CAE如何基于CPU最佳核数和token等计算成本
简介
以经济高效的方式确定用于 CAE 仿真的高性能计算集群规模
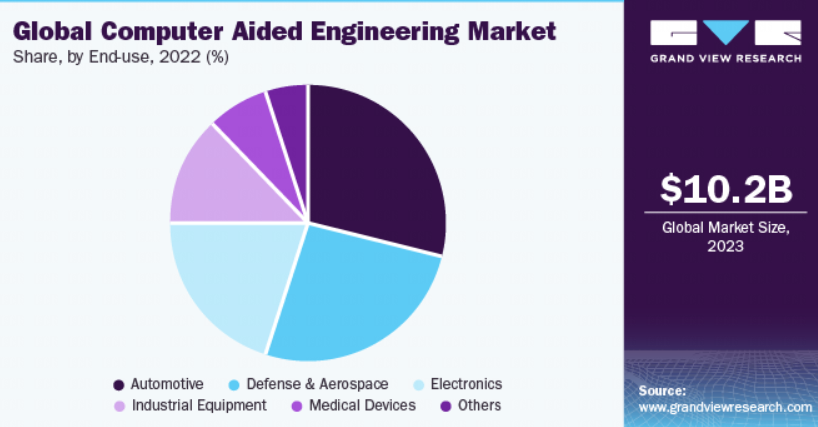
计算机辅助工程(CAE Computer aided engineering)是产品开发中非常重要的一部分,尤其是在汽车、国防军工航天、工业装备和电子电气和医疗设备行业。每个CAE部门的核心都有一个计算集群,主要用于运行有限元求解器,以模拟汽车碰撞、安全气囊充气、跌落和更多物理过程。几乎所有CAE仿真器软件供应商都使用不同的许可证模式。特别是每种求解器的token缩放公式(token数量与所用 CPU 内核的函数关系)都是独一无二的。
我们提出了一种推导单次求解器运行总成本的方法,并提出了提高中小型CAE集群效率的可能性。我们并不推导一般指令,而是展示了如何利用对许可证模型、求解器行为和硬件选项的专门分析来最大限度地提高效率。
汽车行业中的典型集群装置从50到200个内核的本地资源到过万内核的集中式云计算装置不等。然而,一般来说,对高性能计算系统的要求要高于可用的计算能力。这既有经济方面的原因(许可证的限制),也有基础设施方面的原因(数据中心的冷却设施和空间有限)。因此,为了实现最高的计算效率,必须优化批量操作中的计算时间表。
GNS Systems是一家专门应对此类挑战的 IT 服务公司。在本文中,我们将举例说明如何通过对客户提供的情况进行详细、科学的分析来提高效率。
-
首先,我们利用现代英特尔至强E5处理器的基准测试结果,研究了各种CAE软件的性能如何取决于所使用的CPU内核数量以及 CPU内核绑定的细节。我们可以清楚地观察到涡轮频率的积极影响。
-
其次,我们得出了模拟成本(包括硬件、软件和人员成本)的一般公式。我们表明,在汽车行业普通商业用户的典型情况下,往往存在一个 CPU 内核的 "甜蜜点"。我们将 "最佳点 "定义为 CPU 内核数(1 个以内),它能使模拟的总成本最小化。
-
最后,我们还讨论了典型行业用户可能采用的技巧(如硬件负载不足),以便在保持集群总容量不变的情况下降低仿真总成本。
理论考虑和公式推导
决定总成本的主要因素有三个。它们是
-
- 许可证成本
-
- 硬件成本 -
-
- 附加因素,如人员成本、等待求解器作业完成的一般成本或因项目延迟而产生的成本
许可证成本
每个软件都有自己的许可证模式。我们将以 LS-Dyna、Abaqus 和 Ansys 求解器为例。
通常情况下,集群作业需要一定数量的token,token数量仅根据使用的内核数量计算。此外,一些软件供应商还提供不同种类的token,这些token可以组合起来进行多核计算。例如,Ansys 提供 "anshpc "和 "pack "许可证。

