Pulsar 入门实战(1)--Pulsar 消息传递
本文主要介绍 Pulsar 消息传递的相关概念,对应的 pulsar 版本为 3.3.x。
1、概述
Pulsar 基于发布-订阅模式构建。在这种模式中,生产者将消息发布到主题;消费者订阅这些主题,处理传入的消息,并在处理完成后向 broker 发送确认。

当创建订阅时,即使消费者断开连接,Pulsar 也会保留所有消息。只有当消费者确认所有这些消息都已成功处理后,保留的消息才会被丢弃。
如果消息消费失败并且希望重新消费该消息,可以启用消息重投递机制,让 broker 重新发送该消息。
2、消息
消息是 Pulsar 的基本“单元”。它们是生产者发布到主题的内容,也是消费者从主题中消费的内容。下表列出了消息的组成部分。
| 组件 | 说明 |
| Value / data payload | 消息的内容 |
| Key | 消息的 key |
| Properties | 消息的属性,用户定义的键值对 |
| Producer name | 生产者的名称,如果没有指定,将自动生成 |
| Topic name | 主题名称 |
| Schema version | 消息所使用模式的版本号 |
| Sequence ID | 消息的序列 ID |
| Message ID | 消息 ID |
| Publish time | 消息发布的时间戳 |
| Event time | 由应用程序附加到消息上的可选时间戳。例如,应用程序可以附加消息处理的时间戳。默认为 0。 |
消息的默认最大大小为 5 MB。可以修改如下配置来调整消息的最大大小:
A、broker.conf
# The max size of a message (in bytes). maxMessageSize=5242880
B、bookkeeper.conf
# The max size of the netty frame (in bytes). Any messages received larger than this value are rejected. The default value is 5 MB. nettyMaxFrameSizeBytes=5253120
2.1、Acknowledgment(消息确认)
消费者在成功消费一条消息后,会向 broker 发送一条消息确认。消息会被永久存储,直到所有订阅已确认该消息后才会被删除。确认(ack)是Pulsar判断消息可以从系统中删除的一种方式。如果您想存储已被消费者确认的消息,需要配置消息保留策略。
对于批量消息,可以启用批量索引确认以避免向消费者重新发送已确认的消息。
消息可以通过以下两种方式进行确认:
- 单独确认 消费者对每条消息进行确认,向 broker 发送确认请求。
- 累计确认 消费者只确认它接收到的最后一条消息。在流中,直到(包括)提供的那条消息为止,所有消息都不会重新投递给该消费者。
单独确认 API:
consumer.acknowledge(msg);
累计确认 API:
consumer.acknowledgeCumulative(msg);
注意:累计确认不能用于共享(Shared)或键共享(Key_Shared)订阅类型,因为共享或键共享订阅类型涉及多个消费者访问相同的订阅。在共享订阅类型中,消息是单独确认的。
2.2、Negative acknowledgment(否定确认)
否定确认机制允许向 broker 发送通知,指示消费者未处理某条消息。当消费者未能成功消费一条消息并需要重新消费时,消费者会向 broker 发送一个否定确认(nack),触发 broker 将这条消息重新投递给消费者。
根据订阅类型不同,消息可以以单独或累积方式进行否定确认。
在 Exclusive 和 Failover 订阅类型中,消费者可用累计方式进行否定确认。
在 Shared 和 Key_Shared 订阅类型中,消费者可可用单独方式进行否定确认。
在有序订阅类型(如 Exclusive、Failover 和 Key_Shared)上使用否定确认可能会导致失败的消息按非原始顺序发送给消费者。
如果你打算对某条消息使用否定确认,请确保在确认超时之前进行否定确认。
否定确认 API:
Consumer<byte[]> consumer = pulsarClient.newConsumer() .topic(topic) .subscriptionName("sub-negative-ack") .subscriptionInitialPosition(SubscriptionInitialPosition.Earliest) .negativeAckRedeliveryDelay(2, TimeUnit.SECONDS) // the default value is 1 min .subscribe(); Message<byte[]> message = consumer.receive(); // call the API to send negative acknowledgment consumer.negativeAcknowledge(message); message = consumer.receive(); consumer.acknowledge(message);
要以不同的延迟重新投递消息,你可以通过设置消息重投次数来使用重投递退避机制。
Consumer<byte[]> consumer = pulsarClient.newConsumer() .topic(topic) .subscriptionName("sub-negative-ack") .subscriptionInitialPosition(SubscriptionInitialPosition.Earliest) .negativeAckRedeliveryBackoff(MultiplierRedeliveryBackoff.builder() .minDelayMs(1000) .maxDelayMs(60 * 1000) .multiplier(2) .build()) .subscribe();
消息重投时延如下:
| 重投消息数 | 重投时延 |
| 1 | 1 秒 |
| 2 | 2 秒 |
| 3 | 4 秒 |
| 4 | 8 秒 |
| 5 | 16 秒 |
| 6 | 32 秒 |
| 7 | 60 秒 |
| 8 | 60 秒 |
注意:如果启用了批处理,批处理中的所有消息都会重新投递给消费者。
2.3、Acknowledgment timeout(确认超时)
注意:默认情况下,确认超时是禁用的,这意味着发送给消费者的消息不会被重新投递,除非消费者崩溃。
确认超时机制允许你设置一个时间,用于客户端跟踪未确认的消息。在达到确认超时时间(ackTimeout)后,客户端会向 broker 发送重新投递未确认消息的请求,从而使 broker 将未确认的消息重新发送给消费者。
你可以配置确认超时机制,在 ackTimeout 之后重新投递消息,定时任务会在每个 ackTimeoutTickTime 周期检查确认超时的消息。
你还可以使用重投递回退机制,通过设置消息重投的次数,以不同的延迟时间重新投递消息。
重投递回退机制 API:
consumer.ackTimeout(10, TimeUnit.SECOND) .ackTimeoutRedeliveryBackoff(MultiplierRedeliveryBackoff.builder() .minDelayMs(1000) .maxDelayMs(60 * 1000) .multiplier(2) .build());
