袋鼠云产品功能更新报告08期|近百项全新功能和优化,你要的都在这里!
欢迎来到袋鼠云08期产品功能更新报告!在瞬息万变的市场环境中,我们深知客户的需求与期待,因此,我们及时推出袋鼠云最新产品更新及优化,包括数据治理中心、Hive SQL 性能优化、新插件等,助力企业在数字世界中勇往直前。
以下为袋鼠云产品功能更新报告08期内容,更多探索,请继续阅读。
离线开发平台
新增功能更新
1.支持对接 Inceptor 表权限的申请和审批
背景:客户使用的是平台的 web 层权限管控方案,期望 Inceptor 表也能支持 web 层权限管控。
新增功能说明:
如图所示,当表权限通过后,用户则在离线中拥有审批通过后的 Inceptor 表权限。权限主要分为以下三点:
• DQL:主要是 select 语句,只读权限
• DML:主要是 insert update 语句,只写权限
• DDL:主要是 alter 语句,变更表记录

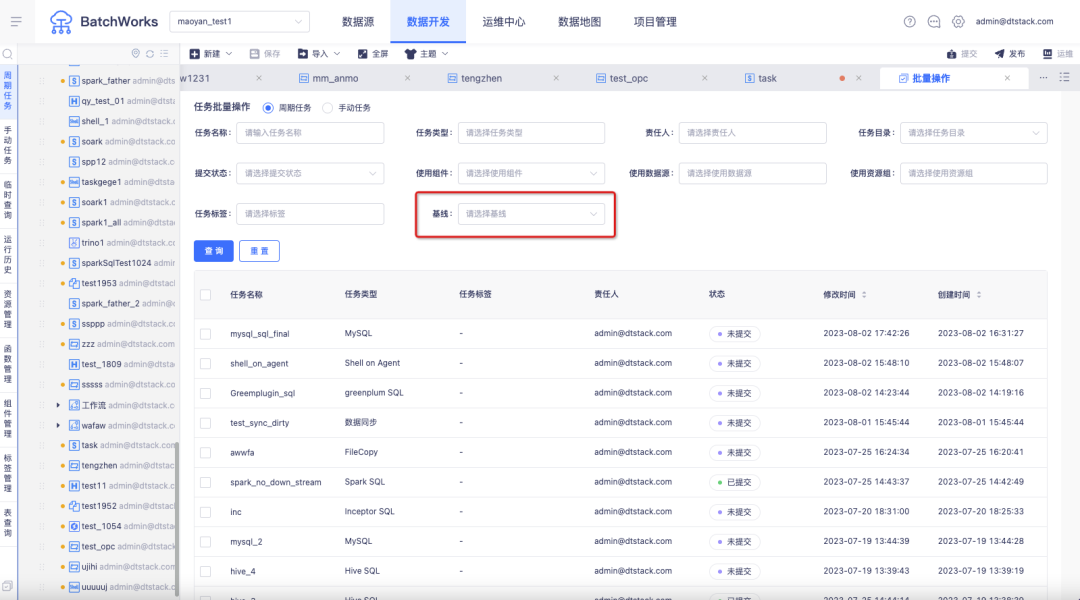
2.批量操作支持按基线进行任务的筛选
背景:客户希望在基线功能的基础上进行扩展,除了实现破线告警功能外,还希望能够支持批量设置资源租。这样,当某条基线出现错误时,可以更快地进行恢复。
新增功能说明:在批量操作处,增加基线筛选项。
3.任务优先级
背景:任务如果不出现异常(出错或延迟),集群资源一般是能够支持任务的正常运行,极少出现正常运行时的任务的大面积阻塞的情况。但如果任务依赖树比较复杂,上游几个重要任务出现异常且修复耗时长,会导致恢复后下游任务扎堆跑,那么就可能出现任务挤兑的情况,所以任务优先级的设置就显得尤为重要。
新增功能说明:支持在基线管理中对任务设置1-5个级别的优先级,数值越大,任务运行的优先级越高。优先级越高的任务,在调度资源紧张的情况下,将优先获得调度资源。
为基线设置优先级后,基线上所有任务及其有效上游任务自动赋予该优先级,配置优先级后将会在T+1生成的周期实例中生效。

4.任务发布对接审批中心
背景:部分客户对任务发布至生产项目的安全性要求较高,希望能够审批后再完成发布。
新增功能说明:开启发布审批流程后,在离线执行发布动作后,审批人需要先在审批中心进行审批后,发布流程才可继续进行。


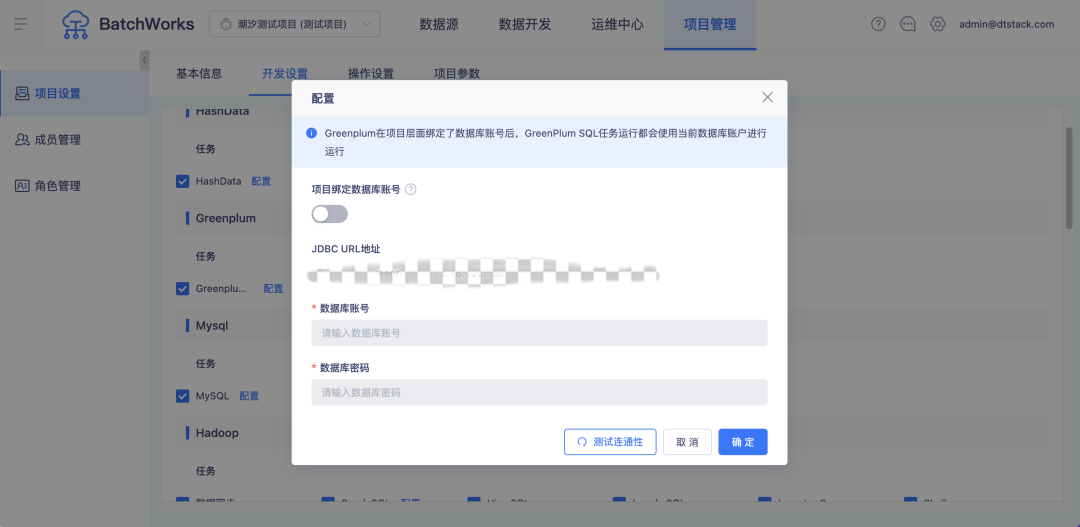
5.项目支持绑定数据库账号
背景:部分客户遇到这样的场景,不同的项目由不同的团队负责,对应的数据权限也不同,因此希望能够在项目维度进行数据库账号的绑定。
新增功能说明:RDB 类的数据库账号支持在项目中进行设置。在控制台还可设置集群、个人层面的数据库账号,这三者间的优先关系是个人>项目>集群。
功能优化
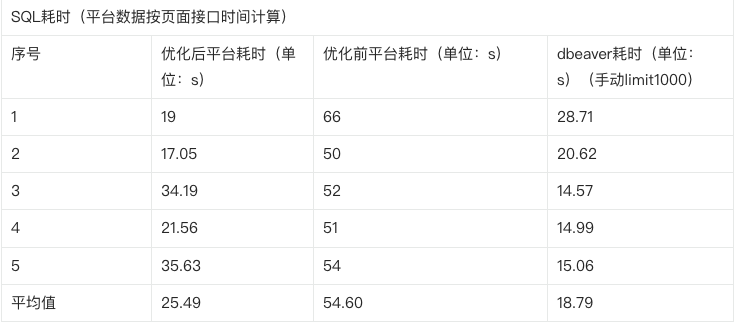
1.Hive SQL 性能优化
背景:在客户侧运行 Hive SQL 时,反馈 Hive SQL 任务执行较慢。
体验优化说明:性能优化后,简单查询的速率有显著提升,具体用例和时间对比如下:
• SELECT * FROM putong0629.dl_user WHERE id > 0;(表有18个字段,10w条数据)
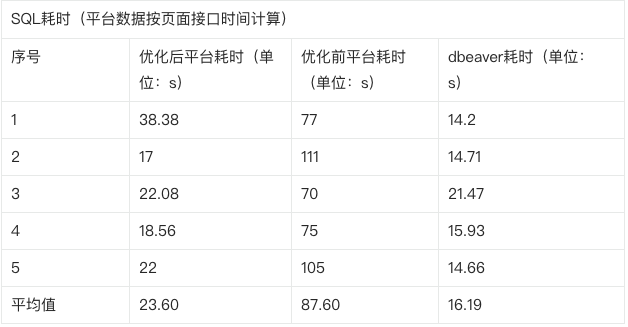
• SELECT * FROM putong0629.dl_user WHERE id is not null LIMIT 1;(表有18个字段,10w条数据)
2.SQL 编辑器格式化优化,且支持回撤
• ctrl+Z/command+Z 进行格式化内容回撤
• 格式化后格式参考竞品和其他开源代码编辑器格式化方式进行了优化调整

3.日志实时打印优化
背景:间隔2.5s轮询任务日志,任务结束后未再继续轮询日志,会导致丢失日志中的关键信息。
体验优化说明:日志实时打印优化,任务失败后会再轮询打印一次日志。
4.离线开发 IDE 界面右侧菜单抽屉支持左右动态拉伸
背景:以前的交互逻辑如图所示,右侧抽屉是固定的,当填写参数等字段信息较多的参数时,非常不方便需要来回拉动查看信息。
体验优化说明:可以自由拉伸右侧抽屉的宽度,调整至舒服的宽度再进行填写。

5.SQL 查询结果空值优化
背景:目前离线展示的查询结果有问题,不管是空还是字符串都显示为空,用户无法进行区分。
体验优化说明:查询结果对 「对象为字符串为“null” 」「对象为字符串为“” 」「对象为空」三种情况做了区分。

6.任务下线时提示当前下游依赖的任务
背景:任务被下线时,会影响到当前任务的所有下游任务,用户通常没有很好的方式能够去判断具体影响了哪些下游任务。
体验优化说明:对任务进行下线操作时,会出现弹窗显示当前影响的任务范围。
7.GitLab 代码同步功能优化
• 适配 GitLab 版本15.7.8
• 项目拉取改为异步操作,防止拉取超时
• 任务推送从“保存后再推送"修改为“推送完成后再保存”
• 支持按照任务目录拉取
• 按文件类型选择时,修改为选填
• 批量操作希望支持批量推送和拉取

