[vue3] vue3更新组件流程与diff算法
在Vue3中,组件的更新通过patch函数进行处理。
patch函数
源码位置:core/packages/runtime-core/src/renderer.ts at main · vuejs/core (github.com)
const patch: PatchFn = (
n1,
n2,
container,
anchor = null,
parentComponent = null,
parentSuspense = null,
namespace = undefined,
slotScopeIds = null,
optimized = __DEV__ && isHmrUpdating ? false : !!n2.dynamicChildren,
) => {
// 二者相同,不需要更新
if (n1 === n2) {
return
}
// vnode类型不同,直接卸载旧节点
if (n1 && !isSameVNodeType(n1, n2)) {
anchor = getNextHostNode(n1)
unmount(n1, parentComponent, parentSuspense, true)
n1 = null
}
// ......
const { type, ref, shapeFlag } = n2
switch (type) {
case Text:
// 处理文字节点
break
case Comment:
// 处理注释节点
break
case Static:
// 静态节点
break
case Fragment:
// Fragment节点
break
default:
if (shapeFlag & ShapeFlags.ELEMENT) {
// 处理普通DOM元素
} else if (shapeFlag & ShapeFlags.COMPONENT) {
// 处理组件
} else if (shapeFlag & ShapeFlags.TELEPORT) {
// 处理teleport
} else if (__FEATURE_SUSPENSE__ && shapeFlag & ShapeFlags.SUSPENSE) {
// 处理suspense
} else if (__DEV__) {
// 报错:vnode类型不在可识别范围内
warn('Invalid VNode type:', type, `(${typeof type})`)
}
}
}
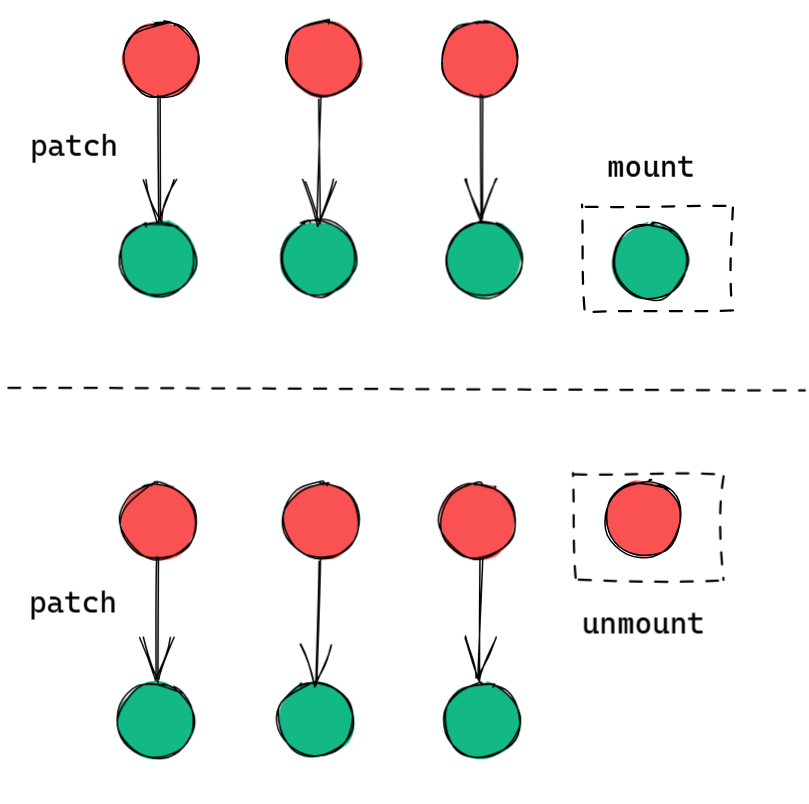
patch函数用来挂载或者更新vnode。
patch的大致流程:
n1和n2如果相等,则表示无变化,直接退出;n1和n2如果引用不同,则先检查其vnode类型,如果类型不同,则直接卸载n1,挂载n2;- 主流程:根据
n1和n2的vnode类型,调用不同的process函数。
process
process函数的参数列表大致相同,都是要传入n1、n2和container等参数。patch函数主要起到一个分类讨论的功能。
这里只讨论普通元素类型和组件类型的vnode处理过程,因为这是Vue应用中最常见、覆盖范围最广的两种类型。
普通元素类型,即
ShapeFlags.ELEMENT,在浏览器环境下就是指DOM类型。
普通元素vs组件
从组件树的角度来理解普通元素和组件元素的区别。

一个组件的children可以是普通元素或组件元素。
-
叶子节点必须是普通元素,因为只有普通元素能够通过相关平台挂载到界面上。
Vue会在编译时确定mount方法,以适应不同的平台。对于浏览器环境来说,普通元素是通过vnode来表示DOM节点,将vnode转换成实际DOM元素并插入到页面上的操作由vue3源码中的runtime-dom这个package实现。叶子节点必须是普通元素,但是普通元素不一定是叶子节点,比如一个
div标签内部可以包含其它组件。 -
叶子节点不可能是组件,因为组件必须被实现且被注册,其实现必须使用已注册的组件或者普通元素。并且组件是虚拟元素,并不能被实际挂载到指定平台上,只能递归地
patch它的children,直到把普通元素都挂载到界面上。
在 Vue3 - patch 函数的源码中可以看到除了这两种类型,还有很多针对其它类型 vnode 的 process 函数,这些 process 函数主要做的只有两件事:挂载和更新。
对于旧vnode n1 和 新vnode n2:
- 当
n1是null时,则表示挂载n2; - 当
n1不为null时,则表示n1更新为n2;
patchElement
patchElement 会对它的 children 也进行 patch,也就是调用 patchChildren 函数。
children 有三种情况:文本、数组、NULL。

