系统设计(架构师)指南5设计一致哈希(HASHING)
5 设计一致哈希(HASHING)
要实现横向扩展,就必须在服务器之间高效、均匀地分配请求/数据。一致哈希是实现这一目标的常用技术。不过,首先让我们深入了解一下这个问题。
5.1 重散列(rehashing)问题
如果有n台缓存服务器,平衡负载的常用方法是使用下面的散列方法:
serverIndex = hash(key)%N,其中N是服务器池的大小。
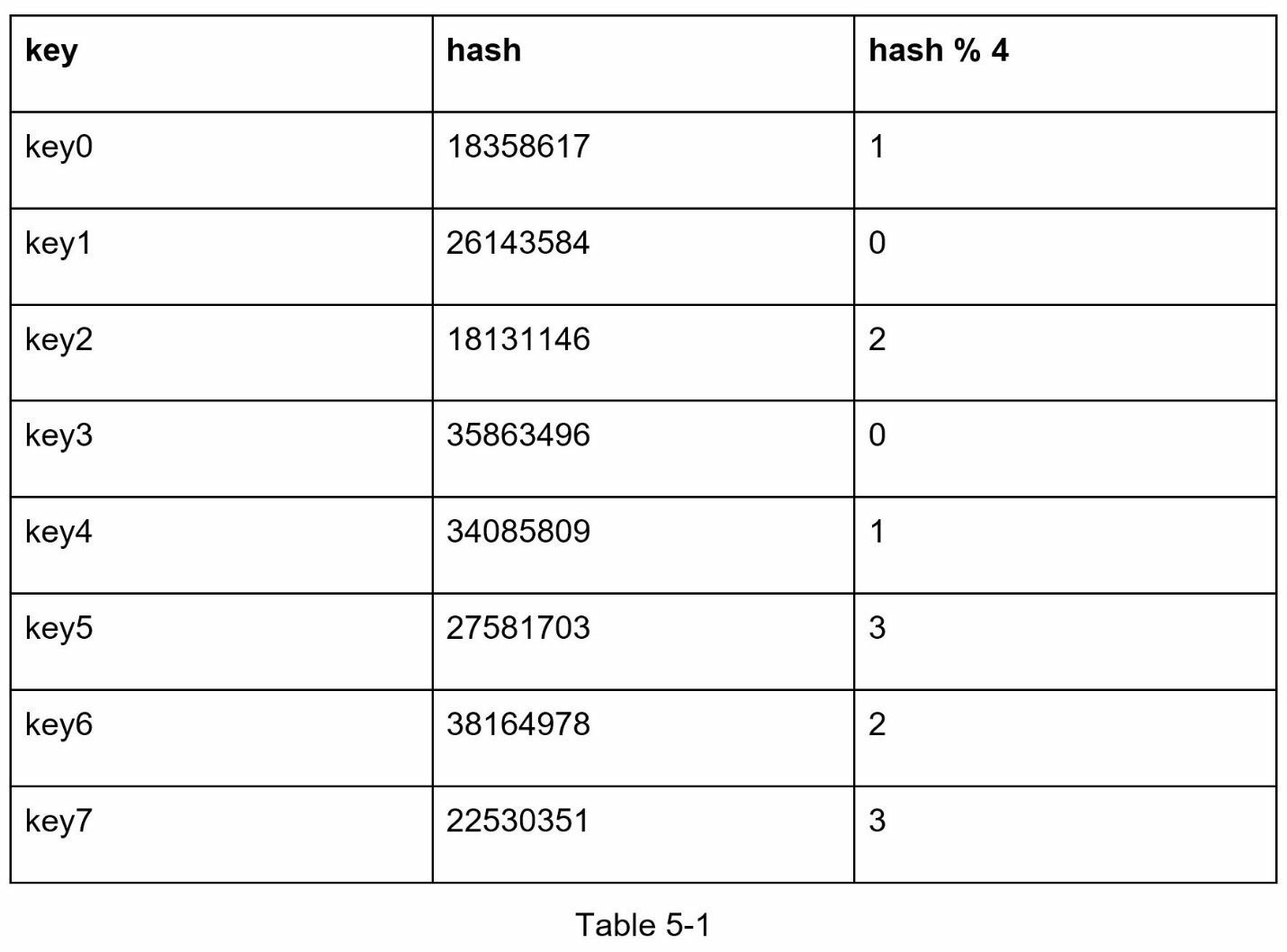
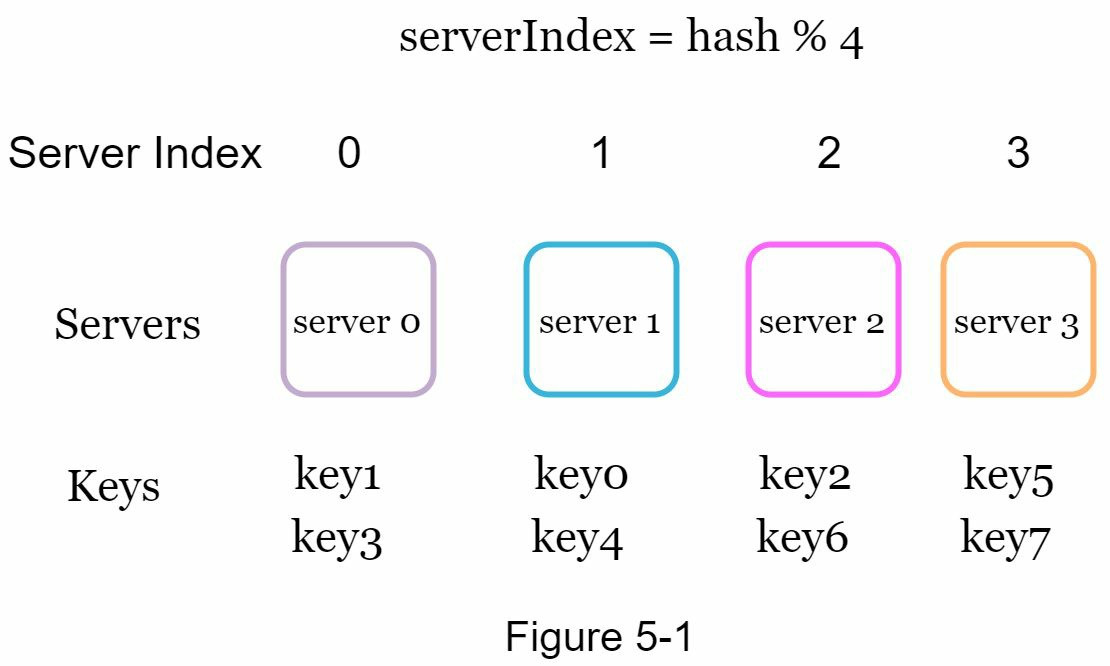
当服务器池的大小固定且数据分布均匀时,这种方法效果很好。但是,当添加新服务器或移除现有服务器时,问题就会出现。例如,如果服务器1离线,服务器池的大小就会变成3。这意味着当服务器1离线时,大多数缓存客户端会连接到错误的服务器来获取数据。这将导致缓存丢失风暴。一致性散列是缓解这一问题的有效技术。
5.2 一致散列(Consistent hashing)
引自维基百科:"一致散列是一种特殊的散列方式,当重新调整哈希表大小并使用一致散列时,平均只需重新映射 k/n 个键,其中k是键的个数,n是槽的个数。相比之下,在大多数传统哈希表中,数组槽数的变化会导致几乎所有的键都要重新映射"。
5.3 散列空间和散列环
既然我们已经理解了一致散列的定义,那就让我们来看看它是如何工作的。假设使用SHA-1作为散列函数f,散列函数的输出范围为:x0, x1, x2, x3, ..., xn。在密码学中,SHA-1 的散列空间从 0 到 2^160 - 1。也就是说,x0 对应 0,xn 对应 2^160 - 1,中间的所有其他散列值都在 0 和 2^160 - 1 之间。
5.4 散列服务器
使用相同的哈希函数f,我们根据服务器IP或名称将服务器映射到哈希环上。