消息重投时延如下:
| 重投消息数 | 重投时延 |
| 1 | 10 + 1 秒 |
| 2 | 10 + 2 秒 |
| 3 | 10 + 4 秒 |
| 4 | 10 + 8 秒 |
| 5 | 10 + 16 秒 |
| 6 | 10 + 32 秒 |
| 7 | 10 + 60 秒 |
| 8 | 10 + 60 秒 |
注意:
如果启用了批处理,一个批次中的所有消息都会重新投递给消费者。
与确认超时相比,否定确认是首选。首先,设置超时值很困难。其次,当消息处理时间超过确认超时时,broker 会重新发送消息,但这些消息可能不需要被重新消费。
确认超时 API:
Consumer<byte[]> consumer = pulsarClient.newConsumer() .topic(topic) .ackTimeout(2, TimeUnit.SECONDS) // the default value is 0 .ackTimeoutTickTime(1, TimeUnit.SECONDS) //定时检查确认超时消息的时间间隔 .subscriptionName("sub") .subscriptionInitialPosition(SubscriptionInitialPosition.Earliest) .subscribe(); Message<byte[]> message = consumer.receive(); // wait at least 2 seconds message = consumer.receive(); consumer.acknowledge(message);
2.4、Retry letter topic(重试信主题)
重试信主题允许你存储未能被消费的消息,并在稍后重新尝试消费它们。通过这种方法,你可以自定义消息重新投递的间隔。原始主题上的消费者也会自动订阅重试消息主题。一旦达到最大重试次数,未被消费的消息将被移动到一个死信主题进行手动处理。重试信主题的功能是由消费者实现的。
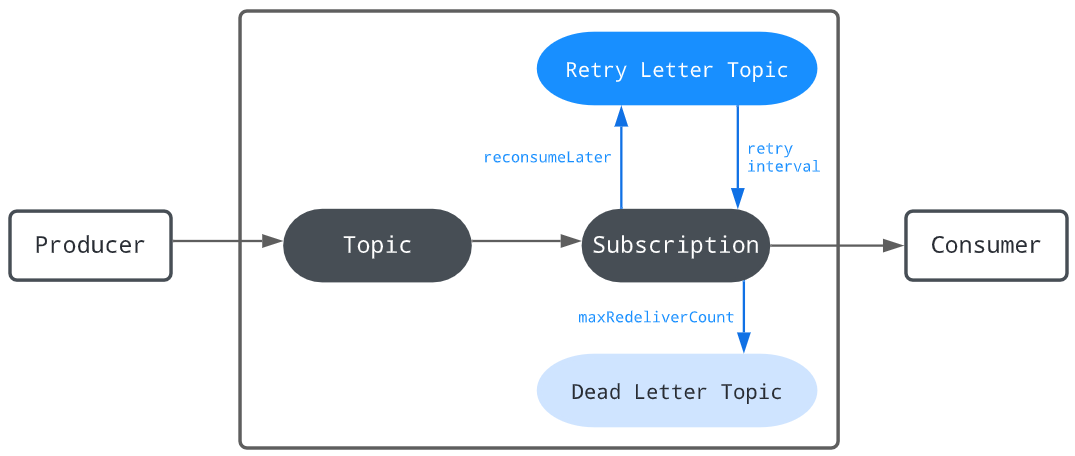
使用重试信主题与使用延迟消息传递的意图不同,尽管它们都旨在稍后消费消息。重试信主题通过消息重新投递来处理失败,以确保关键数据不会丢失,而延迟消息传递则旨在在指定的延迟时间传递消息。
默认情况下,重试是禁用的。你可以将 enableRetry 设置为 true,以在消费者上启用重试功能。
可用使用以下 API 来从重试信主题消费消息;当达到 maxRedeliverCount 的值时,未被消费的消息将会被移动到死信主题。
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES) .topic("my-topic") .subscriptionName("my-subscription") .subscriptionType(SubscriptionType.Shared) .enableRetry(true) .deadLetterPolicy(DeadLetterPolicy.builder() .maxRedeliverCount(maxRedeliveryCount) .build()) .subscribe();
默认的重试信主题格式如下:
<topicname>-<subscriptionname>-RETRY
通过代码指定重试信主题:
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES) .topic("my-topic") .subscriptionName("my-subscription") .subscriptionType(SubscriptionType.Shared) .enableRetry(true) .deadLetterPolicy(DeadLetterPolicy.builder() .maxRedeliverCount(maxRedeliveryCount) .retryLetterTopic("my-retry-letter-topic-name") .build()) .subscribe();
重试信主题中的消息包含一些特殊属性,这些属性是由客户端自动创建的。
| 属性 | 描述 |
| REAL_TOPIC | 实际的主题 |
| ORIGIN_MESSAGE_ID | 消息原始 message ID |
| RECONSUMETIMES | 消费消息的重试次数 |
| DELAY_TIME | 消息重试间隔,单位为毫秒 |
可使用以下 API 将消息存储在重试信主题中:
consumer.reconsumeLater(msg, 3, TimeUnit.SECONDS);
可以使用以下 API 添加自定义属性。在下一次消费时,可以通过 message#getProperty 获取自定义属性。
Map<String, String> customProperties = new HashMap<String, String>(); customProperties.put("custom-key-1", "custom-value-1"); customProperties.put("custom-key-2", "custom-value-2"); consumer.reconsumeLater(msg, customProperties, 3, TimeUnit.SECONDS);
注意:目前,在共享订阅类型中启用了重试主题。 与否定确认相比,重试信主题更适合需要大量重试且具有可配置重试间隔的消息。因为重试主题中的消息被持久化到了 BookKeeper,而因否定确认需要重试的消息则被缓存在客户端。
2.5、Dead letter topic(死信主题)
死信主题允许您在某些消息未成功消费时继续消息的消费。那些未能成功消费的消息会被存储在一个特定的主题中,称为死信主题。死信主题的功能由消费者实现。您可以决定如何处理死信主题中的消息。
启用默认的死信主题:
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES) .topic("my-topic") .subscriptionName("my-subscription") .subscriptionType(SubscriptionType.Shared) .deadLetterPolicy(DeadLetterPolicy.builder() .maxRedeliverCount(maxRedeliveryCount) .build()) .subscribe();
默认死信主题格式如下:
<topicname>-<subscriptionname>-DLQ
死信主题的生产者名称格式如下:
<topicname>-<subscriptionname>-<consumername>-DLQ
指定死信主题名称:
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES) .topic("my-topic") .subscriptionName("my-subscription") .subscriptionType(SubscriptionType.Shared) .deadLetterPolicy(DeadLetterPolicy.builder() .maxRedeliverCount(maxRedeliveryCount) .deadLetterTopic("my-dead-letter-topic-name") .build()) .subscribe();
