现组件的清晰隔离和专业化管理。
- 节点标签化:为每个存储节点设置了专门的标签
node.kubernetes.io/storage=rook,以便 Kubernetes 能够智能地调度相关资源。同时,非存储节点将被标记为node.rook.io/rook-csi=true,这表明它们将承载 Ceph CSI 插件,使得运行在这些节点上的业务 Pod 能够利用 Ceph 提供的持久化存储。 - 存储介质配置:在每个存储节点上,我将新增一块 100G 的 Ceph 专用数据盘
/dev/sdd。为保证最佳性能,该磁盘将采用裸设备形态直接供 Ceph OSD 使用,无需进行分区或格式化。
重要提示:
- 本文提供的配置和部署经验对于理解 Rook-Ceph 的安装和运行机制具有参考价值。然而,强烈建议不要将本文描述的配置直接应用于任何形式的生产环境。
- 在生产环境中,还需进一步考虑使用 SSD、NVMe 磁盘等高性能存储介质;细致规划故障域;制定详尽的存储节点策略;以及进行细致的系统优化配置等。
2. 前置条件
2.1 Kubernetes 版本
-
Rook 可以安装在任何现有的 Kubernetes 集群上,只要它满足最低版本,并且授予 Rook 所需的特权
-
早期 v1.9.7 版本的 Rook 支持 Kubernetes v1.17 或更高版本
-
现在的 v1.14.9 版本支持 Kubernetes v1.25 到 v1.30 版本(可能支持更低的版本,可以自己验证测试)
2.2 CPU Architecture
支持的 CPU 架构包括: amd64 / x86_64 and arm64。
2.3 Ceph 先决条件
为了配置 Ceph 存储集群,至少需要以下任意一种类型的本地存储:
- Raw devices (no partitions or formatted filesystems,没有分区和格式化文件系统,本文选择)
- Raw partitions (no formatted filesystem,已分区但是没有格式化文件系统)
- LVM Logical Volumes (no formatted filesystem)
- PVs available from a storage class in
blockmode
使用以下命令确认分区或设备是否使用文件系统并进行了格式化:
$ lsblk -f
NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS
sda
├─sda1 ext4 1.0 b5e46d67-426b-476f-bd89-18137af7ff59 682.5M 23% /boot
└─sda2 LVM2_member LVM2 001 NepB96-M3ux-Ei6Q-V7AX-BCy1-e2RN-Lzbecn
├─openeuler-root ext4 1.0 0495bb1d-16f7-4156-ab10-5bd837b24de5 29.9G 7% /
└─openeuler-swap swap 1 837d3a7e-8aac-4048-bb7a-a6fdd8eb5931
sdb LVM2_member LVM2 001 Dyj93O-8zKr-HMah-hxjd-8IZP-IxVE-riWf3O
└─data-lvdata xfs 1e9b612f-dbd9-46d2-996e-db74073d6648 86G 14% /data
sdc LVM2_member LVM2 001 LkTCe2-0vp7-e3SJ-Xxzb-UzN1-sd2T-74TF3L
└─longhorn-data xfs 30a13ac0-6eef-433c-8d7e-d6776ec669ff 99.1G 1% /longhorn
sdd
- 如果 FSTYPE 字段不为空,说明该设备已经格式化为文件系统,对应的值就是文件系统类型
- 如果 FSTYPE 字段为空,说明该设备还没有被格式化,可以被 Ceph 使用
- 本例中可以使用的设备为 sdd
如果需要清理已有磁盘给 Ceph 使用,请使用下面的命令(生产环境请谨慎):
yum install gdisk
sgdisk --zap-all /dev/sdd
2.4 LVM 需求
Ceph OSDs 在以下场景依赖 LVM。
- If encryption is enabled (
encryptedDevice: "true"in the cluster CR) - A
metadatadevice is specified osdsPerDeviceis greater than 1
Ceph OSDs 在以下场景不需要 LVM。
- OSDs are created on raw devices or partitions
- Creating OSDs on PVCs using the
storageClassDeviceSets
openEuler 默认已经安装 lvm2,如果没有装,使用下面的命令安装。
yum install -y lvm2
2.5 Kernel 需求
- RBD 需求
Ceph 需要使用构建了 RBD 模块的 Linux 内核。许多 Linux 发行版都有这个模块,但不是所有发行版都有。例如,GKE Container-Optimised OS (COS) 就没有 RBD。
在 Kubernetes 节点使用 lsmod | grep rbd 命令验证,如果没有任何输出,请执行下面的命令加载 rbd 模块。
# 在当前环境加载 rbd 和 nbd 模块
modprobe rbd
modprobe nbd
# 开机自动加载 rbd 和 nbd 模式(适用于 openEuler)
echo "rbd" >> /etc/modules-load.d/rook-ceph.conf
echo "nbd" >> /etc/modules-load.d/rook-ceph.conf
# 再次执行命令验证
lsmod | grep rbd
# 正确的输出结果如下
$ lsmod | grep rbd
rbd 135168 0
libceph 413696 1 rbd
- CephFS 需求
如果您将从 Ceph shared file system (CephFS) 创建卷,推荐的最低内核版本是 4.17。如果内核版本小于 4.17,则不会强制执行请求的 PVC sizes。存储配额只会在更新的内核上执行。
注意: openEuler 22.03 SP3 目前最新的内核为 5.10.0-218.0.0.121,虽然大于 4.17 但是有些过于高了,在安装 Ceph CSI Plugin 的时候可能会遇到 CSI 驱动无法注册的问题。
3. 扩容集群节点
3.1 扩容存储专用 Worker 节点
将新增的三台存储专用节点加入已有的 Kubernetes 集群,详细的扩容操作请参考 KubeKey 扩容 Kubernetes Worker 节点实战指南。
3.2 设置节点标签
按规划给三个存储节点和其它 Worker 节点打上专属标签。
- 存储节点标签