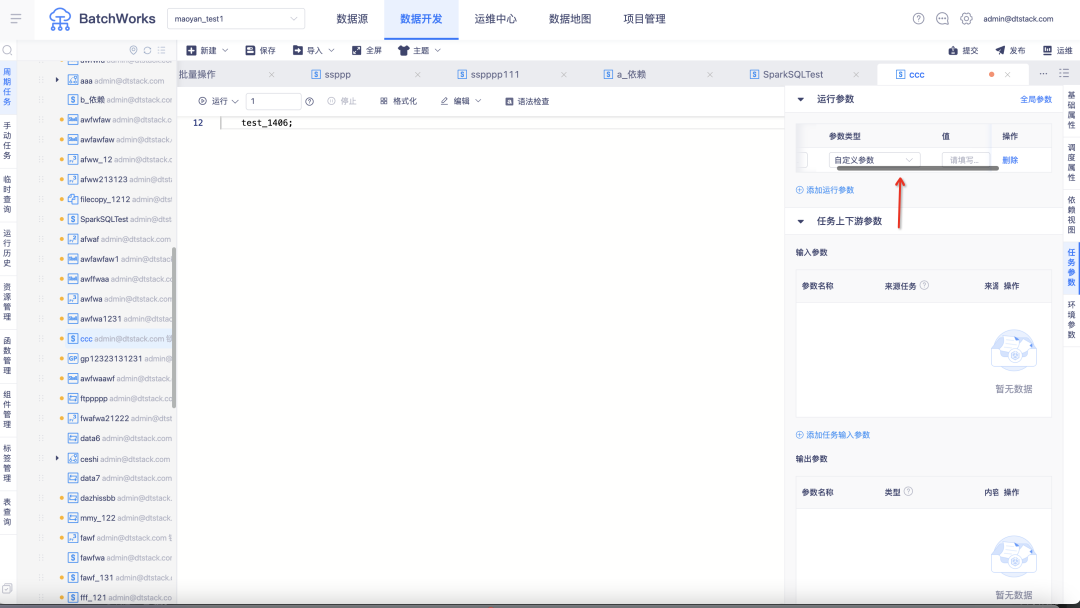
8.SQL 查询结果优化
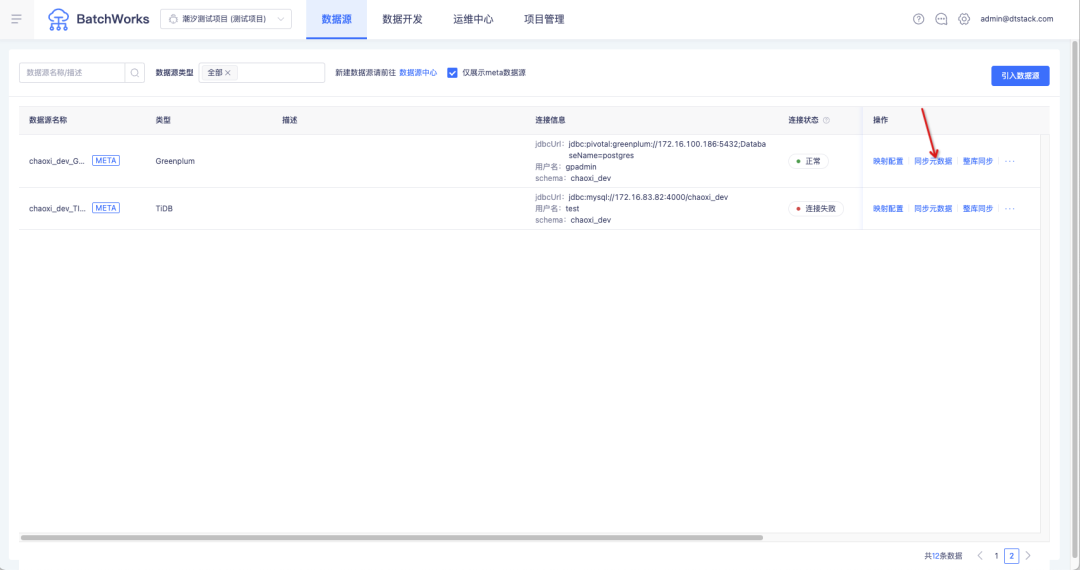
• 离线元数据同步支持视图同步:离线数据源页面的元数据同步功能,支持元数据同步同步视图
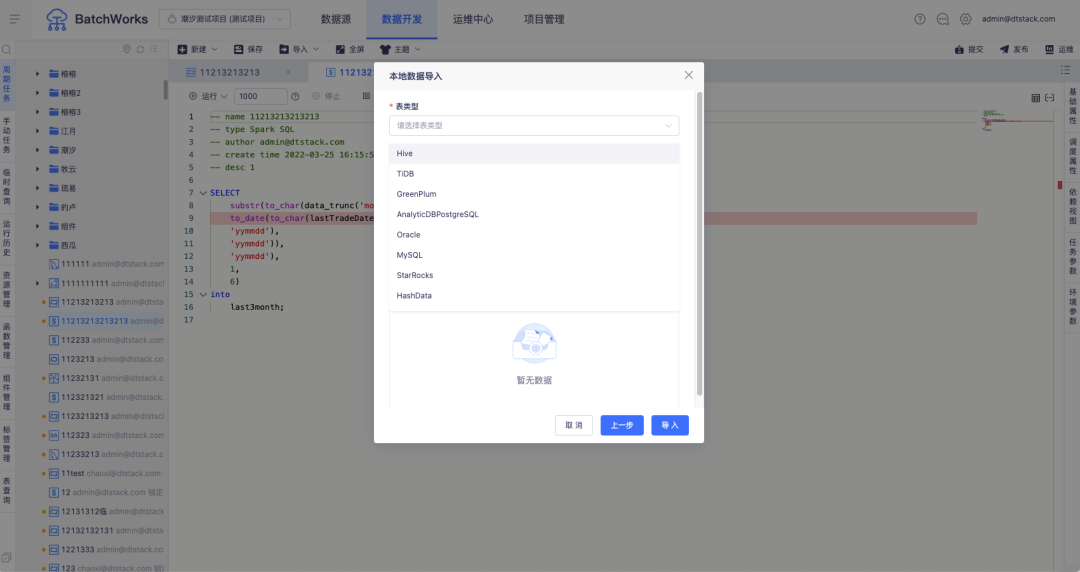
• 支持数据源本地数据导入
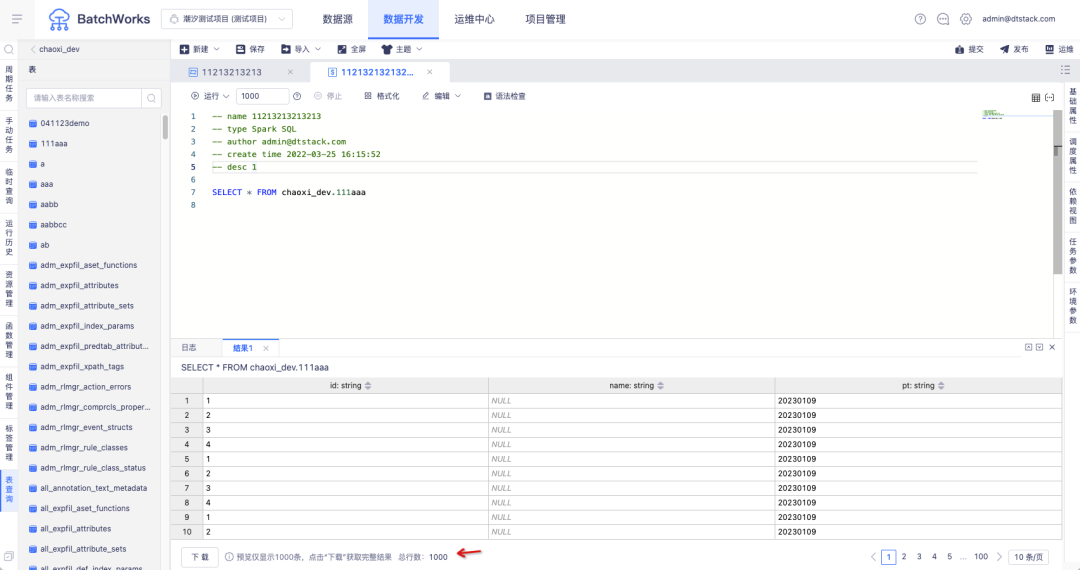
• 查询返回行数
• 查询结果支持排序

• 查询结果表名标识字段类型标记
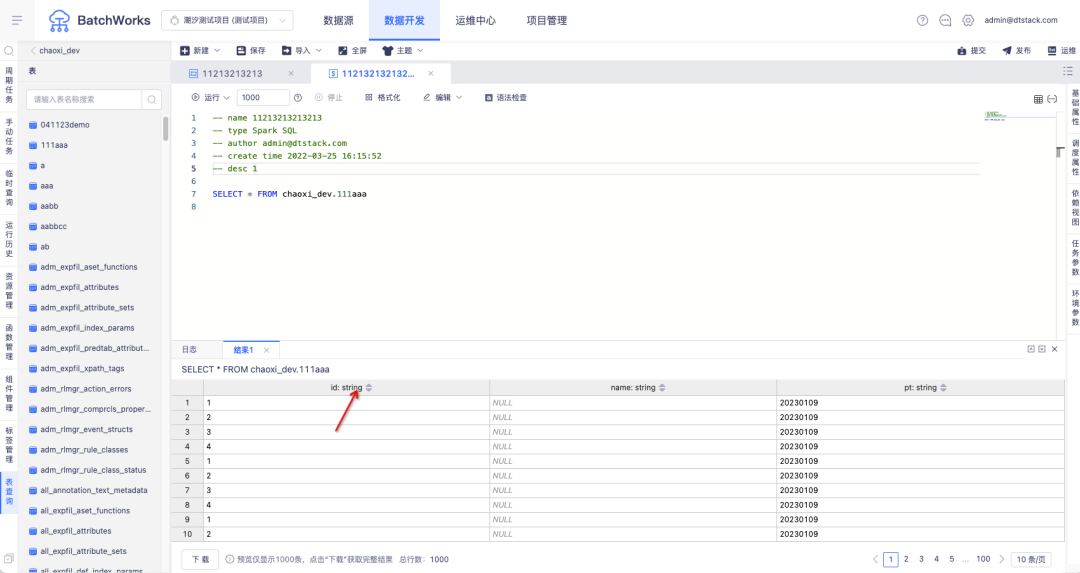
9.调度周期为月时,支持选择最后一天
调度周期为“月”时,时间支持选择“每月最后一天”。