默认情况下,在创建 DLQ 主题时不会创建订阅。如果在 DLQ 主题上没有即时订阅,可能会丢失消息。为了自动创建 DLQ 的初始订阅,您可以指定 initialSubscriptionName 参数。如果设置了这个参数,但是 Broker 的 allowAutoSubscriptionCreation 被禁用,DLQ 的生产者将无法创建。
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES) .topic("my-topic") .subscriptionName("my-subscription") .subscriptionType(SubscriptionType.Shared) .deadLetterPolicy(DeadLetterPolicy.builder() .maxRedeliverCount(maxRedeliveryCount) .deadLetterTopic("my-dead-letter-topic-name") .initialSubscriptionName("init-sub") .build()) .subscribe();
initialSubscriptionName 只是为了消息不丢失创建的订阅,并不是本消费者订阅了该死信主题;需要另外写程序处理死信主题中的消息或手工处理。
死信主题用于保存未成功消费的消息,触发条件包括确认超时、否定确认或重试信主题。
注意:目前,死信主题已在共享(Shared)和键共享(Key_Shared)订阅类型中启用。
2.6、Compression(压缩)
消息压缩可以通过小号一些 CPU 开销来减小消息大小。Pulsar 客户端支持的压缩类型:LZ4、ZLIB、ZSTD、SNAPPY。
压缩类型存储在消息的元数据中,因此消费者可以根据需要自动采用不同的压缩类型。
生产者中启用压缩:
client.newProducer() .topic("topic-name") .compressionType(CompressionType.LZ4) .create();
2.7、Batching(批处理)
当启用批处理时,生产者会累积并在单个请求中发送一批消息。批量大小由最大消息数和最大发布延迟定义。因此,积压大小表示的是批的总数,而不是消息的总数。

在 Pulsar 中,批次被作为单个单位进行跟踪和存储,而不是作为单独的消息。消费者将一个批次解开成单独的消息。然而,即使启用了批处理,通过 deliverAt 或 deliverAfter 参数配置的预定消息始终会作为单独的消息发送。
通常情况下,一个批次在所有消息被消费者确认后才会被确认。这意味着如果批次中不是所有消息都被确认,可能由于意外故障、否定确认(NACK)或确认超时,会导致重新投递该批次中的所有消息。
为了避免将已确认的批次消息重新投递给消费者,Pulsar 从版本 2.6.0 开始引入了批次索引确认功能。启用批次索引确认后,消费者会过滤已确认的批次索引,并向 broker 发送批次索引确认请求。broker 会维护批次索引的确认状态,并跟踪每个批次索引的确认状态,以避免向消费者分发已确认的消息。当批次中所有消息的索引都被确认时,该批次会被删除。
默认情况下,批次索引确认是禁用的(acknowledgmentAtBatchIndexLevelEnabled=false)。可以在 broker 中将 acknowledgmentAtBatchIndexLevelEnabled 参数设置为 true 来启用批次索引确认。启用批次索引确认会导致更多的内存开销。
批次索引确认还必须在消费者端通过调用 .enableBatchIndexAcknowledgment(true) 来启用:
Consumer<byte[]> consumer = pulsarClient.newConsumer() .topic(topicName) .subscriptionName(subscriptionName) .subscriptionType(subType) .enableBatchIndexAcknowledgment(true) .subscribe();
注意:异步发送消息(sendAsync)时批处理才会生效。
2.8、Chunking(分块)
消息分块允许 Pulsar 在生产者端将大消息分割成多个块,并在消费者端将分块的消息聚合起来处理。
启用消息分块后,当消息大小超过允许的最大有效载荷大小(即 broker 的 maxMessageSize 参数)时,消息传递的工作流程如下:
- 生产者将原始消息分割为分块消息(并带有分块元数据),将它们按顺序分别发送到 broker。
- broker 将分块消息以与普通消息相同的方式存储在同一管理 ledger 中,并使用 chunkedMessageRate 参数记录主题上的分块消息速率。
- 消费者缓存分块消息,在接收到消息的所有分块后,将分块消息聚合到接收队列中。
- 客户端从接收队列消费聚合后的消息。
注意:
分块仅适用于持久化主题。
分块不能与批处理同时启用。在启用分块之前,需要先禁用批处理。
2.8.1、使用有序消费者处理连续的分块消息
下图显示了一个主题,其中有一个生产者发布了分块消息和常规非分块消息。生产者将消息 M1 分为三个标记为 M1-C1、M1-C2 和 M1-C3 的分块消息。broker 将所有三个分块消息存储在管理 ledger 中,并按相同顺序将它们发送到有序(独占/故障转移)消费者。消费者在内存中缓冲分块消息,直到接收到所有分块消息,然后将它们聚合成一条消息,最后将原始消息 M1 交给客户端。

2.8.2、使用有序消费者处理交织的分块消息
当多个生产者将分块消息发布到单个主题时,broker 将来自不同生产者的所有分块消息存储在同一个管理 ledger 中。管理 ledger 中的分块消息可能会交织在一起。如下所示,生产者1将消息 M1 分为三个分块消息 M1-C1、M1-C2 和 M1-C3。生产者2将消息 M2 分为三个分块消息 M2-C1、M2-C2 和 M2-C3。特定消息的所有分块消息仍然是有序的,但在管理 ledger 中可能不是连续的。
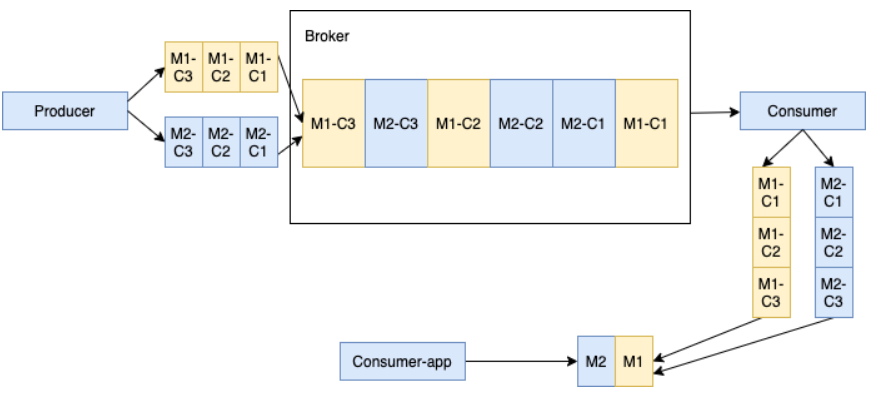
注意:在这种情况下,交织的分块消息可能会给消费者带来一些内存压力,因为消费者为每个大消息保留一个单独的缓冲区,以将其所有分块消息聚合成一条消息。你可以通过配置maxPendingChunkedMessage 参数来限制消费者同时维护的最大分块消息数。当达到阈值时,消费者通过静默确认来丢弃待处理的消息或请求 broker 稍后重新传递它们,以优化内存利用。
2.8.3、启用消息分块
前提:将 enableBatching 参数设置为 false 来禁用批处理。
消息分块功能默认处于关闭状态。要启用消息分块,在创建生产者时将 chunkingEnabled 设置为 true。
注意:如果消费者在指定时间(expireTimeOfIncompleteChunkedMessage)内未能接收到消息的所有分块,则未完成的分块将过期。过期时间默认值为 1 分钟。
3、主题