# 设置 rook-ceph 部署和存储Osd 节点标签
kubectl label nodes ksp-storage-1 node.kubernetes.io/storage=rook
kubectl label nodes ksp-storage-2 node.kubernetes.io/storage=rook
kubectl label nodes ksp-storage-3 node.kubernetes.io/storage=rook
- Worker 节点标签
# 安装 ceph csi plugin 节点
# kubectl label nodes ksp-control-1 node.rook.io/rook-csi=true
# kubectl label nodes ksp-control-2 node.rook.io/rook-csi=true
# kubectl label nodes ksp-control-3 node.rook.io/rook-csi=true
kubectl label nodes ksp-worker-1 node.rook.io/rook-csi=true
kubectl label nodes ksp-worker-2 node.rook.io/rook-csi=true
kubectl label nodes ksp-worker-3 node.rook.io/rook-csi=true
- 控制(Control)节点
不做任何设置,Ceph 的服务组件和 CSI 插件都不会安装在控制节点。网上也有人建议把 Ceph 的管理组件部署在 K8s 的控制节点,我是不赞同的。个人建议把 Ceph 的所有组件独立部署。
4. 安装配置 Rook Ceph Operator
4.1 下载部署代码
# git clone --single-branch --branch v1.14.9 https://github.com/rook/rook.git
cd /srv
wget https://github.com/rook/rook/archive/refs/tags/v1.14.9.tar.gz
tar xvf v1.14.9.tar.gz
cd rook-1.14.9/deploy/examples/
4.2 修改镜像地址
可选配置,当 DockerHub 访问受限时,可以将 Rook-Ceph 需要的镜像离线下载到本地仓库,部署时修改镜像地址。
# 取消镜像注释
sed -i '125,130s/^.*#/ /g' operator.yaml
sed -i '506,506s/^.*#/ /g' operator.yaml
# 替换镜像地址前缀
sed -i 's#registry.k8s.io#registry.opsxlab.cn:8443/k8sio#g' operator.yaml
sed -i 's#quay.io#registry.opsxlab.cn:8443/quayio#g' operator.yaml
sed -i 's#rook/ceph:v1.14.9#registry.opsxlab.cn:8443/rook/ceph:v1.14.9#g' operator.yaml
sed -i '24,24s#quay.io#registry.opsxlab.cn:8443/quayio#g' cluster.yaml
注意:上面的镜像仓库是我内部离线仓库,参考我文档的读者不要直接照抄,一定要换成自己的镜像仓库。
4.3 修改自定义配置
修改配置文件 operator.yaml 实现以下需求:
- rook-ceph 所有管理组件部署在指定标签节点
- k8s 其他节点安装 Ceph CSI Plugin
CSI_PROVISIONER_NODE_AFFINITY: "node.kubernetes.io/storage=rook"
CSI_PLUGIN_NODE_AFFINITY: "node.rook.io/rook-csi=true,node.kubernetes.io/storage=rook"
4.4 部署 Rook Operator
- 部署 Rook operator
kubectl create -f crds.yaml -f common.yaml -f operator.yaml
- 验证
rook-ceph-operatorPod 的状态是否为Running
kubectl -n rook-ceph get pod -o wide
执行成功后,输出结果如下:
$ kubectl -n rook-ceph get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
rook-ceph-operator-9bd897ff8-426mq 1/1 Running 0 40s 10.233.77.255 ksp-storage-3 <none> <none>
4.5 KubeSphere 控制台查看 Operator 资源
登录 KubeSphere 控制台查看创建的 Rook Ceph Operator Deployment 资源。

5. 创建 Ceph 集群
5.1 修改集群配置文件
- 修改集群配置文件
cluster.yaml,增加节点亲和配置
placement:
all:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node.kubernetes.io/storage
operator: In
values:
- rook
- 修改集群配置文件
cluster.yaml,增加存储节点和 OSD 磁盘配置
storage: # cluster level storage configuration and selection
useAllNodes: false # 生产环境,一定要修改,默认会使用所有节点
useAllDevices: false # 生产环境,一定要修改,默认会使用所有磁盘
#deviceFilter:
config:
storeType: bluestore
nodes:
- name: "ksp-storage-1"
devices:
- name: "sdd"
- name: "ksp-storage-2"
devices:
- name: "sdd"
- name: "ksp-storage-3"
devices:
- name: "sdd"
5.2 创建 Ceph 集群
- 创建集群
kubectl create -f cluster.yaml
- 查看资源状态,确保所有相关 Pod 均为
Running
$ kubectl -n rook-ceph get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
csi-cephfsplugin-5mrxf 2/2 Running 0 2m25s 192.168.9.96 ksp-worker-3 <none> <none>