表 1:不同 CAE 求解器的token缩放和年度成本概览。
图1显示了每个求解器所需的token数量与所用内核数量的函数关系。对于 Abaqus 和 Dyna,相对token成本与token数量相同。对于有不同token类型的 Ansys,我们考虑了相对成本,以提供合理的缩放行为。
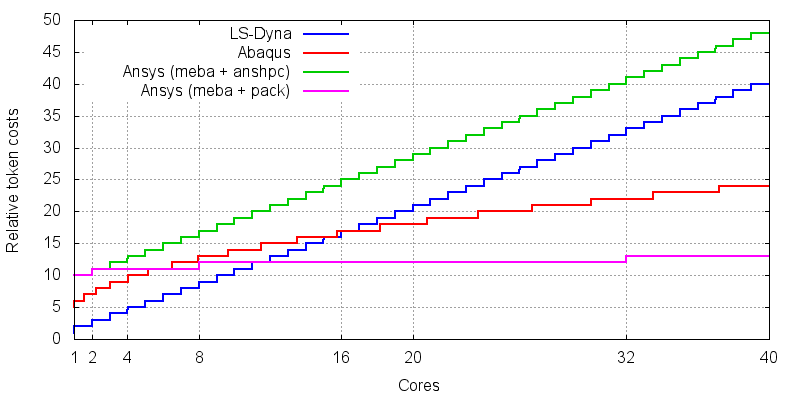
Dyna 和 Abaqus 不需要考虑不同token的绝对成本。只有在 Ansys 有不同token类型的情况下,我们才会考虑相对成本。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
- 如需英文原版可联系微信pythontesting
硬件成本
CAE工作通常在企业机架服务器上运行。硬件种类繁多,尤其是CPU。在这项工作中,我们选择了一个典型的服务器设置来估算成本。请注意,这些成本可能至少相差2倍。

表2:中小型 CAE 集群单机典型硬件成本概览。
其他因素
除上述成本外,还有一些更难估算的额外成本,如人员成本。在工程师提交作业并继续其他工作的情况下,几乎不会产生额外成本。但是,假设工程师在等待关键结果,在工作运行期间不能做有用的工作,我们就必须增加一个很大的成本因素。
另一种成本一般很难估算,但在决定是否使用集群时也不应忽视,那就是运行成本(主要是数据中心的电费和空间费)。
因此,我们不会从量化的角度考虑这类成本,但我们要强调的是,为了进行有意义的总成本分析,必须将这些成本考虑在内。
得出通用成本公式 在本节中,我们将使用以下缩写:
- n: 作业使用的内核数
- c: 作业总成本
- cl:许可证成本
- ch: 硬件成本
- l(n): n个内核的许可成本
- h:硬件成本
- t: 作业的运行时间(秒)
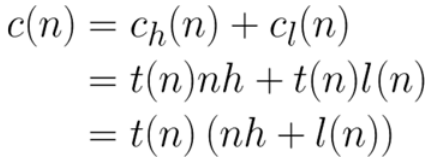
数量 t(n) 描述了求解器本身的缩放行为。由于并行计算是一个非常复杂的领域,因此无法在此给出精确公式。因此,我们使用实验结果来获取所需的信息。
实验基准结果
我们将展示有关典型 CAE 作业扩展行为的实验结果。所有测试均使用较新的企业机架服务器进行。不过,由于CAE机器的访问权限有限,我们无法在所有测试中使用相同的硬件。尽管如此,测试结果仍可用于提取定性结果。
为了获得有意义的比较数据,我们引入了"token小时数"(TH Token Hours)。代币小时 "是指某项任务占用代币的总时间。TH 的定义如下:
TH = 使用的token数(T)×作业运行时间(小时)(H)