Pulsar 主题是一种存储单元,用于将消息组织成流。与其他发布-订阅系统类似,Pulsar 中的主题是用于从生产者传输消息到消费者的通道。主题名称是具有明确定义结构的 URL:
{persistent|non-persistent}://tenant/namespace/topic
| 主题名称组件 | 描述 |
| persistent/non-persistent | Pulsar 支持两种类型的主题:持久化主题和非持久化主题。默认情况下是持久化主题,对于持久化主题,所有消息都会持久化存储在磁盘上(如果 broker 不是独立的,消息将在多个磁盘上持久化存储),而非持久化主题的数据则不会持久化到存储磁盘上。 |
| tenant | 主题租户,租户在 Pulsar 中对于多租户架构至关重要。 |
| namespace | 主题命名空间,每个租户拥有一个或多个命名空间。 |
| topic | 主题名称 |
注意:在 Pulsar 中,你不需要显式地创建主题。如果客户端尝试向一个尚不存在的主题写入或接收消息,Pulsar 会自动创建该主题。如果客户端在创建主题时没有指定租户或命名空间,那么该主题会被创建在默认的租户和命名空间中。你也可以在指定的租户和命名空间中创建主题,例如 persistent://my-tenant/my-namespace/my-topic。
4、命名空间
Pulsar 命名空间是主题的逻辑分组,同时也是租户内的逻辑概率。租户通过管理 API 创建命名空间。例如,具有多个应用程序的租户可以为每个应用程序创建单独的命名空间。命名空间允许应用程序创建和管理主题的层次结构。例如,主题 my-tenant/app1 是租户 my-tenant 下应用程序 app1 的命名空间。你可以在命名空间下创建任意数量的主题。
5、订阅
Pulsar 订阅是一个命名的配置规则,确定消息如何传递给消费者。它是由一组消费者在主题上建立的租约。Pulsar 有四种订阅类型:
- 独占订阅(exclusive)
- 共享订阅(shared)
- 故障转移订阅(failover)
- 键共享(key_shared)
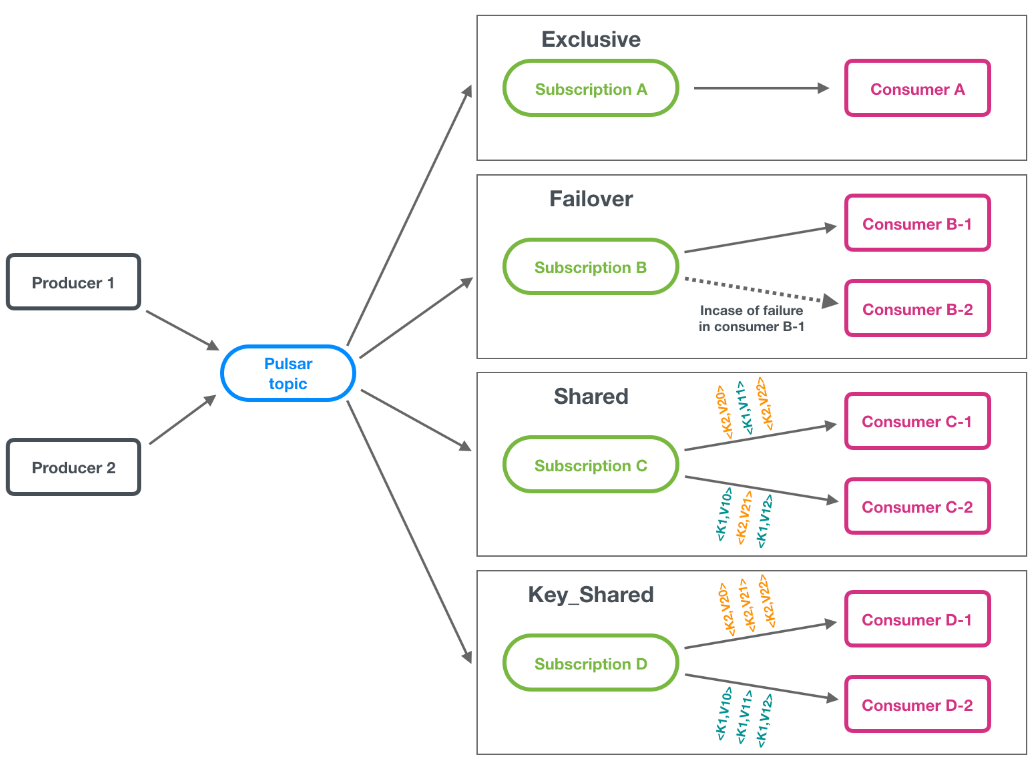
提示:
在 Pulsar 中,你可以灵活地使用不同的订阅来实现发布-订阅或队列的效果。
1、如果你希望在消费者之间实现传统的“广播式发布-订阅消息”,可以为每个消费者指定一个唯一的订阅名称,这是一种独占式订阅类型。
2、如果你希望在消费者之间实现“消息队列”,可以让多个消费者共享相同的订阅名称(共享订阅、故障转移订阅、键共享订阅)。
3、如果你希望同时实现这两种效果,可以将独占式订阅类型与其他订阅类型结合使用,为消费者创建不同的订阅。
5.1、订阅类型
当一个订阅没有消费者时,其订阅类型是未定义的。订阅的类型在有消费者连接时确定,并且可以通过重新启动所有消费者并使用不同的配置来更改订阅类型。
5.1.1、独占订阅(Exclusive)
独占订阅只允许单个消费者连接到该订阅。如果多个消费者使用相同的订阅名称订阅同一个主题,会发生错误。需要注意的是,如果主题是分区的,所有分区都将由允许连接到该订阅的单个消费者来消费。
在下图中,只有消费者A被允许消费消息。
提示:独占订阅是默认的订阅类型。

5.1.2、故障转移订阅(Failover)
故障转移订阅允许多个消费者连接到同一个订阅上。
对于非分区主题或分区主题的每个分区,会选择一个主消费者来接收消息。
当主消费者断开连接时,所有(未确认的和随后的)消息将被传递给下一个排队的消费者。
注意:在某些情况下,一个分区可能存在一个较旧的活动消费者在处理消息,同时一个新切换的活动消费者开始接收新消息。这可能导致消息重复或顺序错乱的问题发生。
故障转移 | 分区主题
对于分区主题,broker 按照消费者的优先级和消费者名称的词典顺序进行排序。broker 尝试将分区均匀地分配给优先级最高的消费者。消费者是通过运行一个模运算 mod(partition index, consumer index)来选择的。
A、如果分区主题中的分区数量少于消费者数量
例如,在下图中,这个分区主题有 2 个分区,并且有 4 个消费者。每个分区有 1 个活动消费者和 3 个备用消费者。
对于 P0,消费者A是主消费者,而消费者B、消费者C 和消费者D是备用消费者。
对于 P1,消费者B是主消费者,而消费者A、消费者C 和消费者D是备用消费者。
此外,如果消费者A和消费者B都断开连接,那么
对于 P0:消费者C是活动消费者,消费者D是备用消费者。
对于 P1:消费者D是活动消费者,消费者C是备用消费者。
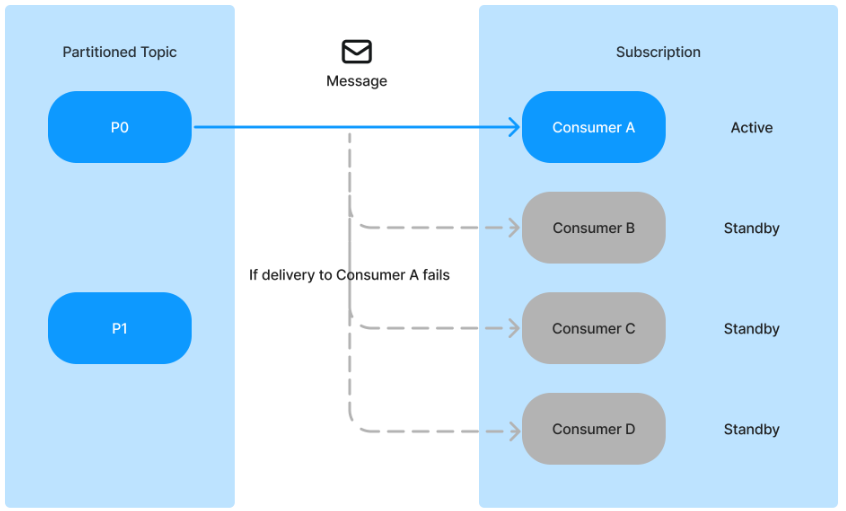

B、如果分区主题中的分区数量多于消费者数量
例如,在下图中,这个分区主题有 9 个分区和 3 个消费者。
P0、P3 和 P6 分配给消费者A。消费者A是它们的活跃消费者。消费者B和消费者C是它们的备用消费者。
P1、P4 和 P7 分配给消费者B。消费者B是它们的活跃消费者。消费者A和消费者C是它们的备用消费者。
P2、P5 和 P8 分配给消费者C。消费者C是它们的活跃消费者。消费者A和消费者B是它们的备用消费者。

故障转移 | 非分区主题
A、如果是一个非分区主题,那么 broker 会按照消费者订阅非分区主题的顺序选择它们。
例如,在下面的图表中,有 1 个非分区主题,2 个消费者。
该主题有 1 个活跃消费者和 1 个备用消费者。
消费者A是主要消费者,如果消费者A断开连接,消费者B将成为下一个接收消息的消费者。

B、如果存在多个非分区主题,消费者的选择是基于哈希消费者名称和哈希主题名称。客户端使用相同的订阅名称订阅所有主题。
例如,在下面的图表中,有 4 个非分区主题和 2 个消费者。
非分区主题 1 和非分区主题 4 分配给消费者 A。消费者 B 是它们的备用消费者。
非分区主题 2 和非分区主题 3 分配给消费者 B。消费者 A 是它们的备用消费者。

5.1.3、共享订阅(Shared)
Pulsar 中的共享订阅类型允许多个消费者连接到同一个订阅。消息以循环分发方式传送到各个消费者,并且每条消息只会传送到一个消费者那里。当一个消费者断开连接时,所有已发送但未被确认的消息将被重新安排发送给其余的消费者。
在下面的图表中,Consumer A、Consumer B 和 Consumer C 都可以订阅该主题。
注意:共享订阅不保证消息顺序或不支持累积确认。

5.1.4、键共享订阅(Shared)
Pulsar 中的建共享订阅类型允许多个消费者连接到同一个订阅。但与共享类型不同,键共享类型是把具有相同键或相同排序键的消息送给同一个消费者。无论消息被重新传递多少次,它都会传递给同一个消费者。

注意:
如果有新切换的活跃消费者,它将从旧的非活跃消费者确认消息的位置开始读取消息。
举例来说,如果 P0 被分配给 Consumer A。Consumer A 是活跃消费者,而 Consumer B 是备用消费者。
如果 Consumer A 断开连接而没有读取任何来自 P0 的消息,在添加 Consumer C 并使其成为新的活跃消费者后,Consumer C 将直接开始从 P0 读取消息。
如果Consumer A 在从 P0 读取消息(0,1,2,3)后断开连接,当添加 Consumer C 并使其成为活跃消费者后,Consumer C 将开始从 P0 读取消息(4,5,6,7)。
有三种映射算法决定如何为给定的消息键(或排序键)选择消费者:
- 自动分割哈希范围(Auto-split Hash Range)