csi-cephfsplugin-5s4kz 2/2 Running 0 2m25s 192.168.9.95 ksp-worker-2 <none> <none>
csi-cephfsplugin-kgd48 2/2 Running 0 2m25s 192.168.9.94 ksp-worker-1 <none> <none>
csi-cephfsplugin-provisioner-7f595d6cc4-5xpm8 5/5 Running 0 2m25s 10.233.64.1 ksp-storage-1 <none> <none>
csi-cephfsplugin-provisioner-7f595d6cc4-q7q4v 5/5 Running 0 2m25s 10.233.77.26 ksp-storage-3 <none> <none>
csi-cephfsplugin-q7rqj 2/2 Running 0 2m25s 192.168.9.97 ksp-storage-1 <none> <none>
csi-cephfsplugin-x6tfj 2/2 Running 0 2m25s 192.168.9.99 ksp-storage-3 <none> <none>
csi-cephfsplugin-z72tl 2/2 Running 0 2m25s 192.168.9.98 ksp-storage-2 <none> <none>
csi-rbdplugin-2f8db 2/2 Running 0 2m25s 192.168.9.97 ksp-storage-1 <none> <none>
csi-rbdplugin-6dtwt 2/2 Running 0 2m25s 192.168.9.94 ksp-worker-1 <none> <none>
csi-rbdplugin-82jrf 2/2 Running 0 2m25s 192.168.9.95 ksp-worker-2 <none> <none>
csi-rbdplugin-dslkj 2/2 Running 0 2m25s 192.168.9.96 ksp-worker-3 <none> <none>
csi-rbdplugin-gjmmw 2/2 Running 0 2m25s 192.168.9.98 ksp-storage-2 <none> <none>
csi-rbdplugin-hfv4k 2/2 Running 0 2m25s 192.168.9.99 ksp-storage-3 <none> <none>
csi-rbdplugin-provisioner-c845669bc-dp6q4 5/5 Running 0 2m25s 10.233.64.4 ksp-storage-1 <none> <none>
csi-rbdplugin-provisioner-c845669bc-f2s6n 5/5 Running 0 2m25s 10.233.77.24 ksp-storage-3 <none> <none>
rook-ceph-crashcollector-ksp-storage-1-7b4cf6c8fb-7s85r 1/1 Running 0 68s 10.233.64.7 ksp-storage-1 <none> <none>
rook-ceph-crashcollector-ksp-storage-2-cc76b86dc-vb4gl 1/1 Running 0 53s 10.233.73.85 ksp-storage-2 <none> <none>
rook-ceph-crashcollector-ksp-storage-3-67bf8cf566-6rcjg 1/1 Running 0 52s 10.233.77.39 ksp-storage-3 <none> <none>
rook-ceph-exporter-ksp-storage-1-646fb48465-5mfcx 1/1 Running 0 68s 10.233.64.14 ksp-storage-1 <none> <none>
rook-ceph-exporter-ksp-storage-2-79fd64549d-rbcnt 1/1 Running 0 50s 10.233.73.86 ksp-storage-2 <none> <none>
rook-ceph-exporter-ksp-storage-3-7877646d8c-7h2wc 1/1 Running 0 48s 10.233.77.32 ksp-storage-3 <none> <none>
rook-ceph-mgr-a-c89b4f8bd-psdwl 3/3 Running 0 86s 10.233.73.80 ksp-storage-2 <none> <none>
rook-ceph-mgr-b-7ffd8dcb85-jpj5x 3/3 Running 0 86s 10.233.77.29 ksp-storage-3 <none> <none>
rook-ceph-mon-a-654b4f677-fmqhx 2/2 Running 0 2m15s 10.233.73.79 ksp-storage-2 <none> <none>
rook-ceph-mon-b-74887d5b9c-4mb62 2/2 Running 0 109s 10.233.77.28 ksp-storage-3 <none> <none>
rook-ceph-mon-c-5fb5489c58-7hj6n 2/2 Running 0 99s 10.233.64.16 ksp-storage-1 <none> <none>
rook-ceph-operator-9bd897ff8-6z45z 1/1 Running 0 29m 10.233.77.18 ksp-storage-3 <none> <none>
rook-ceph-osd-0-65ccb887ff-bjtbs 2/2 Running 0 54s 10.233.64.19 ksp-storage-1 <none> <none>
rook-ceph-osd-1-c689d9f57-x6prx 2/2 Running 0 53s 10.233.73.84 ksp-storage-2 <none> <none>
rook-ceph-osd-2-776bb9cbd6-vmxxp 2/2 Running 0 52s 10.233.77.37 ksp-storage-3 <none> <none>
rook-ceph-osd-prepare-ksp-storage-1-tj6rk 0/1 Completed 0 64s 10.233.64.18 ksp-storage-1 <none> <none>
rook-ceph-osd-prepare-ksp-storage-2-rds4q 0/1 Completed 0 63s 10.233.73.83 ksp-storage-2 <none> <none>
rook-ceph-osd-prepare-ksp-storage-3-hpzgs 0/1 Completed 0 63s 10.233.77.41 ksp-storage-3 <none> <none>
5.3 KubeSphere 控制台查看 Ceph 集群资源
- Deployment(部署,17个)

- Daemonsets(守护进程集,2个)

6. 创建 Rook toolbox
通过 Rook 提供的 toolbox,我们可以实现对 Ceph 集群的管理。
6.1 创建 toolbox
- 创建 toolbox
kubectl apply -f toolbox.yaml
- 等待 toolbox pod 下载容器镜像,并进入 Running 状态:
kubectl -n rook-ceph rollout status deploy/rook-ceph-tools
6.2 常用命令
- 登录 Toolbox
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
- 验证 Ceph 集群状态
$ kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
bash-5.1$ ceph -s
cluster:
id: e7913148-d29f-46fa-87a6-1c38ddb1530a
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 6m)
mgr: a(active, since 5m), standbys: b
osd: 3 osds: 3 up (since 5m), 3 in (since 5m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 577 KiB
usage: 81 MiB used, 300 GiB / 300 GiB avail
pgs: 1 active+clean
观察 Ceph 集群状态,需要满足下面的条件才会认为集群状态是健康的。
- health 的值为 HEALTH_OK
- Mons 的数量和状态
- Mgr 一个 active,一个 standbys
- OSD 3 个,状态都是 up
- 其他常用的 Ceph 命令
# 查看 OSD 状态
ceph osd status
ceph osd df
ceph osd utilization
ceph osd pool stats
ceph osd tree
# 查看 Ceph 容量
ceph df
# 查看 Rados 状态
rados df
# 查看 PG 状态
ceph pg stat
- 删除 toolbox(可选)
kubectl -n rook-ceph delete deploy/rook-ceph-tools
7. Block Storage
7.1 Storage 介绍
Rock Ceph 提供了三种存储类型,请参考官方指南了解详情:
- Block Storage(RBD): Create block storage to be consumed by a pod (RWO)
- Filesystem Storage(CephFS): Create a filesystem to be shared across multiple pods (RWX)
- Object Storage(RGW): Create an object store that is accessible inside or outside the Kubernetes cluster
本文使用比较稳定、可靠的 Block Storage(RBD)的方式作为 Kubernetes 的持久化存储。
7.2 创建存储池
Rook 允许通过自定义资源定义 (crd) 创建和自定义 Block 存储池。支持 Replicated 和 Erasure Coded 类型。本文演示 Replicated 的创建过程。
- 创建一个 3 副本的 Ceph 块存储池,编辑
CephBlockPoolCR 资源清单,vi ceph-replicapool.yaml
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
namespace: rook-ceph
spec:
failureDomain: host
replicated:
size: 3
- 创建 CephBlockPool 资源
kubectl create -f ceph-replicapool.yaml
- 查看资源创建情况
$ kubectl get cephBlockPool -n rook-ceph -o wide
NAME PHASE TYPE FAILUREDOMAIN REPLICATION EC-CODINGCHUNKS EC-DATACHUNKS AGE
replicapool Ready Replicated host 3 0 0 16s
- 在 ceph toolbox 中查看 Ceph 集群状态
# 登录
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
# 查看集群
bash-5.1$ ceph -s
cluster:
id: e7913148-d29f-46fa-87a6-1c38ddb1530a
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 10m)
mgr: a(active, since 8m), standbys: b
osd: 3 osds: 3 up (since 9m), 3 in (since 9m)
data:
pools: 2 pools, 2 pgs
objects: 3 objects, 577 KiB
usage: 81 MiB used, 300 GiB / 300 GiB avail
pgs: 2 active+clean
# 查看集群存储池
bash-5.1$ ceph osd pool ls
.mgr
replicapool
bash-5.1$ rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
.mgr 1.7 MiB 2 0 6 0 0 0 106 91 KiB 137 1.8 MiB 0 B 0 B
replicapool 12 KiB 1 0 3 0 0 0 0 0 B 2 2 KiB 0 B 0 B
total_objects 3
total_used 81 MiB
total_avail 300 GiB
total_space 300 GiB
# 查看存储池的 pg number
bash-5.1$ ceph osd pool get replicapool pg_num
pg_num: 32
7.3 创建 StorageClass
- 编辑 StorageClass 资源清单,
vi storageclass-rook-ceph-block.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
