解锁 SQL Server 2022的时间序列数据功能
解锁 SQL Server 2022的时间序列数据功能
SQL Server2022在处理时间序列数据时,SQL Server 提供了一些优化和功能,比如 DATE_BUCKET 函数、窗口函数(如 FIRST_VALUE 和 LAST_VALUE)以及其他时间日期函数,以便更高效地处理时间序列数据。
GENERATE_SERIES函数
SQL Server 2022 引入了一个新的函数 GENERATE_SERIES,它用于生成一个整数序列。
这个函数非常有用,可以在查询中生成一系列连续的数值,而无需创建临时表或循环。
GENERATE_SERIES ( start, stop [, step ] ) start:序列的起始值。 stop:序列的终止值。 step:每次递增或递减的步长(可选)。如果省略,默认为1。
使用场景包括快速生成一系列数据用于测试或填充表或者结合日期函数生成一系列日期值。
示例
生成的结果集将包含 20 行,每行显示从 '2019-02-28 13:45:23' 开始,按分钟递增的时间。
SELECT DATEADD(MINUTE, s.value, '2019-02-28 13:45:23') AS [Interval] FROM GENERATE_SERIES(0, 20, 1) AS s;
对于每一个 s.value,DATEADD 函数将基准日期时间增加相应的分钟数。

DATE_BUCKET函数
SQL Server 2022 引入了一个新的函数 DATE_BUCKET,用于将日期时间值按指定的时间间隔分组(即分桶)。
这个函数在时间序列分析、数据聚合和分段分析等场景中非常有用。
DATE_BUCKET ( bucket_width, datepart, startdate, date ) bucket_width:时间间隔的大小,可以是整数。 datepart:时间间隔的类型,例如 year, month, day, hour, minute, second 等。 startdate:起始日期,用于定义时间间隔的起点。 date:需要分组的日期时间值。
使用 DATE_BUCKET 函数时,指定的时间间隔单位(如 YEAR、QUARTER、MONTH、WEEK 等)以及起始日期(origin)决定了日期时间值被分配到哪个存储桶。这种方式有助于理解时间间隔的计算是如何基于起始日期来进行的。
示例
DECLARE @date DATETIME = '2019-09-28 13:45:23'; DECLARE @origin DATETIME = '2019-01-28 13:45:23'; SELECT 'Now' AS [BucketName], @date AS [DateBucketValue] UNION ALL SELECT 'Year', DATE_BUCKET (YEAR, 1, @date, @origin) UNION ALL SELECT 'Quarter', DATE_BUCKET (QUARTER, 1, @date, @origin) UNION ALL SELECT 'Month', DATE_BUCKET (MONTH, 1, @date, @origin) UNION ALL SELECT 'Week', DATE_BUCKET (WEEK, 1, @date, @origin) --假如日期时间值如下: Now: 2019-09-28 13:45:23 --按年分组: DATE_BUCKET(YEAR, 1, @date, @origin) 从 2019-01-28 13:45:23 开始的年度存储桶,2019-09-28 落入 2019-01-28 至 2020-01-28 的存储桶中。 结果:2019-01-28 13:45:23 --按季度分组: DATE_BUCKET(QUARTER, 1, @date, @origin) 从 2019-01-28 13:45:23 开始的季度存储桶,每个季度 3 个月。 2019-09-28 落入第三个季度存储桶(即从 2019-07-28 13:45:23 到 2019-10-28 13:45:23)。 结果:2019-07-28 13:45:23 --按月分组: DATE_BUCKET(MONTH, 1, @date, @origin) 从 2019-01-28 13:45:23 开始的月度存储桶,每个月一个存储桶。 2019-09-28 落入第九个存储桶(即从 2019-09-28 13:45:23 到 2019-10-28 13:45:23)。 结果:2019-09-28 13:45:23 --按周分组: DATE_BUCKET(WEEK, 1, @date, @origin) 从 2019-01-28 13:45:23 开始的每周存储桶。 2019-09-28 落入从 2019-09-23 13:45:23 到 2019-09-30 13:45:23 的存储桶。 结果:2019-09-23 13:45:23