- 自动分割一致性哈希(Auto-split Consistent Hashing)
- 粘性(Sticky)
每种算法都有其独特的方式来将消息分配给消费者,以确保消息的有效处理和负载均衡。
所有映射算法的步骤如下:
1、消息键(或排序键)传递给哈希函数(例如,Murmur3 32-bit),生成一个 32 位整数哈希值。
2、该哈希值传递给算法,从现有的连接消费者中选择一个消费者。
+--------------+ +-----------+ Message Key -----> / Hash Function / ----- hash (32-bit) -------> / Algorithm / ----> Consumer +---------------+ +----------+
当一个新的消费者连接并因此被添加到已连接消费者列表时,算法会重新调整映射,使当前映射到现有消费者的一些键被映射到新添加的消费者。当一个消费者断开连接并因此从已连接消费者列表中移除时,映射到该消费者的键将被映射到其他消费者。
Auto-split Hash Range
自动分割哈希范围(Auto-split Hash Range)假设每个消费者被映射到 0 到 2^16(65,536)范围内的某个区域;所有的映射区域覆盖整个范围,并且没有重叠。通过对消息哈希进行取模(取模的大小为65,536)运算,得到的数字(0 <= i < 65,536)包含在某个区域内;映射到该区域的消费者就是被选择的消费者。
例子:
假设我们有4个消费者(C1、C2、C3和C4),那么:
0 16,384 32,768 49,152 65,536 |------- C3 ------|------- C2 ------|------- C1 ------|------- C4 ------|
给定消息键 Order-3459134,其哈希值为 murmur32("Order-3459134") = 3112179635,它在范围内的索引为 3112179635 mod 65536 = 6067。该索引包含在区域 [0, 16384) 内,因此消费者 C3 将被映射到此消息键。
当一个新的消费者连接时,选择范围最大的区域,并将其一分为二——下半部分将映射到新添加的消费者,上半部分将映射到原来拥有该区域的消费者。以下是从 1 个消费者增加到 4 个消费者的情况:
C1 connected: |---------------------------------- C1 ---------------------------------| C2 connected: |--------------- C2 ----------------|---------------- C1 ---------------| C3 connected: |------- C3 ------|------- C2 ------|---------------- C1 ---------------| C4 connected: |------- C3 ------|------- C2 ------|------- C4 ------|------- C1 ------|
当一个消费者断开连接时,其区域将合并到其右侧的区域中。例子:
C4 断开连接:
|------- C3 ------|------- C2 ------|---------------- C1 ---------------|
C1 断开连接:
|------- C3 ------|-------------------------- C2 -----------------------|
这种算法的优点是在添加或删除消费者时只影响单个现有消费者,但代价是区域大小不均匀。这意味着某些消费者会获得比其他消费者更多的键。下一个算法则相反。
Auto-split Consistent Hashing
自动拆分一致性哈希(Auto-split Consistent Hashing)假设每个消费者被映射到一个哈希环中。哈希环是一个从 0 到 MAX_INT(32 位整数)的数值范围,当你遍历这个范围时,到达 MAX_INT 后,下一个数字将会是 0。这就好像把一条从 0 开始到 MAX_INT 结束的线弯成一个圆,使得终点与起点连接在一起:
MAX_INT -----++--------- 0 || , - ~ ~ ~ - , , ' ' , , , , , , , , , , , , , , , , , ' ' - , _ _ _ , '
当添加一个消费者时,我们在那个圆上标记 100 个点,并将它们与新添加的消费者关联。对于 1 到 100 之间的每个数字,我们将该数字与消费者名称连接起来,然后对其运行哈希函数,以获取将在圆上标记的点的位置。例如,如果消费者名称是 "orders-aggregator-pod-2345-consumer",那么我们会在圆上标记 100 个点:
murmur32("orders-aggregator-pod-2345-consumer1") = 1003084738 murmur32("orders-aggregator-pod-2345-consumer2") = 373317202 ... murmur32("orders-aggregator-pod-2345-consumer100") = 320276078
由于哈希函数具有均匀分布的属性,这些点将在圆上均匀分布。
通过将消息键的哈希值放置在圆上,然后顺时针沿着圆继续前进,直到到达一个标记点,来为给定的消息键选择一个消费者。该点可能会有多个消费者(哈希函数可能会产生碰撞),因此,我们运行以下操作来获取消费者列表中的一个消费者:hash % consumer_list_size = index。
当添加一个消费者时,我们会如前所述在圆上添加 100 个标记点。由于哈希函数的均匀分布,这 100 个点会使得新消费者从每个现有消费者中分出一小部分键。它保持了均匀分布,但代价是影响到所有现有的消费者。
Sticky
粘性(Sticky)假定每个消费者被映射到从 0 到 2^16(65,536)的某个区域,并且区域之间没有重叠。通过对消息哈希值进行模运算(除以范围大小 65,536),得到的数字(0 <= i < 65,536),将位于某个区域内;映射到该区域的消费者即为所选的消费者。
在这个算法中,你拥有完全的控制权。每个新添加的消费者可以通过 Consumer API 指定希望映射到的范围。你需要确保没有重叠,并且所有范围都被区域覆盖。
例子:
假设我们有两个消费者(C1 和 C2),每个消费者都指定了他们的范围,那么:
C1 = [0, 16384), [32768, 49152) C2 = [16384, 32768), [49152, 65536) 0 16,384 32,768 49,152 65,536 |------- C1 ------|------- C2 ------|------- C1 ------|------- C2 ------|
给定消息键 Order-3459134,其哈希值为 murmur32("Order-3459134") = 3112179635,其索引为 3112179635 mod 65536 = 6067。这个索引位于 [0, 16384) 范围内,因此这条消息将被路由到消费者 C1。
如果新连接的消费者没有提供其范围,或者其范围与现有消费者的范围重叠,那么该消费者将被断开连接,从消费者列表中移除,并且被视为从未尝试过连接。
如何使用映射算法?