# Change "rook-ceph" provisioner prefix to match the operator namespace if needed
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
# clusterID is the namespace where the rook cluster is running
clusterID: rook-ceph
# Ceph pool into which the RBD image shall be created
pool: replicapool
# RBD image format. Defaults to "2".
imageFormat: "2"
# RBD image features. Available for imageFormat: "2". CSI RBD currently supports only `layering` feature.
imageFeatures: layering
# The secrets contain Ceph admin credentials.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
# Specify the filesystem type of the volume. If not specified, csi-provisioner
# will set default as `ext4`. Note that `xfs` is not recommended due to potential deadlock
# in hyperconverged settings where the volume is mounted on the same node as the osds.
csi.storage.k8s.io/fstype: ext4
# Delete the rbd volume when a PVC is deleted
reclaimPolicy: Delete
# Optional, if you want to add dynamic resize for PVC.
# For now only ext3, ext4, xfs resize support provided, like in Kubernetes itself.
allowVolumeExpansion: true
- 创建 StorageClass 资源
kubectl create -f storageclass-rook-ceph-block.yaml
注意: examples/csi/rbd 目录中有更多的参考用例。
- 验证资源
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
local openebs.io/local Delete WaitForFirstConsumer false 76d
nfs-sc (default) k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 22d
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 11s
8. 创建测试应用
8.1 使用 Rook 提供的测试案例
我们使用 Rook 官方提供的经典的 Wordpress 和 MySQL 应用程序创建一个使用 Rook 提供块存储的示例应用程序,这两个应用程序都使用由 Rook 提供的块存储卷。
- 创建 MySQL 和 Wordpress
kubectl create -f mysql.yaml
kubectl create -f wordpress.yaml
- 查看 PVC 资源
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pv-claim Bound pvc-938fc531-cff8-452b-b89a-0040ac0aaa02 20Gi RWO rook-ceph-block 31s
wp-pv-claim Bound pvc-d94118de-7105-4a05-a4e7-ebc5807cc5c1 20Gi RWO rook-ceph-block 13s
- 查看 SVC 资源
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 76d
