分布式存储系统举例剖析(elasticsearch,kafka,redis-cluster)
1. 概述
对于分布式系统,人们首先对现实中的分布式系统进行高层抽象,然后做出各种假设,发展了诸如CAP, FLP 等理论,提出了很多一致性模型,Paxos 是其中最璀璨的明珠。我们对分布式系统的时序,复制模式,一致性等基础理论特别关注。
在共识算法的基础上衍生了选举算法,并且为分布式事务提供了部分的支持。本文从常见的几种分布式存储系统看看实践中的分布式系统设计细节。理论结合实际,能更好地帮助我们加深理解。
2.分片
先来看看分片的定义:
The word “Shard” means “a small part of a whole“. Hence Sharding means dividing a larger part into smaller parts. In DBMS, Sharding is a type of DataBase partitioning in which a large database is divided or partitioned into smaller data and different nodes
分片是分布式存储系统绕不开的话题,分片提供了更大的数据容量,能够提升读写效率,提升数据可用性。
| 分布式存储系统 | 分片 | 备注 |
| elasticsearch | 每个index 进行分片,即 shard | shard计算,shard = hash(routing) % number_of_primary_shards |
| kafka | 每个topic分析分片,即 partition | 根据key来选择partition,也可以根据自定义partition算法实现 同一的user发送到同一 的partition |
| redis-cluster | 对所有数据进行分片,hash slot 16384(2^14) | hash tags 确保数据分配到同一个slot:{123}:profile and user:{123}:account |
- 对redis-cluster 来讲,redis client 需要缓存 key - slot 映射,因为redis 节点不会对 查询请求进行代理,如果查询数据不存在,则需要client重新查询。
- redis-cluster 的设计目标是在提供高性能的基础上,让redis数据能分布在多达1000个节点的集群上。
3.复制
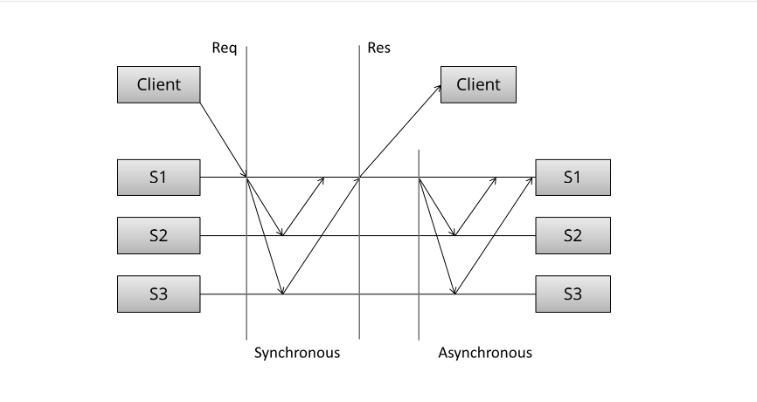
复制提升了数据的可靠性,复制分片还可以用来做read。在分布式系统重,有两种复制模式:
- 同步复制,主节点在同步数据到slave,然后返回响应给到client
- 异步复制,主节点先返回响应给到client,然后同步数据到slave
| 分布式存储系统 | 复制 | 备注 |
| elasticsearch | primary 复制数据到 in-sync copies,同步复制 | |
| kafka | 主分片复制数据到 ISR (in sync replica) | producer 可以配置 acks 和 min.insync.replicas 来调整一致性 |
| redis-cluster | 采用redis 的复制机制,异步复制 | redis对性能非常敏感,所以采用的都是异步复制 |
- 以上三种系统均采用 primary-backup model (Google I/O 2009 - Transactions Across Datacenters), 具有低延迟,高吞吐,会有部分的数据丢失窗口
- 旧的elasticsearch 版本中可以调整write conistency level : one(primary shard), all(all shard), quorum(default).