10.Inceptor 读取支持范围分区
背景:在数据同步中,离线 Inceptor 读取不支持范围分区(Range Partitioning),仅支持了单值分区(Single-Value Partitioning)。
体验优化说明:在离线数据同步选择 Inceptor 数据源读取时,支持选择范围分区。
实时开发平台
新增功能更新
1.TBDS 账号
有 TBDS 账号的用户,往集群提交任务时以个人账号提交,其余统一以默认账号提交。
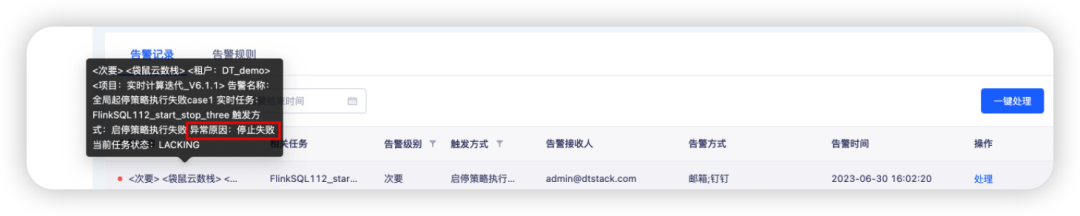
2.全局/任务告警新增“启停策略执行失败”触发方式
背景:目前平台无法感知到启停策略是否执行成功,比如运行中的任务是否按照启停策略正常停止了,停止的任务是否按照启停策略重新启动了。
新增功能说明:配置规则后可以在告警内容中看到具体失败的原因。

3.支持用户自定义角色
背景:目前用户在平台内使用的角色和对应权限点是内置固定的,当不同用户对角色应有的权限点或者角色种类与平台提供的想法不一致时,无法根据自身需求进行修改。
新增功能说明:支持在「角色管理」中新增自定义角色并编辑相应角色权限点,并优化了项目内操作成员的权限。

4.Flink1.16 任务支持 on k8s 运行
支持在控制台-集群配置中配置采集类型为 NFS 的 k8s,配置步骤在「整体说明-调度支持」中查看。
5.新增 Hudi 作为 FlinkSQL 的源表/结果表
支持引入 HMS 数据源,并且可以在 FlinkSQL 向导模式的源表/结果表选择 Hudi 表。

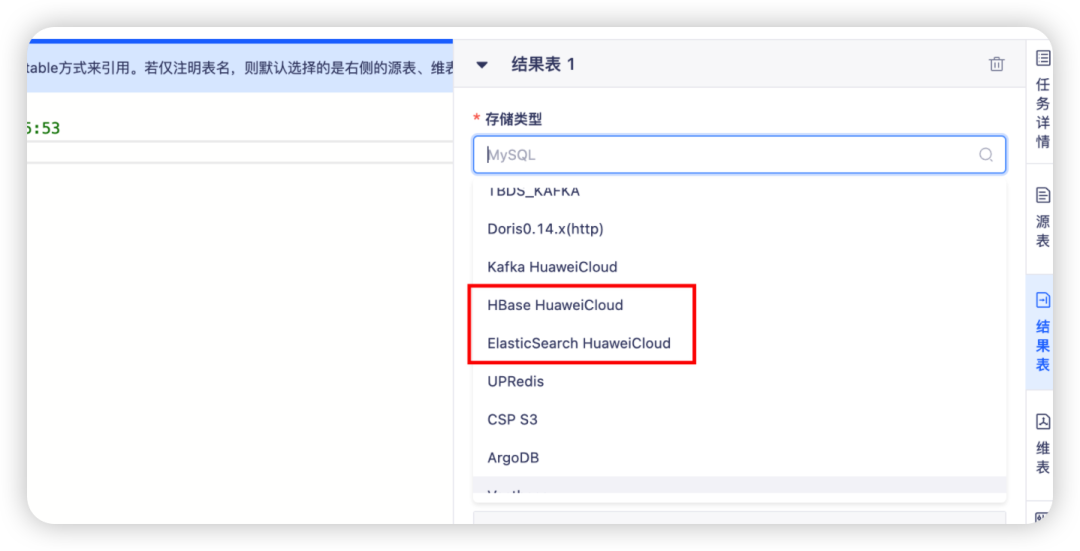
6.新增 HBase/ElasticSearch HuaweiCloud 作为 FlinkSQL 的维表/结果表
支持在结果表/维表中选择使用适配 fusioninsight/MRS 集群的 HBase/ES HuaweiCloud 数据源。

7.实时任务的 sql query、调试和售前 demo 任务通过的 session 模式提交
背景:目前实时平台的任务提交默认均走 perjob 模式,但是对于实时 sql query、调试、demo 任务的场景,需要更快速的产出数据,并不需要持续长时间的运行,perjob 模式的优势就利用不上了。并且 perjob 模式的劣势在于提交流程较长,也不符合此类场景。
新增功能说明:session 配置新增以下三个配置项来支持实时的任务场景:

8.源表新增 Upsert Kafka 插件
新增 Upsert Kafka 插件做为 FlinkSQL 的源表和结果表。

9.新增【实时湖仓】模块
新增【实时湖仓】模块,支持对湖表的管理和计算。
功能优化
1.增强 IDE 中 FlinkSQL 语法解析的准确性
背景:之前的语法解析,对于很多 SQL 正确的写法依然会高亮报错。
体验优化说明:提高对 SQL 语法解析的准确性。
2.Starrocks 结果表,向导模式支持更新模式
背景:Starrocks 插件支持 upsert 定义主键,但平台向导模式不支持,需要在向导模式对更新模式进行调整适配。
体验优化说明:向导模式适配 Starrocks 数据源并适配 upsert 自定义主键。

3.新增 oushu 目标表
结果表支持 oushuDB 数据源。

4.日志打印中的业务数据问题
背景:目前实时任务的运行日志中会打印业务数据,存在数据安全风险,需要屏蔽掉。
体验优化说明:运行日志、task manager 日志、历史日志里是否存在打印业务数据,如果存在,对打印的业务数据做隐藏。

5.新增【任务下线】功能、新增【任务停止时间】列
优化部分任务运维的交互体验,新增【任务下线】功能,在任务列表新增【任务停止时间】列。

6.向导模式的各种数据源统一开放自定义参数配置
背景:目前结果表中部分数据源的「添加自定义参数」和「更新策略」配置项是缺失的。
体验优化说明:
• 结果表—Sql server维表—mysql、oracle、sql server、Postgresql、kingbaseES8、greatdb、doris0.14.x(http)、doris0.14.x(jdbc)starrocks、impala、clinkhouse、inceptor、ES6.x、ES7.x、TBDS_HBASE、argodb、vastbase 对以上数据源添加开放自定义参数配置。
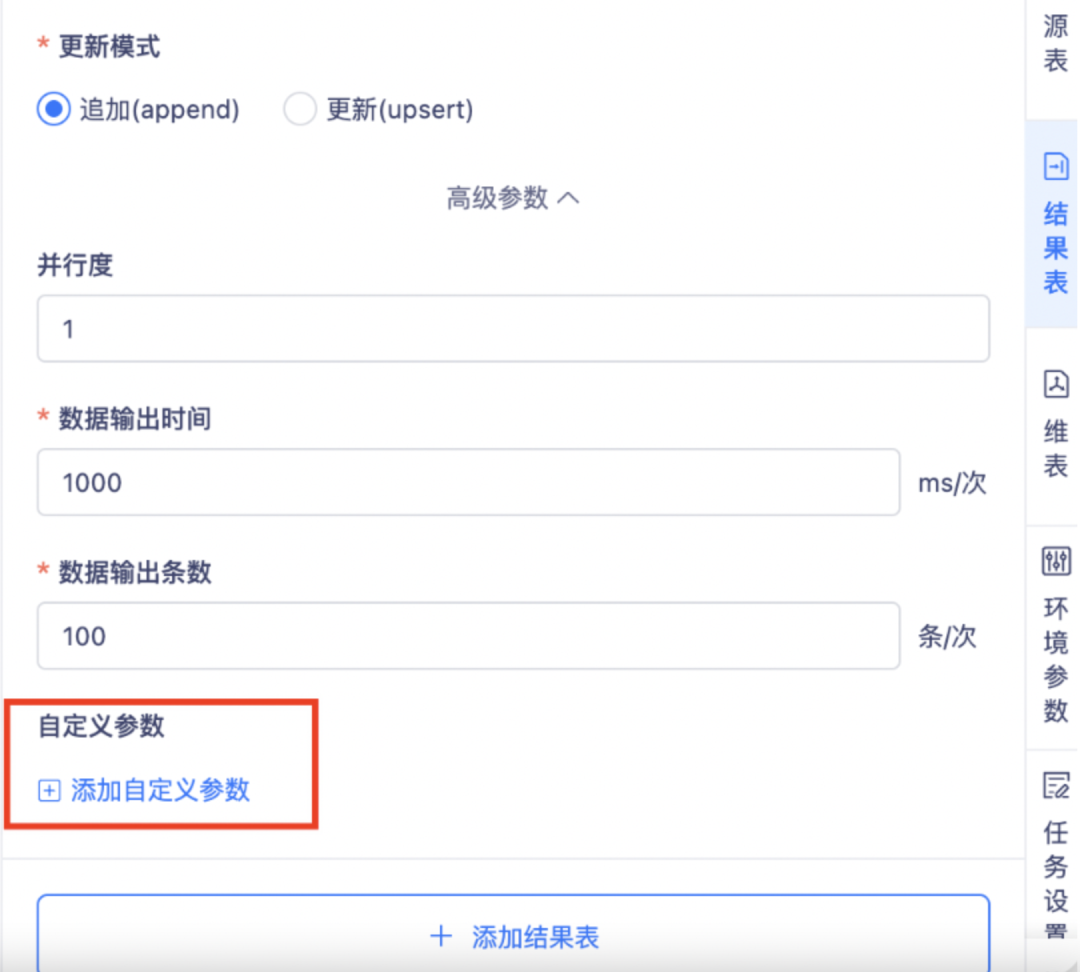
• 结果表—涉及数据源:Sql server、Postgresql、kingbaseES8,对以上数据源新增更新策略。
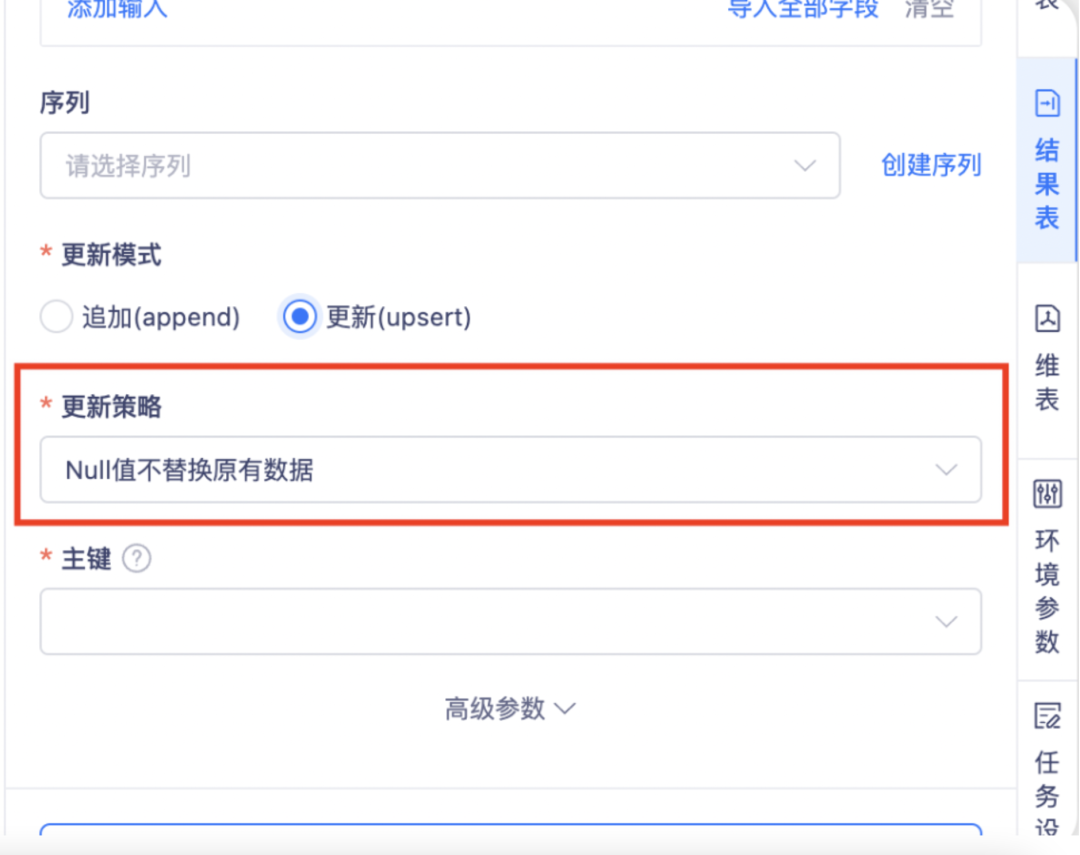
7.【任务运维】健康分模型优化
对于任务运维做功能上优化,新增任务扣分项说明、常见问题排查指导,用户可通过健康分查看具体扣分项进行完善,方便于用户进行问题排查。

