读程序员的制胜技笔记10_可口的扩展
2023-11-12 07:11 由
躺柒 发表于
#其他
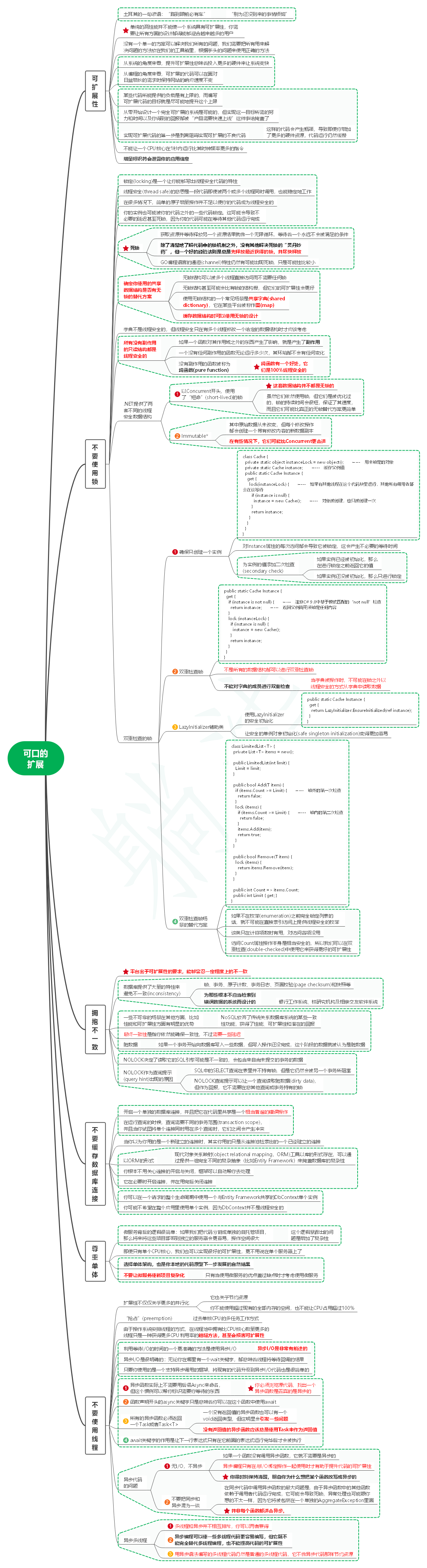
1. 可扩展性
1.1. 土耳其的一句谚语:“路到眼前必有车”
1.1.1. “别为还没到来的事情烦恼”
1.2. 单纯的高性能并不能使一个系统具有可扩展性,你需要让所有方面的设计都得能够迎合越来越多的用户
1.3. 没有一个单一的方案可以解决我们所有的问题,我们需要把所有用来解决问题的方法放在我们的工具箱里,根据手头的问题来使用正确的方法
1.4. 从系统的角度来看,提升可扩展性意味着投入更多的硬件来让系统变快
1.5. 从编程的角度来看,可扩展的代码可以在面对日益增长的需求时保持网站的响应速度不变
1.6. 某些代码所能提供的负载是有上限的,而编写可扩展代码的目标就是尽可能地提升这个上限
1.7. 从零开始设计一个完全可扩展的系统是可能的,但实现这一目标所需的努力和时间以及你得到的回报都被“产品需要快速上线”这件事给掩盖了
1.8. 实现可扩展代码的第一步是剥离阻碍实现可扩展的不良代码
1.8.1. 这样的代码会产生瓶颈,导致即使你增加了更多的硬件资源,代码运行仍然缓慢
1.9. 不能让一个CPU核心在1秒内运行比其时钟频率更多的指令
1.10. 增量标识符会泄露你的应用信息
2. 不要使用锁
2.1. 锁定(locking)是一个让你能够写出线程安全代码的特性
2.2. 线程安全(thread safe)的意思是一段代码即使被两个或多个线程同时调用,也能稳定地工作
2.3. 在很多情况下,简单的原子增量操作并不足以使你的代码成为线程安全的
2.4. 你的实例也可能被你的代码之外的一些代码锁定。这可能会导致不必要的延迟甚至死锁,因为你的代码可能在等待其他代码运行完成
2.5. 死锁
2.5.1. 获取资源并等待释放另一个资源结果就像一个无限循环,等待着一个永远不会被满足的条件
2.5.2. 除了清楚地了解代码中的锁机制之外,没有其他解决死锁的“灵丹妙药”,但一个好的经验法则是总是先释放最近获得的锁,并尽快释放
2.5.3. GO编程语言的通道(channel)特性仍然有可能出现死锁,只是可能性比较小
2.6. 确定你使用的共享数据结构是否有无锁的替代方案
2.6.1. 无锁结构可以被多个线程直接访问而不需要任何锁
2.6.2. 无锁结构甚至可能会比有锁的结构慢,但它们的可扩展性会更好
2.6.3. 使用无锁结构的一个常见场景是共享字典(shared dictionary),它在某些平台被称作图(map)
2.6.4. 缓存数据结构时可以使用无锁的设计
2.7. 字典不是线程安全的,但线程安全只在有多个线程修改一个给定的数据结构时才应该考虑
2.8. 所有没有副作用的只读结构都是线程安全的
2.8.1. 如果一个函数对其作用域之外的东西产生了影响,就是产生了副作用
2.8.2. 一个没有任何副作用的函数无论运行多少次,其环境都不会有任何变化
2.8.3. 没有副作用的函数被称为纯函数(pure function)
2.8.3.1. 纯函数有一个好处,它们是100%线程安全的
2.9. .NET提供了两套不同的线程安全数据结构
2.9.1. 以Concurrent开头,使用了“短命”(short-lived)的锁
2.9.1.1. 这套数据结构并不都是无锁的
2.9.1.2. 虽然它们依然使用锁,但它们是被优化过的,锁的持续时间会很短,保证了其速度,而且它们可能比真正的无锁替代方案更简单
2.9.2. Immutable
2.9.2.1. 其中原始数据从未改变,但每个修改操作都会创建一个带有修改内容的新数据副本
2.9.2.2. 在有些情况下,它们可能比Concurrent更合适
2.10. 双重检查的锁
2.10.1. 确保只创建一个实例
2.10.1.1. C#
class Cache {
private static object instanceLock = new object(); ⇽--- 用来锁定的对象
private static Cache instance; ⇽--- 缓存实例值
public static Cache Instance {
get {
lock(instanceLock) { ⇽--- 如果有其他线程在这个代码块里运行,其他所有调用者都会在这等待
if (instance is null) {
instance = new Cache(); ⇽--- 对象被创建,也只被创建一次
}
return instance;
}
}
}
}
2.10.1.2. 对Instance属性的每次访问都会导致它被锁定,这会产生不必要的等待时间
2.10.1.3. 为实例的值添加二次检查(secondary check)
2.10.1.3.1. 如果实例已经被初始化,那么在进行锁定之前返回它的值
2.10.1.3.2. 如果实例还没被初始化,那么只进行锁定
2.10.2. 双重检查锁
2.10.2.1. C#
public static Cache Instance {
get {
if (instance is not null) { ⇽--- 注意C# 9.0中基于模式匹配的“not null”检查
return instance; ⇽--- 返回实例而无须锁定任何内容
}
lock (instanceLock) {
if (instance is null) {
instance = new Cache();
}
return instance;
}
}
}
2.10.2.2. 不是所有的数据结构都可以进行双重检查锁
2.10.2.3. 不能对字典的成员进行双重检查
2.10.2.3.1. 当字典被操作时,不可能在锁之外以线程安全的方式从字典中读取数据
2.10.3. LazyInitializer辅助类
2.10.3.1. 使用LazyInitializer的安全初始化
2.10.3.1.1. C#
public static Cache Instance {
get {
return LazyInitializer.EnsureInitialized(ref instance);
}
}
2.10.3.2. 让安全的单例对象初始化(safe singleton initialization)变得更加容易
2.10.4. 双重检查锁场景的替代方案
2.10.4.1. C#
class LimitedList<T> {
private List<T> items = new();
public LimitedList(int limit) {
Limit = limit;
}
public bool Add(T item) {
if (items.Count >= Limit) { ⇽--- 锁外的第一次检查
return false;
}
lock (items) {
if (items.Count >= Limit) { ⇽--- 锁内的第二次检查
return false;
}
items.Add(item);
return true;
}
}
public bool Remove(T item) {
lock (items) {
return items.Remove(item);
}
}
public int Count => items.Count;
public int Limit { get; }
}
2.10.4.2. 如果不在枚举(enumeration)之前完全锁定列表的话,就不可能在直接索引访问上提供线程安全的枚举
2.10.4.3. 该类只在计算项数时有用,对访问各项没用
2.10.4.4. 访问Count属性操作本身是相当安全的,所以我们可以在双重检查(double-checked)中使用它来获得更好的可扩展性
3. 拥抱不一致
3.1. 平台出于可扩展性的要求,能够容忍一定程度上的不一致
3.2. 数据库提供了大量的特性来避免不一致(inconsistency)
3.2.1. 锁、事务、原子计数、事务日志、页面校验(page checksum)和快照等
3.2.2. 为那些根本不应当检索到错误数据的系统而设计的
3.2.2.1. 银行工作系统、核研究机构及相亲交友软件系统
3.3. 一些不可靠的场景在其他方面,比如性能和可扩展性方面有明显的优势
3.3.1. NoSQL放弃了传统关系数据库系统的某些一致性功能,获得了性能、可扩展性和潜在的回报
3.4. 最终一致性是指你依然能确保一致性,不过需要一些延迟
3.5. 脏数据
3.5.1. 如果一个事务开始向数据库写入一些数据,但写入操作还没完成,这个阶段的数据就被认为是脏数据
3.6. NOLOCK决定了读取它的SQL引擎可能是不一致的,会包含来自尚未提交的事务的数据
3.7. NOLOCK作为查询提示(query hint)出现的原因
3.7.1. SQL中的SELECT查询在表里并不持有锁,但是它仍然会被另一个事务所阻塞
3.7.2. NOLOCK查询提示可以让一个查询读取脏数据(dirty data),但作为回报,它不需要在意其他查询或事务持有的锁
4. 不要缓存数据库连接
4.1. 开启一个单独的数据库连接,并且把它在代码里共享是一个相当普遍的错误操作
4.2. 在运行查询的时候,查询需要不同的事务范围(transaction scope),并且当你试图将单个连接同时用在多个查询时,它们之间会产生冲突
4.3. 当你以为你用的是一个新建立的连接时,其实你用的只是从连接池检索出的一个已经建立的连接
4.4. 以ORM的形式
4.4.1. 现代对象关系映射(object relational mapping,ORM)工具以库的形式存在,可以通过提供一组完全不同的复杂抽象(比如Entity Framework)来掩盖数据库的复杂性
4.5. 你根本不用关心连接的开启与关闭,框架可以自动帮你去处理
4.6. 它在必要时开启连接,并在用完后关闭连接
4.7. 你可以在一个请求的整个生命周期中使用一个与Entity Framework共享的DbContext单个实例
4.8. 你可能不希望在整个应用里使用单个实例,因为DbContext并不是线程安全的
5. 尊重单体
5.1. 微服务背后的逻辑很简单:如果我们把代码分割成单独的自托管项目,那么将来将这些项目部署到独立的服务器会更容易,操作空间很大
5.1.1. 这个逻辑暴露出的问题是增加了复杂性
5.2. 即使只有单个CPU核心,我们也可以实现很好的可扩展性,更不用说在单个服务器上了
5.3. 选择单体架构,也是你本地的代码原型下一步发展的自然结果
5.4. 不要让微服务使新项目复杂化
5.4.1. 只有当使用微服务的优点盖过缺点时才考虑使用微服务
6. 不要使用线程
6.1. 扩展性不仅仅关乎更多的并行化
6.1.1. 它也关乎节约资源
6.1.2. 你不能使用超过现有的全部内存的空间,也不能让CPU占用超过100%
6.2. “抢占”(preemption)
6.2.1. 过去单核CPU的多任务工作方式
6.3. 由于操作系统安排线程的方式,在线程池中拥有比CPU核心数量更多的线程只是一种获得更多CPU利用率的粗糙方法,甚至会损害可扩展性
6.4. 利用等待I/O的时间的一个更准确的方法是使用异步I/O
6.4.1. 异步I/O是非常有前途的
6.5. 异步I/O是很明确的:无论你在哪里有一个wait关键字,都意味着线程将等待回调的结果
6.6. 只要你使用的是一个支持异步调用的框架,将现有的代码升级到异步I/O代码也是很简单的
6.7. 异步函数实际上不需要用后缀Async来命名,但这个惯例可以帮你标识需要你等待的东西
6.7.1. 你必须浏览源代码,找出一个异步函数是否真的是异步的
6.8. 函数声明开头的async关键字只是意味着你可以在这个函数中使用await
6.9. 所有的异步函数必须返回一个Task或者Task<T>
6.9.1. 一个没有返回值的异步函数也可以有一个void返回类型,但这明显会引发一些问题
6.9.2. 没有返回值的异步函数应该总是使用Task来作为返回值
6.10. await关键字的作用是让下一行表达式只有在它前面的表达式运行完毕后才会被执行
6.11. 异步代码的问题
6.11.1. 无I/O,不异步
6.11.1.1. 如果一个函数没有调用异步函数,它就不需要是异步的
6.11.1.2. 异步编程只有在与I/O绑定操作一起使用时才有助于提升代码的可扩展性
6.11.1.3. 你得时刻保持清醒,明白你为什么想把某个函数改写成异步的
6.11.2. 不要把同步和异步混为一谈
6.11.2.1. 在同步代码中调用异步函数的最大问题是,由于异步函数中的其他函数依赖于调用者代码运行完成,它可能会导致死锁,异常处理也可能跟你想的不太一样,因为它将被包裹在一个单独的AggregateException里面
6.11.2.2. 并非每个函数都适合异步。
6.12. 异步多线程
6.12.1. 多线程和异步并不相互排斥,你可以两者兼得
6.12.2. 异步编程可以使一些多线程代码更容易编写,但它既不能完全替代多线程编程,也不能提高代码的可扩展性
6.12.3. 用异步语法编写的多线程代码仍然是普通的多线程代码,它不像异步代码那样节约资源
热门相关:都市剑说 星界游民 试婚老公,要给力 覆汉 都市剑说