TH = Number of used tokens (T) × Runtime of the job in hours (H)
T 和 H 都取决于所使用的 CPU 内核数。T(H) 可使用表1中的公式计算:。H(n) 是根据实验结果得出的。
在本节的基准测试中,我们对每个求解器使用了一个(任意的)测试作业。显然,不同类型的作业具有不同的缩放行为。例如,我们预计显式作业和隐式作业之间会有很大差异。我们要指出的是,我们在这里展示的结果并不是普遍有效的,而是作为如何评估求解器运行成本的示例。在本工作的最后,我们将展示如何利用这些示例优化性能。我们的目的是演示方法,而不是给出详细的通用说明。
LS-Dyna
本节所示基准测试在英特尔至强 E5-2690 v2 CPU 上进行。
图 显示了简单 LS-Dyna 测试作业的 TH(n)(霓虹灯根据 [TopCrunch] 修订)。结果显示,随着CPU 数量(n)的增加,TH 大致呈线性增长。只有在 2 核和 4 核之间,token时间是相同的。

Abaqus
本节所示基准测试在英特尔至强 E5-2690 v2 CPU 上进行。
图3:显示了简单的 Abaqus 显式测试作业 (e1) 的 TH(n)。
在一到四个内核之间,TH 下降很快。超过四个内核时,TH 会缓慢单调下降。
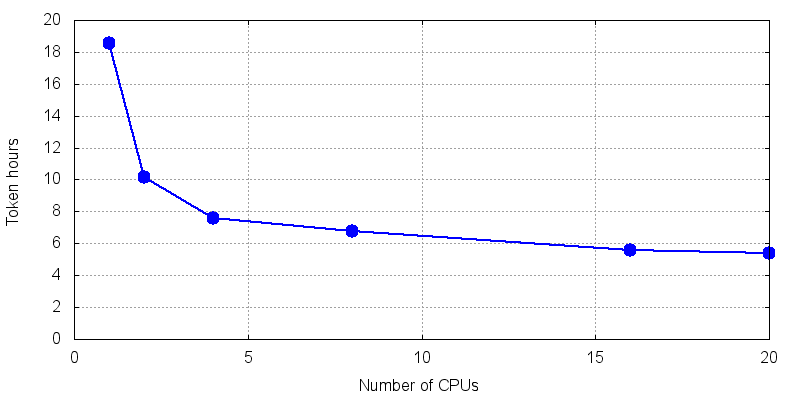
Abaqus 测试作业的token小时数(TH)与 CPU 内核数(n)的关系。随着 CPU 数量的增加,TH 明显下降。
Ansys
本节所示基准测试在英特尔至强 E5-2667 v2 CPU 上进行。
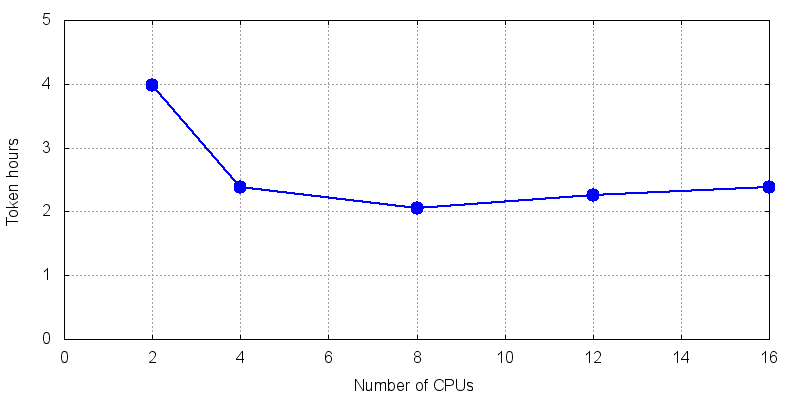
图4显示了 Ansys 测试作业的 TH(n)。对于多达四个 CPU 内核,TH 下降速度非常快。在 8 个 CPU 内核左右出现一个不明显的最小值。曲线在 4 至 16 个内核之间大致持平。
总成本分析
我们将前面显示的所有数据和理论考虑因素相加。这意味着我们将使用公式 (1) 计算给定测试作业的总成本。该计算结合了硬件和许可证成本(见表 1:和表 2:)以及相应求解器的 CPU 内核缩放。
图 5 显示了 LS-Dyna 测试作业的结果,图 6 显示了 Abaqus 测试作业的结果,最后,图 7 显示了 Ansys 测试作业的结果。
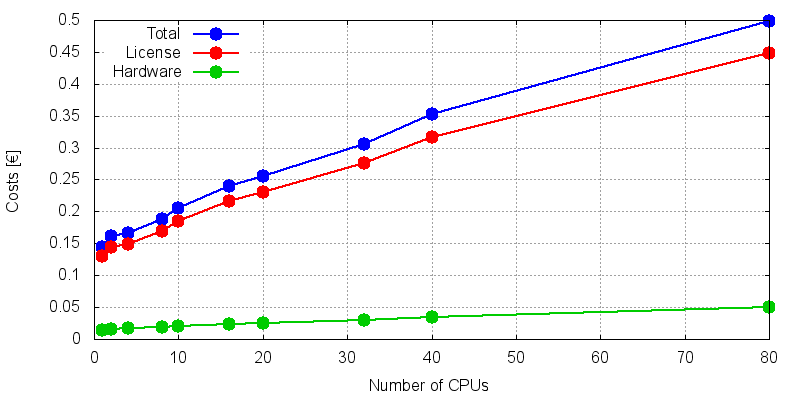
图 5:LS-Dyna 测试作业的成本与所用 CPU 内核的函数关系。
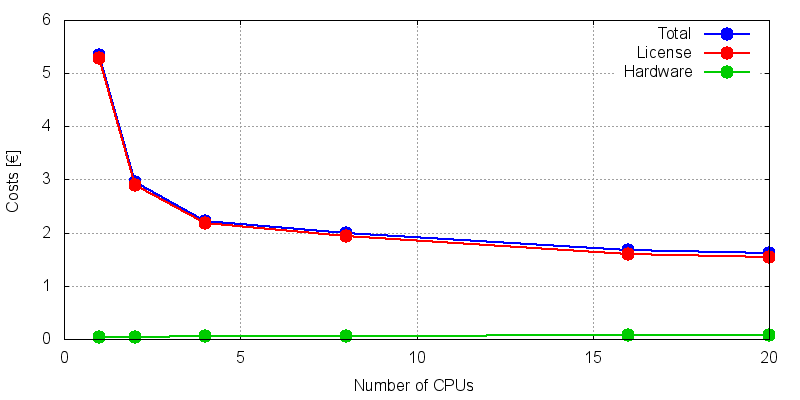