5.5 散列键
值得一提的是,这里使用的哈希函数与 "重洗问题 "中的哈希函数不同,没有模块化操作。

5.6 服务器查询
要确定密钥存储在哪个服务器上,我们要从密钥在哈希环上的位置开始顺时针查找,直到找到服务器为止。下图解释了这一过程。按顺时针方向,0存放在服务器0上;1存放在服务器1上;2存放在服务器2上;3存放在服务器3上。

5.7 添加服务器
使用上述逻辑,添加新服务器只需重新分配一部分密钥。
添加新服务器 4后,只需重新分配0,而 k1、k2 和 k3 仍保存在相同的服务器上。让我们仔细看看其中的逻辑。在服务器4添加之前,0保存在服务器0上。现在,密钥0将被保存在服务器4上,因为服务器4是它从密钥0在环上的位置顺时针旋转遇到的第一个服务器。其他Key不会根据一致的哈希算法重新分配。

5.8 移除服务器
移除服务器时,只有一小部分Key需要使用一致散列算法重新分配。下图中,当服务器1被移除时,只有key1必须重新映射到服务器2。其余的密钥不受影响。

5.9 基本方法中的两个问题
一致散列算法是由麻省理工学院的Karger等人提出的。基本步骤如下
-
使用均匀分布的散列函数将服务器和密钥映射到环上。
-
要找出密钥映射到哪个服务器上,就从密钥位置开始顺时针查找,直到找到环上的第一个服务器为止。
这种方法存在两个问题。首先,考虑到服务器可以添加或删除,环上所有服务器的分区大小不可能保持一致。分区是相邻服务器之间的散列空间。分配给每个服务器的环上分区的大小有可能非常小,也有可能相当大。下图如果删除 s1,s2 的分区(双向箭头突出显示)将是 s0 和 s3 分区的两倍。

其次,环上有可能出现密钥分布不均匀的情况。例如,如果将服务器映射到下图所列的位置,则大部分密钥都存储在服务器 2 上。然而,服务器 1 和服务器 3 却没有数据。

一种称为虚拟节点或副本的技术可用于解决这些问题。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
- 一致散列:https://en.wikipedia.org/wiki/Consistent_hashing
- 一致散列:
https://tom-e-white.com/2007/11/consistent-hashing.html - Dynamo: 亚马逊的高可用键值存储:
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf - Cassandra - 一种分散的结构化存储系统:
http://www.cs.cornell.edu/Projects/ladis2009/papers/Lakshman-ladis2009.PDF - Discord 如何将 Elixir 扩展到 5,000,000 并发用户:
https://blog.discord.com/scaling-elixir-f9b8e1e7c29b - CS168: 现代算法工具箱讲座 #1:导论和一致性
哈希算法:http://theory.stanford.edu/~tim/s16/l/l1.pdf - Maglev: A Fast and Reliable Software Network Load Balancer:
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/44824.pdf
5.10 虚拟节点
虚拟节点指的是真实节点,每个服务器都由环上的多个虚拟节点表示。下图中,服务器 0 和服务器 1 都有 3 个虚拟节点。3 是任意选择的;而在实际系统中,虚拟节点的数量要大得多。我们不用 s0,而是用 s0_0、s0_1 和 s0_2 来表示环上的服务器 0。同样,s1_0、s1_1 和 s1_2 代表环上的服务器 1。通过虚拟节点,每个服务器负责多个分区。标签为 s0 的分区(边)由服务器 0 管理,而标签为 s1 的分区则由服务器 1 管理。

要查找密钥存储在哪台服务器上,我们可以从密钥所在位置出发,顺时针方向查找环上遇到的第一个虚拟节点。下图,要找出 k0 存放在哪个服务器上,我们从 k0 所在位置开始顺时针方向查找虚拟节点 s1_1,它指的是服务器 1。