要使用上述提到的映射算法,可以在构建消费者时指定 keySharedPolicy。
- AUTO_SPLIT - Auto-split Hash Range
- STICKY - Sticky
如果 broker 中启用了 subscriptionKeySharedUseConsistentHashing,则会使用一致性哈希(Consistent Hashing)来分割,而不是使用哈希范围(Hash Range)。
保持处理顺序
键共享订阅类型保证任何时刻一个关键字只会由一个消费者处理。当新的消费者连接时,一些关键字的映射将从现有消费者转移到新的消费者身上。连接建立后,broker 将记录当前的读取位置,并将其与新的消费者关联。读取位置是一个标记,表示这点及之前的消息已分发给消费者,此后的消息尚未被分发。只有当读取位置及之前的消息都被确认后,broker 才会向新的消费者传递消息。这将确保特定关键字在任何给定时间只由一个消费者处理。然而,这样做的代价是,如果现有的某个消费者卡住了且没有定义确认超时,新的消费者将无法收到任何消息,直到卡住的消费者恢复或断开连接。
可以通过 Consumer API 启用 allowOutOfOrderDelivery 来放宽这一要求。如果在新消费者上设置了这个选项,那么在它连接时,broker 将允许它接收消息,即使该关键字的某些消息在其他消费者中仍在处理中,因此在添加新消费者的短时间内可能会影响顺序。
键共享订阅批处理
注意:当消费者使用键共享订阅类型时,你需要禁用批处理或者为生产者使用基于关键字的批处理。
使用基于关键字的批处理在键共享订阅类型中是必要的,原因有两个:
1、broker 根据消息的键分发消息,但默认的批处理方法可能无法将具有相同键的消息打包到同一个批次中。
2、由于是消费者而不是 broker 从批次中分发消息,因此一个批次中第一条消息的键被视为该批次中所有消息的键,从而导致上下文错误。
基于关键字的批处理旨在解决上述问题。这种批处理方法确保生产者将具有相同键的消息打包到同一个批次中。没有键的消息被打包到一个批次中,这个批次没有键;当 broker 分发这个批次消息时,它会使用 NON_KEY 作为键。基于关键字的批处理,生成者的 batchingMaxMessages 参数是针对的所有不同 key 消息的总数,当消息达到该数量时将会按键分别打包发送。
以下是键共享订阅类型下启用基于键的批处理示例:
Producer<byte[]> producer = client.newProducer() .topic("my-topic") .batcherBuilder(BatcherBuilder.KEY_BASED) .create();
注意:
使用键共享订阅时,需注意以下几点:
1、你需要为消息指定一个键或排序键。
2、不能使用累积确认机制。
3、当主题中最新消息的位置为 X 时,新连接的键共享消费者将不会接收任何消息直到 X 之前(包括)的消息都被确认。
5.2、订阅模式
5.2.1、什么是订阅模式
订阅模式指示游标属于持久类型还是非持久类型。
当创建订阅时,会创建一个关联的游标来记录最后消费的位置。
当订阅的消费者重新启动时,它可以继续从上次消费的位置开始消费。
| 订阅模式 | 描述 | 注意 |
| 持久 | 光标是持久的,它会保留消息并持久化当前位置。代理因故障重新启动,可以从持久存储(BookKeeper)中恢复游标,使得可以从上次消费的位置继续消费消息。 | 默认的订阅模式 |
| 非持久 | 光标是非持久的。一旦 broker 停止运行,游标将丢失且无法恢复,因此无法继续从上次消费的位置消费消息。 | Reader 的订阅模式是非持久性的,并且不会阻止主题中的数据被删除。Reader 的订阅模式无法更改。 |
一个订阅可以有一个或多个消费者。当消费者订阅一个主题时,必须指定订阅名称。持久订阅和非持久订阅可以使用相同的名称,它们彼此独立。如果消费者指定了一个之前不存在的订阅,该订阅会自动创建。
5.2.2、什么时候使用
默认情况下,没有任何持久订阅的主题的消息会被标记为已删除。如果你希望阻止消息被标记为已删除,可以为该主题创建一个持久订阅。在这种情况下,只有被确认的消息才会被标记为已删除。更多信息,可参阅消息保留和过期。
5.2.3、如何使用
创建消费者后,消费者的订阅模式默认是持久的。可以通过更改消费者的配置将订阅模式更改为非持久。
Consumer<byte[]> consumer = pulsarClient.newConsumer() .topic("my-topic") .subscriptionName("my-sub") .subscriptionMode(SubscriptionMode.Durable) .subscribe();
关于如何创建、检查或删除持久订阅,可查看订阅管理。
6、多主题订阅
当消费者订阅主题时,默认情况下它订阅一个特定的主题,比如 persistent://public/default/my-topic。然而,从 Pulsar 1.23.0-incubating 开始,消费者可以同时订阅多个主题。您可以通过两种方式定义主题列表:
- 基于正则表达式(regex)来定义,例如 persistent://public/default/finance-.*
- 显式地定义一个主题列表
注意:当通过正则表达式订阅多个主题时,所有主题必须位于同一个命名空间。
当订阅多个主题时,Pulsar 客户端会自动发现与正则表达式或主题列表匹配的主题,然后订阅所有这些主题。如果其中某些主题不存在,消费者在主题被创建后会自动订阅它们。
注意:在多个主题之间没有顺序保证。当生产者向单个主题发送消息时,所有消息都保证按照发送顺序消费。然而,这些保证在多个主题之间并不适用。因此,当生产者向多个主题发送消息时,从这些主题读取消息的顺序不能保证是相同的。
多主题订阅示例:
import java.util.regex.Pattern; import org.apache.pulsar.client.api.Consumer; import org.apache.pulsar.client.api.PulsarClient; PulsarClient pulsarClient = // Instantiate Pulsar client object // Subscribe to all topics in a namespace Pattern allTopicsInNamespace = Pattern.compile("persistent://public/default/.*"); Consumer<byte[]> allTopicsConsumer = pulsarClient.newConsumer() .topicsPattern(allTopicsInNamespace) .subscriptionName("subscription-1") .subscribe(); // Subscribe to a subsets of topics in a namespace, based on regex Pattern someTopicsInNamespace = Pattern.compile("persistent://public/default/foo.*"); Consumer<byte[]> someTopicsConsumer = pulsarClient.newConsumer() .topicsPattern(someTopicsInNamespace) .subscriptionName("subscription-1") .subscribe();
7、分区主题
普通主题由单个 broker 提供服务,这限制了主题的吞吐量。分区主题是一种特殊类型的主题,由多个 broker 处理,因此允许更高的吞吐量。
分区主题被实现为 N 个内部主题,其中 N 是分区的数量。当向分区主题发布消息时,每条消息会被路由到多个 broker 中的一个。Pulsar 自动处理分区在各个 broker 之间的分布。
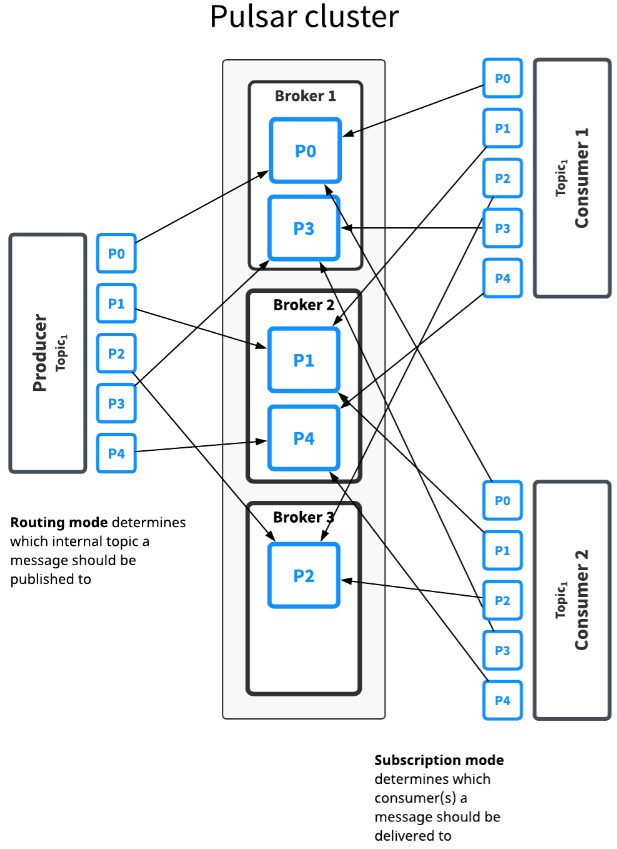