8.【实时开发】任务导入导出功能优化
背景:实时任务的导入导出功能,在做任务资源组信息替换时,用了数据库的序号,而没用名称,导致跨环境导入时会报错。(因为跨环境的这些信息,在数据库的id大概率是不一样的)
体验优化说明:任务导入导出时,需要做信息替换的如资源组、数据源等信息,均使用名称进行替换。这样只需要保障两个环境维护的名称一致,就可以实现跨环境的政策导入导出。
数据资产平台
新增功能更新
1.Trino 支持元数据同步
离线、指标、标签等其他产品模块创建项目生成的 Trino meta 数据源资产支持自动引入,且 Trino meta 数据源支持质量项目授权。
2.支持通过 Trino 实现 TDSQL 和 Inceptor 表的跨源比对
背景:Inceptor 表的比对中之前没有考虑 hyperbase、hyperbase drive、search 的支持。
新增功能说明:数据质量可通过 Trino 实现 TDSQL 和 Inceptor(hyperbase、hyperbase drive、search) 表的跨源比对。
3.分区表支持在表结构中显示分区信息
若该数据表为分区表,则在表详情-表结构中,新增展示表的分区信息。
4.支持数据标准的上线、下线审批操作
数据标准模块普通用户创建的数据标准需要经过审批中心审核完成后才可进行上线、下线,上线后的数据标准才可进行标准映射及标准绑定操作。

5.元数据同步支持配置自动同步过滤规则
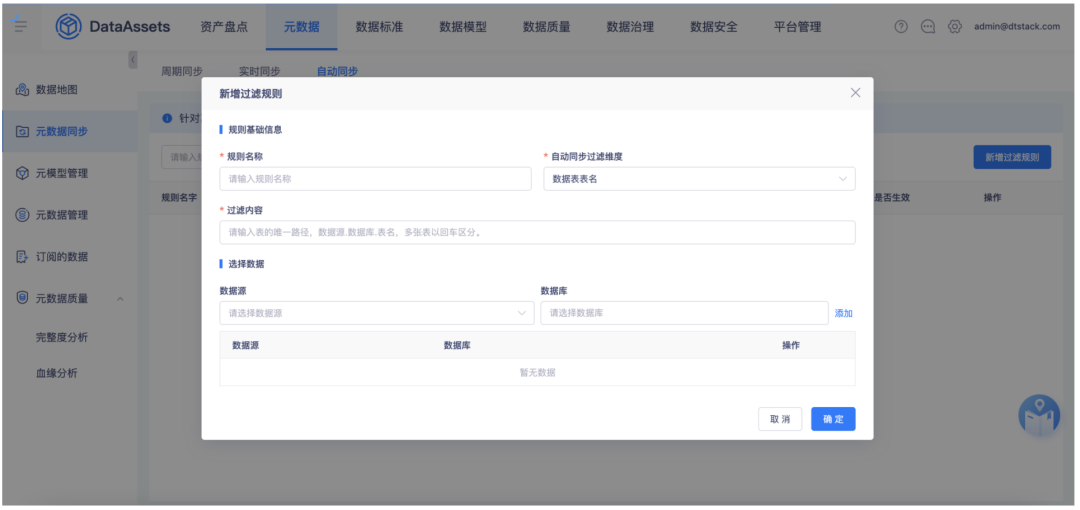
背景:针对监听离线 ddl 语句并实时同步表进入资产的逻辑,客户元数据同步任务是添加了过滤条件的,不想采集 tmp 表到数据地图,通过元数据同步任务是可以过滤掉的,但是实时 ddl 监听的逻辑是没有地方添加过滤条件的,所以离线跑任务的时候,里面的 tmp 表还是会被采集到资产中。
新增功能说明:在元数据同步模块新增【自动同步】功能,用于配置自动同步的过滤规则。
6.greenplum 数据源支持视图同步
greenplum 数据源支持进行视图同步,gp 视图与 gp 数据表共用一个元模型,元模型中新增源表名(视图特有)、视图描述(视图特有)技术属性,在选择 gp 类数据源下的数据时,可选中具体视图进行元数据同步、数据脱敏等操作。

7.资产支持 MySQL 类型数据源的自动引入
针对离线创建项目时生成的 meta 数据源,资产支持 MySQL 类型数据源的自动引入,自动引入后需自动创建周期任务。
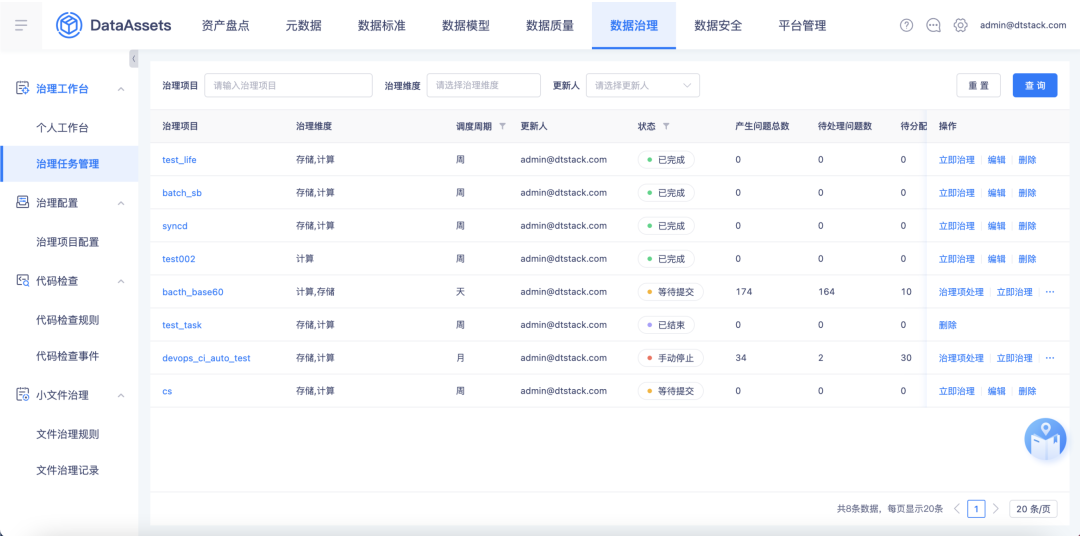
8.【数据治理】治理工作台、治理配置功能
背景:数据治理的意义是为推动用户依据规范标准进行数据开发,从计算、存储、质量、规范、价值五个维度进行数据治理,目的是优化存储成本、节约计算资源、推动标准规范,让用户通过数据治理看到问题、看到效果。
新增功能说明:本次迭代支持从计算、存储维度进行数据治理,支持自动同步离线开发模块创建的项目信息,可通过配置治理任务对项目进行周期治理,并对产生的待处理问题分配处理人进行处理,实现问题的闭环管理。