随着虚拟节点数量的增加,密钥的分布也变得更加均衡。这是因为虚拟节点越多,标准偏差就越小,从而导致数据分布均衡。标准偏差衡量数据的分布情况。在线研究[2]的实验结果表明,在有一两百个虚拟节点的情况下,标准偏差介于平均值的 5%(200 个虚拟节点)和 10%(100 个虚拟节点)之间。当我们增加虚拟节点的数量时,标准偏差会更小。但是,需要更多空间来存储虚拟节点的数据。这是一个权衡问题,我们可以根据系统要求调整虚拟节点的数量。
5.11 找受影响的键
添加或删除服务器时,需要重新分配一部分数据。我们如何找到受影响的范围来重新分配密钥呢?
下图中,服务器 4 被添加到环上。受影响的范围从 s4(新添加的节点)开始,围绕环逆时针移动,直到找到一个服务器(s3)。因此,位于 s3 和 s4 之间的密钥需要重新分配到 s4。
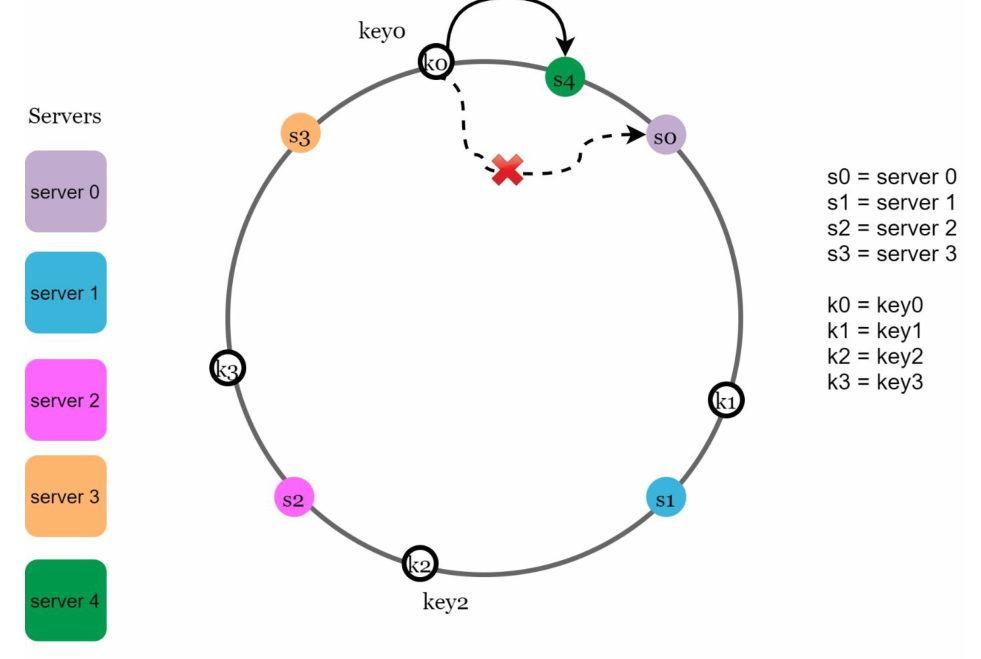
下图当服务器(s1)被移除时,受影响的范围从 s1(被移除的节点)开始,围绕环路逆时针移动,直到找到服务器(s0)为止。因此,位于 s0 和 s1 之间的密钥必须重新分配到 s2。

5.12 总结
在本章中,我们深入讨论了一致散列,包括为什么需要一致散列以及一致散列的工作原理。一致散列的好处包括
- 当服务器添加或删除时,最小化的密钥会重新分配。
- 由于数据分布更均匀,因此易于横向扩展。
- 缓解热点密钥问题。对特定分片的过度访问可能会导致服务器过载。想象一下,凯蒂-佩里、贾斯汀-比伯和 Lady Gaga 的数据最终都在同一个分片上。一致散列法通过更均匀地分配数据,有助于缓解这一问题。
一致散列在现实世界的系统中得到了广泛应用,其中包括一些著名的系统:
- 亚马逊Dynamo数据库的分区组件。
- Apache Cassandra 中跨集群的数据分区。
- Discord 聊天应用程序
- Akamai 内容交付网络
- Maglev 网络负载平衡器