Topic1 主题有五个分区(P0到P4),分布在三个 broker 上。由于分区的数量多于 broker 的数量,其中两个 broker 每个处理两个分区,而第三个 broker 只处理一个分区(再次强调,Pulsar 会自动处理这些分区的分布)。
该主题的消息被广播给两个消费者。路由模式决定消息发布到哪个分区,而订阅类型决定消息发送给哪个消费者。
在大多数情况下,可以决定路由模式和订阅类型。通常,分区和路由模式应由吞吐量决定,而订阅类型则应由应用程序语义来决定。
分区主题需要通过 admin API 明确创建。在创建主题时可以指定分区的数量。
7.1、路由模式
| 模式 | 描述 |
| RoundRobinPartition |
如果没有提供键值,生产者将以轮询方式将消息发布到所有分区,以实现最大的吞吐量。启用批处理时,按批次消息轮询。如果在消息上指定了键值,分区生产者将对键值进行哈希处理,并将消息分配给特定的分区。这是默认模式。 |
| SinglePartition | 如果未提供键值,生产者将随机选择一个分区并将所有消息发布到该分区。而如果在消息上指定了键值,生产者将对键值进行哈希计算,并将消息发布到对应的分区。 |
| CustomPartition | 自定义消息路由器,可以实现 MessageRouter 接口来创建自定义的消息路由。 |
7.2、顺序保证
消息的顺序与消息路由模式和消息键密切相关。通常,用户希望 Per-key-partition 的顺序保证。
如果提供了键值,使用 RoundRobinPartition 或 SinglePartition 模式时,消息将通过哈希方案被路由到相应的分区。
| 顺序保证 | 描述 | 路由模式和键值 |
| Per-key-partition | 所有具有相同键的消息将按顺序发布到同一个分区中。 | 使用单分区模式(SinglePartition)或轮询分区模式(RoundRobinPartition),并且每条消息都提供了键值。 |
| Per-producer | 同一个生产者生产的消息是有序的。 | 使用单分区模式,并且每条消息都没有提供键值。 |
7.3、哈希方案
哈希方案是在选择消息的分区时可用的标准哈希函数集。有两种类型的标准哈希函数可供选择:
- JavaStringHash
- Murmur3_32Hash
生产者的默认哈希函数是 JavaStringHash。
8、非持久主题
默认情况下,Pulsar 会持久化存储所有未被确认的消息在多个 BookKeeper bookie(存储节点)上。因此,持久化主题上的消息数据可以在 broker 重启和订阅者故障转移时继续存在。
当然,Pulsar 也支持非持久化主题。非持久化主题是指消息数据永远不会被持久化存储到磁盘,而是仅保留在内存中。当使用非持久化主题时,关闭 broker 或断开订阅者与主题的连接会导致该主题上的所有在途消息丢失,这意味着客户端可能会看到消息丢失。
非持久化主题的名称通常是这种形式:
non-persistent://tenant/namespace/topic
在非持久化主题中,broker 会立即将消息传递给所有已连接的订阅者,而无需将它们持久化存储到 BookKeeper 中。如果订阅者断开连接,broker 将无法传递那些在途消息,订阅者也将无法再次接收到这些消息。省略持久化存储步骤在某些情况下使非持久化主题上的消息传递速度略快于持久化主题,但需要注意的是,这样做会丧失 Pulsar 的一些核心优势。
注意:对于非持久化主题,消息数据仅存在于内存中,没有特定的缓冲区,这意味着数据不会在内存中缓存。接收到的消息会立即传输给所有连接的消费者。如果 broker 发生故障或者消息数据无法从内存中获取,那么您的消息数据可能会丢失。只有当您确定使用案例确实需要时才使用它们。
默认情况下,broker 启用了非持久化主题,可以在 broker 的配置中禁用它们。可以使用 pulsar-admin topics 命令管理非持久化主题,详情请参阅 pulsar-admin。
目前,未分区的非持久化主题不会被持久化到 ZooKeeper 中。这意味着如果拥有它们的broker崩溃,它们不会被重新分配给另一个代理,因为它们只存在于原始代理的内存中。目前的解决方法是在 broker 的配置中将 allowAutoTopicCreation 的值设置为 true,并且将 allowAutoTopicCreationType 设置为 non-partitioned(这些是默认值)。
8.1、性能
持久化主题中,所有消息都会持久化存储在磁盘上,而非持久化主题中,broker 不会持久化消息,并在消息传递到 broker 后立即向生产者发送确认信息,因此非持久化消息通常比持久化消息传递速度更快。因此,生产者在非持久化主题中通常有较低的发布延迟。
8.2、客户端 API
生产者和消费者可以以与持久化主题相同的方式连接到非持久化主题,但关键的区别在于主题名称必须以 non-persistent 开头。所有订阅类型——独占、共享、键共享和故障转移——都支持非持久化主题。
这里是一个非持久化主题的消费者示例:
PulsarClient client = PulsarClient.builder() .serviceUrl("pulsar://localhost:6650") .build(); String npTopic = "non-persistent://public/default/my-topic"; String subscriptionName = "my-subscription-name"; Consumer<byte[]> consumer = client.newConsumer() .topic(npTopic) .subscriptionName(subscriptionName) .subscribe();
这里是同一个非持久化主题的生产者示例:
Producer<byte[]> producer = client.newProducer() .topic(npTopic) .create();
8、系统主题
系统主题是 Pulsar 内部预定义的主题,用于内部使用。它可以是持久化或非持久化主题。
系统主题用于实现某些功能,并消除对第三方组件的依赖,例如事务、心跳检测、主题级策略和资源组服务。系统主题使这些功能的实现变得简化、依赖性降低和灵活性增强。以心跳检测为例,可以利用系统主题进行健康检查,内部使用生产者/读者在心跳命名空间下生产/消费消息,从而检测当前服务是否仍然存活。
以下表格列出了每个特定命名空间的系统主题。
| 命名空间 | 主题名称 | 是否持久主题 | 数量 | 用途 |
| pulsar/system | transaction_coordinator_assign_${id} | 持久主题 | 默认 16 | 事务协调器 |
| pulsar/system | __transaction_log_${tc_id} | 持久主题 | 默认 16 | 事务日志 |
| pulsar/system | resource-usage | 非持久主题 | 默认 4 | 资源组服务 |
| host/port | heartbeat | 持久主题 | 1 | 心跳检测 |
| User-defined-ns | __change_events | 持久主题 | 默认 4 | 主题事件 |
| User-defined-ns | __transaction_buffer_snapshot Persistent | 持久主题 | 每个命名空间一个 | 事务缓冲区快照 |
| User-defined-ns | ${topicName}__transaction_pending_ack | 持久主题 | 一个订阅的事务确认一个 | 事务确认 |
注意:
1、不能创建系统主题。要列出系统主题,可以在使用管理 API 获取主题列表时添加 --include-system-topic 选项。
2、从 2.11.0 开始,系统主题默认启用。在早期版本中,需要修改 conf/broker.conf 或 conf/standalone.conf 文件中的以下配置以启用系统主题。