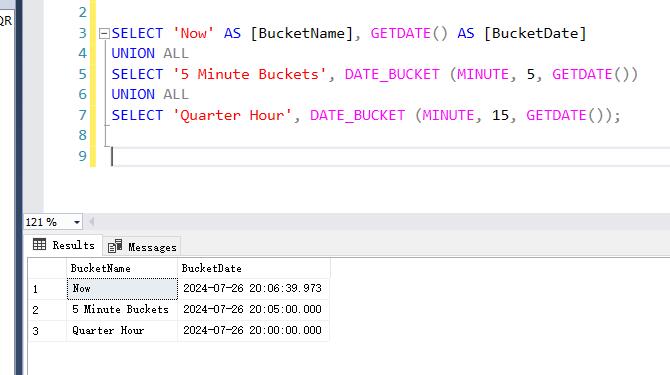
SELECT 'Now' AS [BucketName], GETDATE() AS [BucketDate] UNION ALL SELECT '5 Minute Buckets', DATE_BUCKET (MINUTE, 5, GETDATE()) UNION ALL SELECT 'Quarter Hour', DATE_BUCKET (MINUTE, 15, GETDATE()); Now: BucketName: Now BucketDate: 2024-07-26 16:14:11.030 这是当前时间,即 GETDATE() 返回的系统当前时间。 5 Minute Buckets: BucketName: 5 Minute Buckets BucketDate: 2024-07-26 16:10:00.000 这是将当前时间按 5 分钟间隔进行分组的结果。DATE_BUCKET(MINUTE, 5, GETDATE()) 返回当前时间所在的 5 分钟区间的起始时间。在这个例子中,16:14:11 落在 16:10:00 到 16:15:00 之间,因此返回 16:10:00。 Quarter Hour: BucketName: Quarter Hour BucketDate: 2024-07-26 16:00:00.000 这是将当前时间按 15 分钟间隔进行分组的结果。DATE_BUCKET(MINUTE, 15, GETDATE()) 返回当前时间所在的 15 分钟区间的起始时间。在这个例子中,16:14:11 落在 16:00:00 到 16:15:00 之间,因此返回 16:00:00。
更多实际场景示例
按自定义起始日期分组
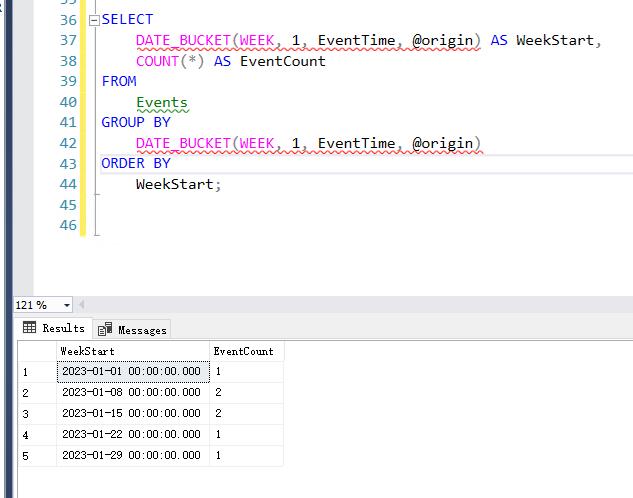
假设我们有一系列事件时间 EventTime,希望从'2023-01-01'日期开始,每周进行分组统计事件数量。
--创建表 Events: USE [testdb] GO CREATE TABLE Events ( EventID INT PRIMARY KEY, EventTime DATETIME ); INSERT INTO Events (EventID, EventTime) VALUES (1, '2023-01-02 14:30:00'), (2, '2023-01-08 09:15:00'), (3, '2023-01-09 17:45:00'), (4, '2023-01-15 12:00:00'), (5, '2023-01-16 08:00:00'), (6, '2023-01-22 19:30:00'), (7, '2023-01-29 11:00:00'); --从'2023-01-01'起始日期开始,每周进行分组统计事件数量。 DECLARE @origin DATETIME = '2023-01-01'; SELECT DATE_BUCKET(WEEK, 1, EventTime, @origin) AS WeekStart, COUNT(*) AS EventCount FROM Events GROUP BY DATE_BUCKET(WEEK, 1, EventTime, @origin) ORDER BY WeekStart;
按自定义时间间隔分组
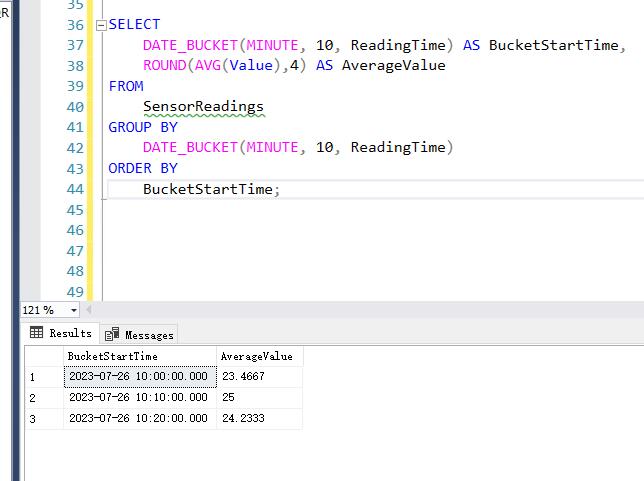
假设我们有一个传感器数据表 SensorReadings
USE [testdb] GO CREATE TABLE SensorReadings ( ReadingID INT PRIMARY KEY, --唯一标识 ReadingTime DATETIME, --读数的时间 Value FLOAT --读数的值 ); INSERT INTO SensorReadings (ReadingID, ReadingTime, Value) VALUES (1, '2023-07-26 10:03:00', 23.5), (2, '2023-07-26 10:05:00', 24.1), (3, '2023-07-26 10:09:00', 22.8), (4, '2023-07-26 10:15:00', 25.0), (5, '2023-07-26 10:20:00', 23.9), (6, '2023-07-26 10:27:00', 24.3), (7, '2023-07-26 10:29:00', 24.5); --我们希望按 10 分钟的间隔将数据分组,并计算每个间隔的平均读数值。 