图 6:作为所用 CPU 内核函数的 Abaqus 测试作业成本。

图 7:所用 CPU 内核与 Ansys 测试作业成本的函数关系。
最大化性能的方法
本节将介绍如何使用给定数据最大化给定作业的效率。
总体考虑
首先,本节中的所有数据都有一个明显的共同特征:硬件成本明显低于许可证成本,这对于任何希望提高仿真成本效率的人来说都是至关重要的。这两项成本相差大约十倍。这意味着 CAE 批量作业的总成本主要取决于许可证成本。因此,避免硬件短缺导致许可证闲置至关重要。另一方面,如果能提高许可证的使用效率,那么拥有一些闲置硬件往往是很小的代价。
其次,尽管硬件成本可以忽略不计,但购买最适合所用求解器的 CPU 仍有可能提高 CAE 集群的整体性能,因为合适的 CPU 可以最大限度地提高许可证效率。
- LS-Dyna
图5显示了总成本与用于 LS-Dyna 测试作业所使用的 CPU 内核数的函数关系。CPU 内核数量的增加总是会导致总成本的增加。
这意味着,一方面,只有在其他因素(如作业完成前的等待时间成本)起作用的情况下,使用一个以上的 CPU 才是合理的。另一方面,CPU 的单核时钟频率必须很高。由于每个额外内核的使用都会大大增加成本,因此我们希望一个内核的功率越大越好。
- Abaqus
图 6:显示了总成本与用于 Abaqus 测试作业的 CPU 内核数的函数关系。增加 CPU 内核数量总能降低测试作业的总成本。这意味着最好使用尽可能多的 CPU 内核。此外,我们还希望在一台服务器中包含尽可能多的计算能力,以降低总成本。也就是说,硬硬盘、机箱等由一台服务器中的所有 CPU 内核共享。因此,最佳选择是具有 10 个或更多内核、时钟频率相对较低但整体性能较高的 CPU。
- Ansys
图7显示了总成本与 Ansys 测试作业所用 CPU 内核数的函数关系。总成本在 2 到 4 个内核之间迅速下降,在 8 个内核左右出现一个不明显的最小值,随着内核数的增加而缓慢上升。由于许可证模型较为复杂,结论包含了不同的方面。首先,每个 Ansys 作业都需要一个相对昂贵的通用token(例如 "meba")。为了使用多个 CPU 内核,Ansys 提供了不同的可能性。这里我们选择了两种不同的模式。第一种是 "anshpc "token,第二种是 "pack "token(详见表 1)。如果使用 "anshpc "标记,情况与 Abaqus 所描述的情况相同。但是,如果使用 "pack "token,则需要 CPU 包含 8 个内核的倍数。原因是一个 "包 "token最多可用于八个 CPU 内核。如果 CPU 包含十个内核,则有两个内核未使用,或者必须使用额外的token。这两种情况的效率都很低。如果有两个 "包 "token,单个作业最多可使用 32 个内核。同样,拥有 8 个内核倍数的 CPU 可提供最高效率。