功能优化
1.告警邮件内容增加实例的计划时间
在告警邮件中增加“计划时间”,原来的“调度时间”修改为“开始时间”,便于用户直接通过邮件等通知观察到具体是哪一天的质量任务校验失败。
2.数据源显示优化
• 已接入的数据源,按数据源数量-库数量-表数据-存储大小的优先级排降序
• 数据目录分布中,根据当前租户对接的子产品模块来显示数据资源内容
3.数据安全开启时 web 层表权限的申请入口脱敏入口去掉
当数据安全子模块中开启权限管控策略时,以数据安全模块配置的权限策略为准,资产模块的表权限的申请入口隐藏。
若数据安全子模块中开启了针对 hive/sparkthrift/trino 的脱敏策略,则脱敏入口中的脱敏应用,不可选择这些类型的数据源下的数据表。
4.表生命周期 IDE 脚本同步
离线开发模块支持通过 IDE 脚本进行生命周期配置,当生命周期有变更时,可同步到资产,在元数据模块查看表详情时可展示生命周期信息。
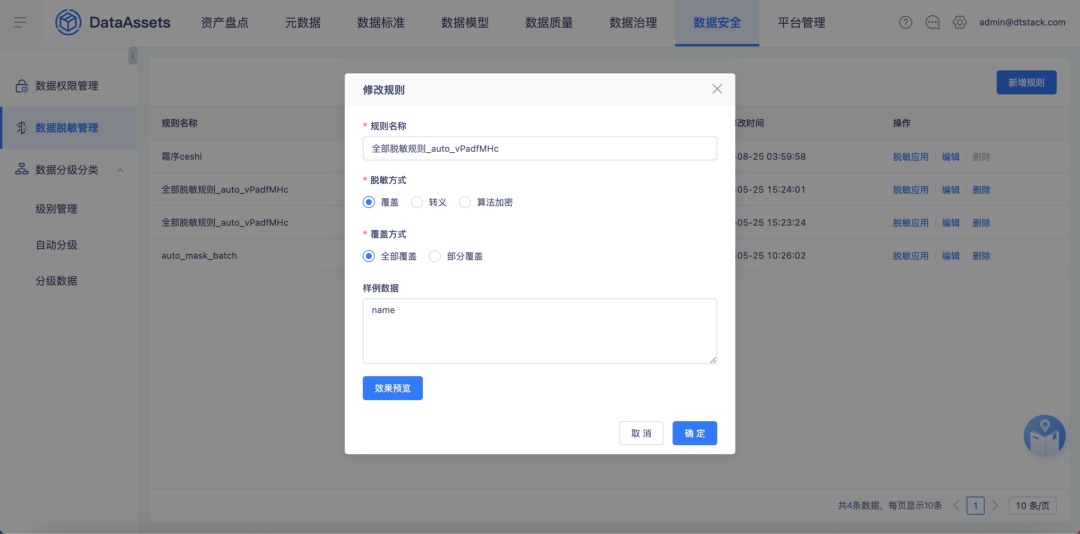
5.数据脱敏管理优化
数据脱敏规则配置完成后,在进行脱敏应用配置页面支持编辑操作。
6.规范性规则校验优化
规范性规则逻辑优化,例如设置最小长度=20,逻辑为字符串长度大于等于20算符合规则(最大长度函数逻辑同理)。
7.【数据地图】数据表展示优化
数据表的列表展示中,展示内容为“数据源·数据库”调整为展示“数据源 | 数据库”,鼠标悬浮提示“数据源 | 数据库”。
若数据源存在多个,展示第一个数据源名称的完整信息,其他的用“…”表示,例如“mysql_test1… | dbtest1”;针对 Trino 数据源,展示内容为“数据源 | catalog | 数据库”。
表详情页面,在技术属性一栏,“表名”字段的下方,新增字段为“数据源”,展示该数据表的所属数据源信息,多个数据源之间用英文分号分割。元数据模型中的技术属性页面,新增技术属性“数据源”。
8.表结构字段列表编辑交互优化
背景:字段列表里可编辑的内容要一个个点编辑比较麻烦,优化成整表点编辑后所有位置可编辑,编辑完以后整表保存。
体验优化说明:
• 标签添加的交互逻辑优化
• 支持批量编辑字段描述及字段标签
数据服务平台
新增功能更新
1.API 调用各阶段组成及耗时分析
测试 API 页面和生成 API 测试界面添加调用分析 tab,可通过瀑布图看到总耗时以及执行的内容,以及函数报错等问题的具体原因。
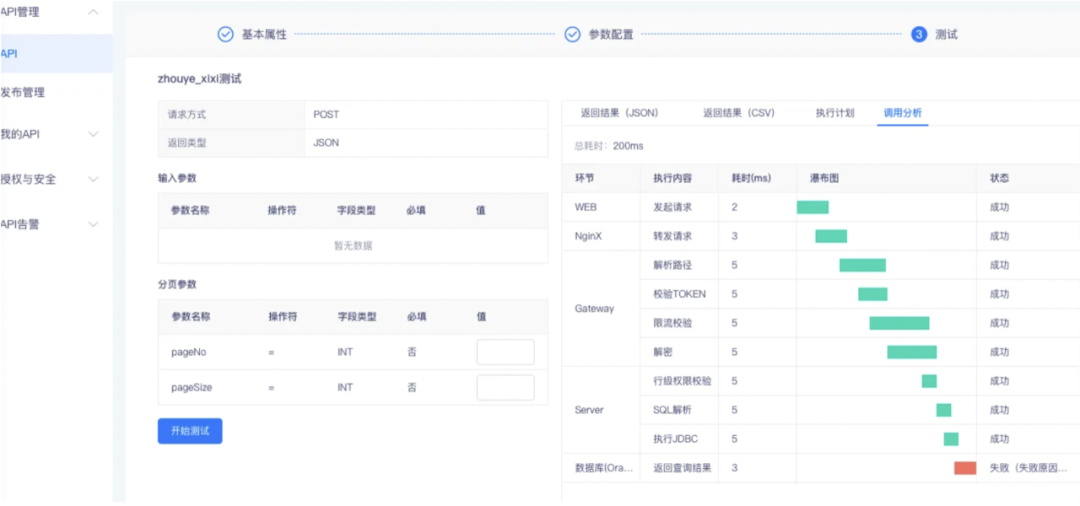
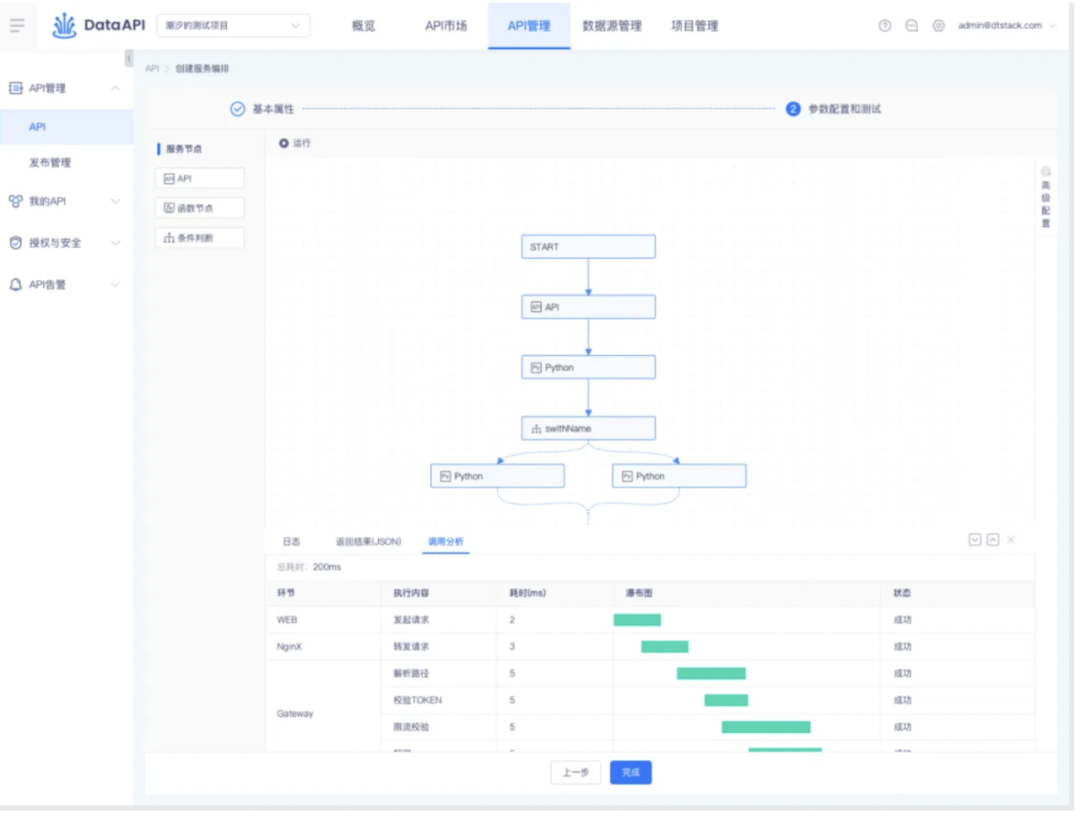
服务编排与生成 API 类似增加调用分析,可查看具体的耗时及失败原因。
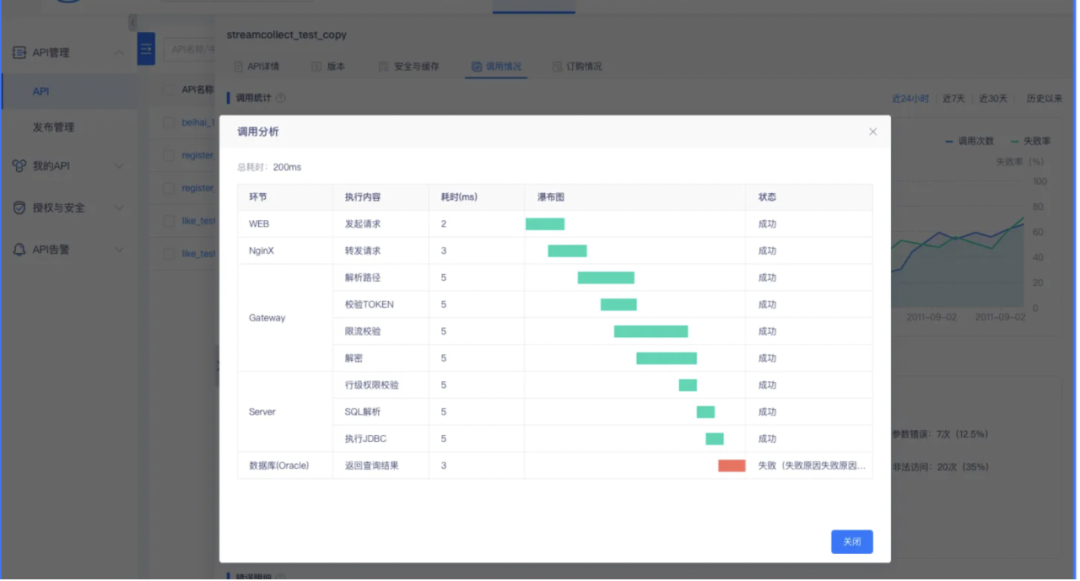
每次调用记录增加保存入参内容(生成 API、注册 API、服务编排、服务分析)和调用分析(生成 API、注册 API、服务编排),且支持查看调用分析逻辑与生成 API 调用入参一致。
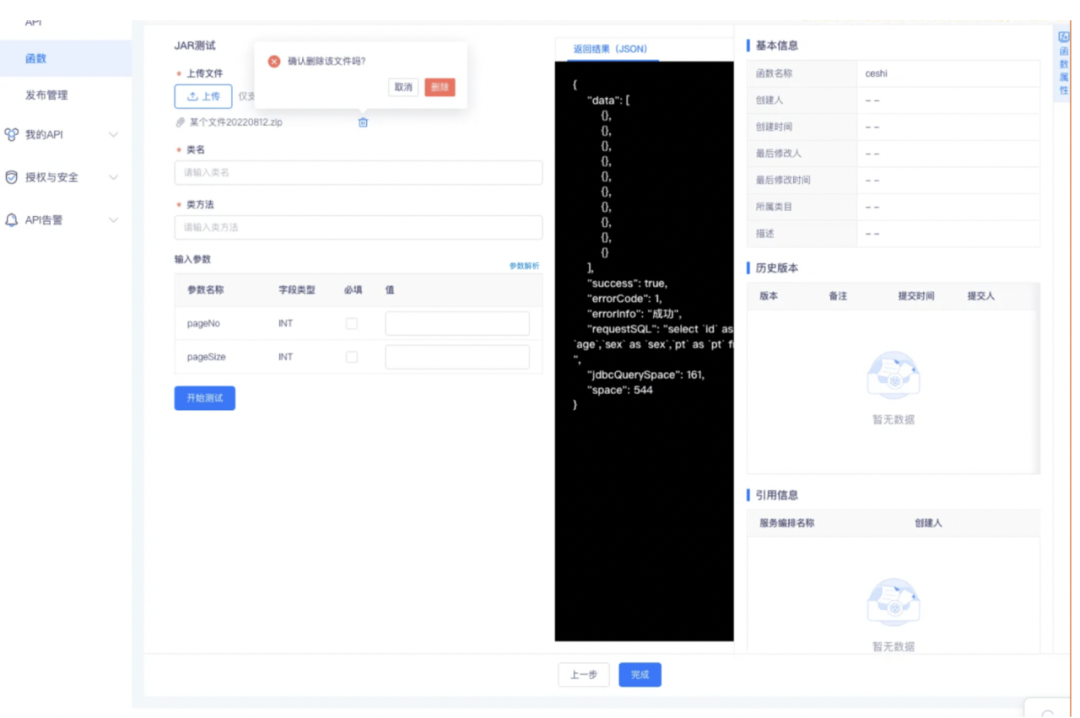
2.服务编排支持 JAVA
服务编排由 python 节点变为函数节点,函数节点可选择是哪个函数类型,python2.7、python3.9 以及 JAVA 函数,入参方式与原来相同。