SELECT DATE_BUCKET(MINUTE, 10, ReadingTime) AS BucketStartTime, ROUND(AVG(Value),4) AS AverageValue FROM SensorReadings GROUP BY DATE_BUCKET(MINUTE, 10, ReadingTime) ORDER BY BucketStartTime;
如果是传统方法需要使用公用表表达式CTE才能完成这个需求
--查询:按 10 分钟间隔分组并计算平均值 WITH TimeIntervals AS ( SELECT ReadingID, ReadingTime, Value, --将分钟数归约到最近的 10 分钟的整数倍, 从2010年到现在有多少个10分钟区间 DATEADD(MINUTE, (DATEDIFF(MINUTE, '2000-01-01', ReadingTime) / 10) * 10, '2010-01-01') AS BucketStartTime FROM SensorReadings ) SELECT BucketStartTime, ROUND(AVG(Value), 4) AS AverageValue FROM TimeIntervals GROUP BY BucketStartTime ORDER BY BucketStartTime;
WITH TimeIntervals AS (...)公共表表达式(CTE)用于计算每条记录的 BucketStartTime。
DATEDIFF(MINUTE, '2000-01-01', ReadingTime) / 10 计算 ReadingTime 到基准时间 '2000-01-01' 的分钟数,然后除以 10,得到当前时间点所在的 10 分钟区间的索引。
DATEADD(MINUTE, ..., '2000-01-01') 将该索引转换回具体的时间点,即区间的起始时间。
查询主部分:
选择 BucketStartTime 和相应区间内读数值的平均值。
使用 GROUP BY 按 BucketStartTime 分组,并计算每个分组的平均值。
ORDER BY 用于按照时间顺序排列结果。
FIRST_VALUE 和 LAST_VALUE 窗口函数
在 之前版本的SQL Server 中,FIRST_VALUE 和 LAST_VALUE 是窗口函数,用于在一个分区或窗口中返回第一个或最后一个值。
SQL Server 2022 引入了新的选项 IGNORE NULLS 和 RESPECT NULLS 来处理空值(NULL)的方式,从而增强了这些函数的功能。
基本语法
FIRST_VALUE 返回指定窗口或分区中按指定顺序的第一个值。 FIRST_VALUE ( [scalar_expression ] ) OVER ( [ partition_by_clause ] order_by_clause [ rows_range_clause ] ) LAST_VALUE 返回指定窗口或分区中按指定顺序的最后一个值。 LAST_VALUE ( [scalar_expression ] ) OVER ( [ partition_by_clause ] order_by_clause [ rows_range_clause ] ) 新功能:IGNORE NULLS 和 RESPECT NULLS IGNORE NULLS: 忽略分区或窗口中的 NULL 值。 RESPECT NULLS: 默认行为,包含分区或窗口中的 NULL 值。
示例
假设我们有一个表 MachineTelemetry,包含以下数据:
CREATE TABLE MachineTelemetry ( [timestamp] DATETIME, SensorReading FLOAT ); INSERT INTO MachineTelemetry ([timestamp], SensorReading) VALUES ('2023-07-26 10:00:00', 23.5), ('2023-07-26 10:00:15', 24.1), ('2023-07-26 10:00:30', NULL), ('2023-07-26 10:00:45', 25.0), ('2023-07-26 10:01:00', NULL), ('2023-07-26 10:01:15', 23.9), ('2023-07-26 10:01:30', NULL), ('2023-07-26 10:01:45', 24.3);