wordpress LoadBalancer 10.233.25.187 <pending> 80:31280/TCP 33s
wordpress-mysql ClusterIP None <none> 3306/TCP 50s
- 查看 Pod 资源
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
wordpress-6678b8879f-ql6sm 1/1 Running 0 49s 10.233.73.89 ksp-storage-2 <none> <none>
wordpress-mysql-5d69d6696b-fwttl 1/1 Running 0 67s 10.233.64.15 ksp-storage-1 <none> <none>
8.2 指定节点创建测试应用
Wordpress 和 MySQL 测试用例中,pod 创建在了存储专用节点。为了测试集群中其它 Worker 节点是否可以使用 Ceph 存储,我们再做一个测试,在创建 Pod 时指定 nodeSelector 标签,将 Pod 创建在非 rook-ceph 专用节点的 ksp-worker-1 上。
- 编写测试 PVC 资源清单,
vi test-pvc-rbd.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-pvc-rbd
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
- 创建 PVC
kubectl apply -f test-pvc-rbd.yaml
- 查看 PVC
$ kubectl get pvc -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
mysql-pv-claim Bound pvc-00c09bac-cee2-4a0e-9549-56f05b9c6965 20Gi RWO rook-ceph-block 77s Filesystem
test-pvc-rbd Bound pvc-ad475b29-6730-4c9a-8f8d-a0cd99b12781 2Gi RWO rook-ceph-block 5s Filesystem
wp-pv-claim Bound pvc-b3b2d6bc-6d62-4ac3-a50c-5dcf076d501c 20Gi RWO rook-ceph-block 76s Filesystem
- 编写测试 Pod 资源清单,
vi test-pod-rbd.yaml
kind: Pod
apiVersion: v1
metadata:
name: test-pod-rbd
spec:
containers:
- name: test-pod-rbd
image: busybox:stable
command:
- "/bin/sh"
args:
- "-c"
- "touch /mnt/SUCCESS && sleep 3600"
volumeMounts:
- name: rbd-pvc
mountPath: "/mnt"
restartPolicy: "Never"
nodeSelector:
kubernetes.io/hostname: ksp-worker-1
volumes:
- name: rbd-pvc
persistentVolumeClaim:
claimName: test-pvc-rbd
- 创建 Pod
kubectl apply -f test-pod-rbd.yaml
- 查看 Pod( Pod 按预期创建在了 ksp-worker-1 节点,并正确运行)
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pod-rbd 1/1 Running 0 5s 10.233.94.210 ksp-worker-1 <none> <none>
wordpress-6678b8879f-ql6sm 1/1 Running 0 10m 10.233.73.89 ksp-storage-2 <none> <none>
wordpress-mysql-5d69d6696b-fwttl 1/1 Running 0 10m 10.233.64.15 ksp-storage-1 <none> <none>
- 查看 Pod 挂载的存储
$ kubectl exec test-pod-rbd -- df -h
Filesystem Size Used Available Use% Mounted on