利用硬件欠载最大限度地提高成本效益
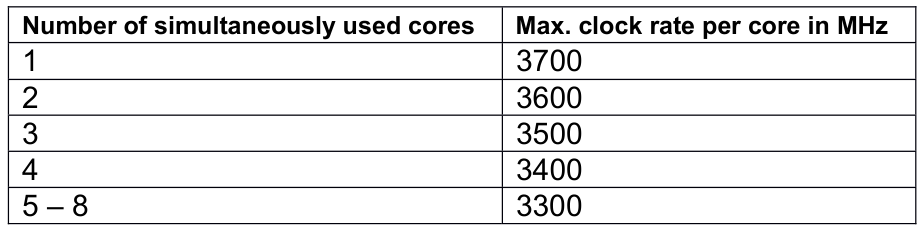
所有现代服务器中央处理器都会在不足全部内核同时工作时提高时钟频率。例如,英特尔至强 E5-2667v2 CPU 的涡轮频率步骤如表 3 所示。
由于硬件成本相对较低,因此有机会只使用每个 CPU 的部分容量。这样就可以提高每个所用内核的时钟频率。
通常情况下,批处理作业会同时使用计算服务器的所有 CPU 内核。不过,由于 LS-Dyna 等一些 CAE 求解器受益于较高的单核时钟频率,因此值得考虑使用低于全部容量的CPU核数。
在图8所示的示例中,我们使用了一台配备两个英特尔至强 E5-2667v2 CPU 的戴尔 PowerEdge 服务器。每个 CPU 由 8 个内核组成,因此总共有 16 个内核。图 8:显示了两种不同使用模式下的总成本。蓝线表示在始终满负荷(即使用所有 CPU 内核)的机器上运行每个作业时的结果。红线表示作业只在一台机器上运行时的结果。由于硬件成本与内核数量无关,因此在使用较少内核时,总成本相对较高。16 个内核的两点差异仅在统计偏差范围内。
使用独占机器的优势在于,由于涡轮频率较高,测试作业的总运行时间大大缩短。考虑到使用 8 个内核运行作业的成本,虽然独占运行作业的硬件成本要高出一倍,但成本几乎相等。
事实上,使用该特定测试作业时,我们无法通过硬件减载来降低总成本。
不过,两者之间的差距非常小。很有可能,对于某些作业来说,硬件减载确实可以通过降低单个 CAE 作业的总成本来提高效率。

图8使用两种不同利用率模型的 CAE 作业总成本。红线显示的是只在一台机器上运行的作业的成本,而蓝线显示的是完全满载的机器上的作业的成本。16 个内核的两个点仅在统计偏差范围内存在差异,因此应视为相等。
除了更高的涡轮频率外,我们还预计内存性能会在 CPU 未完全加载的情况下有所提高,这归功于现代服务器 CPU 的 NUMA 架构。特别是对于通常对内存要求较高的隐式工作,可能值得考虑硬件欠载问题。
小结
我们利用直接的理论考虑,结合 CAE 求解器工作的基准,得出了单次 CAE 求解器运行的总成本。我们选择了三个典型的 CAE 求解器(LS-Dyna、Abaqus 和 Ansys),介绍了如何最大化中小型 CAE 集群效率的方法。最重要的结果如下
- 许可证成本比硬件成本高出大约十倍 - 使用与所使用求解器的许可证模型非常匹配的 CPU 可以提高效率。
- 在某些条件下,硬件负载不足也是提高效率的一个机会,值得针对具体工作进行研究。