diff算法
diff 算法用于将旧children的vnode数组更新为新children的vnode数组,它通过比较两个序列,尽可能地复用相同的vnode,以此来减少频繁创建vnode带来的开销。
事实上,diff 是在 patchKeyedChildren 中实现的,对于没有设置 key 的数组,patchChildren函数内部调用的是 patchUnkeyedChildren,函数实现大致如下:
- 计算两个数组的长度的最小值
commonLength;- 前
commonLength个 vnode 直接 patch 更新,不会考虑移动到不同位置来复用;- 旧序列如果有剩余则unmount,新序列如果有多余则mount。
这种做法在大多数情况下都会需要创建 vnode,开销还是比较大的。因此为了提高渲染性能,使用渲染列表的时候要写上 key。
vue3 的 diff算法实现在patchKeyedChildren函数中,主要包含五个流程,其中第五个是最复杂的步骤:
-
两个序列从头部向尾部依次同步,直到不能匹配进入下个流程;
起始索引都是从0开始,用一个变量
i就可以了。
-
两个序列从尾部向头部依次同步,直到不能匹配进入下个流程;
两个序列长度可能不一样,最后一个元素的索引不一样,因此需要两个变量
e1和e2来指向ending index。
在上述两个流程之后:
-
如果旧序列遍历完了,而新序列还有剩余,则新序列剩余的vnode依次mount;
i>e1则表示旧序列遍历完了;i<=e2则表示新序列还有剩余;while(i<=e2){...; i++}把剩余的vnode都挂载。

-
如果新序列遍历完了,而旧序列还有剩余,则旧序列剩余的vnode依次unmount;
i>e2表示新序列都遍历完了;i<=e1表示旧序列还有剩余;while(i<=e1){ unmount(...); i++ }将剩余的旧 vnode 都卸载。

-
未知序列,尽可能地通过移动复用vnode,剩下的mount或者unmount。
头部和尾部都同步了若干vnode,但是两个序列都还没有遍历完成,说明中间有一段序列是混乱的、难以匹配的。

在步骤5中,有细分为多个子步骤:
首先用
s1和s2表示旧新序列的起始索引:const s1 = s2 = i;5.1. 遍历新序列,使用
Map建立key到newIndex的映射:keyToNewIndexMap;使用
Map的原因是PropertyKey这个类型是联合类型string | number | symbol,不能简单的用对象或数组表示。建立 key 到 index 的映射,是为了后续我们可以通过旧序列中的 key 来建立可复用情况下新旧节点之间的映射关系。
// 这段代码不是源码,只保留主干。 const keyToNewIndexMap: Map<PropertyKey, number> = new Map() for (i = s2; i <= e2; i++) { const nextChild = c2[i]; // c2 即 children2 if (nextChild.key != null) keyToNewIndexMap.set(nextChild.key, i) } }5.2. 遍历旧序列,使用一个
newIndexToOldIndexMap数组建立新旧序列中可复用节点的位置对应关系。newIndexToOldIndexMap的作用:
通过这个数组,我们可以知道一个新vnode可以由哪个旧vnode更新得到。在这个数组中,newIndex是以 0 开始的,而 oldIndex 是以 1 开始的,这是为了把
oldIndex==0作为一个特殊标识,表示新节点在旧序列中不存在。当newIndexToOldIndexMap[k] = 0,则表示新序列中第 k 个vnode在旧序列中不存在,无法复用。
newIndexToOldIndexMap的构建过程:
遍历旧序列
c1:for(let i=s1; i<=e1; i++){...}-
使用
keyToNewIndexMap查询c1[i]的 key:-
如果 key 为 undefined,则说明这个旧的 vnode 在新序列中不存在了,卸载这个旧 vnode;
-
如果 key 为某个数字,则表明这个旧 vnode 在新序列中有 vnode 的 key 跟它一样,可以复用。使用
patch函数将旧节点更新为新节点。这一步骤中记录新旧序列索引映射的代码是
newIndexToOldIndexMap[newIndex - s2] = i + 1。- 减去
s2是因为序列包含 diff 算法步骤1同步的头节点; i+1是因为这个数组记录的 oldIndex 是从 1 开始的。
- 减去
-
-
如果发现新序列中的节点都找到与之对应的旧节点了,那么
for循环后续的旧节点都直接卸载。
在这个步骤中,还通过一个
moved变量来记录节点的相对位置是否被移动了:if (newIndex >= maxNewIndexSoFar) { maxNewIndexSoFar = newIndex } else { moved = true }如果当前新节点的索引
newIndex大于或等于此前遍历到的最大新节点索引maxNewIndexSoFar,那么当前节点在新列表中的顺序相对于旧列表来说是保持递增的。
-
5.3 移动与挂载
经过上面若干步骤,能复用的旧节点都通过 patch 将数据更新到新节点上了,不能复用的旧节点都被卸载了。
而新节点如果没有在旧序列中出现,则挂载;如果在旧序列中出现了,
-
如果
moved为 false,则表示(已经执行复用操作的)新节点的顺序和在旧序列中的相对顺序是一致的,这种情况无需处理; -
如果
moved为 true,则表示相对顺序不一致,需要移动 vnode。为了减少移动次数,这里应用了最长递增子序列算法,计算了数组
newIndexToOldIndexMap的最长递增子序列。从上图右边的子图中可以看出,递增子序列越长意味着相对顺序一致的子序列越长,那么需要移动的 vnode 就越少。
思考版图大致如下:
