正则表达式从入门到高级
序言
对于正则,许多程序员都觉得它很繁琐,找不到头绪。但其实只要明白了基础语法,正则其实是非常简单的。学习正则表达式一定要躬行实践,自己动手来测试的自己表达式,这将大大有益对于正则表达式的掌握。在正文开始前,先给大家推荐一个好用的正则在线测试工具,本文后面将会使用它来对我们编写的正则表达式做测试:https://c.runoob.com/front-end/854/
基础语法
正则表达式的基本形式:/pattern/flags 。其中 pattern 是匹配规则,flage 被称为修饰符。我们先来看一个简单的示例:
正则:/you/g
文本:If you shed tears when you miss the sun, you also miss the stars
匹配结果:
you
you
you提示:在每一个示例下面,可以通过上面提供的在线测试工具来自己测试一下,加深理解。在线测试工具的结果:
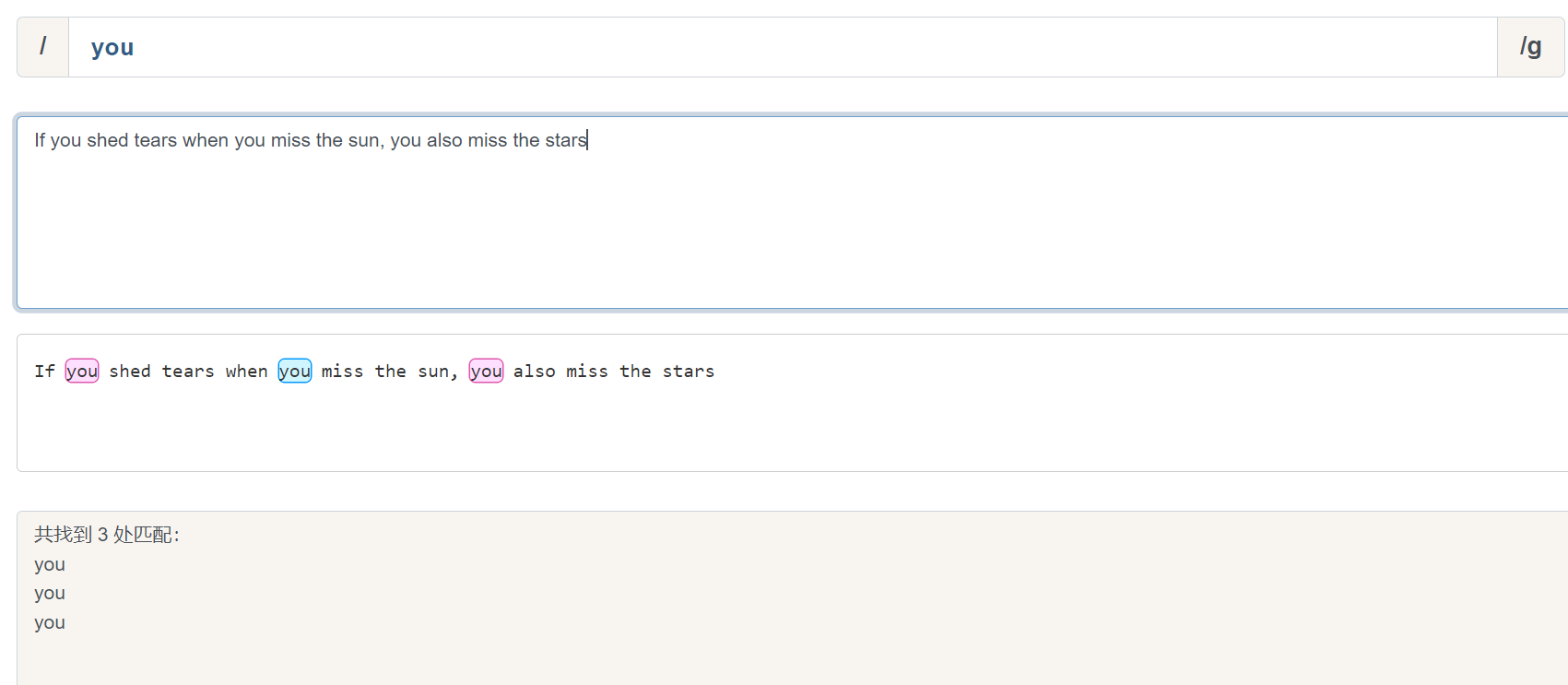
在上面的示例中,/g 被称为全局匹配,是一个常用修饰符,表示匹配字符串中的所有元素,即匹配了3个 you 。
修饰符
修饰符用于标记正则表达式的额外策略,下面四个是常用的修饰符:
| 字符 | 描述 |
| g | 全局匹配 |
| i | 忽略大小写 |
| m | 多行模式 |
| s | 该模式下,.会匹配换行符\n |
g 基本在所有表达式中都需要携带的修饰符,i 望文知义。 m 和 s 我们会在后文中逐渐的认识到,现在不必纠结他们。
元字符
元字符这个概念比较难以被理解,通常会直接劝退一批想学正则表达式的人。其实元字符说白了,就是规定一个普通字符具备特殊含义,用来匹配符合这个特殊含义的字符。我们先列举出常用的一些元字符,逐项来看他们的所具备的特殊含义。
选择与分支
| 字符 | 描述 |
| sea|sky | 匹配 sea 或者 sky,可以匹配若干个,如 sea|sky|stars |
| [abc] | 匹配 a 和 b 和 c |
| [^abc] | 匹配除了 a 和 b 和 c 之外的字符 |
| [a-z] | 匹配 a 到 c 之间的所有小写字符,也可以使用[0-9]匹配数字范围 |
| [a-z] | 匹配除了 a 到 c 之间的所有小写字符,同理,也可以匹配数字范围 |
以上五个选择分支的匹配规则是很常用的匹配规则。通常,sea|sky 这种匹配方式会被 () 括起来:

() 也是一种元字符,通常用来把一组匹配规则括起来,表示一个分组。
基础元字符
| 字符 | 描述 |
| . | 匹配任意字符,不包括换行符\n和\r,如果需要匹配 \n和\r ,可以使用修饰符:s |
| \d | 匹配一个数字,相当于 [0-9] |
| \D | 匹配非数字,相当于 [^0-9] |
| \s | 匹配任意空白字符,相当于 [\t\n\r\f\v] |
| \S | 匹配非空白字符,相当于 [^\t\n\r\f\v] |
| \w | 匹配数字、字母、下划线中任意一个字符,相当于 [a-zA-Z0-9_] |
| \W | 匹配非数字、字母、下划线中的任意字符,相当于 [^a-zA-Z0-9_] |
\ 也是一个基础元字符,用来将元字符转换为普通字符,类似于编程语言中的转义。如真的要匹配 . 这个字符,应该使用 \. ,否则 . 将会被识别为匹配任意字符。正则表达式中需要的转义字符:* . ? + $ ^ [ ] ( ) { } | \
边界元字符
还有一些基础元字符:边界元字符。其不占用字符位置,只是表达一个边界:
| 字符 | 描述 |
| \b | 匹配位于每个单词的开始或结束位置 |
| \B | 匹配不是单词开头和结束的位置,即每个单词的中间位置 |
| ^ | 匹配开始位置,多行模式下匹配每一行的开始 |
| $ | 匹配结束位置,多行模式下匹配每一行的结束 |
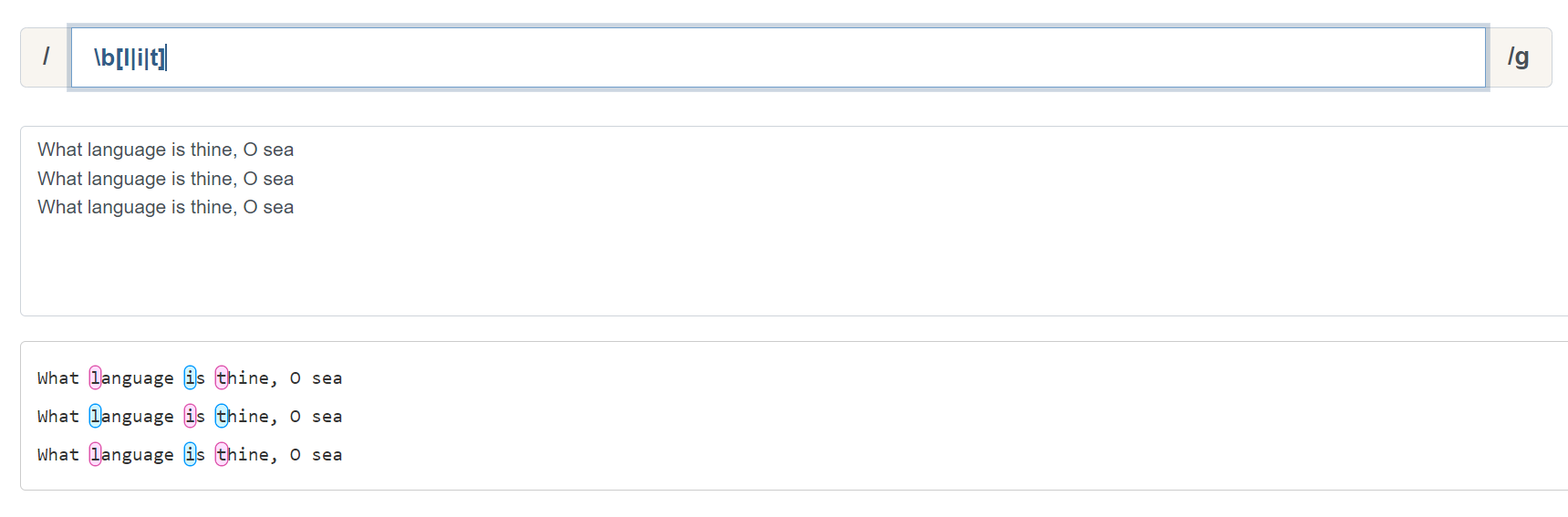
\b 和 \B 比较容易理解,\b 可以粗略的理解就是匹配单词之间的空格,但是匹配结果不会携带这个空格。\B 则是和 \b 相反:

^ 和 & 匹配有一个很重要的概念:行。他们表示了一行的开始和结束位置。我们来看一个示例:
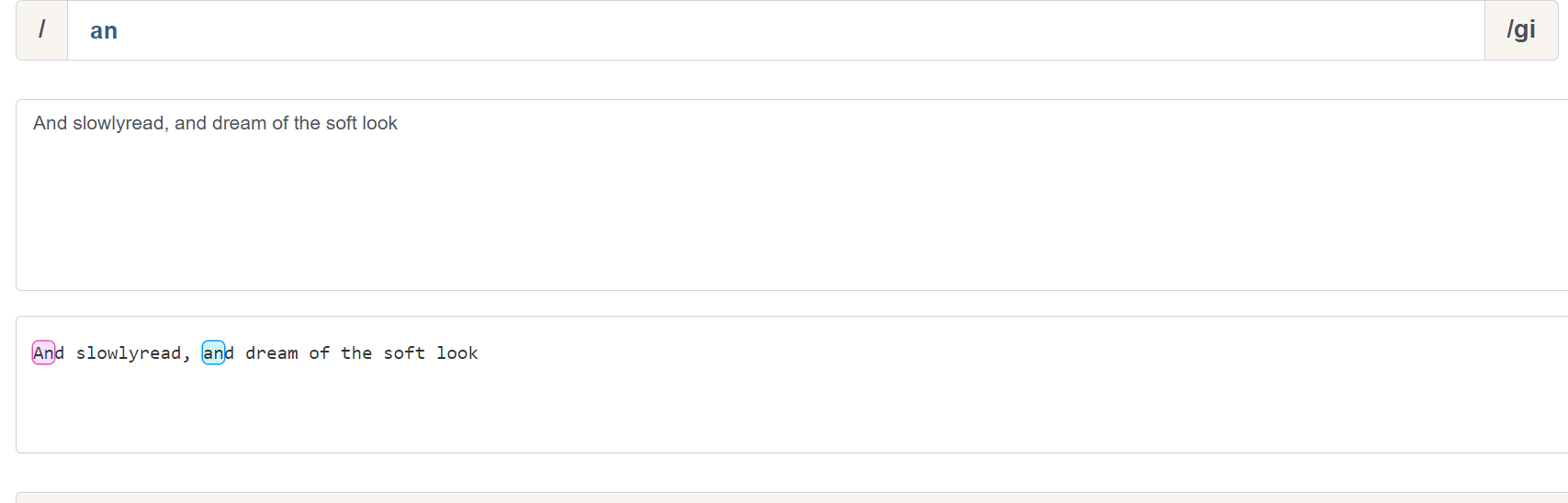

可以看到,加入了 ^ 后,an 的匹配只会从行首开始匹配,我们这里加入 i 修饰符,表示不区分大小写的匹配。& 同理:


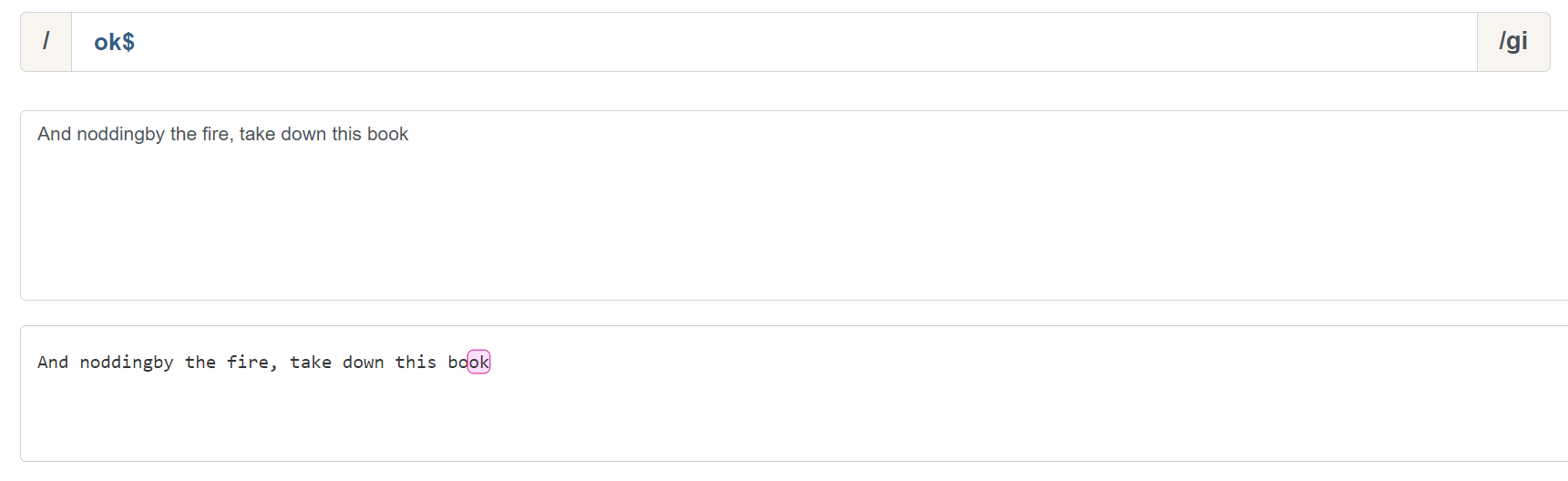
为什么说行是 ^ 和 & 的重要概念呢,我们来看一组示例。ok& 可以匹配以 ok 为结束的字符:
这显然符合我们的预期,但是当我们在加入一行文本,匹配结果就会出现意外:
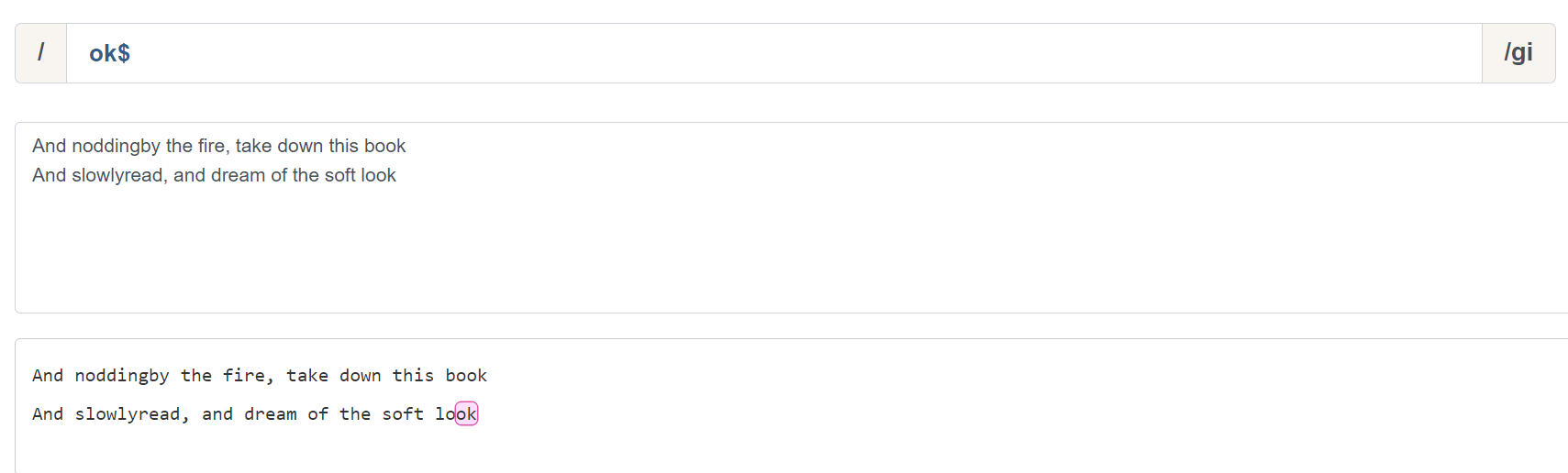
按照道理说,应该能匹配到两个 ok 字符,但是这里只匹配到了最后一行,如果需要匹配多行数据,则需要加入一个修饰符:m (多行模式)。让我们看一下加入多行模式后的匹配结果:

这样就符合了我们的预期情况。
重复匹配
| 字符 | 描述 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 "do" 或 "does" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配 n 次。例如,o{2,} 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 "fooooood" 中的前三个 o。o{0,1} 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
在该匹配的模式下,还有一个特殊的元字符:?。被称为非贪婪模式。注意,该 ?和上文的匹配零次或一次完全不同。非贪婪模式的元字符 ? 只能跟在上述六个的重复匹配后面。例如,我们想要匹配出一段文本中的以 http 或者 https 开头的图片地址:
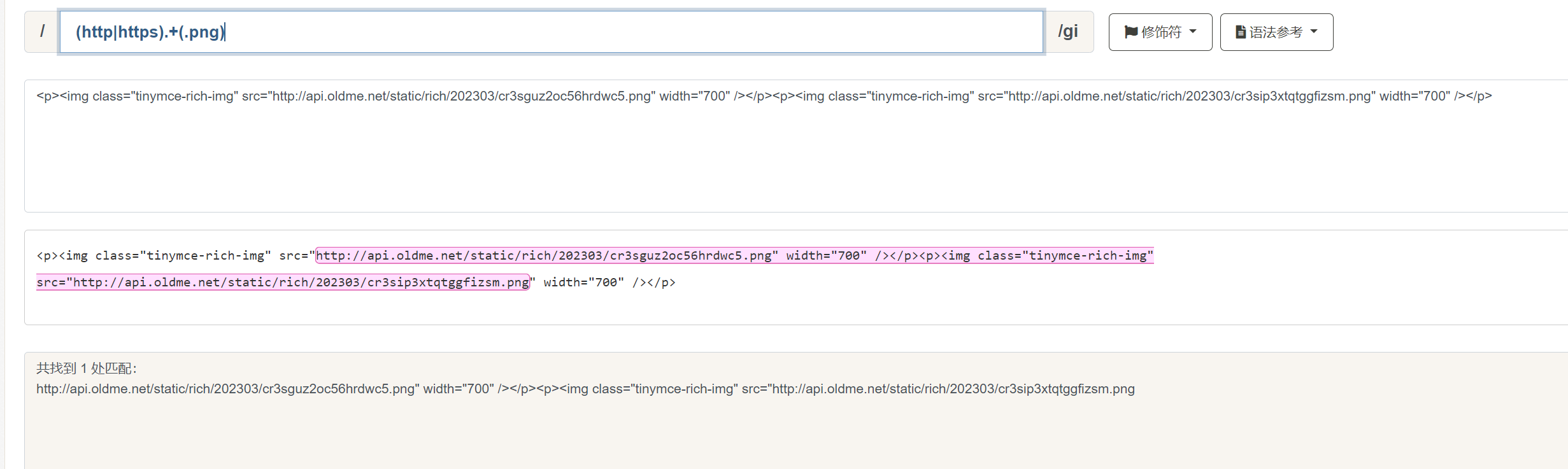
示例文本中存在两个 .png 的图片,我们使用 (http:https) 来匹配 http 或者 https 开头,然后使用 . 来匹配所有字符,再加上 + ,表示一次或多次匹配,最后使用 (.png) 表示匹配 .png 结束。但这样的结果就是当我们遇到第一个 .png 时,.+ 也会匹配到 .png,所以就导致了获取了错误的匹配结果。遇到这种情况,我们就要使用非贪婪模式,在 + 后面加上 ? :

可以看到,此时获取了我们想要的结果。非贪婪模式下,会尽可能少的匹配字符串。
到此,我们已经掌握了正则表达式的基础,可以找一些实际的业务需求来加深理解。比如说检测邮箱地址是否合法:

\w 会匹配所有数字、字母下划线, + 表示至少需要匹配到一个字符,我们要求它需要到 @ 时停下,所以加上 ? 非贪婪模式。这样就可以成功匹配到 tyyn1022@ 。继续检测后面的是否符合要求,同样使用 \w+? 匹配域名名称,\. 表示匹配文本 . ,最后加上 (com|net|top|org),即要求顶级域名必须是 com、net、top、org。这样就匹配到了剩余的部分:163.com
零宽断言
零宽断言是正则表达式的高级用法,它一种特殊的元字符。实际作用就如同它的名字:零宽与断言。简而言之,就是匹配某个字符的前后,却又不想匹配到这个字符本身(零宽的意思)。零宽断言分为四种:
| 字符 | 描述 |
| (?=pattern) | 正向先行断言。例如,foo(?=bar) 会匹配 foobar 中的 foo。 |
| (?!pattern) | 反向先行断言。例如,foo(?!bar) 会匹配 foobaz 中的 foo,但不会匹配 foobar 中的 foo。 |
| (?<=pattern) | 正向后行断言。例如,(?<=foo)bar 会匹配 foobar 中的 bar,但不会匹配 bazbar 中的 bar,因为它前面不是 foo。 |
| (?<!pattern) | 反向后行断言。例如,(?<!foo)bar 会匹配 bazbar 中的 bar,但不会匹配 foobar 中的 bar。 |
我们来举一个实际的例子,我们需要从一段富文本文本中匹配所有以 http:// 或者 https:// 开头,以 .png 或者 .jpg 结尾的图片地址,但是要求不能把 http:// 和 https:// 匹配进去
/((?<=http://)|(?<=https://)).+?(.png|.jpg)/ig
该正则表达式即可达到我们想要的效果:
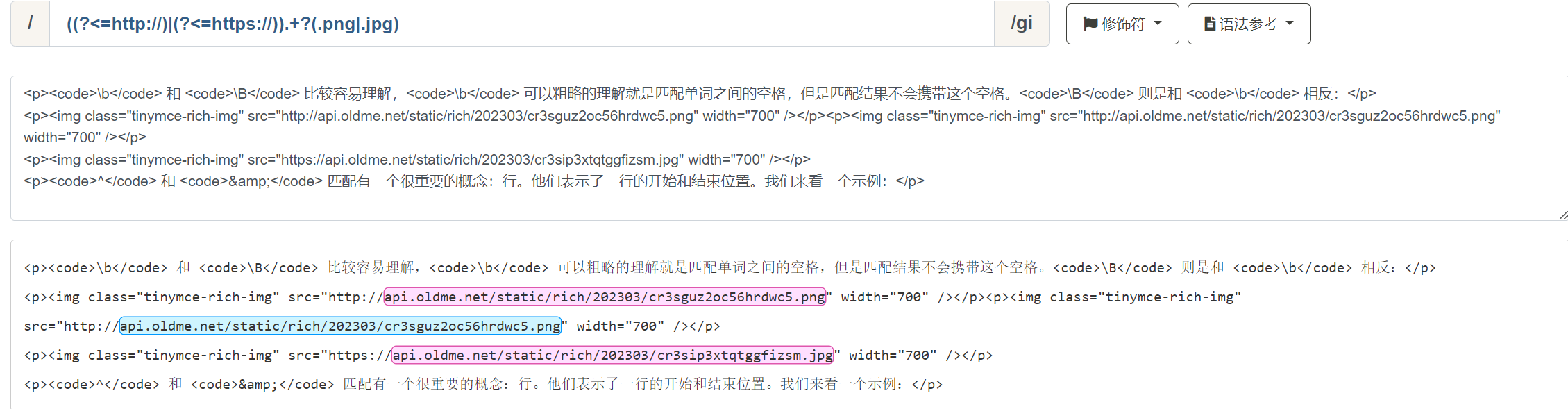
在该表达式中分为三段:
((?<=http://)|(?<=https://)),正向后行断言,表示匹配以 http:// 或者 https:// 开头的字符.+?,匹配除了换行符 \n 和 \r 之外的所有字符至少一次,且是非贪婪模式,为什么这里使用贪婪模式,可以自己动手试一下(.png|.jpg)表示以 .png 或者 .jpg 结尾
热门相关:洪荒二郎传 今天也没变成玩偶呢 豪门情变,渣总裁滚远点! 大妆 情事:八头身美女