函数类型新增 Java8,当函数类型选择 JAVA8 时,跳转至 JAR 包上传界面,python 函数与原来一致。Java 函数跳转后,先上传 JAR 包或 zip 文件,大小小于50MB,再进行填写类名与类方法。在输入参数时,点击参数解析,可自动解析字段类型,参数名称等。

3.服务编排支持显示结果返回样例
服务编排高级配置中增加显示返回结果样例及将测试结果作为 json 样例保存。

4.支持 API 路径前缀自定义
此部分实现主要通过配置项变更和代码逻辑兼容,配置项变更如下(同名配置项服务之间配置的值必须保证完全一样):
api-web变更:
(废弃) gateway.url
(新增) gateway.url.host = http://gateway-default-api530-api.base53.devops.dtstack.cn
(新增) gateway.url.custom.prefix = /custom/data
(新增) gateway.url.custom.open = true
gateway变更:
(新增) gateway.url.custom.open = true
(新增) gateway.url.custom.prefix = /custom/data
nginx变更/conf/conf.d/apigw.conf:
(localtion后面的配置需要基础运维进行提取变量,支持通过em进行配置项的变更,变更值与api配置文件中gateway.url.custom.prefix保持一致)
#location /api/gateway {
-> 修改成:
#location /custom/data {
proxy_max_temp_file_size 0k;
fastcgi_buffers 32 8k;
proxy_http_version 1.1;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_pass http://real-rdos-api-gw;
if ($request_method = 'OPTIONS') {
return 204;
}
}
配置项说明:
• gateway.url.custom.open :是否使用自定义 url 前缀,默认 false
• gateway.url.host :请求 url,组成为 http(https)😕/hostname:port
• gateway.url.custom.prefix :自定义前缀,以斜杠开头,支持多级,默认 /api/gateway
5.API 支持批量提交、发布、撤回
支持 API 可以批量提交、批量发布、批量撤回等操作,提高 API 的操作效率。

功能优化
1.API 入参支持多个参数至少填写几个的方式来请求
非必填字段可以选择必填几个字段来进行入参。例如:手机号,姓名,身份证。该功能可限制必须填入的字段个数,数字框为2,则必填俩个,可填写手机号或姓名,身份证或手机号,即可获得返回参数,否则调用失败。

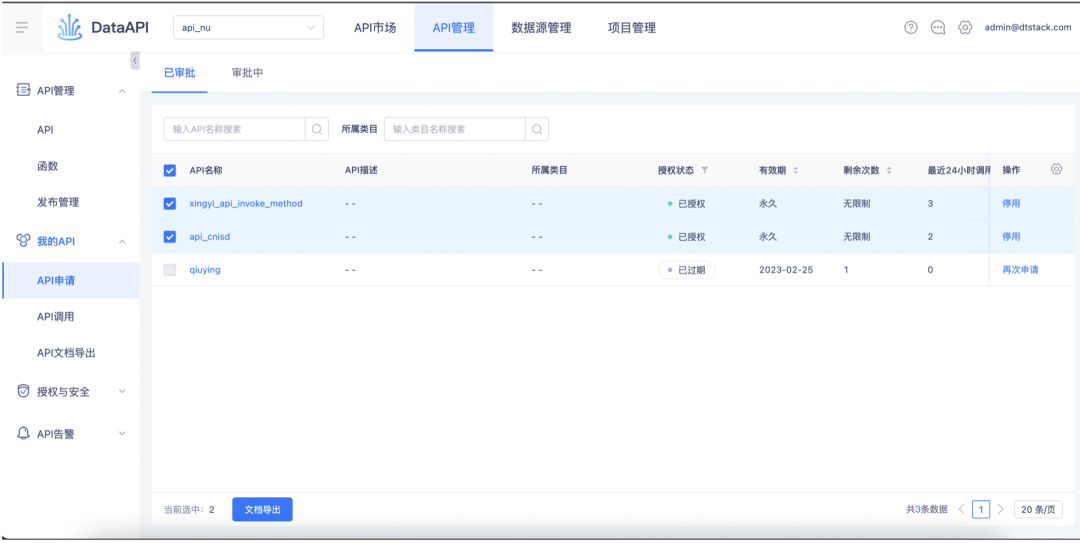
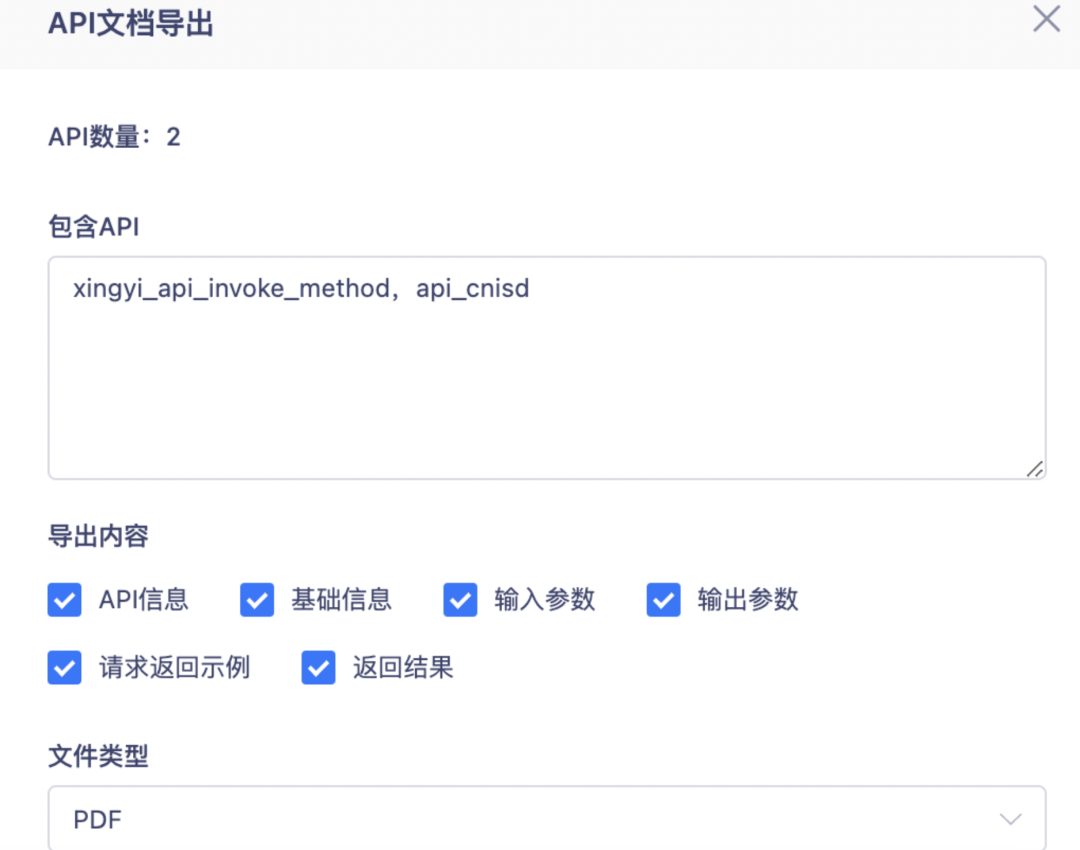
2.API 文档导出时支持选择导出的内容
API 文档导出时支持选择导出的内容,且可支持选择目录中的部分 API 进行文档导出。
3.注册 API 返回结果是否带平台默认结构支持配置
背景:目前在数据服务注册的 API 会外面包一层内容,导致注册以后的返回结果与原生 API 不一致。
体验优化说明:后端增加一个配置项,可配置返回结果是否加上我们自己的内容,默认加上。
4.支持 API 做熔断和降级的策略创建
支持创建熔断降级的策略:

创建后可以在单个 API 进行选择应用:
客户数据洞察平台
新增功能更新
1.标签目录支持批量上传、下载
背景:客户开发标签通常存在两套环境:生产环境、测试环境,在测试环境创建的标签目录期望直接能同步到生产环境,省去重复操作的过程。
新增功能说明:
• 进入项目A的标签目录列表中,点击「目录下载」下载目录文件

• 进入项目B的标签目录列表中,点击「目录上传」上传目录文件

• 上传 CSV 格式目录文件,系统将根据目录名称、目录级别、上级目录名称做增量更新,需保证上级目录在文件或线上目录中已存在。文件目录采用异步方式更新,更新过程中,目录不可修改。

2.标签跨项目/实体复制
背景:在测试环境与生产环境同在的情况下,想要实现在测试环境进行标签加工测试功能无误后,将该标签以简单的方式在生产环境设置一遍。
新增功能说明:
• 「新建标签」时可以通过「跨项目复制」将当前项目下其他实体或是其他项目的标签复制到当前实体下快速创建标签

• 选中特定标签后,将进入标签创建页面,将复制标签的配置信息快速填充至当前新标签的配置中,若其中涉及当前实体尚未配置的表/标签,则需手动重新选择一遍。
3.数据同步支持同步到 Inceptor,生成 hyperbase 格式的表
背景:数栈底层支持使用 TDH,上层对应的数据客户存储到了 Inceptor,相应的,数据同步结果需要同步到 Inceptor。
新增功能说明:API 访问数据源设置中,可设置 Inceptor 数据源。
功能优化
1.标签 SQL 优化,partition 相关字段拆分提高加工效率
背景:历史 SQL 拼接是基于全表做数据查询,数据量大时会存在内存溢出场景,导致报错。
体验优化说明:SQL 优化调整为优先确定所需分区,再对该特定分区做数据查询,从而避免报错情况出现。
2.实体增加源表说明信息
背景:实体内涉及到的表信息历史均是以表名做展示,英文的形式不方便直观理解,补充展示表说明内容。
体验优化说明:
• 实体详情内展示表说明信息

• 新建/编辑实体,展示表说明信息

3.标签配置、标签市场、标签圈群页面展示标签名称+描述信息


4.列表优化
标签圈群实例列表页、群组详情群体列表页、群组交并差等页面,页面滑动至列表区域,列表区域可全幅显示,展示更多内容。
指标管理平台
新增功能更新
1.指标结果表历史数据支持行级更新
背景:绩效考核场景下,绩效分配规则由业务人员制定,通常规则的推出具有滞后性,即,规则是2023年4月1日推出,规则的生效时间从2023年1月1日开始执行,此时就需要对自2023年1月1日以来的数据做更新。全表更新的方式效率慢、占用资源大,只对受影响的行做更新将可缩短更新周期,对业务正常使用影响也相对较小。
新增功能说明:
行更新的整体操作流程如下:
• 创建数据模型时,对于源表涉及到行更新的 hudi 表,将其设置为需要行更新,创建模型后,系统将为该表提供一个接口,供传入变更数据条件

• 根据需要创建对应的指标,因模型中使用到了行更新表,后续指标都将通过 Spark 计算,存储为 Hudi 表,同时,因 Spark 暂不支持并发写 Hudi 表,调度中涉及到的跨周期依赖内容需要选择自依赖
• 调用该表的行更新接口,传入变更条,接口信息可通过「数据源管理」中的表详情查看。系统将根据提前设置好的更新频率,针对已经接收到的变更记录,自动识别所有指标表中受影响的行,计算出新的结果后对历史数据做批量更新,若数据的行更新具有紧迫性,也可点击「行更新」立即执行
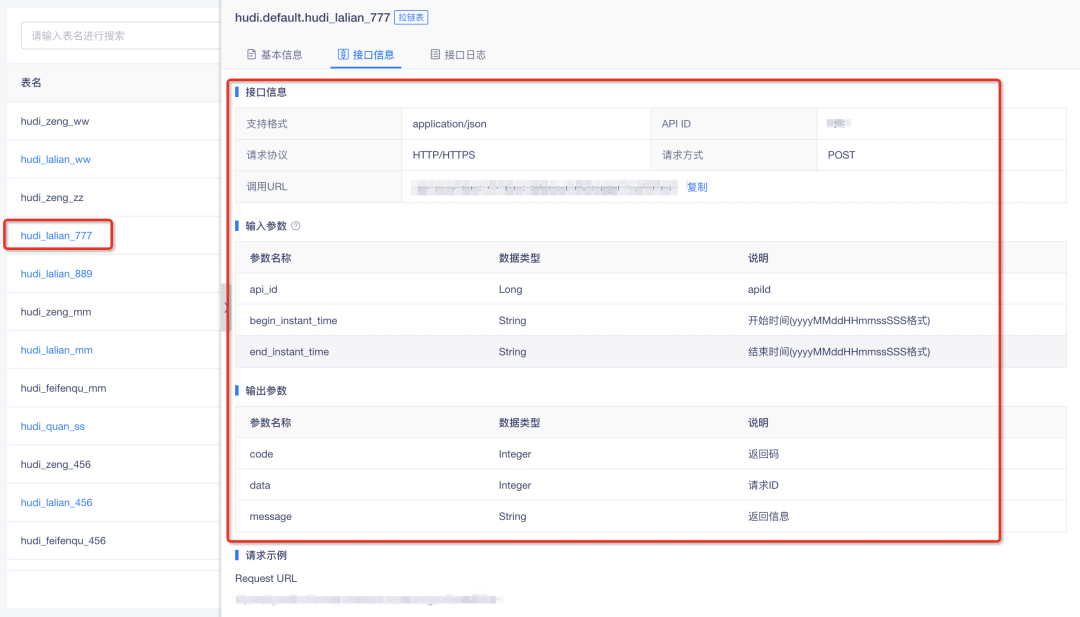
• 【数据源管理】模块中查询相关记录变更后的后续指标的行更新进度