- kafka 是典型的日志消息系统,数据量特别大,在常见的quorum-based 系统中,为了能容忍n个节点失败,往往需要2n + 1 个节点,这对kafka来讲多余的存储成本非常的高,于是kafka采用了ISR机制,即只维护那些与主分片及时保持同步的分片,当主分片失败时,从ISR 中选取一个作为最新的主分片即可。
4.一致性
不同的复制策略带来了不同的一致性,常见的一致性有
- 强一致性
- 最终一致性
- 弱一致性
根据Ryan Barrett在Google I/O 2009 - Transactions Across Datacenters中的定义,elasticsearch/kafka/redis-cluster 都采用了 primary-backup model,primary-backup model 的特点是最终一致性,但是具体细节有所不同。
| 分布式存储系统 | 写入一致性 | NWR 模型 | 备注 |
| elasticsearch | 最终一致性 (较强) | w(all write) , r(1) | 需要refresh 到文件系统缓存才可见,flush操作到磁盘 |
| kafka | 最终一致性 (可调) | w(ack writes) , r(1) | ack = 0 最弱,ack = all 最强 |
| redis-cluster | 最终一致性 (较弱) | w(1) , r(1) |
- 采用最终一致性,意味着在写入过程中,会出现部分节点返回最新数据,部分节点返回过期数据的情况,由于这个时间窗口很小,往往可以接受。
- 我们在这里提到了NWR模型,参考 partial quorums,partial quorums 在基于冲突解决的复制模型中使用广泛,比如Dynamo。当 r + w > n 时总有节点能返回最新的数据。
5.选举算法
选举算法的基础是共识算法,paxos是其中最璀璨的明珠,paxos在共识算法中的地位可以用这样表述:
Either Paxos, or Paxos with cruft, or broken
paxos 最早应用于google 的 Chubby (lock manager),zk是 Chubby的开源版本。
| 分布式存储系统 | 选举算法 | 备注 |
| elasticsearch | bully/类raft | bully算法比较简单,谁大就选谁 |
| kafka | zookeeper(zab)/kraft(raft) | |
| redis-cluster | 类raft |
- 可以看到很多分布式组件都有转向raft的趋势。
-
由于paxos算法晦涩难懂,并且如果要应用到实际过程中需要做很多调整,所以开发了一个易于理解的版本raft算法,raft算法分为 leader election, log replication, safety, and membership changes 等模块,相比于paxos 所有节点都是平等的,raft 进行leader 选举,并且通过log replication进行数据同步,safety 确立了raft算法的完备性,membership changes 处理节点变更的情形。log replication 表示了raft底层的数据结构,对我们设计类似系统大有裨益。
6.事务支持
存储系统中,事务是非常重要一部分,我们来看看各类组件是否支持分布式事务,以及他们是如何实现的:
| 分布式存储系统 | 事务支持 | 备注 |
| elasticsearch | 不支持 | |
| kafka | 支持事务,基于2PC | |
| redis-cluster | 不支持跨节点的事物,支持单节点的事物 | 使用multi/exec/watch 来实现 |
- 2PC是一种强一致的模型,具有高延迟,低吞吐的特点。
- 常见的分布式事务模型有,primary-backup model,multi-master model, 2PC, Paxos. 3PC 是2PC 的变体。个人认为TCC, 基于消息表的事务也是2PC 的变体。
7.总结
本文从分布式系统的几个方面探讨了elasticsearch,kafka,redis-cluster的细节,他们有很多共性,但是在许多方面也有很多不同。鉴于笔者对分布式系统的研究还不是很深入,如果错误,请指正。
8.参考
https://book.mixu.net/distsys/single-page.html
https://www.youtube.com/watch?v=srOgpXECblk
https://snarfed.org/transactions_across_datacenters_io.html
http://harry.me/blog/2014/12/27/neat-algorithms-paxos/
https://ramcloud.atlassian.net/wiki/download/attachments/6586375/raft.pdf