overlay 99.9G 14.0G 85.9G 14% /
tmpfs 64.0M 0 64.0M 0% /dev
tmpfs 7.6G 0 7.6G 0% /sys/fs/cgroup
/dev/rbd0 1.9G 24.0K 1.9G 0% /mnt
/dev/mapper/openeuler-root
34.2G 2.3G 30.1G 7% /etc/hosts
/dev/mapper/openeuler-root
34.2G 2.3G 30.1G 7% /dev/termination-log
/dev/mapper/data-lvdata
99.9G 14.0G 85.9G 14% /etc/hostname
/dev/mapper/data-lvdata
99.9G 14.0G 85.9G 14% /etc/resolv.conf
shm 64.0M 0 64.0M 0% /dev/shm
tmpfs 13.9G 12.0K 13.9G 0% /var/run/secrets/kubernetes.io/serviceaccount
tmpfs 7.6G 0 7.6G 0% /proc/acpi
tmpfs 64.0M 0 64.0M 0% /proc/kcore
tmpfs 64.0M 0 64.0M 0% /proc/keys
tmpfs 64.0M 0 64.0M 0% /proc/timer_list
tmpfs 64.0M 0 64.0M 0% /proc/sched_debug
tmpfs 7.6G 0 7.6G 0% /proc/scsi
tmpfs 7.6G 0 7.6G 0% /sys/firmware
- 测试存储空间读写
# 写入 1GB 的数据
$ kubectl exec test-pod-rbd -- dd if=/dev/zero of=/mnt/test-disk.img bs=1M count=1000
1000+0 records in
1000+0 records out
1048576000 bytes (1000.0MB) copied, 4.710019 seconds, 212.3MB/s
# 查看结果
$ kubectl exec test-pod-rbd -- ls -lh /mnt/
total 1000M
-rw-r--r-- 1 root root 0 Aug 5 20:11 SUCCESS
drwx------ 2 root root 16.0K Aug 5 20:11 lost+found
-rw-r--r-- 1 root root 1000.0M Aug 5 20:14 test-disk.img
# 测试超限(再写入 1GB 数据,只能写入 929.8MB)
$ kubectl exec test-pod-rbd -- dd if=/dev/zero of=/mnt/test-disk2.img bs=1M count=1000
dd: error writing '/mnt/test-disk2.img': No space left on device
930+0 records in
929+0 records out
974987264 bytes (929.8MB) copied, 3.265758 seconds, 284.7MB/s
command terminated with exit code 1
# 再次查看结果
$ kubectl exec test-pod-rbd -- ls -lh /mnt/
total 2G
-rw-r--r-- 1 root root 0 Aug 5 20:11 SUCCESS
drwx------ 2 root root 16.0K Aug 5 20:11 lost+found
-rw-r--r-- 1 root root 1000.0M Aug 5 20:14 test-disk.img
-rw-r--r-- 1 root root 929.8M Aug 5 20:18 test-disk2.img
注意: 测试时,我们写入了 2G 的数据量,当达过我们创建的 PVC 2G 容量上限时会报错(实际使用写不满 2G)。说明,Ceph 存储可以做到容量配额限制。
9. Ceph Dashboard
Ceph 提供了一个 Dashboard 工具,我们可以在上面查看集群的状态,包括集群整体运行状态、Mgr、Mon、OSD 和其他 Ceph 进程的状态,查看存储池和 PG 状态,以及显示守护进程的日志等。