2.指标目录支持进行权限控制
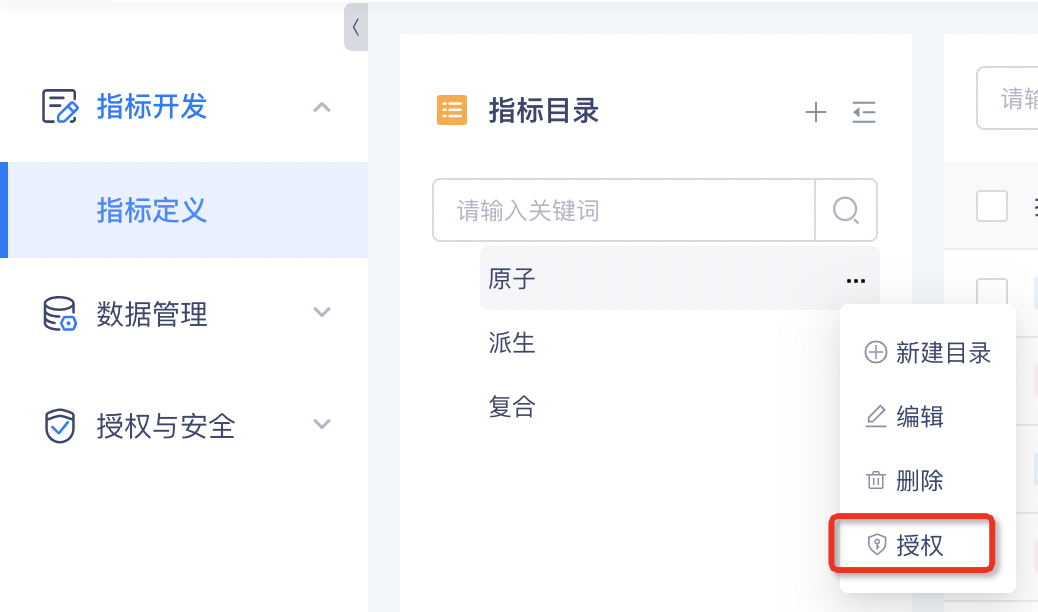
背景:基于指标安全级别,需要将不同的指标授权给不同的人使用,通常指标目录是按业务划分,考虑操作的复杂性,计划将指标授权功能放到指标目录曾经,通过指标目录控制目录下所有指标的查看/编辑权限。
新增功能说明:
点击目录右侧的「授权」按钮,打开目录授权窗口。
授权页面,系统会默认将新创建的目录设置为全员可编辑,在此基础上,可修改为全员可查看、部分用户可编辑;也可关闭全员设置,只对部分用户开放查看、编辑操作。
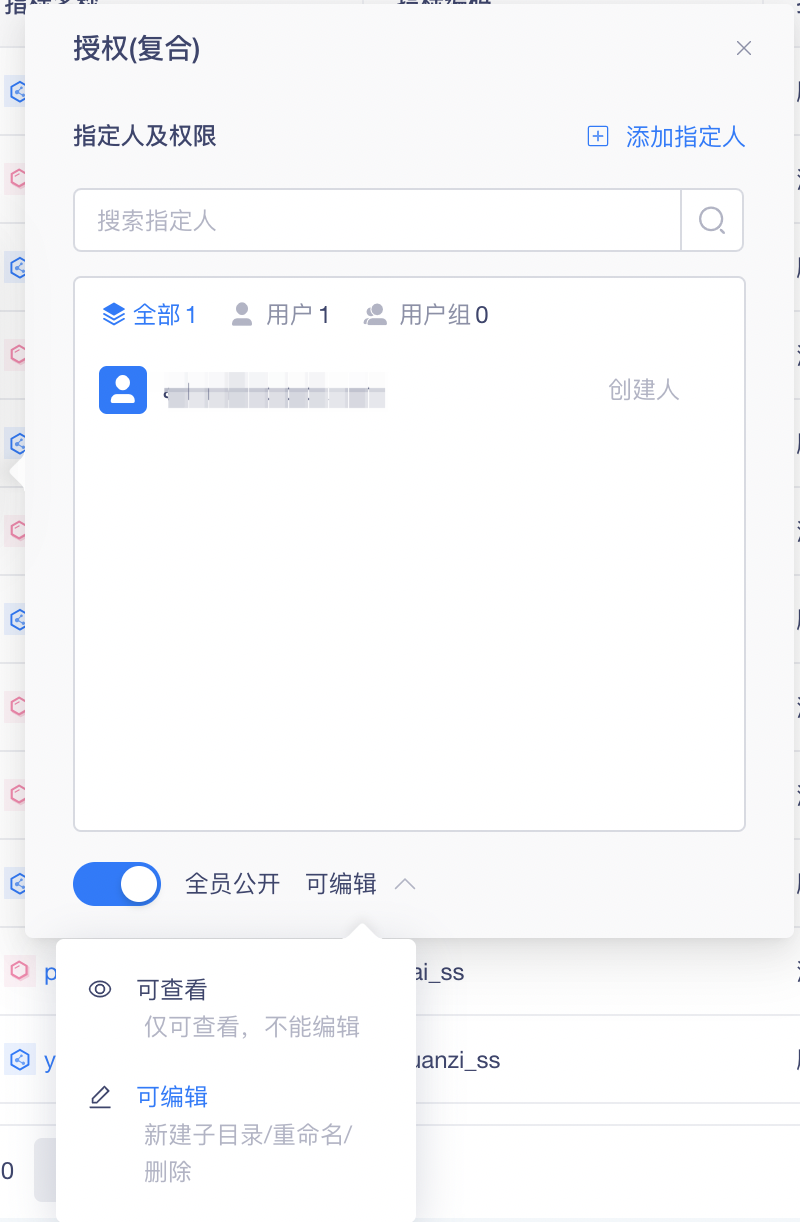
授予权限的用户可看到该目录下的所有指标,新建/编辑指标时也可选择有权限的目录。
3.指标支持自定义添加 UDF 函数
背景:系统目前支持的函数均为 Trino 支持的系统函数,在此基础上,会有部分场景需要用到用户自定义的函数,如:取上周一所在日期,该内容需要通过自定义函数来实现。
新增功能说明:
针对 Trino385 版本,可在「函数管理」模块创建 Trino 自定义函数,创建成功的自定义函数可在自定义指标中被引用。
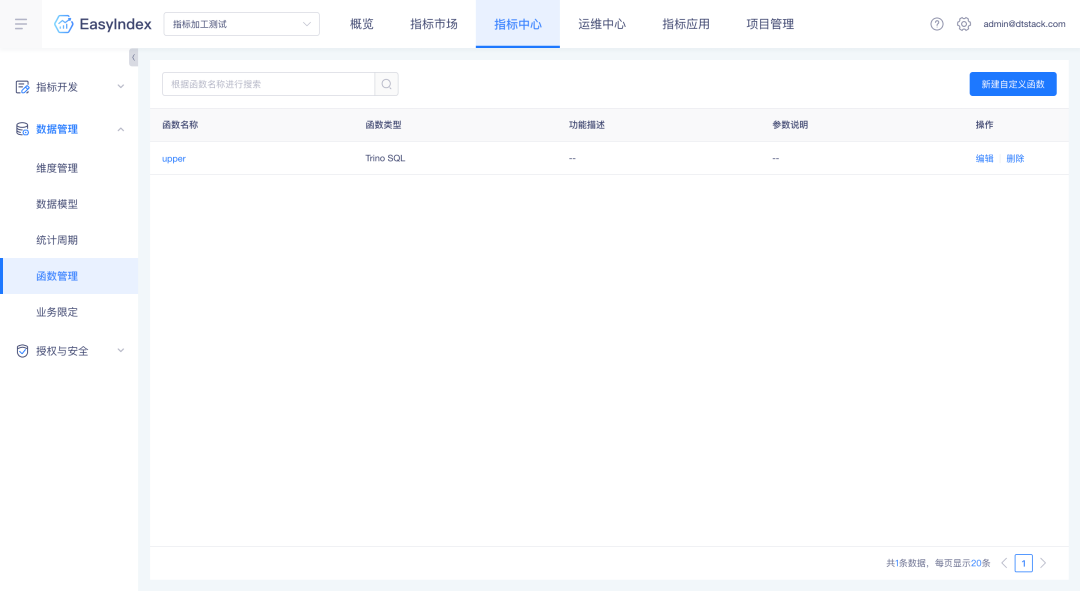
第一步:在平台创建自定义函数前,需要先写好自定义函数插件,并将文件打包成 zip 包。
第二步:点击「新建自定义函数」进入函数设置窗口,配置函数信息并将打包好的文件上传。

第三步:进入自定义指标新建/编辑页面,编写 SQL 并调用自定义函数。

4.统计周期增加时间参数:上季初、上月初、上月末、上年初
背景:绩效考核场景下,统计周期涉及统计上月、上季、上年的汇总数据,对应的时间参数需要支持 yyyyMMdd、yyyy-MM-dd 格式的上季初、上月初、上月末、上年初参数。
新增功能说明:
• 上季初:bdp.system.preqrtrstart、bdp.system.preqrtrstart2
• 上月初:bdp.system.premonthstart、bdp.system.premonthstart2
• 上月末:bdp.system.premonthend、bdp.system.premonthend2
• 上年初:bdp.system.preyrstart、bdp.system.preyrstart2
5.支持基于指标结果表生成的新模型做行更新
背景:绩效考核场景下,存在根据模型1创建指标1,并将指标1的结果作为模型2的数据源表,需要实现模型1的表进行行更新后,指标1和模型2的指标均可进行行更新。
新增功能说明:指标提供行更新状态跟进接口,业务通过接口调用状态,再调用下一个模型进行更新。
• 数据模型设置的表选自 Hive Catalog 时,不需要设置行更新、更新方式可修改;选择 Hudi Catalog 时,需要设置行更新
• 数据源管理中仅展示 Hudi 数据源
• 需要行更新的表,设置删除方式可选择两种:
1)物理删除:表的数据删除是直接做删除。此时需要保证表开启 CDC 或文件存储方式是 op_key_only/data_before_after,否则,系统将无法追踪到变更前后的数据差异
2)逻辑删除:表的数据删除是以某一删除字段的值变化做区分,此时需要指定删除字段,以及对应取值
• 对应的查询各指标行更新进度可通过接口查询:
1)入参:表信息、请求id、行更新涉及模型标识/指标标识/API 名称
2)出参:模型/指标/API 针对所需表&所需请求批次的更新状态、表数据更新开始时间、表数据更新结束时间
• 行更新相关的指标 Hudi 表的建表语句做相应调整
功能优化
1.指标共享增加详情信息显示
背景:指标共享模块功能改版,不方便查看已共享指标/模型的共享规则。
体验优化说明:点击共享的指标/模型名称,可查看对应的内容详情,包括共享信息及共享规则。

2.指标共享生成的视图创建规则调整
背景:基于行更新功能产生 Spark 读写数据的场景,因 Spark 暂不支持查询 Trino 视图,需将视图从由 Trino 创建改为由 Spark 创建。
体验优化说明:
• 指标/模型共享过程中涉及到的视图改为通过 Spark 创建
• 共享指标、模型生成的视图名称变更
1)模型视图名称:表名_项目id_模型 code_index_view
2)指标视图名称:指标结果表_项目 id_index_view
3.模型/指标更新的下游联动更新
背景:指标加工过程中,存在上游配置项变更的情况,此时,下游对应的对应 SQL 需做同步更新,以保证全局高效配置,功能统一,代表使用场景如下:
• 客户使用过程中,会存在模型的表的分区字段/维度对象属性配置等信息变更的情况,编辑的技术信息变更后,当前只针对维度勾选上的增减做下游联动更新,其余技术信息的变更也需要联动更新
• 客户计算指标时,存在同一指标不同统计区间内的加工口径不一样的情况,此时,表内将根据口径作用时间同时存在两个口径下的数据,如:2022年数据是口径1的结果,2023年数据是口径2的结果
体验优化说明:
• 模型修改表关联后,原子指标、派生指标联动更新 SQL,将模型部分的 SQL 更新至新版本,同时,若落表的模型选择的表发生变更,模型结果表将采用删表新建表的方式更新模型表
• 模型中的选择维度修改关联维度对象、关联维度属性后,原子指标引用的维度对象、维度属性信息同步更新
• 模型中修改上游任务依赖,派生指标中的上游任务配置同步调整
• 模型/指标维度减少,导致下游指标用到的维度消失时,使用删表、重新建表的方式进行更新指标表
• 模型使用的源表字段类型发生变更时,后续引用该字段的指标表使用删表、重新建表的方式进行更新指标表
4.行更新性能优化
第一版行更新是以分区为单位进行优化,整体速度较慢,本次优化定位到分区内的特定行进行优化,提升整体行更新效率。
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
热门相关:睡服BOSS:老公,躺下! 甜妻动人,霸道总裁好情深 试婚100天:夜少,宠上瘾 豪门隐婚:老婆别闹了 全系灵师:魔帝嗜宠兽神妃