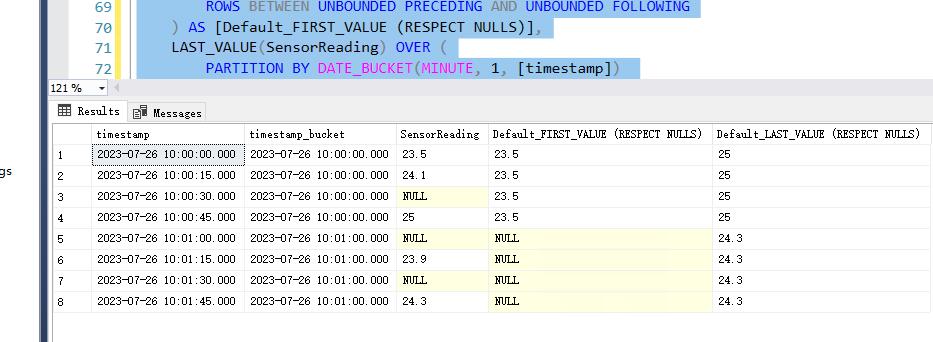
默认行为(包含 NULL 值)
--使用 FIRST_VALUE 和 LAST_VALUE 进行差距分析 --默认行为(包含 NULL 值) SELECT [timestamp], DATE_BUCKET(MINUTE, 1, [timestamp]) AS [timestamp_bucket], SensorReading, FIRST_VALUE(SensorReading) OVER ( PARTITION BY DATE_BUCKET(MINUTE, 1, [timestamp]) ORDER BY [timestamp] ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS [Default_FIRST_VALUE (RESPECT NULLS)], LAST_VALUE(SensorReading) OVER ( PARTITION BY DATE_BUCKET(MINUTE, 1, [timestamp]) ORDER BY [timestamp] ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS [Default_LAST_VALUE (RESPECT NULLS)] FROM MachineTelemetry ORDER BY [timestamp];
忽略 NULL 值
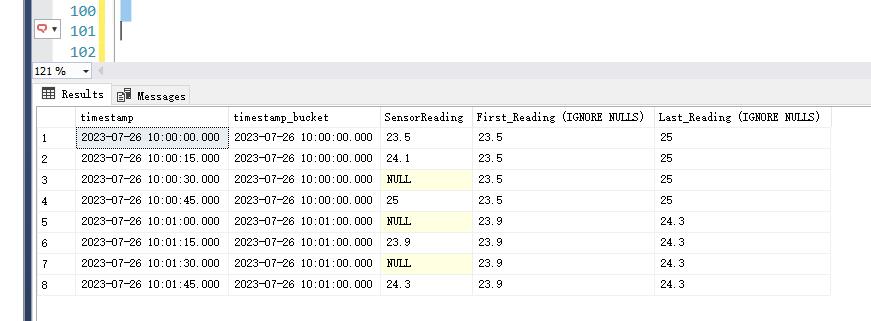
--忽略 NULL 值 SELECT [timestamp], DATE_BUCKET(MINUTE, 1, [timestamp]) AS [timestamp_bucket], SensorReading, FIRST_VALUE(SensorReading) IGNORE NULLS OVER ( PARTITION BY DATE_BUCKET(MINUTE, 1, [timestamp]) ORDER BY [timestamp] ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS [First_Reading (IGNORE NULLS)], LAST_VALUE(SensorReading) IGNORE NULLS OVER ( PARTITION BY DATE_BUCKET(MINUTE, 1, [timestamp]) ORDER BY [timestamp] ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS [Last_Reading (IGNORE NULLS)] FROM MachineTelemetry ORDER BY [timestamp];
总结
实际上,对于时间序列我们一般使用专业的时间序列数据库,例如InfluxDB 。
它使用 TSM(Time-Structured Merge Tree)作为存储引擎称,这是 LSM 树的一种变体,专门优化用于时间序列数据的写入和查询性能。
另外,SQL Server 的时间序列功能是使用行存储引擎(Row Store)作为其存储引擎,这意味着数据是按行进行存储和处理的。
在大部分场景下面,如果性能不是要求非常高,其实SQL Server 存储时间序列数据性能是完全足够的,而且额外使用InfluxDB数据库需要维护多一个技术栈,对运维要求更加高。
特别是现在追求数据库一体化的趋势背景下,无论是时间序列数据,向量数据,地理数据,json数据都最好在一个数据库里全部满足,减轻运维负担,复用技术栈,减少重复建设成本是比较好的解决方案。
参考文章
https://sqlbits.com/sessions/event2024/Time_Series_with_SQL_Server_2022
https://www.microsoft.com/en-us/sql-server/blog/2023/01/12/working-with-time-series-data-in-sql-server-2022-and-azure-sql/
https://www.mssqltips.com/sqlservertip/6232/load-time-series-data-with-sql-server/
本文版权归作者所有,未经作者同意不得转载。