部署集群的配置文件 cluster.yaml ,默认已经开启了 Dashboard 功能,Rook Ceph operator 部署集群时将启用 ceph-mgr 的 Dashboard 模块。
9.1 获取 Dashboard 的 service 地址
$ kubectl -n rook-ceph get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-exporter ClusterIP 10.233.4.126 <none> 9926/TCP 46m
rook-ceph-mgr ClusterIP 10.233.49.41 <none> 9283/TCP 46m
rook-ceph-mgr-dashboard ClusterIP 10.233.7.182 <none> 8443/TCP 46m
rook-ceph-mon-a ClusterIP 10.233.45.222 <none> 6789/TCP,3300/TCP 47m
rook-ceph-mon-b ClusterIP 10.233.52.144 <none> 6789/TCP,3300/TCP 47m
rook-ceph-mon-c ClusterIP 10.233.57.144 <none> 6789/TCP,3300/TCP 47m
9.2 配置在集群外部访问 Dashboard
通常我们需要在 K8s 集群外部访问 Ceph Dashboard,可以通过 NodePort 或是 Ingress 的方式。
本文演示 NodePort 方式。
- 创建资源清单文件,
vi ceph-dashboard-external-https.yaml
apiVersion: v1
kind: Service
metadata:
name: rook-ceph-mgr-dashboard-external-https
namespace: rook-ceph
labels:
app: rook-ceph-mgr
rook_cluster: rook-ceph
spec:
ports:
- name: dashboard
port: 8443
protocol: TCP
targetPort: 8443
nodePort: 31443
selector:
app: rook-ceph-mgr
mgr_role: active
rook_cluster: rook-ceph
type: NodePort
- 创建资源
kubectl create -f ceph-dashboard-external-https.yaml
- 验证创建的资源
$ kubectl -n rook-ceph get service rook-ceph-mgr-dashboard-external-https
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr-dashboard-external-https NodePort 10.233.5.136 <none> 8443:31443/TCP 5s
9.3 获取 Login Credentials
登陆 Dashboard 时需要身份验证,Rook 创建了一个默认用户,用户名 admin。创建了一个名为 rook-ceph-dashboard-password 的 secret 存储密码,使用下面的命令获取随机生成的密码。
$ kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
6W6#Y3PvI~=CVq0f'@Yo
9.4 通过浏览器打开 Dashboard
访问 K8s 集群中任意节点的 IP,https://192.168.9.91:31443,默认用户名 admin,密码通过上面的命令获取。

9.5 Ceph Dashboard 概览
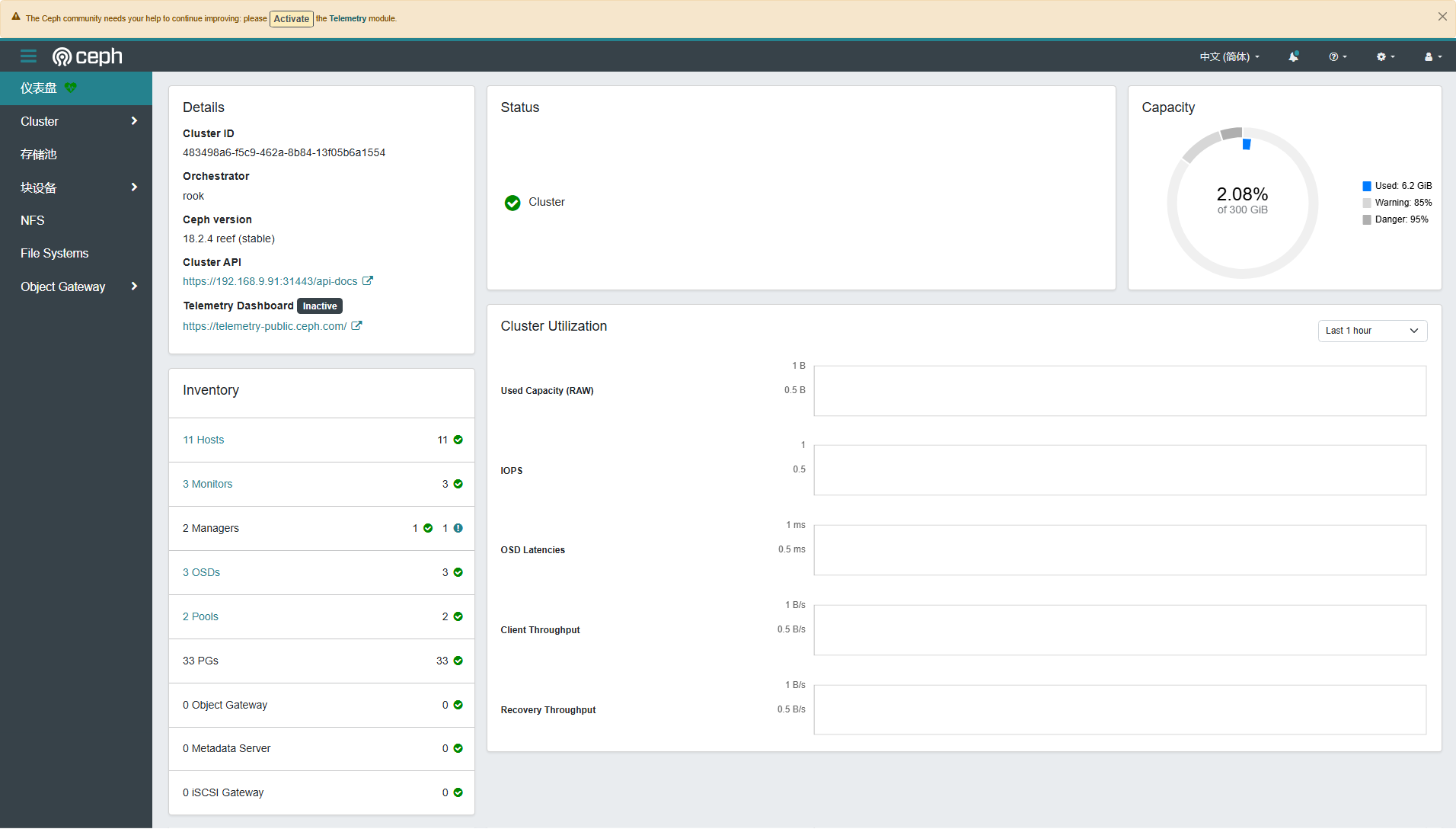
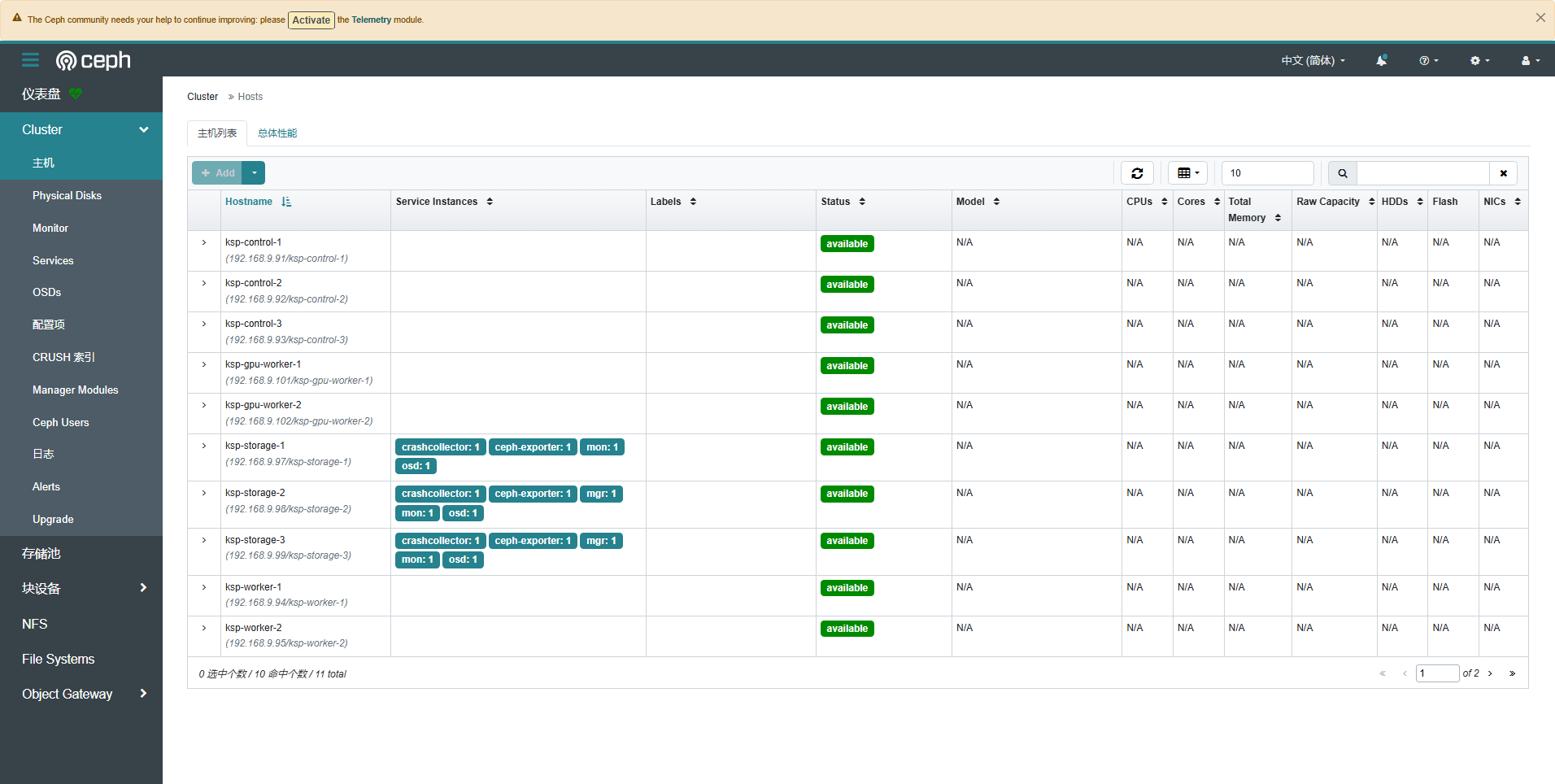
Ceph Dashboard 虽然界面简单,但是常用的管理功能都具备,能实现图形化管理存储资源。下面展示几张截图,作为本文的结尾。
- Dashboard
- 集群-主机
- 集群-OSD

- 存储池

免责声明:
- 笔者水平有限,尽管经过多次验证和检查,尽力确保内容的准确性,但仍可能存在疏漏之处。敬请业界专家大佬不吝指教。
- 本文所述内容仅通过实战环境验证测试,读者可学习、借鉴,但严禁直接用于生产环境。由此引发的任何问题,作者概不负责!
本文由博客一文多发平台 OpenWrite 发布!