systemTopicEnabled=true topicLevelPoliciesEnabled=true
9、消息重投递
Apache Pulsar 支持优雅的故障处理,并确保关键数据不会丢失。软件总是会出现意外情况,有时消息可能无法成功传递。因此,拥有处理失败的内置机制尤为重要,特别是在异步消息传递中,如下例所示。
- 消费者与数据库或 HTTP 服务器断开连接时,会导致以下情况发生:数据库在消费者向其写入数据时暂时离线,消费者调用的外部 HTTP 服务器暂时不可用。
- 消费者由于消费者崩溃、连接中断等原因与 broker 断开连接时,会导致以下结果:未确认的消息会传递给其他可用的消费者。
在 Apache Pulsar 中,消息重新投递通过至少投递一次语义来避免异步消息传递中的失败,确保 Pulsar 会多次处理消息。
要使用消息重新投递功能,需要在客户端中启用此机制。可以通过三种方法激活消息重新投递功能。
- 否定确认
- 确认超时
- 重试信主题
10、消息保留和过期
默认情况下,broker 会执行以下动作:
- 立即删除所有已被消费者确认的消息
- 将所有未被确认的消息持久化存储在消息日志中。
然而,Pulsar 有两个特性可以覆盖这种默认行为:
- 消息保留允许存储已被消费者确认的消息。
- 消息过期允许为尚未被确认的消息设置生存时间(TTL)。
注意:所有消息的保留和过期管理都在命名空间级别进行。如需操作指南,请参阅消息保留和过期。

通过消息保留,对于命名空间中的所有主题,某些消息即使已经确认,也会在 Pulsar 中持久存储。未涵盖保留策略的已确认消息将被删除。如果没有保留策略,所有已确认的消息将被删除。
对于消息过期,一些消息会被删除,即使它们尚未被确认,因为它们根据 TTL 已经过期(例如,应用了 5 分钟的 TTL,消息虽然未被确认,但已经存在 10 分钟)。
11、消息去重
消息重复发生在 Pulsar 多次持久化同一条消息时。消息去重确保每条消息只被持久化到磁盘一次,即使消息被生产多次也是如此。消息去重在服务器端自动处理。
以下图表说明了当消息去重功能禁用和启用时会发生的情况:

消息去重功能禁用时,生产者在主题上发布消息1;消息到达 broker 并被持久化到 BookKeeper。然后,生产者再次发送消息1(可能是由于某些重试逻辑),broker 接收消息并再次存储到 BookKeeper,这意味着发生了重复。
消息去重功能启用时,生产者发布消息1,该消息被 broker 接收并持久化。当生产者尝试再次发布相同的消息时,broker 知道它已经接受到消息1,因此不会再次将该消息持久化。
注意:
11.1、生产者幂等性
消息去重的另一种方法是生产者幂等性,这意味着每条消息只会被生产一次,避免了数据丢失和重复。这种方法的缺点是将消息去重的工作放到了应用程序中。在 Pulsar 中,这是在 broker 层级处理的,因此无需修改 Pulsar 客户端代码,只需要进行管理上的更改。
11.2、去重和一次有效语义
消息去重使 Pulsar 成为理想的消息传递系统,可以与流处理引擎(spe)和其他寻求提供一次有效处理语义的系统一起配合使用。那些不提供自动消息去重功能的消息传递系统需要由 SPE 或其他系统来保证去重,这意味着严格的消息顺序需要应用程序承担去重的责任。而在 Pulsar 中,严格的顺序保证不会增加应用程序的成本。
12、延迟消息投递
延迟消息投递允许稍后消费消息。在这种机制中,消息被存储在 BookKeeper 中。DelayedDeliveryTracker 在消息发布到 broker 后,在内存中维护时间索引(时间 -> 消息ID)。一旦指定的延迟时间结束,这条消息将被传递给消费者。
注意:只有共享订阅和键共享订阅支持延迟消息投递。在其他类型的订阅中,延迟消息会立即分发。
下图说明了延迟消息投递的概念:

broker 保存消息而不进行任何检查。当消费者消费消息时,如果消息设置为延迟,则该消息会被添加到 DelayedDeliveryTracker 中。订阅会检查并从 DelayedDeliveryTracker 中获取超时的消息。
注意:
与保留策略一起使用:在 Pulsar 中,当 ledger 中的消息被消费后,该 ledger 会自动删除。Pulsar 会删除主题前面的 ledger,但不会删除主题中间的 ledger。这意味着如果发送了一条延迟很长时间的消息,该消息直到达到延迟时间之前不会被消费。这意味着即使某些后续 ledger 已完全消费,只要延迟消息未被消费,该主题上的所有 ledger 都无法删除。
与积压配额策略一起使用:在使用延迟消息后,使用积压配额策略要小心谨慎。这是因为延迟消息可能会导致消息在长时间内未被消费,触发积压配额策略,从而导致后续消息发送被拒绝。
与消息过期策略一起使用:当时间到期时,Pulsar 会自动将消息移动到已确认状态(准备将其删除),即使这些消息是延迟消息,也不会考虑预期的延迟时间。
12.1、Broker
延迟消息传递默认启用,可以按以下方式在 broker 配置文件中进行更改:
# Whether to enable the delayed delivery for messages. # If disabled, messages are immediately delivered and there is no tracking overhead. delayedDeliveryEnabled=true # Control the ticking time for the retry of delayed message delivery, # affecting the accuracy of the delivery time compared to the scheduled time. # Note that this time is used to configure the HashedWheelTimer's tick time for the # InMemoryDelayedDeliveryTrackerFactory (the default DelayedDeliverTrackerFactory). # Default is 1 second. delayedDeliveryTickTimeMillis=1000 # When using the InMemoryDelayedDeliveryTrackerFactory (the default DelayedDeliverTrackerFactory), whether # the deliverAt time is strictly followed. When false (default), messages may be sent to consumers before the deliverAt # time by as much as the tickTimeMillis. This can reduce the overhead on the broker of maintaining the delayed index # for a potentially very short time period. When true, messages will not be sent to consumer until the deliverAt time # has passed, and they may be as late as the deliverAt time plus the tickTimeMillis for the topic plus the # delayedDeliveryTickTimeMillis. isDelayedDeliveryDeliverAtTimeStrict=false
12.2、Producer
以下是生产者延迟消息传递的示例:
// message to be delivered at the configured delay interval producer.newMessage().deliverAfter(3L, TimeUnit.Minute).value("Hello Pulsar!").send();